
動画プロンプトの最適化:テキスト vs 画像
AI動画生成におけるテキストから動画、画像から動画、ハイブリッドのプロンプト手法を比較し、ブランドの一貫性、クリエイティブな制御、コスト、品質についてのガイダンスを提供します。
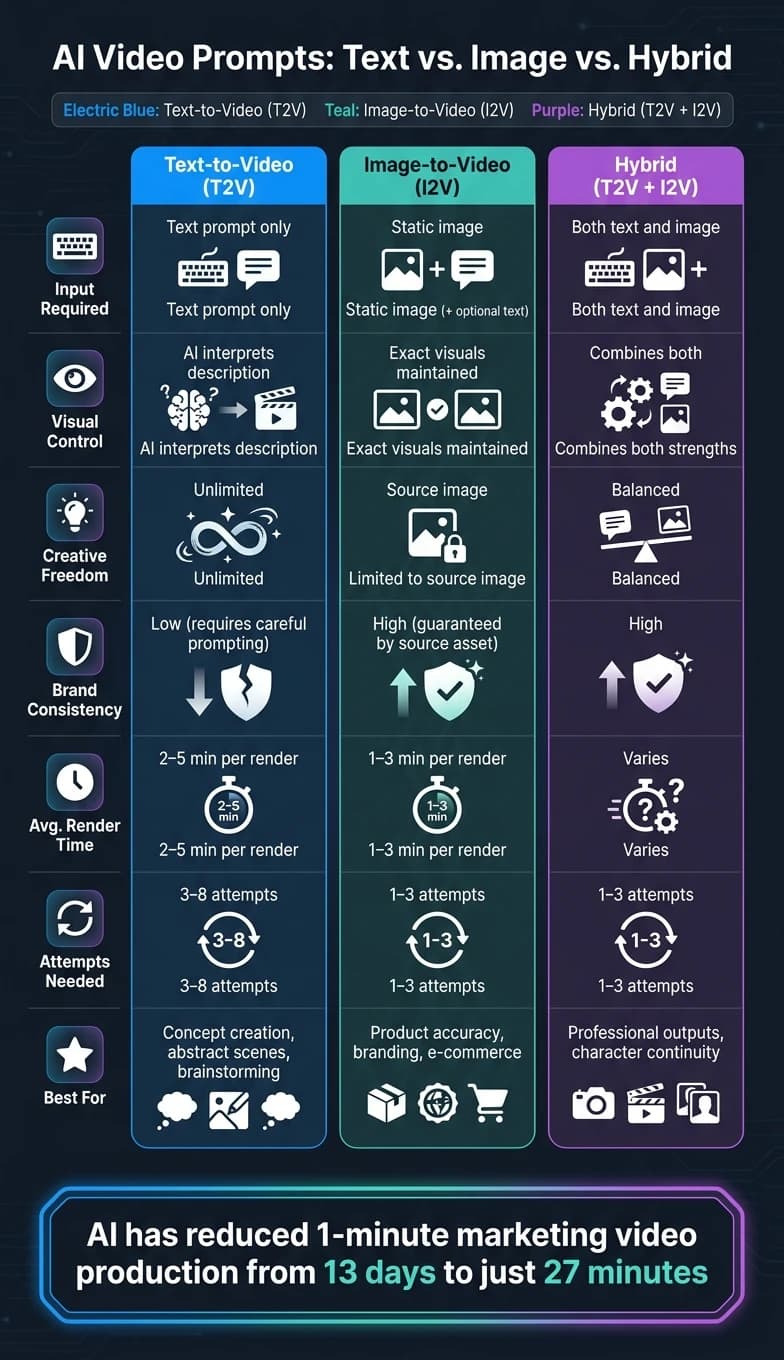
AI動画生成において、プロンプトの選択 - テキストから動画(T2V) または 画像から動画(I2V) - は結果に大きな影響を与えます。簡単に整理すると次のとおりです。
- テキストから動画:まったく新しいビジュアルを作成するのに最適です。ブレインストーミング、コンセプトのテスト、抽象的なシーンの生成に向いています。質の高い結果を得るには詳細なプロンプトが必要ですが、その分柔軟性があります。
- 画像から動画:正確さを維持するのに最適です。静止画像をアップロードすると、AIがそれをアニメーション化します。製品のショーケース、ブランディング、または一貫性が重要な場面に最適です。アップロードした画像のコンテキストに制限されます。
- ハイブリッドアプローチ:両方の手法を組み合わせ、精度と制御を実現します。視覚的な一貫性のために画像を使い、動きやスタイルを導くためにテキストを使います。
主な検討事項:
- T2Vは自由度が高い一方で、正確なプロンプトエンジニアリングが求められます。
- I2Vは正確さを保証しますが、クリエイティビティが入力画像に制限されます。
- 時間とコストの効率は異なります。T2Vはより多くの反復を必要とし、I2Vはより少ない試行で素早く結果を得られます。
簡易比較:
| 特徴 | テキストから動画 | 画像から動画 | ハイブリッド |
|---|---|---|---|
| 必要な入力 | テキストのみ | 静止画像(+テキスト) | 両方 |
| 視覚的制御 | AIがテキストを解釈 | 入力画像を維持 | 双方の強みを組み合わせる |
| クリエイティブな範囲 | 無制限 | 画像に制限される | バランス型 |
| ブランドの一貫性 | 努力が必要 | 高い | 高い |
| 理想的なユースケース | コンセプト作成 | 製品の正確さ | プロフェッショナルな成果物 |
結論:新しいアイデアにはT2V、精度にはI2V、そして映画的なAI動画生成と洗練された結果にはその両方を使いましょう。
テキストプロンプトと画像プロンプト:主な違い
テキストプロンプトとは?
テキストプロンプトとは、本質的にAIに何を作成すべきかを伝える文章による指示です。ゼロから始め、シーンやライティングから雰囲気やカメラの動きまですべてを作り上げます。視覚的な参照がないため、モデルは完全にその学習データに依存し、多くのクリエイティブな可能性を提供します。たとえば、火星の輝く峡谷を飛ぶドローンのような、まったく空想的なものを描写すると、AIはあなたのビジョンを実現しようとします。
しかし、この自由にはひとつの課題が伴います。曖昧なプロンプトは平凡な結果につながりかねません。最良の出力を得るには、10の具体的なカテゴリーにわたる詳細を盛り込む必要があります。被写体、スタイル、ライティング、環境、雰囲気、構図、動き、カメラ、長さ、音声です。ほとんどのユーザーはこれらのいくつかを省略してしまい、その結果、ありきたりな出力 - フラットなライティングの静的なショットのようなもの - になりがちです。
「テキストから動画と画像から動画は互換性のあるものではありません。これらは潜在空間において異なる制約のもとで動作しており、いつどちらを使うかを知ることが、映画的な出力と使い物にならない生成物との分かれ目になります。」- Sarah Iruoje [1]
対照的に、画像プロンプトはクリエイティブなプロセスを支える視覚的な出発点を提供します。
画像プロンプトとは?
画像プロンプトは、静止画像をベースとして始まります。すべてをゼロから生成する代わりに、AIはその画像をアニメーション化し、動きやその他の要素を加えます。このアプローチにより、モデルは被写体の見た目を明確に理解できます。
これは、ブランドや製品の仕事のように 視覚的な正確さが重要 なプロジェクトで特に役立ちます。たとえば、製品画像をアップロードすると、AIはその形状、色、レイアウトを保持します。キャラクターは一貫性を保ち、ロゴが歪むこともありません。これにより、画像から動画は、eコマース、製品マーケティング、そして元の見た目を維持することが不可欠なあらゆるシナリオで好まれる選択肢となります。ただし、トレードオフとして、クリエイティブな範囲は画像にすでに存在するものに制限され、まったく新しいものを作り出すことはできません。
「映像作家として、最大の敵はランダム性です。AIに主人公の見た目を『推測』してほしいわけではありません。すでにあなたがデザインしたキャラクターをアニメーション化してほしいのです。」- AIAI.com [10]
マルチモーダルプロンプティング
テキストプロンプトと画像プロンプトの強みを組み合わせることで、マルチモーダル入力は強力な制作手段を提供します。2026年までに標準となりつつあるこれらのワークフローは、視覚的な参照と説明的なテキスト指示を組み合わせます。画像が被写体の視覚的なディテールを固定し、テキストが動きやカメラの挙動を指示します。たとえば、製品写真をアップロードし、「ソフトなスタジオライティングでゆっくりドリーイン」といったテキスト指示を加えることで、シーンの展開を制御できます。
APIMartのようなプラットフォームは、このプロセスをシームレスにします。ユーザーはKling V3やSoraといったツールを単一のAPI内で活用でき、テキストと画像の入力を組み合わせる際に異なるツールやワークフローを切り替える必要がなくなります。
| 要素 | テキストから動画 | 画像から動画 |
|---|---|---|
| 必要な入力 | テキストプロンプトのみ | 静止画像(+任意でテキスト) |
| 視覚的制御 | モデルが説明を解釈 | 正確なビジュアルを維持 |
| クリエイティブな自由度 | 無制限 | ソース画像のコンテキストに制限される |
| ブランドの一貫性 | 低い(慎重なプロンプトが必要) | 高い(ソースアセットにより保証される) |
| 学習曲線 | 高い(プロンプトエンジニアリング) | 低い(アップロードして生成) |
テキストプロンプト:強みと限界
テキストプロンプトの強み
テキストプロンプトは、クリエイティビティを引き出す点で真価を発揮します。わずかな説明的な言葉だけで、シーン全体を形作ることができます。数百のAIモデルにわたって、異なる雰囲気、スタイル、シーンのアイデアをテストする場合でも、素早い実験が可能です。荒々しい都会の背景から、陽光あふれる海岸の風景に切り替えたいですか?いくつかの言葉を調整して再生成するだけです。テキストから動画のモデルは、学習データから情報を引き出すことにも優れており、特に都市景観、自然のシーケンス、空想的な環境のような抽象的なビジュアルで想像力豊かな結果につながることがあります。これらはGrok Imagine Videoのようなモデルを使って生成できます。
しかし、どんなツールにも言えることですが、いくつかのトレードオフがあります。
テキストプロンプトの限界
テキストプロンプトの最大の課題は、精度に欠けることです。視覚的な参照がないため、モデルはしばしば予測不能な判断を下します。これにより、複数のクリップにわたってキャラクター、ブランドカラー、ロゴの配置、製品のディテールに不整合が生じることがあります。もうひとつのハードルは?モデルはしばしば、リアルな手の握り、同期した動き、安定したテキスト描画といった複雑な物理的相互作用に苦労します。[9][4]
これらの課題を乗り越えるには、実証済みの戦略をいくつか用いることが不可欠です。
テキストプロンプトのベストプラクティス
結果を改善する最も効果的な方法のひとつは、構造化された10スロット形式 を使うことです。被写体 + アクション + 環境 + スタイル + カメラ + ライティング + 動き + 雰囲気 + 長さ + 音声。[9][4] これらの要素のいずれかを省略すると、品質の低い出力につながる可能性があります。たとえば、うまく作られた不動産のプロンプトは次のようになります。「スローなクレーンダウン、モダンな家の外観、ワイドな確立ショット、ゴールデンアワーのライティング、シネマティックなスタイル。」
出力を洗練させるための追加のテクニックをいくつか紹介します。
- タイムスタンプ付きアクションブロック:より良い制御のためにタイムスタンプ付きのアクションを取り入れます。特にSora 2のようなモデルで有効です。例:「0〜3秒:被写体がフレームに入る、3〜6秒:封筒を拾い上げる。」 このアプローチはペース配分を管理し、不規則または予測不能な動きを減らすのに役立ちます。[4]
- ネガティブプロンプト:「ぼやけ、低品質、歪み、ウォーターマーク」 といったよくある問題を避けるためにネガティブプロンプトのフィールドを使います。これらの除外設定がよりクリーンな結果を保証する助けになります。[11]
- 一貫したシード値:複数の生成にわたって同じシード値を使い続けます。これにより、ゼロからやり直すことなくディテールを微調整でき、時間と労力を節約できます。[1][4]
画像プロンプト:強みと限界
画像プロンプトの強み
正確なビジュアルが必要なときには、画像プロンプトが第一の選択肢になります。テキストだけに頼る代わりに画像をアップロードし、AIはそれを参照点として使います。このアプローチは、製品デモ、不動産ツアー、ブランドコンテンツのようなシナリオで特に効果的です。なぜか?それは、1枚の画像が、製品パッケージの正確な色合い、ロゴの配置、素材の質感など、言葉だけでは特定しづらいディテールを即座に伝えられるからです [2][7]。
もうひとつの大きな利点は効率性です。画像から動画(I2V)のワークフローでは、テキストプロンプトでの3〜8回の試行と比べて、通常1〜3回の生成で目的の結果を得られます。これは、構図、ライティング、色といった基礎的な要素が最初のフレームからすでに設定されているためです [6][7]。
画像プロンプトの限界
欠点は?柔軟性が損なわれることです。動画が参照画像に固定されるため、まったく新しいシーンをゼロから作ることはできません。さらに、入力画像の品質が重要です。照明が不十分、解像度が低い、構図が不自然な画像は、最終的な出力に直接影響します [2]。
動きも厄介になることがあります。微妙な表情の変化、歪んだ手、または宝飾品や衣服のテキストのような消えてしまうディテールが、クリップの流れを乱すことがあります。以下の表は、さまざまなショットタイプとそれに関連するリスクをまとめたものです。
| ショットタイプ | リスク | 最適な用途 |
|---|---|---|
| 微妙な動き | 低い | クリーンな顔、製品の完全性、安定した背景 |
| スローなプッシュイン/パン | 低い | シネマティックな雰囲気、プロフェッショナルなマーケティング |
| 激しい動き | 高い | アクションシーン(再試行が必要な場合あり) |
| 速いオービット/ズーム | 高い | ダイナミックなトランジション(アーティファクトが発生しやすい) |
2026年現在、ほとんどのモデルは5〜15秒のクリップで最も良く機能します。より長い動画の場合は、フレーム間でディテールの一貫性を保つために、ポストプロダクションで短いセグメントをつなぎ合わせる方が安全です [6][9]。
画像プロンプトの制御オプション
これらの課題に対処するために、いくつかの制御設定を調整できます。Kling V3のようなモデルを備えたAPIMartのようなプラットフォームでは、動きの強度、クリップの長さ、プロンプトの重みといったパラメーターを調整できます。これらの設定は、テキスト指示が参照画像と比べてどれだけ影響を持つかのバランスを取るのに役立ちます [12]。
固定シード値を使うことも賢い手です。これにより、元の画像の視覚的な一貫性を失うことなく、複数の生成にわたって動きの方向と強度を微調整できます [12]。最良の結果を得るには、高品質の参照画像を微妙な動きの設定とロックされたシードと組み合わせます。このアプローチは、わずか1〜2回の試行でクリーンで洗練されたクリップを生み出すことがよくあります。
テキスト、画像、または両方を使うべきとき
ユースケースの比較
テキストから動画と画像から動画のどちらを選ぶかは、すでに手元にあるアセットによって決まります。
「テキストから動画と画像から動画のAIモデルのどちらを選ぶかは、実のところ技術的な決定ではありません。あなたが何を持って臨むかということなのです。」- Eachlabs Team [2]
まだビジュアルのないコンセプトや製品 - ローンチ前のアイデアのようなもの - を扱っているなら、テキストから動画が最善の選択です。写真撮影を必要とせずにゼロからビジュアルを作成できます。一方、すでにプロの製品写真やブランド画像を持っているなら、通常は画像から動画が適しています。これにより、動画内のビジュアルが実際の製品と完全に一致することが保証され、特にeコマースでは返品を減らすうえで重要です [3][7]。
| シナリオ | 推奨入力 | 理由 |
|---|---|---|
| 新ブランド、既存アセットなし | テキストから動画 | 写真撮影を必要とせずにゼロからビジュアルを作成 [3] |
| 製品のショーケースまたはデモ | 画像から動画 | 動画が実際の製品と完全に一致することを保証 [7] |
| 抽象的またはシュールな広告コンセプト | テキストから動画 | 撮影が不可能な比喩的なアイデアを捉える [3] |
| クリップ間のキャラクターの連続性 | ハイブリッド(画像 + テキスト) | 参照画像がアイデンティティを固定し、テキストがアクションを導く [10] |
| プロフェッショナルなブランドコンテンツ | ハイブリッド(画像 + テキスト) | 視覚的なアンカーと動きを組み合わせて洗練された結果を得る [1] |
これらの選択は、コストやレンダリング時間といった実用的な要素にも左右されます。
米国チームにとっての実用的な要素
予算とスケジュールは、クリエイティブな目標と同じくらい大きな役割を果たすことがよくあります。テキストから動画は通常1レンダーあたり2〜5分かかり、うまくいくまでに3〜8回の試行が必要になることがあります。一方、画像から動画はより速く、平均1〜3分で1〜3回の試行で済みます [7][8]。これらの時間の差は、大規模な制作では積み重なっていきます。
コストも重要な検討事項です。APIMartの価格設定は、これらの選択がワークフローにどう影響しうるかを浮き彫りにします。たとえば、Wan 2.5 (画像から動画) は1生成あたりわずか5クレジット(約 $0.39)で、正確さが重要な大量のeコマースに最適です [3]。映画的な品質を目指すなら、1生成あたり60クレジットの Sora 2 Pro がプレミアムな選択肢です。標準品質のニーズには、8クレジットのVeo 3.1 Fast がバランスを取ってくれます [3]。一般的なアプローチとしては、初期段階のアイデアには低コストのテキストから動画モデルから始め、その後最終製品には画像から動画またはハイブリッドのワークフローへ移行します。
テキストプロンプトと画像プロンプトの組み合わせ
テキストプロンプトと画像プロンプトを一緒に使うことで、クリエイティビティと精度を組み合わせ、両方の良いところを得ることができます。
「テキストから動画 = 想像と探求、画像から動画 = 一貫性と制御、ハイブリッド = プロフェッショナルグレードの出力。」- Sarah Iruoje、VidAU.ai [1]
効果的な方法のひとつが 「まず静止画を生成する」 テクニックです。まず、テキストから画像のモデルを使って、望む構図を捉えた静止画を作成します。次に、画像から動画のモデルを使って、その静止画に動きを加えます [2][7]。もうひとつの有望なワークフローは ブリックシステム として知られ、動画広告を異なるセクションに分割します。たとえば、テキストから動画のモデルを使って目を引くシネマティックなオープニングを作り、続けて正確な製品ディテールのために画像から動画のセグメントを配置し、最後に行動喚起のためのブランドオーバーレイで締めくくる、といった具合です [3]。各セクション - つまり「ブリック」 - は、その役割に最も適した入力タイプを使い、まとまりのある効果的な最終動画を作り上げます。
画像から動画 vs テキストから動画:スタートフレームが制御で勝る理由
結論:目標に合った正しいプロンプトタイプを選ぶ
ここでの意思決定プロセスは、ひとつのシンプルな出発点に行き着きます。すでに持っているもので進める。 最初にビジュアルがないなら、テキストから動画はアイデアを素早く試すのに最適な方法です。一方、すでに承認済みの画像があるなら、画像から動画がブランドの一貫性を維持するための第一の選択肢です。最良の結果を得るには、両方の手法を組み合わせることが大きな転機になり得ます。
ものごとを視野に入れるための統計をひとつ紹介します。AIは1分間のマーケティング動画の制作時間を13日からわずか27分に短縮しました [5]。選ぶプロンプトのタイプによって、この効率性をどれだけ実際に活用できるかが決まります。テキストから動画はブレインストーミングの段階で優れ、画像から動画は最終出力の精度を保証し、ハイブリッドのワークフローはプロフェッショナルなチームに必要な洗練された結果をもたらします。
取り入れると役立つテクニックが 「ユニバーサルコア」戦略 です。これは、一貫した被写体とシーンに焦点を当てたモジュール式のプロンプトを作り、そこにモデル固有のパラメーターを加えるというものです。シードパリティを使ってビジュアルを安定させることで、使えるクリップにたどり着くまでに必要な生成回数を減らすこともできます。
APIMartのようなプラットフォームは、マルチモーダルなワークフローをよりシームレスにします。システムは入力に基づいて適切な生成モードを自動的に選択します。画像なしの場合はテキストから動画がデフォルトになり、画像1枚で画像から動画が起動し、画像2枚で最初と最後のフレームモードが有効になります [12]。Sora 2、Veo 3.1、Kling V3を含む500以上のモデルに単一のAPIを通じてアクセスできるため、複数のプラットフォームや課金システムをやりくりすることなく、戦略を簡単に切り替えられます。このような効率化されたワークフローは、クリエイティブなプロセスを簡素化します。
最終的に、万能の解決策は存在しません。最良のプロンプトタイプは、利用可能なアセット、締め切り、そしてプロジェクトが必要とする視覚的な一貫性のレベルによって決まります。それぞれのアプローチをマスターすることで、試行錯誤のサイクルを減らし、より速く結果を出せるようになります。
よくある質問
プロジェクトでテキストから動画と画像から動画のどちらを選べばよいですか?
テキストから動画 と 画像から動画 のどちらを選ぶかは、クリエイティビティと一貫性の面で何を達成しようとしているかによって決まります。
- テキストから動画 は、ストーリーテリングに焦点を当てたり、抽象的なビジュアルを生成したり、ゼロから新しいアイデアを試したりする場合に適しています。
- 画像から動画 は、ブランドコンテンツや繰り返し登場するキャラクターを含むプロジェクトのように、一貫した視覚スタイルを維持することが重要なシナリオに向いています。
これを簡単にするために、APIMartはこの決定をあなたに代わって処理します。入力に基づいて最も適したモードを自動的に選択し、スムーズな統合を保証します。
テキストプロンプトが良い動画結果のために「十分に詳細」であるとはどういうことですか?
優れたテキストプロンプトは、一般的なものから明確に定義されたものへと進み、被写体、アクション、環境、カメラの動き、スタイル を概説します。明確な特徴や具体的なライティングといった正確なディテールを含めることで、曖昧さを排除し、より一貫した結果を保証する助けになります。APIMartを使えば、視覚的な参照をアンカーとして取り入れることで、これをさらに一歩進められます。このアプローチにより、ブランディングやキャラクターデザインのような重要なディテールが、動画コンテンツ全体で一貫したものに保たれます。
複数のAI動画クリップにわたってキャラクターや製品を一貫させるにはどうすればよいですか?
一貫したAI生成の動画クリップを作るには、テキストプロンプトだけに頼るのではなく、マルチモーダル入力に頼る方が良いです。テキストのみのプロンプトは、モデルがすべてのディテールを自力で埋めなければならないため、不整合を引き起こすことがあります。APIMart のようなツールを使ってテキストプロンプトを参照画像と組み合わせることで、キャラクター、ロゴ、製品といった要素についてAIに明確な視覚的ガイドを与えられます。最適な結果を得るには、参照画像が高解像度で、十分に照らされ、被写体を複数の角度から見せていることを確認してください。
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。