
コードを書き直さずにAIモデルを切り替える方法
統合AI APIを使えば、設定変更だけで500以上のモデルを切り替えられます。APIMartのルーティングやA/Bテストの活用方法を解説します。
AIモデルの切り替えは、プロバイダーごとに異なるセットアップ・SDK・レスポンス形式が必要なため、面倒になりがちです。しかし、より良い方法があります。統合AI APIを使えば、単一のインターフェースを通じて複数のモデルに接続でき、設定を更新するだけでモデルの切り替えが簡単に行えます。このアプローチにより、時間の節約、エラーの削減、特定のプロバイダーへの依存回避が実現します。
ここで学べること:
- 統合AI APIはエンドポイント・認証・パラメータを標準化することで、インテグレーションをシンプルにします。
- APIMartのようなツールを使えば、単一のAPIキーとエンドポイントで500以上のモデルに接続できます。
- 設定の一元化やルーティングレイヤーの構築といった設計のヒントにより、モデルの切り替えが容易になります。
- A/Bテストとモニタリングによって、新しいモデルへの移行をスムーズに行えます。
統合APIにより大規模な書き直しが不要になり、目の前のタスクに最適なモデルの選択に集中できます。
統合AI APIを理解する
統合AI APIとは?
統合AI APIは、複数のAIモデルと接続するためのワンストップショップのようなものです。OpenAI・Anthropic・Googleなどプロバイダーごとに異なる設定を管理する代わりに、裏側のすべてを処理してくれる単一のインターフェースが提供されます。各プロバイダーのインテグレーションの詳細を理解する必要はありません。
このアプローチでは、モデルの切り替えが非常に簡単になります。認証やコアロジックを変更するのではなく、文字列の値を更新するだけです。統合APIは、書き直しに悩まずにマルチモデルインテグレーションを効率化したい方に最適な選択肢です。
| 概念 | 統合AI API | 単一プロバイダーAPI |
|---|---|---|
| エンドポイント | 単一のベースURL(例:https://api.apimart.ai/v1) | プロバイダーごとに異なるURL |
| 認証 | Authorization: Bearer KEY | プロバイダーごとに異なる方式 |
| モデル選択 | "model": "string-id" | SDKまたはURLパスによって異なる |
| ベンダーロックイン | 低い - 設定変更で切り替え可能 [5] | 高い - 移行が難しい |
統合APIインテグレーションの主要コンポーネント
統合APIインテグレーションは、ベースURL・モデル識別子・APIキー・環境変数の4つの主要要素に依存しています。
- ベースURLは、プロバイダー固有のすべてのエンドポイントを1つの共通アドレスに置き換えることで、設定をシンプルにします [1]。
- モデル識別子(
"gpt-4o"や"claude-opus-4"など)は、ゲートウェイにどのAIモデルを使用するかを伝えます。 - APIキーは、統合ゲートウェイを通じた安全なアクセスを保証します。
- 環境変数により、本番コードに触れることなく設定変更が容易になります。
統合ゲートウェイを使用する利点の一つは、リクエストごとに追加されるレイテンシがわずか3ms〜50msであることです [4]。これは、モデル自体がリクエストを処理する時間と比較するとほとんど気にならない程度です。さらに、これらのゲートウェイはパラメータの正規化という厄介な問題にも対処しています。異なるプロバイダーは同じ機能に異なる用語を使用しています。たとえば、モデルがプロンプトにどれだけ厳密に従うかを制御するパラメータは、FluxとGoogleではguidance_scale、Stabilityではcfg_scale、OpenAIではqualityと呼ばれています [3]。統合APIはこれらの違いを吸収し、プロバイダーに関係なく一貫したパラメータで作業できるようにします。
OpenRouter:300以上のAIモデルに対応する単一API
コードを書き直さずにモデルを切り替えるアプリの設計方法
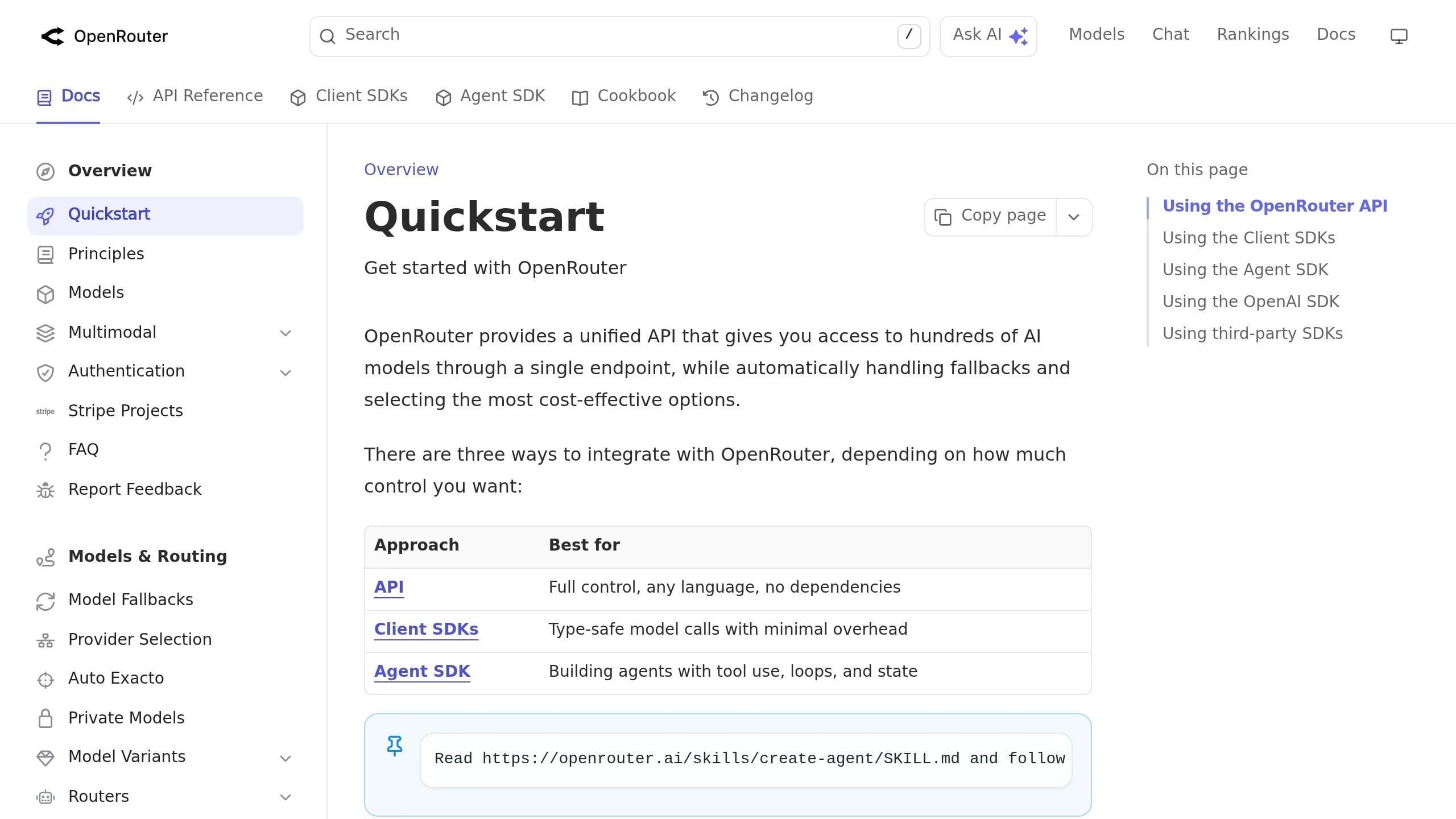
統合APIインテグレーションを最大限に活用するためには、さまざまなモデルに対して柔軟に対応できるようにアプリを設計することが重要です。重要な原則はビジネスロジックをAPI固有のロジックから分離することです。エンジニア兼創業者のTian Panは次のように説明しています:
「ビジネスロジックは、OpenAIやAnthropicの具体的なクライアントではなく、言語モデルの抽象化に依存すべきです。」[6]
このアプローチは、クリーンなコードを書くためだけでなく、高コストな問題を回避するためのスマートな方法でもあります。単一プロバイダーに密結合した中規模の本番システムを移行するには、エンジニアリング費用として5万〜10万ドルのコストがかかる可能性があります [6]。以下の戦略が、これらの問題を回避するためのアプリ設計に役立ちます。
リクエストとレスポンスの形式を標準化する
AIMessageインターフェースやAIResponseオブジェクトなどの単一の内部形式を作成し、使用しているモデルに関係なく一貫性を保ちます [2]。アダプターレイヤーを使えば、各プロバイダー固有の特性をこの標準形式に変換できるため、コード全体を大規模に変更する必要がありません。
たとえば、プロバイダーによってリクエストとレスポンスの処理方法が異なります:OpenAIはsystemロールを持つmessages配列を使用し、Anthropicはトップレベルのsystemパラメータを必要とし、GoogleはsystemInstructionを採用しています [2][9]。レスポンス側では、OpenAIはchoices[0]にコンテンツを配置し、Anthropicはcontent[0]を使用しています。アダプターレイヤーを実装することで、これらの不一致を解消し、モデルを切り替える際の時間と手間を節約できます。
モデル設定を一元管理する
"text-fast"や"reasoning-premium"のような説明的なエイリアスを使用して、中央設定ファイル内の特定のモデルIDを表します [7]。この方法は、統合APIがプロバイダー固有の詳細を隔離する機能を活用し、ビジネスロジックに影響を与えません。新しいモデルバージョンがリリースされたり、よりコスト効率の高いオプションをテストしたりする場合も、アプリ全体を検索する代わりに1行のコードを更新するだけで済みます。
さらに一歩進めて、プロバイダーレジストリを使用できます。これはランタイムで正しいクライアントを動的に作成するファクトリー関数に各エイリアスをリンクします [6][7]。こうすることで、アプリの残りの部分はどのプロバイダーが使用されているかを知る必要も、気にする必要もありません。
モデルルーティングレイヤーを構築する
ルーティングレイヤーはアプリとプロバイダーの間の仲介者として機能し、各リクエストをどのモデルが処理するかを決定します。たとえば、複雑なクエリをプレミアムモデルに送り、シンプルなタスクをより速く低コストなオプションに送るルールベースのルーターを設定できます [10]。このレイヤーは統合APIと連携して、複数のプロバイダーを管理する複雑さを軽減します。
実例として、2026年4月にあるSaaS企業がルーティングレイヤーを使用してシンプルなタスクを安価なモデルに振り分け、要求の高いクエリにのみプレミアムモデルを予約することで、LLMの1日あたりのコストを58%削減し、1,420ドルから594ドルに抑えることに成功しました [8]。このルーティングレイヤーはまた、429や5xxなどのエラーに対する自動フォールバックも管理し、スムーズな運用を確保しました [2][8]。
APIMartを使ったモデルの切り替え方法
APIMartを中央モデルハブとして使用する
APIMartは、テキスト・画像・動画・音声タスク向けの500以上のモデルへの集中アクセスを、単一エンドポイントhttps://api.apimart.ai/v1を通じて提供することで、AIモデルの管理を簡単にします。単一のAPIキー・統一されたリクエスト形式・集中管理された設定により、モデルの切り替えがシームレスになります。
たとえば、PythonまたはNode.js向けのOpenAI SDKを使用している場合、base_urlをAPIMartのエンドポイントに向けるだけで済みます。GPT-5からClaude 4.6 Sonnetへの切り替えは、model文字列を更新するだけで、新しいSDKや認証プロセスに手を入れる必要はありません。
このセットアップは、素早く実験する必要があるチームに特に便利です。各AIプロバイダーに個別のインテグレーションを作成する代わりに、1つの効率的なインテグレーションに依存して必要に応じて設定を調整できます。
プロジェクトのニーズに基づいた動画モデルの切り替え
動画生成においては、適切なモデルを選ぶことが重要です。各モデルは、タスクに応じてコスト・品質・速度のトレードオフが異なります。APIMartは同じAPIを通じて複数の動画モデルオプションを提供することでこのプロセスを簡略化し、ワークフローを変更することなくプロジェクトに最適なものを選択できます。
いくつかの人気オプションの簡単な比較:
| モデル | 価格 | 最適な用途 |
|---|---|---|
| MiniMax Hailuo 2.3 | $0.025/秒 | 素早くコスト効率の高いドラフト |
| Kling V3 Omni(720P) | $0.0672/秒 | マルチモーダル入力と汎用性 |
| Sora 2 Preview | $0.08/秒 | 高品質なクリエイティブ出力 |
たとえば、MiniMax Hailuo 2.3は速度とコストが優先される初期段階のドラフトや社内ブレインストーミングセッションに最適です。テキストと画像の両方の入力を使って短いクリップを作成する必要がある場合は、Kling V3 Omniが堅実な選択です。品質が最優先される顧客向けキャンペーンには、Sora 2 Previewを選びましょう。これらのモデルはすべて同じリクエスト構造を共有しているため、設定値を1つ更新するだけで切り替えられます。
この柔軟性により、プロジェクトにマルチモーダルワークフローを統合することも容易になります。
単一APIによるマルチモーダルワークフローの実行
APIMartの統合APIは、最小限の労力でマルチモーダルワークフローを処理できるよう設計されています。単一パイプライン内でさまざまなモデルタイプをチェーン接続することで、認証・課金・変更の追跡を気にすることなく、各ステップでモデル識別子を調整できます。
コンテンツ制作パイプラインの例:
| ステップ | モデル例 | タスク |
|---|---|---|
| 1. 脚本 | GPT-5 | クリエイティブブリーフと動画プロンプトの作成 |
| 2. ストーリーボード | Flux Pro | スクリプトに基づいた参考画像の生成 |
| 3. 動画合成 | Kling V3 Omni | 画像を映画的なクリップに変換 |
| 4. 最終仕上げ | Sora 2 Preview | 高品質な最終シーンの制作 |
このパイプラインを管理しやすくする秘訣は設定駆動型アプローチにあります。モデル識別子・入力形式・パラメータ(resolution・duration・aspect_ratioなど)などの詳細を1つの設定オブジェクトに集中管理します。こうすることで、ステップ3の動画モデルを変更する必要がある場合も、前の脚本や画像生成ステップに影響を与えることなく変更できます。
動画や画像タスクでは、APIMartはそれらを非同期で処理します。タスクが完了するまで指数バックオフ(10〜20秒から開始)でポーリングするために使用できるtask_idが提供されます。
モデルを安全かつ効率的に切り替えるためのベストプラクティス
APIMartの統合APIインテグレーションを最大限に活用するためには、設定管理・モニタリング・セキュリティにおける重要なプラクティスに従うことが、スムーズで安全なモデル移行に不可欠です。
モデル設定のバージョン管理とテスト
モデル設定を管理する際は、コードと同様に扱います。バージョン管理を使用して、モデル識別子・パラメータ・ルーティングルールへの変更を追跡します。これにより、何か問題が発生した場合に以前のバージョンに素早くロールバックできます。変更の詳細な履歴を保持することで、モデルを切り替える際の問題解決が容易になります。
本番環境に新しいモデルをデプロイする前に、A/Bテストを実施します。ライブトラフィックの一部を新しいモデルにルーティングし、既存のモデルとパフォーマンスを比較します。このアプローチにより、テストデータだけでなく実際の使用状況に基づいたインサイトが得られます。追加の品質チェックには、LLM-as-judgeセットアップを使用します。たとえば、GPT-5やClaude 4.5などのモデルが新しいモデルの出力の1〜5%のサンプルを評価し、ユーザーに影響を与える前に微妙な品質問題を特定できます [8]。
自動化されたヘルスチェックも重要なツールです。60〜120秒ごとに定期的なテストリクエスト(5トークンの軽量な補完など)を設定します。これにより、プロバイダーの障害を早期に検出し、ユーザーからの苦情を待って問題を発見するリスクを軽減できます [2]。
モデルパフォーマンスの監視とログ記録
モデルが稼働したら、レイテンシ・コスト・エラーレートなどのメトリクスを注意深く監視します。特にP95レスポンス時間(95パーセンタイル)は重要な指標です。たとえば、モデルのレスポンスに30秒かかる場合、HTTP 200レスポンスで技術的に成功していても、ユーザー向けアプリケーションではほぼ使用不可能です [2][8]。
「すべてのリクエストに1つのモデルを使う時代は終わりました。各リクエストに適切なツールを選べば、AIのコストは40〜70%削減できます。」 - Akshay Ghalme、AWSデベロップメントオペレーターエンジニア、BytePhase Technologies [8]
ログには解決済みモデルメタデータも記録し、各リクエストをどのモデルが処理したかを詳細に記録します。これはフォールバックシナリオで特に重要です。予算に優しいモデルがプレミアムモデルにエスカレートする頻度が30%を超える場合、ルーティングロジックの調整が必要なサインです [8]。
パフォーマンス監視に加えて、中断のない運用のためにAPIクレデンシャルのセキュリティ確保も重要です。
APIキーの安全な保管とコンプライアンスの維持
安定したマルチモデル環境を維持し、脆弱性を露出させることなくシームレスなモデル移行を確保するためには、強力なセキュリティ対策が不可欠です。APIMartで単一のAPIキーを使用して攻撃対象を最小化します。このキーを環境変数またはシークレットマネージャーに安全に保存し、ハードコーディングやバージョン管理へのコミットは避けましょう。
規制産業で運営するチームにとって、コンプライアンスは必須です。Akshay Ghalmeが述べているように:
「ルーティングは契約上・規制上の制約を遵守しなければなりません - 一部のデータは特定の地域やベンダーから出てはいけません。」[8]
ルーティングロジックがデータ所在地のルールに準拠していることを確認してください。SOC 2コンプライアンス・シングルサインオン(SSO)・集中監査ログをサポートするゲートウェイを使用します。また、特にクライアントが異なる使用層やデータ要件を持つマルチテナント設定では、予期しないコストを防ぐためにテナントごとの支出上限を実装します [8]。
最後に、特定のエラータイプに対してのみ自動フォールバックを予約します。たとえば、モデルの切り替えで問題を解決できる429(レート制限超過)や5xx(サーバーエラー)のレスポンスにはフォールバックを使用します。400 Bad Requestのような4xxエラーにはフォールバックを避けてください。これらは通常、モデルの切り替えでは修正できない不正な入力を示しています [2]。
結論:統合AI APIで柔軟性を獲得する
統合AI APIにより、AIモデルの切り替えは設定を調整するだけの簡単な作業になります - 大規模なコーディングやシステムの改修は不要です。
リクエストとレスポンスの形式を標準化し、モデル設定を一元管理し、すべてを単一のインターフェースを通じてルーティングすることで、モデルを変更する際の複雑なエンジニアリング作業が不要になります。どのモデルを使用するかにかかわらず、アプリケーションロジックはそのまま維持されます。
APIMartを例にとると、テキスト・画像・動画生成を含む500以上のモデルに接続する単一エンドポイントにより、チームはモデルをeffortlesslyに切り替えられます。米国のEコマースチームが商品説明用の2つの言語モデルをA/Bテストするシナリオを想像してください。APIMartでルーティングルールを調整し、USD単位で結果を追跡し、新しいコードをデプロイすることなくコンバージョン率を比較できます。この効率的なプロセスにより、チームは変化するプロジェクトニーズに素早く適応できます。
このセットアップはスケールアップにも対応します。トラフィックの増加に対応してスケーリングする場合でも、高度な動画ジェネレーターやドメイン固有モデルなどの最先端ツールを統合する場合でも、この統合アプローチにより物事がシンプルに保たれます。開発者のオンボーディングが迅速になり、コアアプリケーションを中断することなく新しいテクノロジーに対応できます。
統合AI APIの強みは、柔軟性をアーキテクチャに直接組み込む能力にあります。モデルの移行は大規模な取り組みではなく、日常的な調整になります。この適応性により、次に何が来ても準備が整います。
よくある質問
すべてを再構築せずに既存のアプリにモデル切り替えを追加するには?
コードを書き直さずにモデルの切り替えをシームレスにするには、統合APIゲートウェイの使用を検討してください。SDKのベースURLをAPIMartのようなゲートウェイに向けることで、モデルの選択・ルーティング・フェイルオーバーを手間なく管理できます。このセットアップにより、認証・SDKロジック・エラー処理に触れることなく、コード内のモデルパラメータを動的に更新するなど、設定を調整できます。ゲートウェイがこれらのプロセスの標準化を処理するため、時間と労力を節約できます。
モデルルーティングレイヤーに何を含めるべきか(フォールバックを避けるべき場合は?)
モデルルーティングレイヤーは、アプリケーションをさまざまなAIモデルにリンクするハブとして機能します。リクエストマッピングの管理・コスト効率に基づくモデルの選択・フェイルオーバー戦略の実装・パフォーマンスの監視が仕事です。安定性を維持するために、タスク固有のベンチマークに依存する設定駆動型ルーティングマップを使用します。
正確な単一モデルの実行が必要な特殊なタスクでは、意味的または品質の問題に対するフォールバックメカニズムを避けます。このアプローチにより、厳格な品質管理が確保され、成果の妥協を回避できます。
本番環境を壊さずに新しいモデルを安全にA/Bテストするには?
本番環境での中断リスクを冒さずに新しいAIモデルをテストするには、まず_シャドウモード_でモデルを実行することから始めます。このセットアップでは、本番トラフィックは既存のモデルと新しいモデルの両方に送られます。現在のモデルが引き続きユーザーにサービスを提供する一方、新しいモデルはバックグラウンドで入力を処理し、ライブ運用に影響を与えることなく結果を比較できます。
新しいモデルのパフォーマンスが検証されたら、統合APIゲートウェイやフィーチャーフラグなどのツールを使用して段階的にロールアウトできます。これらにより、パフォーマンスメトリクスを慎重に監視し、問題が発生した場合にシステムの安定性を維持するためのロールバックトリガーを設定できます。
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。