
キャラクターストーリー制作のためのマルチモーダルAI
マルチモーダルAIがテキスト・画像・動画モデルをどう組み合わせて一貫性のあるキャラクターを構築し、シーンカードを設計し、パーソナライズされたストーリーコンテンツを生成するのかを学びます。
マルチモーダルAIは、テキスト・ビジュアル・オーディオ・動画を組み合わせることで、生き生きとしたキャラクターと一貫性のある物語を生み出し、ストーリーテリングを変革しています。コンテンツ制作を簡素化し、コストを削減し、フォーマットをまたいだ一貫性を確保します。以下は押さえておくべきポイントです。
- 何ができるのか: マルチモーダルAIは、text-to-video のような複数のコンテンツタイプを扱い、一貫したビジュアル・声・振る舞いを備えたキャラクターを作り上げます。
- なぜ重要なのか: 1エピソードあたり最大 $500,000 かかる従来の手法と比べ、制作コスト(1ストーリーあたりわずか $5)と時間(1時間未満)を大幅に削減します。
- どのように機能するのか: APIMart のようなツールは 500 以上のAIモデルを統合し、キャラクターストーリーの作成・管理をシームレスなワークフローで実現します。
- 主要なテクニック: 詳細なキャラクタープロフィールには「Character DNA Document」を使い、一貫性のためにアンカービジュアルを用意し、LoRA や IP-Adapter といった高度なツールで精度を維持します。
このガイドでは、物語を書くところから動画を制作するところまで、キャラクターを一貫させ、さまざまなオーディエンスにとって魅力的に保ちながら、マルチモーダルAIを効果的に活用する方法を解説します。
AI駆動のキャラクター開発における基本コンセプト
一貫性のあるキャラクタープロフィールを構築する
ストーリーテリングにマルチモーダルAIを使う際は、キャラクターの確固たる基盤を作ることが不可欠です。ビジュアルやセリフを生成する前に、まず 「Character DNA Document」 ——キャラクターに関するすべてを定義する詳細なリファレンス——から始めましょう。このドキュメントには、身体的な詳細(例:単なる「緑の瞳」ではなく 「わずかに吊り上がったアーモンド形のエメラルドグリーンの瞳」)、性格特性、行動の限界、そしてAIがすべての出力にわたって一貫して従うべき物語ルールを含めるべきです [3]。
このドキュメントに含める詳細のレベルは極めて重要です。曖昧な記述は一貫性のない結果を招き、キャラクターの識別性を損ないます。精密なプロフィールはAIに明確な境界を与え、物語全体を通じてキャラクターの外見・トーン・振る舞いの一貫性を確保します。
「AIコンテンツにおけるキャラクターの一貫性とは、キャラクターがすべての出力にわたって同一であり続けることを意味します。性格、トーン、振る舞い、外見、バックストーリーが変化したり、以前の詳細と矛盾したりしないということです。」 - Aisha Imtiaz, Editor, AllAboutAI [3]
ビジュアルの一貫性を維持する効果的な方法の一つが、成功したキャラクター生成から seed 番号を保存する ことです。この seed を今後のシーンで再利用することで、キャラクターのビジュアルアイデンティティが固定され、時間の経過に伴う微妙な変化を防げます [3]。
マルチモーダルモデルがどう連携するのか
テキスト・画像・動画を専門とするAIモデルは、それぞれキャラクター制作の異なる側面を担います。組み合わせて使うことで、これらのモデルは一体感のある形でキャラクターを生き生きとさせます。例えば:
- GPT-5 のような言語モデルは、キャラクターの声、バックストーリー、感情の深みを作り上げます。
- Flux Kontext のような画像モデルは、文章による記述を一貫したビジュアルデザインへと変換します。
- Kling V3 のような動画モデルは、ダイナミックなシーンをまたいで見た目を保ちながらキャラクターをアニメーションさせます。
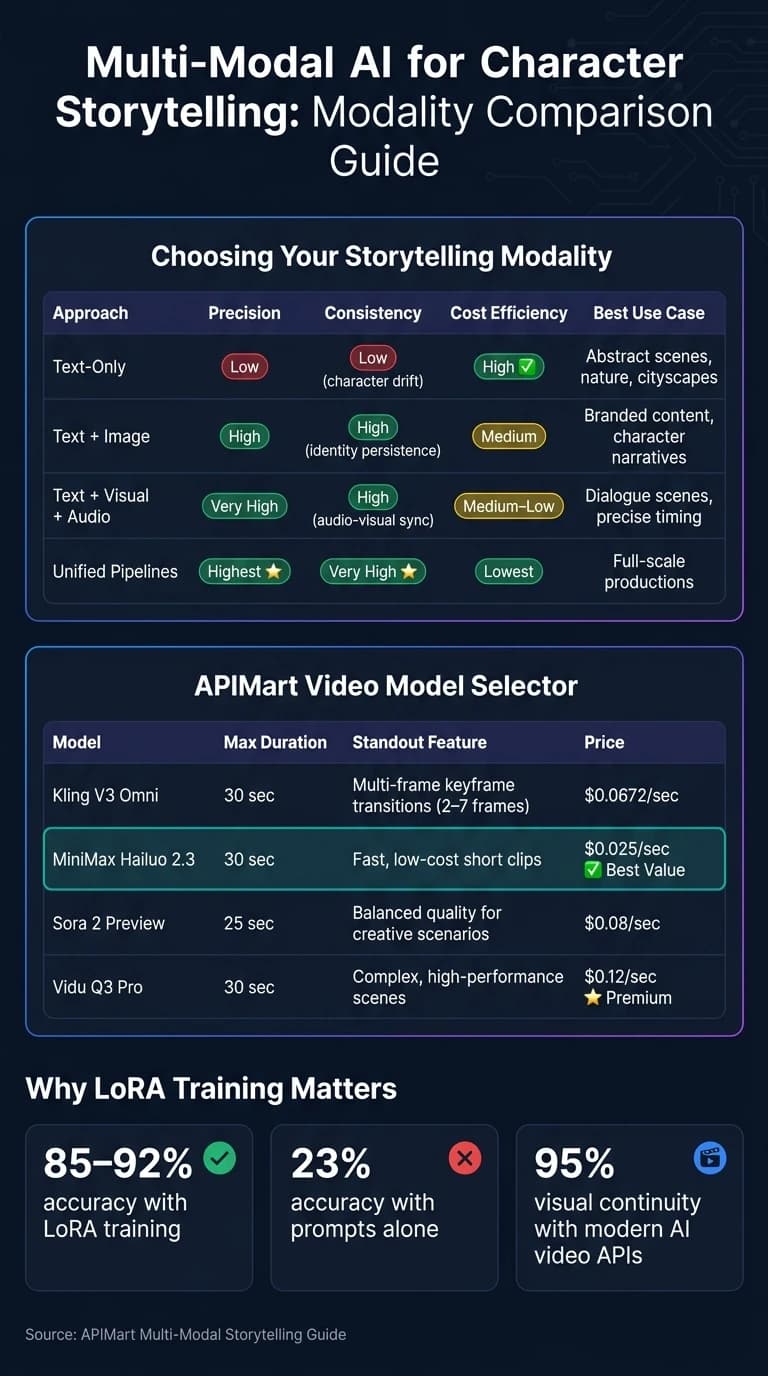
LoRA のような高度なツールは、特定のモデル層をファインチューニングして、顔の構造・衣服の質感・肌の色といった重要なディテールを固定し、プロンプトだけに頼る場合と比べて 85〜92% の精度を達成します [3]。一方、IP-Adapter は「ゼロショット」でのアイデンティティ注入を可能にします。つまり、リファレンスとなるポートレートをアップロードすれば、追加のトレーニングなしにモデルが顔の特徴を抽出します [6]。これらの手法を用いることで、現代のAI動画APIは最大 95% のビジュアル連続性を達成し、シーンをまたいだキャラクターのドリフトを 5% 未満の変動に抑えられます [6]。
かつての「プロンプトを打って祈る」アプローチから、構造化された制作ワークフローへの移行は、業界に革命をもたらしました。Atlas Cloud Blog はこう説明しています:
「業界は『プロンプトを打って祈る』から構造化された制作へと移行しました。」 [6]
この構造化されたアプローチにより、異なるAIツール間を移動しても、キャラクターの一貫性が保たれます。
キャラクターストーリーテリングにおける APIMart の役割
複数のAIモデルを管理するには、かつては複雑なセットアップが必要でしたが、APIMart のようなプラットフォームはそのプロセスを簡素化します。APIMart は、GPT-5、Claude、Flux Kontext、Kling V3、Sora を含む 500 以上のAIモデルを、単一の OpenAI 互換 API を通じて接続し、キャラクター制作パイプライン全体を効率化します。
キャラクター開発のために、APIMart には Kling V3 Omni のようなモデル向けの <<<image_N>>> リファレンス構文などの機能があります。この構文は、どのリファレンス画像に従うべきかをモデルに明示的に伝え、ビジュアルの一貫性を確保します [4]。さらに、create-character エンドポイントを使えば、既存の動画内の特定タイムスタンプからキャラクターのアイデンティティを抽出し、新しいシーンでそのアイデンティティを再利用できます [5]。これらのツールは精密なコントロールを提供し、ストーリーテリングのプロセス全体を通じてキャラクターをビジュアル的にも物語的にも一貫させます。
一貫性のあるマルチキャラクターAIストーリーを作る
マルチモーダルなキャラクターストーリーのワークフローを設計する
ストーリーのスコープを定め、モダリティを選ぶ
AIツールに飛び込む前に、プロジェクトの構成とランタイムをマッピングすることが極めて重要です。例えば、30秒の短い感情の起伏なら、それぞれ約5秒の 6〜8 個のマイクロクリップに分割できますし、2分の解説動画なら、間にタイトルカードを挟んだより長いセグメントで構成できます。この土台を最初に整えておくことで、後の余分なやり直しを避けられます。
スクリプトを、被写体・アクション・環境・カメラの動き・トーンを詳述したシーンカードに分解しましょう。これらのカードを、プレーンテキストで書くにせよ JSON 形式を使うにせよ、絵コンテのように考えてください。この設計段階により、すでに確立したキャラクターアイデンティティとの一貫性が確保されます。
精密なビジュアルが不可欠でない抽象的・雰囲気的な瞬間には、テキストのみのシーンがうまく機能します。しかし、繰り返し登場するキャラクターを導入する際は、テキストと画像を組み合わせることでビジュアルアイデンティティが固定され、シーン間の不整合を防げます。セリフと効果音の組み合わせのように、タイトな同期が求められる瞬間には、テキスト・ビジュアル・オーディオを組み合わせるのが最良のアプローチです。
シーンの概要が固まったら、次のステップは各モダリティに適したモデルを選ぶことです。
APIMart で適切なモデルを選ぶ
各シーンカードのモダリティは、最も適したAIモデルと合致させるべきです。APIMart は、単一のAPIを通じて 500 以上のAIモデルへのアクセスを提供することでこのプロセスを簡素化し、複数のアカウントや連携をやりくりする煩わしさを解消します。
テキスト生成 には、キャラクターの深みとコンテキストを作り出すのに GPT-5 が確かな選択肢です。APIMart 上の GPT-5 には、キャラクターを現実世界のディテールに根拠づける Web Search や File Search といったツールが備わっています [7]。
画像生成 には、APIMart が、文章によるキャラクター記述を一貫したビジュアルへと変換できる高度なモデルを提供します。
動画 については、選択は予算と品質のニーズによって変わります。以下はいくつかの選択肢の概要です:
| モデル | 最適な用途 | APIMart 価格 |
|---|---|---|
| Kling V3 Omni | マルチモーダル入力を用いた映画的なキャラクターシーン | $0.0672/秒 (720p) |
| MiniMax Hailuo 2.3 | 高速・低コストな短尺クリップ | $0.025/秒 |
| Sora 2 Preview | ほとんどのクリエイティブなシナリオに向いたバランスの取れた品質 | $0.08/秒 |
| Vidu Q3 Pro | 複雑で高性能なシーン | $0.12/秒 |
ヒント:GPT-5 のような言語モデルによる最初のパスを使って、キャラクターの身体的特徴を構造化された JSON 形式(例:名前、年齢、髪の色、衣装、声の記述)に抽出しましょう。この アイデンティティシート をすべてのシーンプロンプトに添付することで、すべてのモデル出力にわたってキャラクターの一貫性が確保されます [1]。
APIMart の統合APIのおかげで、モデルの選択と管理のプロセスははるかに分かりやすくなります。
ストーリーテリングにおけるモダリティの比較
各モダリティのアプローチには、それぞれ強みとトレードオフがあります。どれが自分のニーズに合うかを判断するのに役立つ、簡単な比較を以下に示します:
| アプローチ | 精密さ | 一貫性 | コスト効率 | 最適なユースケース |
|---|---|---|---|---|
| テキストのみ | 低 | 低(キャラクタードリフト) | 高 | 抽象的なシーン、自然、都市景観 |
| テキスト + 画像 | 高 | 高(アイデンティティの持続) | 中 | ブランドコンテンツ、キャラクター物語 |
| テキスト + ビジュアル + オーディオ | 非常に高 | 高(オーディオビジュアルの同期) | 中〜低 | セリフのあるシーン、精密なタイミング |
| 統合パイプライン | 最高 | 非常に高 | 最低 | フルスケールの制作 |
早い段階でより高い精密さに投資しておくと、後々の時間と労力を節約できます。テキストのみのワークフローは初期費用が安く見えるかもしれませんが、シーン間のキャラクタードリフトが追加の修正を招き、その初期の節約を帳消しにしてしまう可能性があります。
マルチモーダルなキャラクターストーリーを作成し、洗練させる
テキストベースの物語を書く
マルチモーダルなストーリーテリングの核心には、確固たる物語のフレームワークがあります。これを実現するために、GPT-5 を2つの明確なステップで活用しましょう。まず、キャラクターのビジュアルアイデンティティを、髪の色・顔の構造・衣装・声などの特徴を詳述した構造化された JSON ファイルとして抽出します。次に、物語を、それぞれが単一の主要な動詞(例:走る、隠れる、笑う)に焦点を当てた シーンカード に分解します [1]。このアプローチにより、物語が後述するビジュアルおよび動画の要素と一体感を持って合致し、キャラクターの JSON アイデンティティシートをすべてのモダリティにわたって一貫させられます。
シーンカードを作成する際は、1枚のカードにつき主要な動詞は1つに絞りましょう。複数のアクションでプロンプトを詰め込みすぎると、モデルを混乱させ、一貫性のない、あるいは無秩序な出力を招くことがよくあります [8]。
キャラクターの記述をビジュアルに変換する
キャラクターの物語的な基盤が整ったら、次のステップは彼らをビジュアル的に生き生きとさせることです。まず JSON アイデンティティシートをリファレンス画像のセットに変換します。少なくとも 正面・横顔・4分の3アングル の3つのアンカービューを目指しましょう。これらのアンカー画像はキャラクターのビジュアルガイドとして機能し、物語全体を通じて外見の一貫性を確保します [9]。
「アイデンティティのドリフト」を避けるため、顔の形・カラーパレット・衣装・ライティングの好み・デフォルトの表情といった重要な詳細を含む キャラクターバイブル を維持しましょう。すべての画像プロンプトにこのアイデンティティブロックを組み込み、変えるのはシーン固有のアクションや環境だけにします [9]。APIMart 上の Grok Imagine の Subject 機能 のようなツールを使えば、リファレンス画像を直接アップロードでき、多様な設定でもキャラクターの見た目を一貫させられます [10]。
キャラクター中心の動画シーンを制作する
アンカービジュアルが用意できたら、動画の生成に進めます。洗練された結果を確保するため、テキストプロンプトだけに頼るのではなく、これらのリファレンス画像を土台として使いましょう。
APIMart で利用できるさまざまなモデルは、それぞれ独自の動画制作ニーズに対応します。簡単な比較を以下に示します:
| モデル | 最大尺 | 際立った機能 |
|---|---|---|
| Sora 2 Pro | 25秒 | 拡張された映画的コントロールと同期オーディオ |
| Hailuo 03 | 30秒 | Director Mode と Global Identity VAE |
| Kling V3 | 30秒 | マルチフレームのキーフレーム遷移(2〜7フレーム) |
| Google Veo 3 | 8秒 | ネイティブな環境音・フォーリー・セリフのオーディオ |
クリップ間の滑らかな遷移を確保するには、「ラストフレーム」方式 を使いましょう:ある動画の最後のフレームを取り出し、それを次のシーンの開始画像として使います [10]。この方式は、ゼロからやり直す必要なく、キャラクターの位置・ライティング・表情の連続性を保ちます。Kling V3 Omni は <<<image_N>>> 構文でこのプロセスを簡素化し、プロンプト配列内の特定フレームを直接参照できるようにします [4]。
キャラクターの一貫性を保ち、ストーリーをパーソナライズする
キャラクターの一貫性を維持する方法
マルチモーダルなストーリーテリングにおける最大の課題の一つが、「キャラクタードリフト」を避けることです。これは、シーンをまたいだ小さな意図しない変化が、キャラクターを一貫性のない、あるいは識別しにくいものにしてしまう現象です。これを防ぐ鍵は、コンテンツを生成する前にキャラクターの確固たる基盤を確立することです。
まず キャラクターバイブル を作成しましょう。これには、顔の形・目の色・髪の質感・肌の色・特徴的なしるし・デフォルトの衣装といった不可欠な詳細を含めるべきです。これは、セッションをまたいでコンテキストを保持する能力を持たないAIモデルにとっての外部メモリツールだと考えてください [3][11]。あわせて、ニュートラルなライティング条件下で複数のアングル(正面・横顔・4分の3・全身)からキャラクターを示す 8〜10 枚のアンカー画像からなる リファレンスパック をまとめましょう [9][11]。
技術的な面では、LoRA トレーニング によって、顔の構造や衣服のパターンといった特定の要素をモデルのパラメータに直接埋め込むことができ、プロンプトだけに頼った場合のわずか 23% と比べて 85〜92% のキャラクター精度を達成します [3]。より細かなディテールには、IP-Adapter のようなツールが精密な顔特徴のコントロールを確保し、ControlNet が一貫したポーズと空間的な配置の維持に役立ちます [6][13]。LoRA トレーニングは手頃でもあり、通常キャラクターモデル1体あたり $5 から $15 程度のコストです [13]。APIMart のようなプラットフォームは、Hailuo 03 の Global Identity VAE や Sora 2 の character_url パラメータといったツールで、このプロセスをさらに簡素化し、カスタムトレーニングの必要をなくします。
一貫性を維持する上で、2つのワークフロー習慣が大きな違いを生みます:
- キャラクターの記述子をすべてのプロンプトの冒頭に置く。 AIモデルは順序に基づいてトークンを優先するため、アイデンティティの詳細をプロンプトの後方に埋もれさせると、その影響力が弱まります [11]。
- 5〜8 シーンごとに連続性を確認する。 これにより、ドリフトが大きな問題になる前に早期に発見・修正できます [12]。
「『AI生成コンテンツ』と『AI映画』の隔たりは一貫性です。その隔たりを埋めれば、あなたは単に画像を生成しているのではなく——物語を語っているのです。」 - Sofia Chen, Growth & Marketing Lead, CinemaDrop [11]
これらのステップに従うことで、ビジュアルと物語の両面での一貫性を確保でき、キャラクターをさまざまなオーディエンスにシームレスに適応させる準備が整います。
異なるオーディエンス向けにストーリーを適応させる
キャラクターのアイデンティティが固定されたら、その中核的な特性を保ちながら、さまざまなオーディエンス向けに物語を適応させられます。一貫性は硬直性を意味しません——教室に語りかけるにせよ、役員会でプレゼンするにせよ、あなたのキャラクターは複数のコンテキストで共感を得られるままでいられます。秘訣は、キャラクターのビジュアルと振る舞いの核を保ちつつ、言語・トーン・設定・文化的な参照といった要素を仕立て直すことにあります。
APIMart のようなプラットフォームは、このプロセスをスケーラブルにします。中央集約されたキャラクター埋め込みにより、バーチャルなスポークスパーソンが、異なる言語やローカライズされた環境に適応しながらも、市場をまたいで同じ外見を維持できます [6]。これはバーチャルインフルエンサーの動作の仕方に似ています。2026年初頭までに、これらのインフルエンサーは 4.2% の市場シェア を獲得し、5.67% のエンゲージメント率——人間のカウンターパートのほぼ3倍——を達成しました [6]。
| アプローチ | 一貫性 | オーディエンスの柔軟性 | 最適な用途 |
|---|---|---|---|
| テキストのみ | 低 | 高 | 抽象的または一般的なシーン |
| テキスト + 画像 | 高 | 中 | ブランドコンテンツ、キャラクター物語 |
| 統合パイプライン | 非常に高 | 高 | エピソード形式のシリーズ、複数市場向けキャンペーン |
教育コンテンツでは、トーンをより親しみやすく調整し、語彙を簡素化し、設定を題材に合わせて適応させます——すべて中核のキャラクターアイデンティティを保ったままです。エンターテインメントでは、シーンのコンテキストを変えるだけで、同じキャラクターが緊迫した映画的な役柄を演じられます。キャラクターバイブル は変わらず、変化するのは周囲の要素だけです。
結論と重要なポイント
ストーリーテリングにおけるマルチモーダルAIの主なメリット
マルチモーダルAIは、クリエイターが達成できることを再定義しました。かつては大人数のチーム・多額の予算・数か月の労力を要したタスクが、いまや1時間未満で——しかもごくわずかなコストで——完了できます [2]。この変化はキャラクター主導のストーリーテリングにとって画期的であり、物語の流れを保ちながら制作時間を劇的に削減します。
しかしそれは速度とコストだけの話ではありません。マルチモーダルAIは、ストーリーテリングに新たなレベルの深みと一貫性をもたらします。キャラクターの成長・因果関係のダイナミクス・テーマの一貫性——ばらばらのツールがしばしば苦戦する要素——をシームレスに管理します。例えば、2026年のある調査では、断片化されたツールに頼った場合、63% のライターがオリジナルの素材を作るよりもAI生成コンテンツの編集に多くの時間を費やしたことが明らかになりました [14]。統合されたマルチモーダルなアプローチは、この非効率の多くを取り除きます。
「シンプルなチャットボットはメールには十分ですが、一体感のある物語が必要なときには力不足です。」 - SidekickWriter [14]
クリエイティブなプロセスを効率化することで、マルチモーダルAIはストーリーテリングをより便利にするだけでなく、品質と一貫性の基準も引き上げます。これらのツールは、クリエイターがより豊かで魅力的な物語を、より少ない摩擦で作り上げる力を与えます。
APIMart で次のステップへ
これらの進歩を実践に移す準備ができたなら、APIMart は分かりやすいソリューションを提供します。テキスト・画像・動画にまたがる 500 以上のAIモデルへのアクセスを、単一の OpenAI 互換 API エンドポイント(api.apimart.ai/v1)を通じて提供します。この統合システムにより、複数のAPIキーや請求アカウントを管理したり、プロバイダー間を切り替えたりする煩わしさが解消されます。
始めるにあたっては、下書きと社内レビューにはコスト効率の良いモデルを使うことを検討しましょう。物語を洗練させたら、最終的な仕上がりの出力にはプレミアムモデルに切り替えます。一貫したキャラクターの外見には、seed パラメータを再利用します。そしてコストを抑えるには、1080p や 4K 解像度にスケールアップする前に、720p で出力を検証しましょう。このアプローチにより、品質と予算を効果的に両立できます。
よくある質問
シーン間のキャラクタードリフトを止める最速の方法は?
キャラクタードリフトを避ける最速の方法は、リファレンス画像 をビジュアルガイドとして使うことです。複数のアングルを示すキャラクターシートは、顔のジオメトリ・プロポーション・衣服の一貫性をモデルが保つのに役立ちます。APIMart のようなツールを使えば、こうしたマルチモーダル入力をワークフローに簡単に統合できます。ビジュアルアンカーを、一貫したプロンプトテンプレートおよび固定 seed と組み合わせることで安定性が確保され、絶え間ない手動調整の必要が減ります。
LoRA トレーニングは必要か、それともリファレンス画像で十分か?
LoRA トレーニングを使うかどうかの判断は、突き詰めればキャラクターの外見にどれだけの一貫性が必要かにかかっています。短尺クリップや単一シーンなら、通常リファレンス画像で事足ります。1枚の画像をアップロードするか、以前のフレームに頼るだけで、キャラクターのアイデンティティを保てます。
しかし、ウェブシリーズのように複数のシーンにまたがるプロジェクトなら、LoRA トレーニングがより良い選択肢になります。より高い忠実度をもたらしますが、追加の労力を伴います。適切に仕上げるには、15〜30 枚の高品質な画像と、もう少しの技術的な知識が必要です。
AI動画のために、スクリプトをどうシーンカードに分割すべきか?
Subject: Alex、20代半ばの若いアーティストで、乱れた髪と絵の具が飛び散ったオーバーオール姿。狭いワンルームアパートの散らかった木製の机に座っている。
Action: Alex は大きなノートに一心にスケッチをしており、ときおり手を止めて壁にピンで留められたリファレンス写真に目をやる。彼らは鉛筆の先を噛みながら、物思いにふけっている。
Environment: 部屋は1つのデスクランプでぼんやりと照らされ、画材の棚や描きかけのキャンバスが周りに散らばっている。背景の窓からは、夕暮れの賑わう都市景観が見える。
Camera Direction: カメラは Alex の集中した表情のクローズアップから始まり、そこからゆっくりとズームアウトして、散らかっていながらも創造的な空間を映し出す。
Tone: ムードは親密で内省的であり、Alex の献身とワークスペースの静かなエネルギーを強調する。
Audio: 柔らかなインストゥルメンタルのピアノトラックが背景に流れ、遠くの車のクラクションやくぐもった話し声といった、かすかな街の音が混ざり合う。
Scene 2
Subject: Alex はアパートの建物から出てくる。今は黒いフーディーとジーンズを身につけ、片腕にスケッチブックを抱えている。
Action: 彼らは混雑した歩道を足早に歩き、歩行者をよけながら、ときおり頭上にそびえる摩天楼を見上げる。
Environment: 通りは活気に満ちている——ネオンサインが点滅し、露天商が通行人に呼びかけ、車がいらだたしげにクラクションを鳴らす。
Camera Direction: カメラは中距離で Alex を後方から追い、賑わう人混みの中を進む彼らの動きをとらえる。ときおり、そびえ立つ建物のローアングルショットに切り替わり、街の圧倒的なスケールを強調する。
Tone: シーンは活気に満ち生き生きとしており、前のシーンの孤独と街の混沌を対比させる。
Audio: サウンドスケープは重なり合う街のノイズ——足音、おしゃべり、クラクションを鳴らす車——で満たされ、切迫感とエネルギーを生み出す。
Scene 3
Subject: Alex は静かな公園に着き、小さな池のそばの人けのないベンチを見つける。彼らは腰を下ろし、スケッチブックを開いて描き始める。
Action: Alex がスケッチをする間、彼らはときおりカモが滑るように泳ぐ穏やかな水面を見上げる。かすかなそよ風が彼らの髪を揺らす。
Environment: 公園は穏やかで、午後遅くの光の中、高い木々が長い影を落としている。池は沈みゆく夕日の金色の色合いを映している。
Camera Direction: カメラは公園のワイドショットから始まり、そこから Alex がスケッチする姿のミディアムショットへと移る。ページの上を動く彼らの手のディテールにとどまり、その芸術性の流れるような動きをとらえる。
Tone: 雰囲気は穏やかで思索的であり、先ほどの混沌とは対照的な静けさのひとときを提供する。
Audio: 揺れる葉のやさしい音とさえずる鳥の声がシーンに寄り添い、近くの噴水からのかすかな水の滴る音が加わる。
Scene 4
Subject: 見知らぬ人物、ツイードのジャケットと帽子をかぶった年配の男性が Alex に近づき、彼らのスケッチブックを興味深そうにのぞき込む。
Action: 男性は Alex の絵についてコメントし、短い会話が生まれる。Alex ははにかんで微笑み、その称賛にあきらかに照れている。
Environment: 設定は変わらず、公園は夕日の温かな光に包まれている。
Camera Direction: カメラは Alex と男性のミディアムショットを交互に映し、彼らの表情とボディランゲージをとらえる。Alex がより多くの作品を見せようとスケッチブックを向けると、クローズアップが彼らの微笑みを際立たせる。
Tone: そのやり取りは温かく心を高揚させるもので、芸術によって引き合わされた2人の見知らぬ者同士のつながりを暗示する。
Audio: 公園の環境音が続き、彼らの会話のかすかなつぶやきがその上に重なる。
Scene 5
Subject: 夜が訪れる中、Alex は家路につく。街はいまや街灯と輝く窓に照らされている。
Action: 彼らは屋台で足を止め、ホットドッグを買い、近くのベンチに座って食べる。ひと口ごとに、スケッチブックをめくり、自分の進歩に微笑む。
Environment: 通りはいまや静かで、人も少なく、より涼しくリラックスした雰囲気だ。屋台から湯気が立ちのぼり、空気は澄んで感じられる。
Camera Direction: カメラは屋台の温かな光に縁取られた Alex をミディアムショットでとらえる。クローズアップは、スケッチブックのページをめくる彼らの手を映し、詳細な描画を見せる。
Tone: ムードは満ち足りて内省的であり、達成感とともにその日の旅路を締めくくる。
Audio: まろやかなジャズの調べが背景でそっと流れ、通り過ぎる車のときおりの唸りと屋台のジュージューという音に溶け合う。
Related Blog Posts
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。