
複数のAIモデルを1本のOpenAI互換APIで統合する実践手順
複数ベンダーのLLMをOpenAI互換の単一ゲートウェイに束ね、APIキー1本・自動フェイルオーバー・マルチモーダル連携で運用する流れを整理。Pythonサンプルと認証設定、コスト最適化、429/5xx時フェイルオーバー、表による落とし穴チェックまで本番向けに解説(APIMart想定)。
AI連携をシンプルにしたいですか? 統合APIを使えば、複数のAIモデルを1つの窓口から呼び出せます。例えば GPT、Claude、Gemini などを、単一のインターフェース越しに接続できます。SDK・認証情報・プロトコルをベンダーごとに抱え込まず、1つのエンドポイントで管理できるため、開発時間の短縮、コスト削減、さらにプロバイダ障害時もアプリを落としにくくする、といった効果が期待できます。
統合APIで得られる代表的なメリットは次のとおりです。
- 全モデルを1本のAPIで: テキスト・画像・動画モデルへ、プロバイダごとにコードを書き換えずにアクセスできます。
- コスト最適化: 単純な処理は安価なモデルへ、高度な処理は上位モデルへ振り分け、支出を最大約60%まで抑えることも可能です。
- 自動フェイルオーバー: 障害時にバックアップモデルへ切り替え、サービス継続性を高めます。
- 請求の一元化: 1枚の請求書と、コスト・パフォーマンスを追える単一ダッシュボードで運用できます。
- 導入の速さ: OpenAI 互換の APIMart のようなプラットフォームなら、数分で試せます。
統合APIはマルチモデル運用、支出管理、信頼性の維持を一括で扱いやすくします。具体的な進め方を見ていきましょう。
Lightning Model API Hub の動画チュートリアル
関連のポイント(動画内)
上記の Lightning Model API Hub チュートリアルでは、モデル探索、プロバイダの切り替え、単一ダッシュボード上でのマルチモーダル処理の扱いなど、画面操作レベルの流れを確認できます。
マルチモデル統合のための「統合API」とは何か
統合AI API は、複数のプロバイダを1つのインターフェースの下にまとめる単一のアクセス点として機能します [7]。OpenAI、Anthropic、Google などにそれぞれ別実装を持たなくても、1つのゲートウェイへリクエストを送れます。ゲートウェイ側でルーティング・各プロバイダ向けの整形・標準化されたレスポンスの返却が行われます。
異なる AI プロトコルへの「翻訳役」と考えてください。共通フォーマット—多くの場合 OpenAI の chat/completions 系に寄せた形—で送ると、使用中のプロバイダ(Anthropic の Messages API や Google の Gemini プロトコルなど)向けに統合APIが変換します。
こうした構成により、プロバイダ選びが大規模な開発判断ではなく、設定の調整に近いものになります [7]。例えば OpenAI モデルから Claude 3.5 へ切り替えるのが、設定内の文字列1つを変える程度で済むこともあります。SDK の大規模更新や認証の作り直しが不要になるケースが多いです。実例として、トムソン・ロイターズの法務向けアシスタント「CoCounsel」は、2026年初頭の開発で統合APIを用い、プロバイダ固有コードの負担を避けながら約2か月でプロジェクトを進めたと報告されています [7]。
統合APIの主な機能
統合APIには、実装を効率化する機能がまとまって載っています。
- マルチモーダル対応: テキスト生成、画像解析、動画合成、音声処理など、多様な用途を1つの連携で扱えるように設計されているものがあります [7]。用途ごとに別SDKを覚える必要が減ります。
- モデル探索: 利用可能なモデルやトークン上限・温度パラメータなどをプログラムから把握し、要件に応じて動的にモデルを選べます [6]。
- 自動フェイルオーバー: プロバイダのダウンタイムやレート制限発生時に、別モデルへ自動で切り替え、処理の継続を図ります。
- 請求・分析の一元化: 複数の請求書を細かく追う代わりに、機能・エージェント・タスク種別ごとのコストを1つのダッシュボードで把握し、無駄や支出の偏りを見つけやすくなります。
なぜ統合APIを使うのか
これらの機能は、現場でのメリットとして次のように現れます。
認証情報の簡素化: APIキーは原則1本で済み、ベンダーごとに認証方式を増やし続ける負担を減らせます。
実装の速さ: すでに OpenAI SDK などを使っている場合、ベースURLと APIキーを差し替えるだけで移行が進むことが多く、数分単位の作業に収まることもあります。エンタープライズでは5モデル以上を運用する比率が37%に達し、LLM支出が2025年の2四半期だけで35億ドルから84億ドルへと伸びた、という集計も報告されています [7]。
コスト最適化: タスクを費用対効果の高いモデルへ振り分けられます。例えば単純な処理は MiniMax Hailuo 2.3 のように秒あたり0.025ドル程度の選択肢へ、負荷の高い処理は上位モデルへ、といった配分が可能です。価格の見える化とボリュームディスカウントにより、支出管理もしやすくなります。
「統合AI API がこの無秩序を整理する。1つのエンドポイント、1つのSDK、1枚の請求書。アプリは単一のインターフェースに話しかけ、API が必要なプロバイダへルーティングする。」
冗長性による信頼性: あるプロバイダが停止しても、別プロバイダへ自動で寄せることで稼働を維持しやすくなります。価格や性能の変化にも、コードを根本から書き換えずに追従しやすい柔軟性があります。
複数AIモデルを統合する手順(ステップバイステップ)
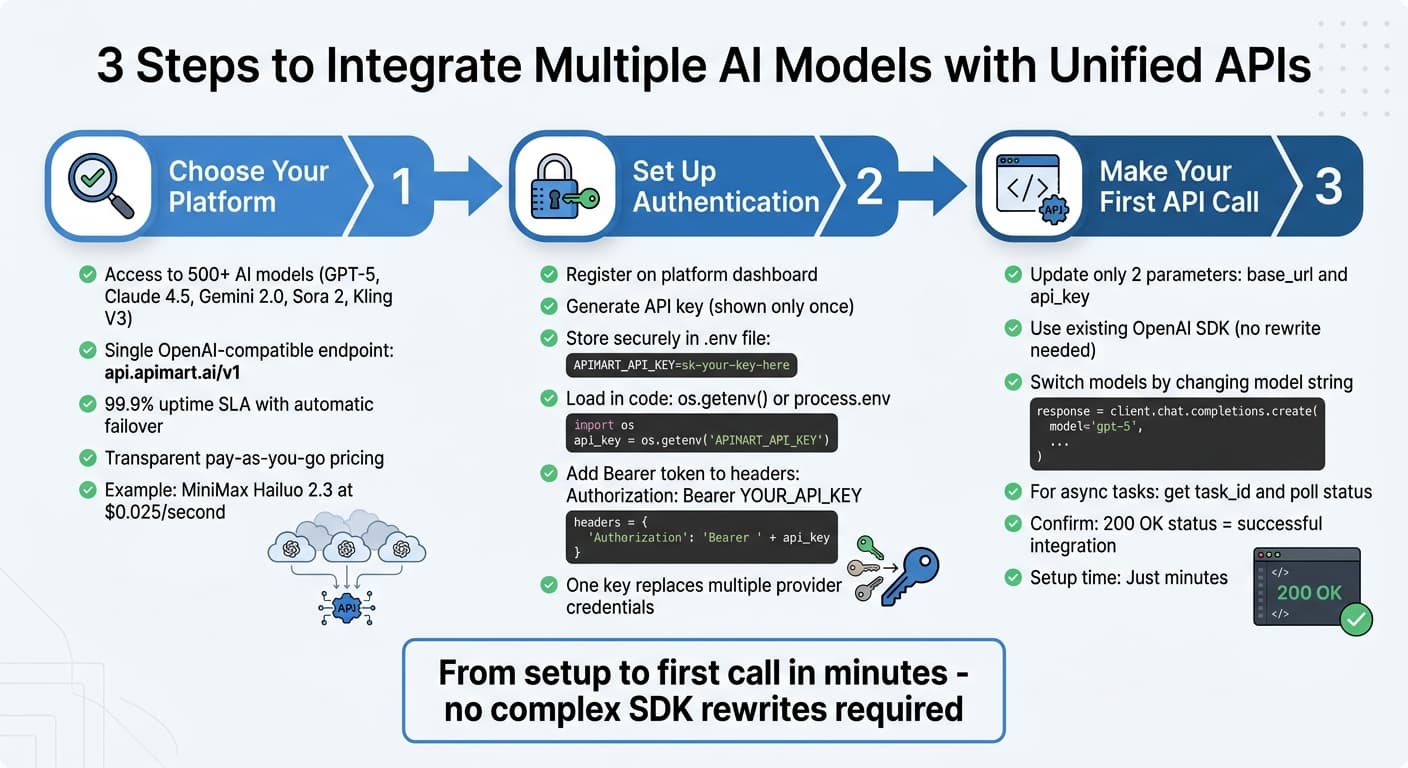
統合API経由で複数モデルをつなぐ流れは、大きく アクセス権の確保 → 環境設定 → リクエスト送信 の3段です。APIMart のようなプラットフォームを使えば、テキスト・画像・動画モデル間の接続を素早く試せます。
プラットフォームの選び方
選定では、モデル幅・分かりやすい価格体系・マルチモーダル対応が揃っているかを確認します。APIMart では GPT-5、Claude 4.5、Gemini 2.0 に加え、Sora 2 や Kling V3 などの動画系モデルも含め、500以上のモデルにアクセスできます。OpenAI互換のエンドポイントは https://api.apimart.ai/v1 です [10]。既存の SDK を活かしたまま、大きな書き換えなしで試しやすいのがポイントです。
稼働率と基盤も見てください。APIMart は99.9%の稼働SLA、自動フェイルオーバー、グローバルCDNによる低遅延を謳っています [10]。従量課金でトークン単価が明示されており、軽いタスクは MiniMax Hailuo 2.3(秒0.025ドル)のようなコスト効率の良いモデルへ、重いタスクは上位モデルへ、と振り分けやすい、という説明もあります [10]。
プラットフォームが決まったら、認証とセキュリティの設定に進みます。
認証とセキュリティの設定
ダッシュボードでアカウント登録し、APIキーを発行して環境変数(例: .env)に安全に保存します。キーは表示が一度きりの場合があるため、すぐに退避してください [9]。ソースコードへの直書きは避けます。
プロジェクトルートに .env を置き、次のように記載します。
APIMART_API_KEY=sk-your-key-here
コード側では、Python なら os.getenv("APIMART_API_KEY")、Node.js なら process.env.APIMART_API_KEY で読み込みます [4]。本番では専用の秘密管理サービスの利用を検討してください。すべてのAPIリクエストでは、ヘッダに Bearer トークンを付けます。
Authorization: Bearer YOUR_API_KEY
この1本のキーで、OpenAI・Anthropic・Google など別々の資格情報を管理する手間を減らせます [9]。キーを安全に置けたら、サンプル呼び出しで動作確認へ進みます。
最初のAPI呼び出し
OpenAI SDK に慣れていれば、base_url と api_key の2点を更新するだけ、という形に近づけることが多いです。GPT-5 を呼ぶ例は次のとおりです。
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.apimart.ai/v1",
api_key=os.getenv("APIMART_API_KEY")
)
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Explain quantum computing in simple terms"}]
)
print(response.choices[0].message.content)
モデル切り替えは model 文字列を変えるだけで足りることが多いです。動画生成など非同期タスクでは、初回レスポンスに task_id が返り、GET /v1/tasks/YOUR_TASK_ID を5〜30秒程度の間隔で叩いて完了を待つ、という流れになります [9]。200 OK と期待どおりの本文が返れば、統合は通っています。401 はキー失効や残高不足などが典型なので、エラーハンドリングを入れましょう [11]。OpenAI SDK に慣れていれば、数分で一通りは終わらせられる構成です。
マルチモデルワークフローの構築(発展的な使い方)
テキスト・画像・動画モデルを統合APIでつなぐと、パイプライン型の高度なユースケースに展開できます。
テキスト・画像・動画モデルの連携
統合APIでは、複数モデルをチェーンしてマルチモーダルな処理列を組めます。複数ステップに分け、各モデルが役割を持つパイプライン設計が一般的です [14]。例: GPT-5 でクリエイティブブリーフを起案 → Flux Pro で画像化 → Kling V3 で動画化、といった流れです。
コスト面では、最初に静的画像で試作・推敲するのが有効です。画像1枚あたり0.02〜0.08ドル程度で反復し、確定後に Sora 2(世代あたり0.10ドル)や Kling 2.6(世代あたり0.04ドル)などで動画化すれば、動画のみでの高コストな試行錯誤 を抑えつつ、見た目の一貫性も保ちやすくなります [15]。
非同期の動画タスクでは task_id で進捗を追い、5〜30秒程度の間隔でポーリングします [13]。レスポンスは標準の JSON 形へ正規化しておくと [14]、テキスト出力を後段の画像・動画モデルの入力パラメータにそのまま渡しやすくなります。JPEG・PNG・WAV などのバイナリは base64 で JSON に埋め込む、という扱いもあります [12]。
マルチモデルパイプラインの性能改善
パイプラインが動いたら、次は性能と費用の最適化です。有効な一手はカスケード型ルーティングです。単純タスクは Gemini Flash(100万入力トークンあたり0.075ドル)のような低コスト側へ、複雑タスクは Claude Sonnet(100万入力トークンあたり3.00ドル)のような上位モデルへ、と振り分けると、コストを60〜80%下げられる、という議論があります [3][14][8]。
リアルタイム用途では 低遅延が決定的 です。30秒かかるモデルは、HTTP 200 が返っても操作体験としては実質使えない、という指摘があります [17]。P95 遅延を監視し、遅延ベースのフォールバック を用意します。asyncio.gather などで 並列実行 し、複数モデルを同時に叩く手もあります [8][14]。
効率化は前処理から始まります。例: 画像を1024〜2048px 程度へ縮小し、分析用途の動画は1秒に1フレーム程度でサンプリングする [1][16]。長い参照文脈を何度も使い回すなら、OpenAI や Anthropic の プロンプトキャッシュ でコストと遅延を抑える方法も検討してください [14]。パイプライン全体では、固定シードやアスペクト比(例: 16:9)を揃え、見た目の一貫性を保つとよいでしょう [15]。
マルチモデル統合のベストプラクティス
本番で安定して回すには、つなぎ込み技術だけでなく、障害・レート制限・コスト暴走への備えが重要です。うまくいくシステムとそうでないシステムの差は、エラー処理と支出管理の設計に出やすいです。
エラー対応とトラブルシューティング
すべてのエラーにフェイルオーバーが必要とは限りません。4xx(例: 400 Bad Request)は入力不正が多く、別プロバイダへ投げ直しても同様に失敗しがちです。フォールバックの主眼は 429(レート制限)や 5xx(サーバエラー)に置く、という整理が推奨されます [17]。
連鎖障害を抑えるにはサーキットブレーカーが有効です。同一プロバイダが連続で失敗したら一時的に送信を止め、クールダウン後にプローブリクエストで復旧を確認します [18]。苦しいプロバイダへ無理に負荷をかけ、レート枠を浪費するのを防げます。
遅延も稼働率と同じくらい重要です。ユーザー向けでは、30秒かかるプロバイダは実質的に使えない—最終的に200が返っても—という見方があります [17]。P95 を追い、主系が遅すぎたら次のリクエストをより速い代替へ寄せる、といった遅延ベースのフォールバックを設計します。
フォールバックが効く理由の一例として、OpenAI は2024年に47件のステータスインシデントがあり、平均すると約8日に1件のペースだった、という整理があります [17]。最初からフォールバックチェーンを構成し、ステージングで APIキーを無効化するなどして、シームレスに副系へ流れるかテストしておくと安心です [3][17]。
| 統合の落とし穴 | 影響 | 対処 |
|---|---|---|
| フォールバックチェーンがない | プロバイダ障害でアプリが止まる | 少なくとも2系統を用意する [17] |
| すべてのタスクに同じモデル | 単純作業まで高コスト | 複雑さに応じてルーティングする [17] |
| エラー区分を見ずにフォールバック | 不要な遅延が増える | 5xx と 429 に限定する [17] |
| レート制限を無視 | 429 が連鎖 | プロバイダ単位で上限を設ける [17] |
エラーと遅延が整理できたら、次はコストのコントロールです。
コストの管理と削減
複雑さに応じたルーティングで最適化します。すべてを GPT-4o や Claude Sonnet に流すと、すぐに費用が膨らみます。分類やデータ抽出のような単純で大量のタスクには、100万入力トークンあたり0.075ドルの Gemini Flash のように、GPT-4o より約33倍、Claude Sonnet より約40倍安い選択肢があります [17]。推論・コードレビュー・創作など重い処理に上位モデルを温存します。
最初から厳しめの予算上限を設けます。APIゲートウェイで日次・時間単位の支出キャップを掛け、無限ループが数時間で月額を食いつぶす事態を避けます [3]。
キャッシュも有効です。繰り返しクエリでは費用を40〜60%削り、応答も速くできる、という報告があります [2][14]。ドキュメントやカタログなど長い参照を何度も使うワークフローに向きます。OpenAI と Anthropic はプロンプトキャッシュをサポートしています。
総額だけでなく、モデル別の成功率・遅延・コストを追います。大半の予算が最上位モデルに偏っているなら、カスケードの条件が意図どおり動いていないサインかもしれません [3][5]。
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Best For |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 汎用・創作寄りのタスク |
| Claude Sonnet | $3.00 | $15.00 | コード・分析 |
| Gemini Flash | $0.075 | $0.30 | 大量処理・コスト重視 |
| GPT-4o mini | $0.15 | $0.60 | 予算重視の代替 |
| Claude Haiku | $0.25 | $1.25 | Sonnet の予算代替 |
最後に、障害が起きてからフォールバックを試すのではなく、APIキーを一時停止するなどして停止をシミュレートし、期待どおりにリクエストが迂回避けされるか確認してください [3][5]。
まとめ:統合APIがAI開発を単純化する理由
複数モデルの運用は負担になりがちですが、統合APIは 1エンドポイント・1 SDK・1枚の請求 に集約します。プロバイダ選びは、一度きりの巨大なアーキテクチャ決定ではなく、設定変更に近い調整へ落ち着きやすくなります [7]。マルチモーダル連携が一本化されることで、ベンダーロックインを和らげ、最小のコード差分でモデル切り替えがしやすくなります。
生産性の面では、2026年初頭にトムソン・ロイターズが統合SDKで法務向け CoCounsel を、開発者3名・約2か月で仕上げた例が引用されています [7]。別々の大工事になりがちな項目を、スケールしやすい形にまとめられる、という話です。
開発速度に加え、運用面の信頼性も伸びます。自動フェイルオーバーや複雑さベースのルーティングは、障害時でも回り続けやすくする助けになります。エンタープライズの37%が本番で5モデル以上を使う、との報告 [7] と、OpenAI の2024年のステータスインシデントが47件(平均して約8日に1件)といった整理 [17] を併せると、フォールバックを持つチームは単一プロバイダ依存に比べ、停止リスクに強い、という読み方ができます。
コスト面でも、基本処理を安価なモデルへ、難しい処理を上位モデルへ、と賢く振り分けられます。予算の集中管理とモデル別コストの可視化で、財務面の見通しも良くなり、インフラに縛られずイノベーションに時間を充てやすくなります [7][17]。
APIMart のようなプラットフォームは、500以上のモデルを OpenAI互換の1本のAPIで開く、という形まで拡張します。マルチモーダルのワークフローでもコスト最適化でも、統合APIは「基盤との格闘」から「プロダクトづくり」へ集中するための土台になります。
よくある質問
リクエストごとにどのモデルを選べばよいですか?
タスク種別、難易度、コスト、信頼性 を軸に決めます。難易度ベースやコストベースのルーティングを入れ、単純作業は安価なモデルへ、重い作業は高性能モデルへ寄せます。主系に問題が出たときのフォールバックもセットで用意し、性能・費用・安定性のバランスを取ります。
テキスト・画像・動画の出力をどう揃えますか?
status、信頼度スコア、モダリティ固有のデータ(テキスト、画像URL、動画メタデータなど)といった共通フィールドをそろえたスキーマを定義します。画像・動画は構造化JSONのメタデータへ正規化し、テキストは統一フォーマットへ揃えます。制御プレーンで変換を監視すれば、モデルをまたいでも予測しやすい出力に寄せられ、後段処理とユーザー体験が安定しやすくなります。
障害やレート制限に対して、最も安全なフォールバックの組み方は?
マルチプロバイダ構成にし、自動フェイルオーバーと継続的なヘルス監視を組み合わせるのが堅いです。APIゲートウェイや制御プレーンでルーティングし、プロバイダの健全性を見て、停止やレート急増時に自動で迂回します。さらに フォールバックチェーン を用意し、主系が失敗したら副系へリトライすることで、停止時間を可能な限り短く保てます。
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。