
マルチモーダルデータセット統合の解説
マルチモーダルデータセット統合の仕組み:テキスト・画像・音声・動画のアライメント、前処理、クロスモーダル整合、ガバナンス、統合APIまで徹底解説。
AIはテキスト・画像・音声・動画など複数種類のデータをまとめて処理できるよう進化しています。 これがマルチモーダルデータセット統合です。単一モーダルモデルが一度に一種類のデータしか扱えないのに対し、マルチモーダルシステムは多様なデータ形式を組み合わせて整合させることで、スクリーンショット・音声メッセージ・チャット履歴が混在するカスタマーサポートケースのような複雑な状況をより深く理解できます。以下が押さえるべきポイントです:
- マルチモーダルデータセット:テキスト・画像・音声など様々なデータ型を整合グループに統合します。例えばキャプション・海の音・ビーチ写真・波のタイム動画がすべて同じシーンを表すように組み合わせます。
- 重要な理由:マルチモーダルデータで学習したモデルは単一モーダルモデルを上回り、動画質問応答などのタスクを20%以上改善します。
- 課題:異なるデータ形式の取り扱い、モダリティ間の情報整合、不完全なデータセットへの対処が挙げられます。
- 解決策:データリミキシング・モダリティマスキング・統合APIなどの技術により統合を効率化し性能を向上させます。APIMartのようなツールはマルチモーダルモデルへのアクセスを簡素化します。
まとめ:マルチモーダルデータセットはクロスモーダル推論を強化することで高度なAI機能を解放します。成功の鍵は高品質なデータアライメント・前処理・ガバナンスにあります。
テキストから動画まで:次世代AIのための統合マルチモーダルデータレイク
マルチモーダルデータセット統合における課題
マルチモーダルデータセットの統合は、さまざまなソースからファイルをマージするほど単純ではありません。本当の課題は、多様なソースを効果的に連携させることにあります。繰り返し現れる3つのハードルが際立っています:データ形式の多様性への対処、クロスモーダルアライメントの確保、欠損または不完全なモダリティへの対応です。
データの不均質性への対処
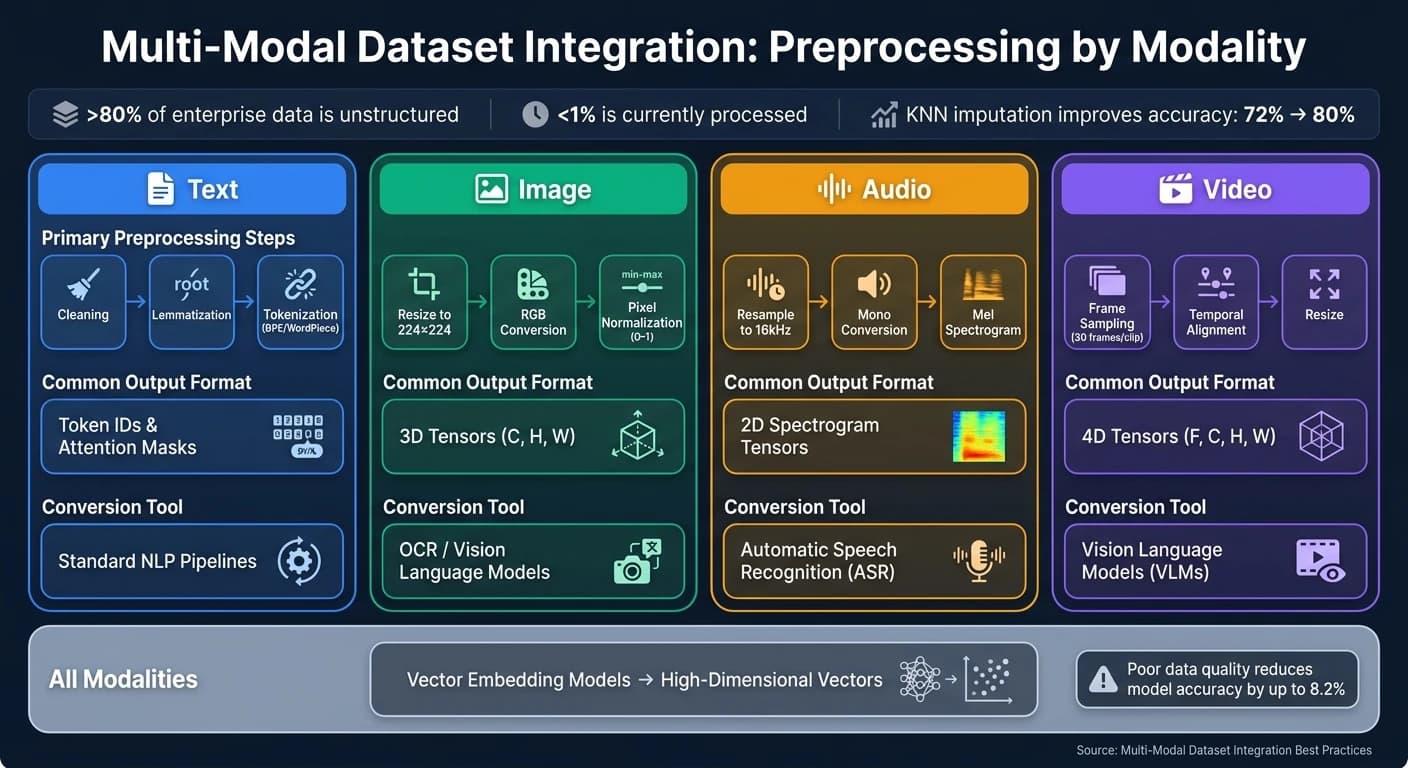
企業データの80%以上が音声・画像・動画などの非構造化形式で存在していることをご存知でしょうか?しかし処理・分析されるのはそのうち1%未満に過ぎません [9]。これはこうしたデータをモデルで使用可能な形式に変換することがいかに難しいかを示しています。
各データ型(モダリティ)にはそれぞれ固有の複雑さがあります。例えば動画ファイルはフレームレートが不統一なことが多く、音声クリップは破損していたり異なる方式でエンコードされていたり、画像解像度は大きくばらつくことがあります。テキストデータも整理されたものからノイズの多いものまで様々です。この混乱を整理するには、音声にはASR、画像にはOCR、動画にはビジョン言語モデル(VLM)などのツールを使って生の入力を統一形式に変換する必要があります [9]。
| モダリティ | 主な変換戦略 | 出力形式 |
|---|---|---|
| 音声 | 自動音声認識 | テキスト/トランスクリプト |
| 画像 | OCR/ビジョン言語モデル | テキスト/説明文 |
| 動画 | ビジョン言語モデル(VLM) | タイムスタンプ付きシーン説明 |
| 全て | ベクター埋め込みモデル | 高次元ベクター |
クロスモーダルアライメントの確保
データを互換性のある形式に変換した後も、モダリティ間で情報を意味的に整合させることはまったく別の課題です。意味ギャップと呼ばれるこの問題は、異なるモダリティの特徴が自然には整合しないことから生じます。
「モダリティ間の意味ギャップは依然として十分に対処されていません。このギャップが適切に管理されないと、ハルシネーションを含む誤った生成が生じる可能性があります。」- Shezheng Song ら、マルチモーダル大規模言語モデルに関する調査 [4]
もう一つの問題はモダリティ怠慢とモダリティ衝突です。共同学習中、モデルは最適化が速いモダリティを優先する傾向があり、他のモダリティは十分に学習されないままになります。研究者のXiaoyu Ma、Hao Chen、Yongjian Dengはこう説明します:
「異なるモダリティは最適化の軌跡(速度やパス)に大きなギャップがあり、マルチモーダルモデルの共同学習時にモダリティ怠慢とモダリティ衝突を引き起こします。」[3]
これに対処するため、「データリミキシング」などの技術を使用してグラジェント方向を整合させることで、CREMADデータセットでは6.50%、Kinetic-Soundsでは**3.41%**の精度向上を実現しました――追加の計算コストなしに [3]。
欠損または部分的なモダリティの管理
実世界のシナリオでは、データセットが完全であることはほとんどありません。例えばデータセットにほとんどのサンプルでテキストと画像が含まれていても、かなりの部分で音声が欠けている場合があります。モデルがこれに対応できなければ、失敗したり最も強いモダリティに過度に依存したりする可能性があります。
一つの解決策はモダリティマスキングで、学習中に欠損モダリティをゼロにすることで、モデルが利用可能なデータから学習できるようにします。モダリティが異なる埋め込み次元を持つ場合、学習可能な投影層によってそれらを共有ベクター空間にマッピングし、不完全なデータでも融合を可能にします [5][7]。Qwen2.5-Omniのような現代的なアーキテクチャはこの柔軟性のために設計されており、「テキスト+音声」や「動画+テキスト」などの組み合わせをシームレスに処理します [6]。
堅牢なマルチモーダルデータセットの構築は容易ではありません。例えばEncordが2025年10月に1億サンプルのデータセットを開発した際、自動クロスモーダルマッチングの検証には976,863件の人間による評価と6,000時間以上の作業が必要でした [1]。これは自動化だけでは十分でなく、人間による検証がプロセスの重要な部分であり続けることを示しています。
これらの課題が、次のセクションで取り上げるベストプラクティスの基盤となります。
マルチモーダルデータセット統合のベストプラクティス
データ収集とスキーマ設計
データを収集する前に、均一なスキーマ標準を確立することが重要です。これにはID・タイムスタンプ・命名規則の一貫した使用が含まれ、データセット間の秩序と互換性を維持します [10]。
効果的なアプローチの一つは、特殊トークン(例:<|__dj__eoc|>)と各モダリティ固有のプレースホルダー(例:<__dj__image>)を使ったインターリーブ形式の採用です。これらのマーカーはメディアパスを専用フィールドに整理するのに役立ちます [8]。フィールドマッピング――{image_uris}のようなテンプレートプレースホルダーを特定のデータセット列にリンクすること――を実装することで、スキーマを柔軟に保ち、常に再フォーマットすることなく様々なジョブタイプに適用できます [11]。
画像のimage_widthsや音声ファイルのaudio_durationなど各モダリティ固有のメタデータを埋め込むことは二重の目的を果たします。品質チェックをサポートし、モダリティ間の前処理を簡素化します。YAMLの設定ファイルはこれらのパラメータを定義するのに特に有用で、バージョン管理が可能になり前処理ロジックを再現できます [8][12]。マルチモーダルプロンプトにおけるデータ品質の低さはモデル性能に大きな影響を与え、精度を最大**8.2%**低下させる可能性があります [12]。そのため早期の品質チェックは価値ある投資です。
均一なスキーマが整ったら、全体の一貫性を維持しながら各モダリティに合わせた前処理を行うことができます。
モダリティ別前処理
各モダリティは統合前に独自の前処理ステップを必要とします。概要を以下に示します:
| モダリティ | 主な前処理ステップ | 一般的な出力形式 |
|---|---|---|
| テキスト | クリーニング、レンマ化、トークン化(BPE/WordPiece) | トークンIDとアテンションマスク |
| 画像 | リサイズ(例:224×224)、RGB変換、ピクセル正規化(0〜1) | 3Dテンソル(C, H, W) |
| 音声 | 16kHzへのリサンプリング、モノ変換、メルスペクトログラム変換 | 2Dスペクトログラムテンソル |
| 動画 | フレームサンプリング(例:30フレーム/clip)、時間的アライメント、リサイズ | 4Dテンソル(F, C, H, W) |
音声は16kHzモノに標準化します。画像の場合は、生の0〜255の範囲のピクセル値を255.0で割り、ニューラルネットワークが効率的に処理できる0〜1の範囲にスケーリングします。動画は、フレームシーケンスを固定長にパディングまたはトランケーションしてバッチ処理を効率化します。KNNなどの方法で欠損データに対処することで、産業用途でのモデル精度が**72%から80%**に向上することが示されています [12]。
「クリーンなデータはモデルが信頼性が高く一貫した情報で動作することを保証し、正確なデータからの推論を助けます。」- Latitude Blog [12]
これらの前処理ステップにより標準化された出力が生成され、モダリティ間の効果的なアライメントへの準備が整います。
クロスモーダルアライメント技術
大規模言語モデル(LLM)はモダリティを橋渡しするユニバーサルインターフェースとして機能できます。画像テキストや音声テキストの組み合わせなど言語ペアデータを活用することで、動画・音声・テキストの三つ組のような希少なマルチウェイペアサンプルへの依存を避けられます [2]。
「言語は汎用アシスタントのユニバーサルインターフェースとして機能できます。様々なタスクを言語で明示的に表現し応答できます。」- Zijia Zhao ら、中国科学院自動化研究所 [2]
時間的アライメントには、**音声視覚トークンインターリービング(AVTI)**が有用な手法です。これは動画と音声の埋め込みを内部順序を保ちながら単一のインターリーブシーケンスに結合します。これによりLLMは時間的同期を失わずに両モダリティを統一コンテキストとして処理できます [13]。モダリティ埋め込み間の幾何学的不整合に直面した場合、ReAlign戦略が助けになります。この学習不要の手法は一次統計を調整し、追加学習なしにセントロイドドリフトを修正します [14]。これらの技術を組み合わせることで、様々なサイズのデータセットに適したスケーラブルなアライメントワークフローが実現します。
マルチモーダルデータセットを活用した技術とユースケース
整合された十分に準備されたマルチモーダルデータは、高度なAI技術と実用的な応用への扉を開きます。
共同埋め込みとコントラスト学習
データセットが整合・前処理されると、テキスト・画像・音声などのフォーマットを統一ベクター空間にマッピングする共同埋め込みなどの技術が可能になります。この空間では、意味的に関連するコンテンツが元の形式に関わらず集まります。
重要な手法はコントラスト学習で、InfoNCE損失を使用してマッチするペアを近づけ、マッチしないペアを遠ざけます。このアプローチはバッチ内ネガティブから恩恵を受け、バッチあたりO(N²)の学習シグナルを生成します。OpenAIのCLIPモデルはこれを最大限に活用し、32,768ペアまでのバッチサイズを使用して、文脈は似ているが意味が異なる「ハードネガティブ」への露出を最大化します [15]。
ただしモダリティギャップが生じることがあります。これは異なる形式の埋め込みが別々にクラスター化する現象です。GR-CLIP技術は平均埋め込みを引くことでクラスターを再中心化し、標準CLIPと比較して検索性能(NDCG@10)を最大26パーセントポイント改善します。さらに、生成的埋め込み手法と比べて75倍少ない計算量でこれを達成します [16]。
これらの埋め込み戦略はモダリティ間のより深いつながりの基盤を築きます。
クロスモーダルアテンション機構
クロスモーダルアテンションは、画像のある領域を特定の単語に関連付けることで、画像とテキストのような異なるモダリティを連結します。トランスフォーマーベースのアーキテクチャは様々な形式を共有意味空間に変換することでこれを実現し、距離が意味を一貫して反映するようにします。
Perceiver モジュールはクロスアテンションを使用して複数のエンコーダからの可変長埋め込みを固定クエリトークンのセットに凝縮することでこれを体現しています。このアプローチは大型マルチモーダルモデルの計算コストを削減します。一方、Emu3のようなデコーダのみのアーキテクチャはすべてのモダリティを単一のトークンシーケンスとして扱い、画像生成や動画再構成などのタスクで優れています。例えばEmu3は単体画像トークナイザーの4倍少ないトークンを使用しながら優れた動画再構成(rFVD:27.893 vs. 139.930)を達成します [18]。多様なデータセットでの指示チューニングにより、MSVDQAなどの動画質問応答ベンチマークでの精度がさらに**21.8%**向上しました [2]。
業界別応用
これらの高度な技術は様々な業界で変革を推進しています。
医療では、X線・放射線科医のメモ・患者の音声説明などのデータを統合データセットに組み合わせることで診断精度が向上しています。遠隔医療プラットフォームは現在このようなデータを使用して、動画・音声・患者記録を統合した自動化された事前訪問サマリーを作成しています [17]。
eコマースでは、クロスモーダル埋め込みが革新的なショッピング体験を可能にしています。例えばテキストの代わりに写真を使って検索できます。画像は商品説明や動画デモと同じベクター空間にエンコードされ、コサイン類似度による結果の検索を可能にします [15]。APIMartのようなプラットフォームは画像・動画・言語にわたる500以上のモデルに接続するsingle APIを提供することでこのプロセスを簡素化し、クロスモーダル検索とコンテンツ生成をアクセスしやすくします。
教育では、動画講義と自動生成されたトランスクリプト・構造化メタデータを組み合わせることで、インテリジェントチュータリングシステム・検索可能な動画ライブラリ・パーソナライズされたコンテンツレコメンデーションが可能になります。この分野は二項モーダルシステム(画像+テキスト)から音声と3Dポイントクラウドを含む五項マルチモーダルセットアップへと拡大しています。5タプルから構築された1億サンプルのデータセットはすでにモデルが同時に「聞いて」「見る」ことを可能にしています [1]。
「CLIPのようなモデルがテキストとビジョン以上のものを処理できたらどうなるでしょう?音声を聞き周囲を感知できたら?」- Frederik Hvilshøj、MLリード、Encord [1]
マルチモーダルデータセットのガバナンスと運用
本番環境でのマルチモーダルデータセットの管理は、単なる技術的統合にとどまりません。再現性と法的基準への準拠を確保するための厳格なガバナンスが必要です。モデルが稼働したら、データ使用を追跡し、機密情報を保護し、監査可能性を維持するシステムが必要です。
データセットのバージョン管理と系譜
マルチモーダルデータセットが複雑になるにつれ、その起源を追跡することが不可欠になります。重要な課題は再現性――学習に使用されたデータを正確に把握することは問題のデバッグに不可欠です。
これに対処するため、バージョン管理されたマニフェストに保存された各学習サンプルにSHA-256ハッシュを使用します。モダリティレベルで依存関係を追跡することで、特定の領域への更新を限定できます。例えば、顔認識ステップが動画フレームのみに依存している場合、音声パイプラインの変更があってもデータセット全体の再処理は不要です。Metaxy(2026年5月更新)などのツールはこのターゲット指定の依存関係追跡をサポートし、不必要な再学習の手間を削減します [21]。
データセットスナップショットをモデル学習実行にリンクすることも重要な実践です。Weights & BiasesやMLflowなどのツールはデータと結果の間のループを閉じるのに役立ちます。EntrapeerのCo-FounderであるEren Hukumdarはこう説明します:
「各モデル学習実行は現在ユニークなスナップショットIDに紐付けられているため、どのデータがどの結果を生んだかを常に把握できます。以前は数週間かかっていたデバッグがデータセットバージョンについての曖昧さがゼロになったため数時間で完了するようになりました。」- Eren Hukumdar、Co-Founder、Entrapeer [20]
チームサイズに基づくガバナンス実践の簡単な比較を示します:
| ガバナンスレベル | 最適対象 | 主要ツール | トレードオフ |
|---|---|---|---|
| 軽量 | 小規模チーム(5名未満、10万サンプル未満) | CSVマニフェスト、SHA-256 | スケーラビリティ制限、強制なし [19] |
| 中規模 | 中規模チーム(5〜30名、10万〜1000万サンプル) | DVC、lakeFS | セットアップ工数が高く、プロセスが遅くなる可能性 [19][20] |
| エンタープライズ | 大規模チーム(30名以上、規制産業) | イミュータブル監査証跡、RBAC | 複雑なセットアップ、6〜12週間のロールアウト [19] |
プライバシー・セキュリティ・コンプライアンス
マルチモーダルデータセットには多くの場合、動画内の顔・音声中の声・文書内の個人情報など機密情報が含まれています。このデータを誤って取り扱うと、特にグローバルな基準が厳格化する中で法的・規制上の問題につながります。
これらのリスクを軽減するため、合法的なデータ収集を確保し、適切な使用権を確認し、削除ログや署名付きイベントを通じてコンプライアンスの証明を維持する多層的なコントロールを実装します [26]。すべてのデータインジェストジョブで、ソース識別子とチェックサムを含む署名付きイベントを発行します。入力データに有効な権利根拠がないかマニフェストエントリが欠落している場合は、未検証データが学習プールに入るのを防ぐため即座にパイプラインを停止します [23][25]。
44の主要なファインチューニングデータセットの監査では、70%以上が明確なライセンスを欠いており、ライセンス分類のエラーが50%を超えていたことが明らかになりました [22]。これは特にEU AI Act(2024年8月施行、2025年8月から強制適用)のような規制において深刻なコンプライアンスリスクをもたらします。同法令は汎用AIシステムの学習データに対して文書化されたガバナンスを義務付けています [22]。
「完璧にフォーマットされたデータセットでも、権利根拠が無効であったり来歴を示せなかったりすれば使用できません。」- Daniel Mercer、シニアAIガバナンスエディター [23]
マルチモーダルデータセットでは系譜グラフが特に有用です。単一の動画ソースからトランスクリプト・個別フレーム・埋め込みを生成でき、それぞれが派生物として扱われます。系譜グラフはこれらの関係を追跡し、ソースアセットが削除された場合にすべての派生物を効率的に削除できるようにします [24]。
ガバナンスの実践が確立されたら、焦点はスムーズな運用パフォーマンスの確保に移ります。
統合APIによるマルチモーダルモデルの運用
良いガバナンスはスケーラブルで信頼性の高いワークフローを支えます。本番システムは各モダリティに対して別々の統合を必要とせずに、複数のモダリティにわたってレート制限・モデル可用性・コスト管理を処理する必要があります。
APIMartのようなプラットフォームは言語・画像・動画にわたる500以上のモデルに接続する単一APIを提供することでこのプロセスを簡素化します。統合クレジットシステムにより、チームはコストを簡単に予測でき、複数のベンダーとの別々の請求関係を管理する必要がありません。GPT-5・Claude・Sora・Kling V3などのモデルが同じエンドポイントからアクセスできるため、モデルを切り替えたり追加したりするたびにマルチモーダルパイプラインを再構築する必要がありません。複雑な本番ワークロードを実行するチームにとって、この運用の一貫性はエンジニアリングのオーバーヘッドを削減し、統合問題のリスクを最小化します。
まとめ
マルチモーダルデータセットの統合は容易ではありませんが、その恩恵は十分に努力に値します。トップパフォーマンス企業の40%以上がマルチモーダルシステムを使用しており [17]、サポートチケットの解決時間が最大35%短縮されたと報告しています [17]。これらの結果は実世界のマルチモーダルデータでモデルを改善しようとするチームに強いベンチマークを示しています。興味深いことに、適切に準備されたデータセットは生のパラメータ数が4倍大きいモデルを上回ることさえあります [1]。
ここでの結論は明確です:データ品質とアライメントは単純な規模よりも重要です。Nature Machine Intelligenceが的確に述べているように:
「マルチモーダルAIのボトルネックはモデルサイズではなく、基礎となるデータの品質とアライメントである。」[17]
これを実現するには規律あるアプローチが必要です:思慮深いスキーマ設計・各モダリティに合わせた前処理・効果的なクロスモーダルアライメント・厳格なガバナンス。実践的な最初のステップは?中間融合戦略を採用することです――中間層でモダリティデータを組み合わせます。これによりパイプラインがモジュール化され、ニーズの変化に応じてデバッグや適応が容易になります [27]。
さらに、非同期並列処理はデータインジェストの待機時間を40%〜60%大幅に削減でき、画像圧縮やフィーチャーキャッシングなどの技術を通じた統合ゲートウェイはAPIコストを60%〜80%削減できます [27]。APIMartのようなツールはGPT-5・Sora・Claude・Kling V3を含む500以上のモデルをサポートする単一APIを提供することでこのプロセスを簡素化し、チームがモデルの更新ごとにパイプラインを全面的に見直すことなく一貫したインターフェースを維持できるようにします。
よくある質問
モダリティのアライメントを確保するにはどうすればよいですか?
モダリティを効果的に連携させるには、モダリティが_共通の意味空間_を共有することが重要です。簡単に言えば、形式や媒体に関わらずコンセプトを一貫して表現する必要があります。
アライメントを維持する方法は以下の通りです:
- 構造化された品質チェック:アノテーターのセルフレビュー・クロスモーダルの一貫性を確保するピアレビュー・最終的な監視のためのシニア監査などのプロセスを使用します。
- 定量的指標:**カーネルアライメント中心化(CKA)**などのツールは特徴セット間の関係を測定でき、モダリティのアライメントの良さを評価するのに役立ちます。
- 統合プラットフォーム:APIMartのようなソリューションはマルチモーダル入力を処理でき、プロジェクト内で多様なデータ型を統合して操作しやすくします。
これらのステップに集中することで、異なるモダリティ間でシームレスで一貫したエクスペリエンスを構築できます。
モダリティが欠損している場合はどうすればよいですか?
欠損データ型(モダリティ)に効果的に対処するには、適応し機能を維持できるシステムを構築することが重要です。グレースフルデグラデーションや知識転移などの戦略は特定の入力が利用できない場合でもシステムの信頼性を維持するのに役立ちます。
学習中は、モダリティドロップアウトなどの技術を使って欠損入力をシミュレートすることでモデルが不完全なデータを処理できるよう準備できます。または教師・生徒フレームワークを使用してシステムがこれらのギャップを効率的に管理できるよう学習させることもできます。
本番環境では、補間やウィンドウイングなどのフォールバック機構を実装して欠損データを補完したりワークフローを動的に調整したりできます。APIMartはマルチモーダル入力を処理できるように設計されており、様々なデータシナリオを一貫性と信頼性を持って管理できるワークフローを設計することが可能です。
マルチモーダル学習データにはどのようなガバナンスが必要ですか?
マルチモーダル学習データの効果的なガバナンスには、データ来歴への細心の注意が必要です。これにはデータの収集方法の文書化・同意状態の確認・削除が必要な条件の特定が含まれます。
重要な実践には、クロスモーダルアライメントの確保(画像が対応するテキストや音声と適切にペアリングされていることの確認など)が含まれます。さらにライセンスコンプライアンスの管理は法的問題を避けるために不可欠です。
組織は品質保証を優先し、徹底した監査証跡を維持する必要があります。これらの措置はGDPR削除要求・著作権紛争・セキュリティ監査などの課題に対処するのに役立ちます。これにより、モデルのライフサイクル全体を通じて透明性と精度を維持できます。
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。