
動画AIのための文化的適応ベストプラクティス
AI動画をグローバル市場に適応させる方法——文化的な手がかり、言語と音声、バイアス、トランスクリエーションのパイプライン、ガバナンス、市場別のパフォーマンス指標。
動画AIを複数の市場で機能させたいなら、スクリプトを翻訳するだけでは足りません。 話し方、ジェスチャー、色、服装、ユーモア、画面上のテキスト、単位、そしてレビュー規則をチェックする必要があります。なぜなら動画モデルは今なお的を外すことが多いからです。あるベンチマークでは_忠実度が56.8%_、行動面は_52.1%_を下回ると報告されています。
要点を手短にまとめると次のとおりです。
- 翻訳だけでは不十分。 単語の置き換えでは、トーン、ジョーク、シンボル、社会的な振る舞いを取りこぼします。
- 動画はリスクを増やす。 優れた音声トラックがあっても、ジェスチャー、色、間の取り方がしっくりこなければ失敗し得ます。Google Veo 3.1のような高度なモデルは、同期音声と映像的なコントロールを提供し、こうしたリスクの軽減に役立ちます。
- データが出力を形づくる。 多くのモデルは、見た目、アクセント、振る舞いにおいて西洋的なデフォルトに偏りがちです。
- プロンプトは有効だが、人の手も依然重要。 2026年のあるテストでは、マルチエージェント型のプロンプト構成で_14.3%_の向上が見られました。
- 反復可能なパイプラインは、その場しのぎの修正に勝る。 スクリプトの変更、テキスト拡張、吹き替え、リップシンク、字幕、法務レビュー、最終QA——これらすべてに決まったフローが必要です。
- ガバナンスも仕事のうち。 音声クローンの同意、肖像の利用、シンボルの使用は、公開前に文書化しておくべきです。
- 市場レベルの指標が、何がうまくいったかを教えてくれる。 ロケール別に視聴時間、CTR、CPA、コメント、センチメント、苦情、修正率を追跡すべきです。
いくつかの詳細が際立ちます。ドイツ語のコピーは英語より_20%–30%長く_なることがあり、ペースと同期の調整が必要です。デザインにもテキストの伸長の余地——多くは_15%–30%_程度——を確保する必要があります。そして米国の視聴者向けには、06/26/2026、$、マイル、°Fといった形式を用いるべきです。
つまるところ話は単純です。_これは最後の土壇場の編集ではなく、リリースプロセスとして扱うべき_ということです。それはすなわち、アイデンティティ・行動・コンテキストの明確なタグ付け、プロンプトのガードレール、ネイティブスピーカーによるレビュー、ポリシーチェック、そして公開後のトラッキングを意味します。
動画AIシステムが対処すべき中核的な文化要因
視覚的な手がかり、シンボル、社会規範
視覚上の選択——服装、ジェスチャー、色、食べ物、間の取り方——は、その場ですぐに意味を帯びます。
色はわかりやすい例です。白は多くの西洋的な文脈では純粋さを表すことが多いですが、一部のアジア文化では喪を示すことがあります [8][9]。服装も同じくらい重要です。より保守的な市場を狙う動画では控えめな装いが求められることがあり、一方で日本のビジネスの場ではフォーマルなスーツが通常想定されます [9]。画面上の人物どうしの距離ですらメッセージを送り得ます。パーソナルスペースの規範は市場ごとに異なるからです。
ジェスチャーや日常のやり取りは、ローカライズするうえでしばしば最も難しい部分です。主に西洋のメディアで学習したモデルは、あいさつのデフォルトを握手にしがちです。しかし米国では無害に見えるジェスチャーが、他の地域では不快感を与えることがあります——中東の一部でのサムズアップ、ブラジルでの「OK」サイン、タイで人に足先を向けることなどです [9]。つまり、ジェスチャーの選択は中立的なデフォルトとして扱うことはできません。市場固有の出力制約として扱わなければなりません。
言語、音声、画面上テキストのディテール
言語の適応は、単語の置き換えをはるかに超えるものです。トーンや丁寧さは市場によって変わります。米国のコピーはしばしば率直で明るい響きを持ち、一方で日本語のコピーはより丁寧で間接的に映ることが多いです [9]。ユーモアはさらに厄介です。ある場所で通用するジョークが、別の場所では滑る——あるいは悪く受け取られる——ことがあります。したがって狙うべきは、逐語訳ではなく同じ感覚です。
音声のペース配分もまた、書き手の問題であるだけでなく技術的な問題です。ドイツ語のテキストは英語より約20〜30%長くなり、音声のタイミングを変える必要が生じます [3]。ペースをそのままにすると、吹き替え音声がグラフィックや字幕からずれ始めます。
米国の視聴者向けには、書式のディテールも重要です。
- 日付は月/日/年の形式、たとえば06/26/2026を用いる
- 価格は米ドルで表示する
- 距離はマイルを用いる
- 気温は華氏(Fahrenheit)を用いる [1]
話される音声は仕事の一部にすぎません。画面上のテキスト——タイトル、ローワーサード、CTA——にも、同じく市場ごとの対応が必要です。MiniMax-Hailuo-02で作成したコンテンツのようなAI生成動画では、焼き込みテキストは市場ごとに再生成すべきです。実写動画では、モーショントラッキングされたローカライズ済みのオーバーレイが、テキストの伸長への対応に役立ちます [3]。
生成メディアにおけるバイアス、表象、公平性
多くの動画AIモデルは、西洋の英語圏メディアに大きく偏ったデータセットで学習されてきました。その結果はかなり直接的です。プロンプトが求めていなくても、出力はしばしば西洋的な美学、アクセント、社会規範をデフォルトにしてしまいます [5][8]。研究者はこれを**「WEIRD」**問題と呼びます——学習データが西洋的(Western)、高学歴(Educated)、工業化された(Industrialized)、富裕な(Rich)、民主的な(Democratic)文脈に形づくられる一方で、他の集団の表象が乏しくなる問題です [8]。
これは出力に表れます。マイノリティコミュニティのキャラクターは、主体性を欠いた背景的な役割に押しやられ、トークニズムに陥ることがあります。非西洋的なアクセントは平板化・中和されることがあります。同じビジュアルスタイルばかりが繰り返し現れ、他の市場が後回しにされているように感じさせます。場合によっては、見た目が最も優れているモデルが、文化的忠実度では最も低いスコアになることもあります [5]。
「文化的な配慮は、最初の1フレームを撮る前に組み込むのが最も簡単だ。」 - Sarah Miller, Author, Vozo [8]
出力をレビューするうえで有用な方法は、3つの次元——アイデンティティ、行動、コンテキスト——で見ることです。アイデンティティ、行動、コンテキストを、データセットのキュレーションと出力レビューのチェックリストとして使いましょう。大規模プロジェクトでは、統一されたゲートウェイを通じて500以上のAIモデルにアクセスし、これらの次元を異なるシステムをまたいでテストできます。
文化的正確性のために動画AIを構築・チューニングする方法
文化的カバレッジのためにデータセットとメタデータをキュレーションする
タグ付けから始めます。学習の前に、広範なラベルにとどまらない形で文化的タグとメタデータを定義します。各クリップは、アイデンティティ・行動・コンテキストにまたがってタグ付けすべきです。たとえば東京の職場でのあいさつであれば、単なる国のタグだけでなく、丁寧さのレベル、社会的階層、そして状況そのものを記録すべきです [6]。
インタラクションのラベルはここで大いに役立ちます。社会的な意味はしばしば小さな瞬間に宿るからです。有用なカテゴリには、感謝・謝罪・あいさつ・別れといった**Expressives(表出行為)や、情報の要求/拒否といったDirectives(指示行為)**があります [6]。これはモデルに地図上のピン以上のものを与えます。モデルに社会的な場面を与えるのです。
地理的なトークンだけでは不十分です。代わりに、具体的な視覚的ディテールを含むプロンプトやメタデータを使いましょう。一例として、マルチモーダルの視覚分析を用いて、着物を「伝統的な日本の衣服」と呼ぶのではなく、左が右にかぶさる襟合わせで記述する方法があります [5]。この種のディテールは、モデルが広範な手がかりから推測するのをやめ、人々が実際に目にすると期待するものに一致させる助けになります。
データにタグが付いたら、プロンプト時の制御を使って生成を導きます。
プロンプト、ガードレール、人によるレビューを組み合わせる
データは役立ちますが、それだけで出力を解決するわけではありません。プロンプトとガードレールがそれを補う必要があります。平板な一行プロンプトは、しばしばあまりに多くのニュアンスを取りこぼします。より強力な構成はマルチエージェント・プロンプティングで、別々のエージェントが人物・アクション・場所を扱ってから結果を統合します [7]。
2026年5月、Santa Clara Universityの研究者はこれをMAVENフレームワークを通じてテストしました。「ポタラ宮で古筝を演奏する中国人」というプロンプトを使い、マルチエージェント型のパイプラインはCultural Relevance Scoreで0.271に達しました。これはベースモデルの0.237に対して14.3%の向上でした。出力はさらに、旗袍にインスパイアされたアップスタイルや、楽器のための特定の手の技法といったディテールも捉えました [7]。
プロンプティングは仕事の一部にすぎません。センシティブな素材に対するポリシーのガードレールと、意味がすり抜けてしまい得るケースのための人によるレビューも必要です。言語ごとにネイティブスピーカーによるレビューの時間を確保しましょう。AIは今なお、視線の方向、対人距離、感情のトーンといった微妙な非言語シグナルの扱いに苦労しています [6][3]。
出力に対して構造化された文化的品質チェックを実施する
生成後は、学習時に使ったのと同じ文化的タグを使って各クリップをレビューします。単純な承認の一巡では、規模が大きくなると持ちこたえられません。多くの市場向けに動画を作るなら、勘ではなくチェックリストが必要です [5]。
そのチェックリストは、いくつかの平易な問いをカバーすべきです。
- ジェスチャーは市場に合っているか?
- シンボルや色の意味は正しく使われているか?
- ビジュアルは、決まり文句やステレオタイプ化された描写を避けているか?
行動は通常、最も的を射させにくい部分です。そこが人間のレビュアーが最も重要になりがちな場所です。構造化されたチェックリストは、レビューをより一貫したものにし、チームや市場をまたいで基準を同じに保ちます。
AIがあっても、なぜローカライゼーションには依然として人が必要なのか
大規模な多言語・異文化間動画のためのワークフロー
文化的チェックが済んだら、次の仕事は、その同じ基準をあらゆる市場で保ち続けることです。
エンドツーエンドのトランスクリエーション・パイプラインを構築する
品質チェックのあとは、反復可能なトランスクリエーション・パイプラインでスケールさせます。それは、明確な担当者、賢い自動化、そして重要なところでの人によるサインオフを意味します。
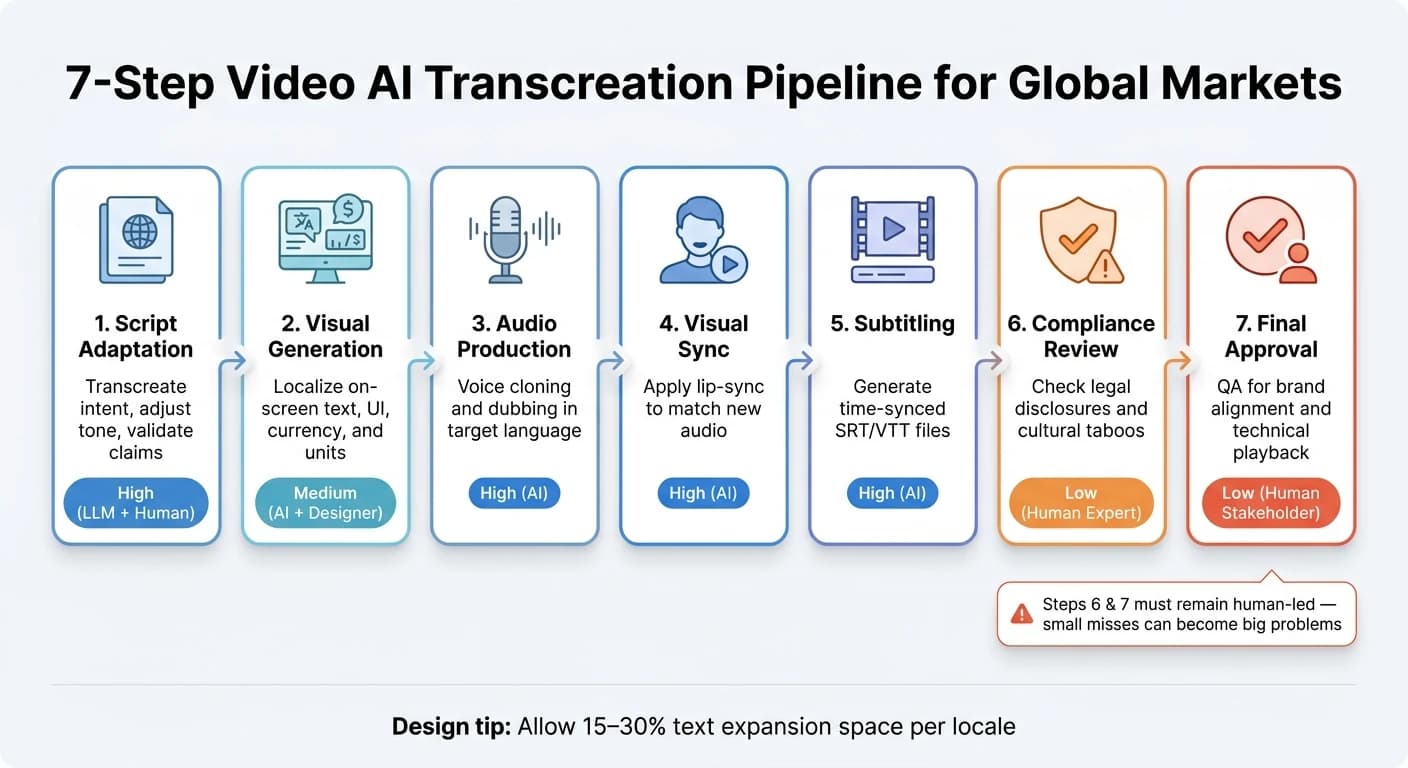
以下が7ステップのフローです。
| ステップ | アクション | 自動化レベル |
|---|---|---|
| 1. スクリプト適応 | 意図をトランスクリエイトし、トーンを調整し、主張を検証する | 高(LLM)+人によるレビュー |
| 2. ビジュアル生成 | 画面上テキスト、UI、通貨、単位をローカライズする | 中(AI+デザイナー) |
| 3. 音声制作 | ターゲット言語での音声クローンと吹き替え | 高(AI) |
| 4. ビジュアル同期 | 新しい音声に合わせてリップシンクを適用する | 高(AI) |
| 5. 字幕付け | 時間同期されたSRT/VTTファイルを生成する | 高(AI) |
| 6. コンプライアンスレビュー | 法的開示と文化的タブーをチェックする | 低(人間の専門家) |
| 7. 最終承認 | ブランド整合性と技術的な再生についてのQA | 低(人間のステークホルダー) |
2つのパートは人間主導のままにすべきです。コンプライアンスレビューと最終承認です。ここは、小さな見落としが大きな問題に変わり得る場所です。
ローカライゼーションが始まる前にマスタースクリプトを確定しておくのも有効です。ソースのスクリプトが遅い段階で変わると、すべての言語版がやり直しになります。これはパイプライン全体を遅らせ、急速にコストを増やします。デザイン面では、テキストの伸長のための余地——約15%〜30%——を残し、主要な製品ディテールを字幕やUIのゾーンより上に保ちましょう [10]。
ポイントはスピードだけではありません。各市場で意味、トーン、信頼が保たれるようにすることです。
市場とオーディエンスの反応でパフォーマンスを追跡する
動画が公開されたら、次のステップは単純です。各ロケールが望みどおりに反応しているかを確認することです。
ローカライズ動画を公開するのは、仕事の半分にすぎません。市場レベルのデータがなければ、ミスマッチがキャンペーン——あるいはブランド——を傷つけ始めるまで、それを見つけるのは難しいです。動画は紙の上では問題なく見え、正しいスペックを満たしていても、それを見る人々には違和感を与えることがあります。
以下の指標をロケール別に継続的に追跡しましょう。
- エンゲージメント:視聴率、完了率、視聴時間、クリック率(CTR)
- コンバージョン:言語別のリード、売上、収益、獲得単価(CPA)
- オーディエンスの反応:ターゲット言語でのコメント、シェア、センチメント、苦情率や修正率
- クリエイティブのパフォーマンス:最も成果の高い言語、市場ごとの最適な動画尺、最適な投稿時間
苦情率と修正率は特に注意に値します。特定のロケールでどちらか一方が急増するのは、多くの場合、何かが的を外した最初の兆候です。それを早期に捉える方が、後で全面的なリコールや公の対応を扱うよりもはるかに安上がりです。
APIMartを使って、モデルのオーケストレーションとコスト管理を一元化する
パイプラインを安定させるには、オーケストレーションを一つのAPIレイヤーで走らせるのが有効です。
多市場向けの動画ワークフローは通常、スクリプトモデル、音声モデル、画像モデル、そしてVeo 3.1のような動画生成モデル——ときには同じ実行内でそのすべて——をやりくりすることを意味します。APIMartはこれらのステップを単一のAPIで結び、社会規範、通貨形式、方言フラグを含むコンテキストメタデータをワークフロー全体に運びます。ドラフトと最終の両方のパスを一つのAPIにルーティングすることで、市場をまたいでコンテキスト、ロギング、コスト管理をそろえて保てます。
ガバナンス、リスク管理、そして重要なポイント
センシティブなコンテンツと同意に関するポリシーを定める
ローカライゼーションが稼働したら、品質、同意、承認を市場をまたいで安定させるのがガバナンスです。
表象ポリシーから始めましょう。これらはステレオタイプ化、文化の盗用、マイノリティの消去を禁じるべきです [11]。また、チームが神聖なシンボル、旗、色をどう扱うかも明記すべきです。小さなディテールがシーンの意味を変え得ます。たとえば、白は一部のアジア文化では喪を示す一方、多くの西洋的な文脈では純粋さを指します [8][11]。
表象ルールは、画面に映るものをカバーします。同意ルールは、_誰が_登場でき、_どのように_登場できるかをカバーします。肖像と音声に対する同意は、明示的かつ具体的である必要があります。タレントのリリースは、新しい市場向けのAI吹き替え、音声クローン、リップシンク編集をカバーすべきです [2]。そして、コミュニティが所有するシンボル、儀式、イメージを扱う場合、ポリシーは、何かを使う前にコミュニティの代表者への相談を求めるべきです [11]。
文書化の面では、Model Cardsとデータシートを使って、データセットの由来、ライセンス条件、収集方法、既知の文化的バイアスを記録しましょう [11]。Cultural Safety Boardを設けて、リスク評価をレビューし、影響の大きいリリースを承認しましょう。四半期ごとのレッドチーミングを実施し、チームがローンチ前に失敗モードを見つけられるようにするのも有効です [11]。
| ポリシー領域 | 文書化すべき内容 |
|---|---|
| 肖像と音声 | AI吹き替え、音声クローン、リップシンク編集をカバーするタレントのリリース |
| 文化的シンボル | 市場別の承認済み/制限付きのシンボル、色、ジェスチャー |
| モデルのバージョン | 学習データ、既知のバイアス、ライセンスを含むModel Cards |
| 承認 | 部門横断のレビューとリリースのサインオフ |
動画AIで文化的適応を展開するチームのための重要なポイント
ポリシーが定まったら、次のステップは、安定したレビューとリリースの管理です。
動画AIにおける文化的適応は、一度きりのチェックリストではありません。それは、各段階で反復可能なワークフロー、明確なポリシー、レビュー、モニタリングを必要とするシステムです。これをうまく扱うチームは、それを土壇場の編集のようには扱いません。最初からリリースプロセスに組み込みます。
文化を広く定義しましょう。それは画面上の言葉だけでなく、あらゆるフレームにおけるアイデンティティ、行動、コンテキストを含みます [5]。プロンプトのガードレールを人によるレビューと組み合わせましょう。特にジェスチャー、あいさつ、その他の非言語的手がかりでは、現在のモデルは今なお取りこぼします [6]。各リリースの前に、ポリシー違反、レビュアーからのエスカレーション、市場からの苦情を監査しましょう。
ローンチ後は、視聴完了率、センチメント、エンゲージメントといったKPIを使って市場別にパフォーマンスを追跡しましょう。それは、ローカライズされた体験がどこで意図どおりに響いていないかを、チームが見つける助けになります [2][4]。リリースの承認は、ポリシーレビュー、レッドチームの発見、市場レベルのフィードバックに結び付けたままにすべきです。
文化的適応は、一度きりのローンチ作業ではなく、監視されたリリースプロセスとして扱いましょう。
よくある質問
ローンチ前に文化的正確性をどう監査すればよいですか?
自動チェックと人によるレビューの両方を使いましょう。市場内のステークホルダーとともにフレームごとに進め、言語、トーン、ブランド適合、再生をレビューします。それからネイティブのフォーカスグループでテストし、何かが公開される前に誤読や意図しない不快感を捉えます。
CultureScoreのようなツールは、アイデンティティ、行動、コンテキストにまたがるミスマッチにフラグを立てる助けになります。あなたのプロセスに合うなら、APIMartはローカライゼーション作業をより容易にする助けになります。ただしそこで止めないでください——最終出力は必ず現地の専門家に確認してもらいましょう。
人によるレビュアーはいつ介入すべきですか?
仕事をしっくりくるものにし、ブランドを保ちたいなら、人によるレビュアーはいくつかの重要なポイントで重要です。
プリプロダクションでは、文化的なコンセプトとスクリプトをレビューし、作業がすでにかなり進んでからではなく早い段階でバイアスを捉えるべきです。翻訳のあとは、ネイティブスピーカーがトーン、意図、現地での妥当性をチェックすべきです。
2段階の承認プロセスも理にかなっています。リップシンクのレンダリング前に翻訳済み音声をサインオフし、それからネイティブスピーカーによるQAを完了して、文化的適合、コンプライアンス、メッセージングを確認します。
ローカライゼーションが成功したかどうかを最もよく示す指標はどれですか?
ビジネス上の結果とオーディエンスのフィードバックの両方を追跡しましょう。
注目すべき主なシグナルは次のとおりです。
- より高いコンバージョン率
- より長い視聴時間
- より強いエンゲージメント
- 多言語SEOによる、より良い現地検索パフォーマンス
何がうまくいっているかをより深く読み解きたいなら、表面的な分析で止めないでください。それらの数値を、社内データやソーシャルメディアのセンチメントと組み合わせましょう。
そして、AI生成コンテンツをレビューしているなら、CultureScoreフレームワークを使って、アイデンティティ、行動、コンテキストにまたがる文化的忠実度をチェックしましょう。
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。