
マルチモデルAPI vs シングルモデルのコスト分析
マルチモデルとシングルモデルのAPIコストを比較 — 利用率、統合・保守のオーバーヘッド、階層型ルーティングを踏まえて、総コストが低い方を見極める。
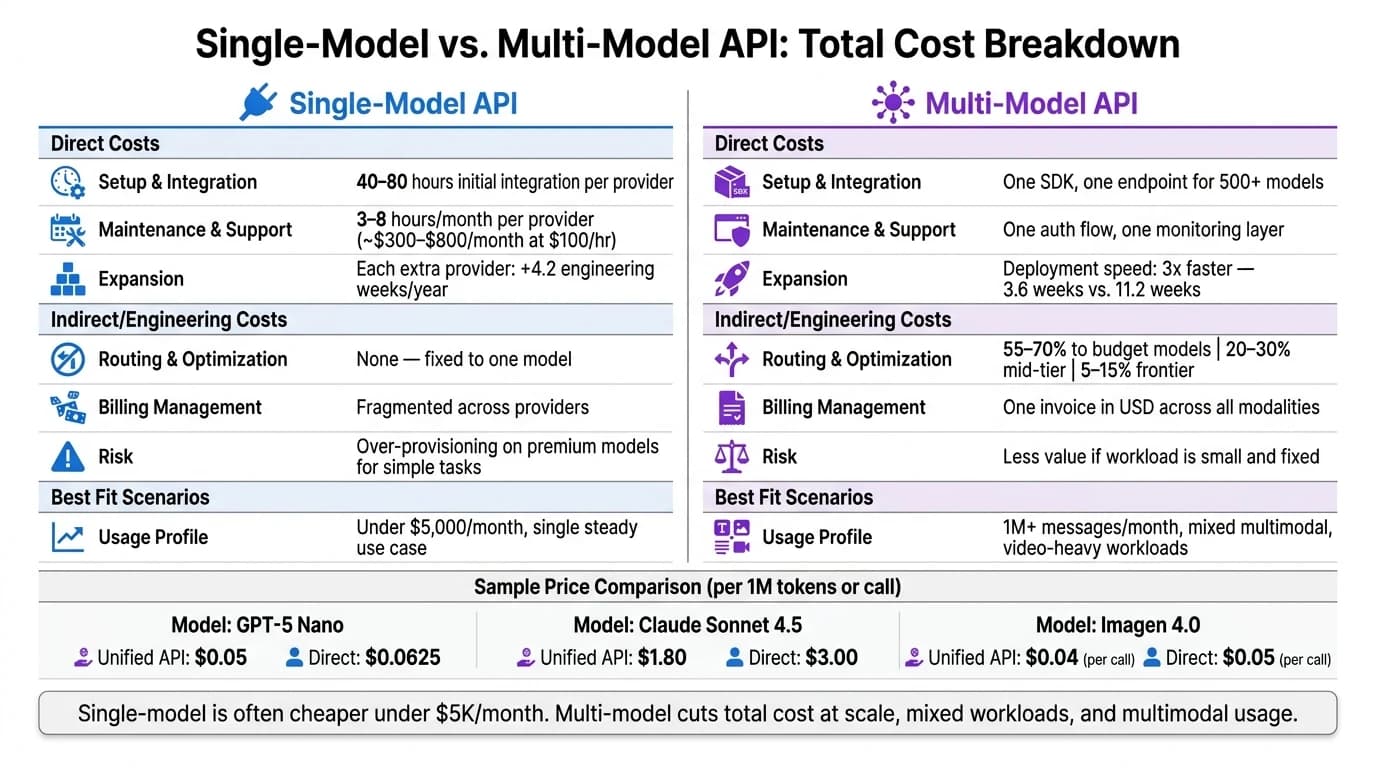
APIの表示価格だけを見ていると、請求額の最も大きな部分を見落としかねません。 この比較では、$5,000/month 未満の安定した単一タスクなら シングルモデル の方がコストが低くなることが多く、一方で混在ワークロード、マルチモーダル利用、または大量利用の場合は マルチモデル が勝つことが多くなります。
要点を短くまとめると、次のとおりです。
- シングルモデル とは、1つのプロバイダー、1つのSDK、1つの請求設定を意味します。
- マルチモデルAPI とは、多数のモデルにまたがってリクエストを送れる1つの統合を意味します。
- ダイレクトAPIの価格はコストの一部にすぎません。
- 隠れたコストは多くの場合、次から発生します。
- エンジニアリングのセットアップ
- 月次の保守
- セキュリティ・コンプライアンスのレビュー
- 請求・ベンダー管理
- ダイレクトなプロバイダー作業には プロバイダーごとに月あたり3〜8時間、つまり $100/hour 換算で約 $300〜$800/month かかることがあります。
- 最初のダイレクト統合には 40〜80時間 かかることがあります。
- プロバイダーを1つ追加するごとに、年間で約 4.2エンジニアリング週 が加わることがあります。
- マルチモデル構成を使うチームは、本番エージェントを約 3倍速く 出荷しました。すなわち 3.6週 vs 11.2週 です。
- モデル層ごとに作業をルーティングすると、次のように支出を削減できます。
- 55〜70% を低コストモデルへ
- 20〜30% を中位層モデルへ
- 5〜15% をフロンティアモデルへ
- 利用料金については、記事内で統合アクセスの方が低くなった例を示しています。
- GPT-5 Nano: 100万入力トークンあたり $0.05 vs. $0.0625
- Claude Sonnet 4.5: $1.80 vs. $3.00
- Imagen 4.0: 1コールあたり $0.04 vs. $0.05
一言でまとめるなら、こうです。シングルモデルは小規模で範囲が固定されている場合に安くなることが多く、マルチモデルはスケール、ルーティング、チームの時間が重要になってくると総コストを削減することが多い。
LLMアプリのコスト最適化テクニック - より速く、より安く、スケーラブルなAI | Uplatz
クイック比較
| 基準 | シングルモデル統合 | 統合マルチモデルAPI |
|---|---|---|
| セットアップ | 1つのダイレクトプロバイダー接続 | 多数のモデルへの1つの接続 |
| 用途への適合 | 安定した単一ユースケースに最適 | 混在・成長するワークロードに最適 |
| 請求 | 1プロバイダーの請求書 | モデルをまたぐ1つの請求書 |
| 価格/品質によるルーティング | 不可 | 可 |
| プロバイダー追加作業 | プロバイダーごとに増加 | 1つのレイヤーに集約 |
| エンジニアリングのオーバーヘッド | 当初は低く、その後増加 | 範囲拡大時に低い |
| コスト面で最適なケース | $5,000/month 未満の固定タスク | 1M+ messages/month、マルチモーダル、動画中心 |
| 主なリスク | 単一プレミアムモデルで簡単なタスクに過剰支払い | ワークロードが小規模かつ固定なら価値が薄い |
この記事は、レートカードだけの判断ではなく、総コストで判断するために使うのがよいでしょう。
シングルモデル統合のコスト構造
ダイレクトコスト:狭いワークロードの利用料と請求
シングルモデル統合は請求をシンプルに保ちます。1つのプロバイダー、1つの価格設定です。主要ユースケースが1つの初期段階のプロダクトなら、そのシンプルさは役立ちます。請求書は1つ、レートカードも1つ、可動部分も少なくなります。
とはいえ、シンプルであることが常に安いとは限りません。利用が急増すれば、超過料金が発生することがあります。そしてエンタープライズレベルでは、最低利用コミットメントを求めるプロバイダーもあります。この構成は、需要が狭く予測しやすい場合に最も適しています。
間接コスト:統合、保守、コンプライアンス作業
請求書は全体像の一部にすぎません。支出の多くはその外側にあります。
中規模チームがプロバイダーをダイレクトに統合する場合、40〜80時間の初期統合作業 が見込まれます [2]。それは通常、アダプターコードの記述、429や5xxレスポンスといったプロバイダーエラーへの対応、リトライロジックの設定、APIキーのローテーション対応を意味します。これが統合税です。
しかも、それはローンチ後も終わりません。モデルの更新は依然として注意を要します。監視も依然としてエンジニアリングの時間を消費します。コンプライアンス作業もさらなる工数を追加しかねません。加えて、シングルモデル構成はデータの露出を1つのベンダーの手に集中させ、集中リスクを高める可能性があります。
シングルモデルが安いときと高くつくとき
シングルモデル構成は、ワークロードが安定していて狭いときにコスト効率を保ちます。それがスイートスポットです。
問題が始まるのは、チームが簡単なものまで含めてすべてのタスクを1つのプレミアムモデルに通すときです。そこから過剰プロビジョニングが支出を圧迫し始めます。そしてプロダクトの範囲が広がると、個別のプロバイダー統合が急速に積み上がりかねません。ダイレクトプロバイダー統合を1つ追加するごとに、初期セットアップと継続的な保守で推定 4.2エンジニアリング週 を消費します [1]。そのオーバーヘッドはあっという間に積み上がります。
ワークロード別に見ると、傾向は次のようになりがちです。
| シナリオ | シングルモデルのコスト挙動 |
|---|---|
| 安定したユースケース、低ボリューム | 低コストで予測しやすい |
| 安定したユースケース、トラフィックの急増 | 超過料金と最低コミットメントのリスク |
| 1つのプレミアムモデルで複数タスク | 過剰プロビジョニングが支出を押し上げる |
| 時間とともに統合が増加 | 保守が増え、請求がより分断される |
シングルモデル構成は多くの場合、無駄なくスタートします。しかし範囲が広がるにつれ、コストもそれとともに上昇しかねません。次のセクションでは、これらのコストをワークロードのタイプ別に比較します。
統合マルチモデルAPIのコスト構造
統合アクセスと柔軟なモデル選択によるダイレクトな節約
シングルモデル構成は、チームが結局オーバーバイしてしまうため、本来より高くつくことがよくあります。統合APIはそれを変えます。すべてのタスクを同じモデルに送る代わりに、簡単な作業を低コストモデルに送り、より強力なモデルは本当に必要な仕事のために取っておけます。
これはコストを2つの明確な形でシフトさせます。ルーティンなタスクはより安いモデルへ、難しいタスクは必要なときだけプレミアムモデルを使う、という形です。実際、このようなルーティングは支出を有意義に削減できます。
請求もシンプルになります。テキスト、画像、動画の利用がすべて 1つの請求書(USD) に表示されるため、財務側の整理は減り、ベンダー間で請求を突き合わせる時間も減ります。
エンタープライズのトークンコストは 2026年4月までに前年比67%低下 しました。これは主に、低コストの選択肢で仕事が足りるときに高価なフロンティアモデルから作業をルーティングして離したチームによって牽引されました [1]。よくある構成の1つは、階層型スタックです。
- トラフィックの 55〜70% をコスト効率モデルへルーティング
- フロンティアモデルには 5〜15% だけを確保 [1]
多数のモデルにまたがる1つの統合による間接的な節約
シングルモデルシステムのセットアップ負担は、チームがプロバイダーを増やしても消えません。むしろ悪化します。新しいプロバイダーごとに、別の認証フロー、別の監視設定、別のガバナンス経路、そしてもう一巡の保守が必要になりかねません。
統合APIは、その雪だるま効果を早期に止めます。1つの認証フロー、1つの監視レイヤー、1つのガバナンスレイヤーをセットアップするだけです。一度作れば、API背後のあらゆるモデルで機能します。
これが重要なのは、統合のオーバーヘッドが新しいプロバイダーを追加するたびに増えるからです。統合レイヤーがあれば、その作業は多数に分散されるのではなく、1つの接続に集約されます。
マルチモデルインフラを使うチームは、本番AIエージェントを 3倍速く デプロイします。すなわち 3.6週 vs 11.2週 です [1]。配管作業に費やす時間が減れば、出荷に使える時間が増えます。
このモデルの実践例としての APIMart
プラットフォームの例を見ると、価格差が見つけやすくなります。
APIMartは、統合アクセスが日々どう機能するかを示しています。1つのAPI、1つの請求フロー、そしてテキスト・画像・動画にまたがるモデルへのアクセスです。
その動画モデルのラインナップも、なぜルーティングが重要かを示しています。MiniMax Hailuo 2.3 Fast は $0.025/second で、高速かつ低コストの選択肢になります。Kling V3 Omni は $0.0672/second (720p) で、中位層の価格でシネマティックな出力に適しています。Sora 2 Preview は $0.08/second で、品質とコストのバランスを取ります。Vidu Q3 Pro は $0.12/second で、より要求の高いハイパフォーマンス生成に適しています。
| モデル | 価格 | 最適な用途 |
|---|---|---|
| MiniMax Hailuo 2.3 Fast | $0.025/sec | 高速・低コストの動画生成 |
| Kling V3 Omni (720p) | $0.0672/sec | シネマティックなビジュアルと中位層コスト |
| Sora 2 Preview | $0.08/sec | 品質とコストのバランス |
| Vidu Q3 Pro | $0.12/sec | 複雑・ハイパフォーマンスな生成に最適 |
| 統合マルチモデルAPI | シングルモデル統合 | |
|---|---|---|
| 請求 | USDで1つの請求書 | プロバイダーごとに分断 |
| 統合作業 | 1つのSDK、1つのエンドポイント | プロバイダーごとに固有のセットアップ |
| ルーティングの柔軟性 | コストまたは品質でルーティング | 1つのモデルに固定 |
| 更新 | プロバイダーの更新を一元管理 | プロバイダーごとに手動更新 |
| 最適な用途 | 混在・成長するワークロード | 単一タスク・低ボリュームのアプリ |
次のセクションでは、これらの節約をワークロードのタイプ別に比較します。
ワークロードタイプ別のダイレクトコスト比較
この比較で使うコスト指標
コストは、実行している作業の種類と結びつけて初めて意味を持ちます。
比較すべき主要な数値は、100万入力トークンあたりのコスト、画像1コールあたりのコスト、動画1秒あたりのコスト、そして 月間USD支出 です。これらを見れば、表示価格だけを見るよりもはるかにワークロードの総コストを把握できます。
いくつかの例で差が明確になります。GPT-5 Nano はAPIMart経由で 100万入力トークンあたり$0.05 に対し、ダイレクトでは $0.0625 です。Claude Sonnet 4.5 は $1.80 に対し $3.00 です。Imagen 4.0 は 1コールあたり$0.04 に対し $0.05 です。小規模なプロジェクトでは大きく感じないかもしれません。スケールすれば、あっという間に積み上がります。
シングルモデルの方が安くなることが多いワークロード
狭く予測可能なワークロードでは、ルーティングはあまり役に立たないことが多いです。
社内の単一の要約パイプラインや、入力サイズが安定した固定範囲のワークフローを思い浮かべてください。月間支出が $5,000未満 に収まり、タスクが変わらないなら、複数モデルにまたがってルーティングする日々の価値は通常あまりありません。その構成では、ダイレクト統合が低コストな経路になることが多いです。
マルチモデルの方が総支出を下げることが多いワークロード
ボリュームが増え、複数のモダリティが絡み始めると、ルーティングが重要になってきます。
混在かつ大量のワークロードは、計算を変える傾向があります。チームがテキスト、画像、動画を生成している場合、あるいは 月間100万件以上のチャットメッセージ を処理している場合、タスクが異なるユースケースに広がるにつれてコストが上昇します。そこがマルチモデル構成で費用を節約できる場面です。簡単なリクエストは低コストモデルに送り、プレミアムモデルは難しい仕事のために取っておきます。
| ワークロードカテゴリ | 月間支出の推定 | 主なコスト要因 | 低コストになりやすいアプローチ |
|---|---|---|---|
| 大量チャット(1M+ messages/month) | $10,000〜$25,000 | 出力トークン量、推論トークン | マルチモデル(簡単なタスクをバジェットモデルへルーティング) |
| 混在マルチモーダル(テキスト+画像+動画) | $15,000+ | マルチモーダルの計算 | マルチモデル(請求を統合、単一SDK) |
| 動画中心のクリエイティブ(100+ hrs/mo) | $25,000+ | 秒あたりのレンダリング料金 | マルチモデル(プレミアム動画モデルで最大20%節約) |
| 安定した社内ツール(要約) | $5,000未満 | 固定的な利用、低い複雑性 | シングルモデル(ルーティングの柔軟性が不要なら) |
予算フレームワークと最終判断ガイド
米国チーム向けのステップバイステップ予算策定法
上記のワークロードパターンを使って、価格を予算の判断に変えます。この方法は3ステップです。
まず ベースラインコスト から始めます。最初に全トラフィックを1つのプレミアムモデルで価格計算します。これにより上限が得られ、他のルーティング構成をテストする前に見込まれる最大支出を把握できます。
次に、階層型ルーティングコスト を計算します。トラフィックの 55〜70% をコスト効率モデルへ、20〜30% を中位層モデルへ送り、複雑な推論を要する 5〜15% のタスクにはフロンティアモデルを取っておきます。そして各層を総量に占める割合とトークンあたり単価で重み付けし、低コストなミックスを算出します。
続いて 総コスト を計算します。両方の選択肢にエンジニアリングのオーバーヘッドを加えます。プロバイダー統合を1つ追加するごとに、年間で約 4.2エンジニアリング週 が加わります [1]。その時間には金額換算のコストがあり、判断を素早く変えかねません。
利用料とオーバーヘッドを加えたら、より良い選択肢は 月間の総コスト が低い方です。
シングルモデルを選ぶときとマルチモデルを選ぶとき
シングルモデル構成は、安定した単一ユースケースがあり複雑性が低いときに最も適しています。よりシンプルで、管理しやすく、狭いニーズには十分なことが多いです。
マルチモデル構成は、ワークロードが混在している、利用が成長している、または冗長性が重要なときにより意味を持ちます。一部のタスクが簡単で他が深い推論を必要とする場合、モデル層をまたいで作業をルーティングすれば、身動きが取れなくなることなく支出を削減できます。
APIMart は 500以上のモデル にまたがる1つのAPIを提供し、AI利用が拡大するにつれて重複する統合作業を削減します。
結論:最も安い請求書が、常に最も安い総コストとは限らない
1つのモデルの低いトークン単価は、スプレッドシート上では素晴らしく見えます。しかしその数値は請求額の全体を示していません。統合の時間、保守のサイクル、フェイルオーバーのロジックはすべてコストを追加します。統合マルチモデルアクセスは、そうした隠れたコストの多くを設計上、削減する助けになります。
重要なポイント:
- 利用料は総コストの一部にすぎません。
- 階層型ルーティングは、ワークロードが混在またはマルチモーダルなときに支出を削減します。
- 統合のオーバーヘッドは、プロバイダーを追加するごとに増加します。
- シングルモデルは、安定した狭いユースケースに適しています。
- マルチモデルは、成長するマルチモーダルなワークロードに適しています。
よくある質問
API価格を超えた総コストはどう計算すればよいですか?
少しの間、トークン価格の先を見てみましょう。より大きな流出は多くの場合、複数プロバイダーをやりくりする日々の作業から生じます。
それは単にAPI利用料を支払うことだけではありません。アダプターレイヤーの構築、エラーハンドリングへの対応、カスタムリトライロジックの記述、そしてバラバラのAPIキーの管理に費やされる追加のエンジニアリング時間です。その作業はあっという間に積み上がります。多くのチームで、統合の保守だけで 月あたり15〜20時間 かかります。
セキュリティもさらなるコストの層を加えます。アクセストークンが異なるベンダーに分散していると、ガバナンスは難しくなります。孤立したキーが残りやすくなり、誰もすぐには気づかない無駄な支出やコスト漏れにつながりかねません。
APIMart のような統合プラットフォームは、それらの可動部分を1つのダッシュボードにまとめ、アクセス制御と支出の追跡をはるかに管理しやすくしつつ、手作業のオーバーヘッドを削減できます。
マルチモデルAPIはいつ1つのモデルより安くなりますか?
マルチモデルAPIは、画一的な構成ではなく インテリジェントなタスク-モデルルーティング を使うときに安くなります。
基本的な考え方はこうです。分類、要約、データ抽出のようなより単純な仕事は低コストモデルに送ります。そしてプレミアムモデルは、より複雑または重要度の高い仕事のために取っておきます。この1つの切り替えだけで、AIコストを 30%〜80% 削減できます。
APIMartは 500以上のモデル へのアクセスに加え、統合請求、ボリューム価格、AIワークロード全体にわたる集約割引によって、これを容易にします。
どのワークロードがモデルルーティングの恩恵を最も受けますか?
モデルルーティングは、タスクの難易度がリクエストごとに変わる 大量かつコスト感度の高い ワークロードで最も効果を発揮します。基本的な考え方はシンプルです。簡単な作業は低コストモデルに送り、フロンティアモデルは難しいもののために取っておきます。
そのため、分類、タグ付け、要約、バックグラウンドのエンリッチメントのような作業にはルーティングが強く適合します。これらのケースでは、リクエストの大部分が仕事を片付けるのに最も高価なモデルを必要としません。
次のような用途にも役立ちます。
- 大量のバッチ処理
- レイテンシに敏感なユーザー向けアプリ
- 動画生成のようなリソース負荷の高いタスク
- 推論、ツール、検索を切り替えるエージェント型ワークフロー
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。