
AI API の価格、性能、スケーラビリティ
2026 年の AI API コストガイド。トークン単位、画像単位、秒単位の価格が実際にどう積み上がるか、そして支払額を左右するレイテンシ、レート制限、リトライを解説します。
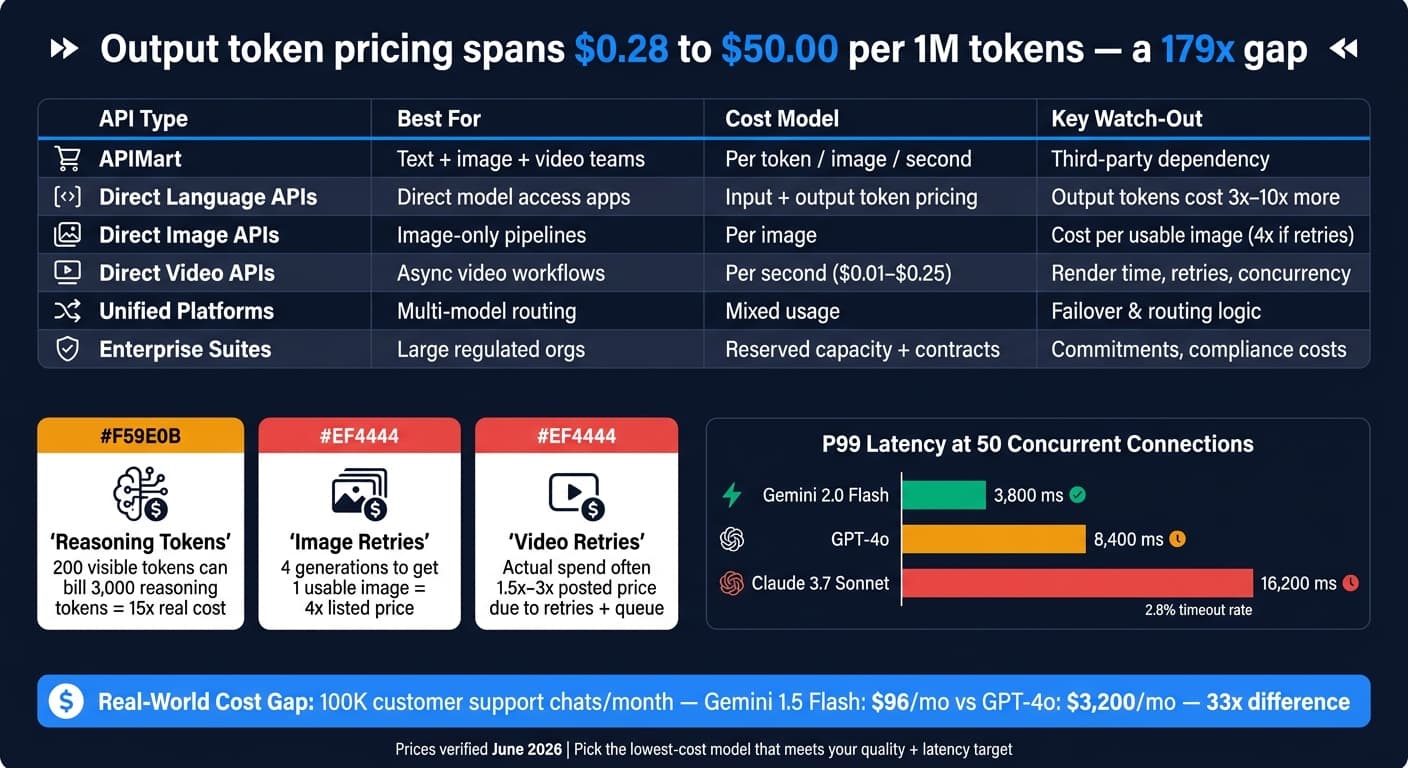
2026 年の AI API のコストはまさにバラバラです。出力価格だけで 100 万トークンあたり $0.28 から $50.00、つまり 179 倍の差 があります。 今 API を選ぶなら、私は何よりもまず コスト、レイテンシ、レート制限、そして トラフィックが増えたときにシステムが持ちこたえるか を見ます。
短いバージョンはこうです。
- APIMart は、テキスト・画像・動画モデル に 1 つの API を求めるチーム向けに作られており、ルーティング、非同期ジョブ、支出制御を備えている。
- 直接の言語モデル API は素直なアクセスを与えるが、出力トークンはしばしば入力トークンより 3〜10 倍 高くつき、推論トークンが請求をさらに押し上げうる。
- 直接の画像 API はしばしば画像単位で価格設定されるが、本当の コストはリトライ、却下率、アップスケーリング、そして使える画像 1 枚を得るのに必要な生成回数に依存する。
- 直接の動画 API はたいてい秒単位で価格設定され、長い待ち時間、非同期の配信、リトライコスト、厳しい並行性の上限を伴う。
- 統一 AI API プラットフォーム は、モデルルーティング、フェイルオーバー、複数プロバイダーにまたがる 1 つの請求層が必要なときに役立つ。
- エンタープライズスイート は、予約容量、コンプライアンス条項、プライベートネットワーク、契約ベースのサポートが必要なチームに合う。
単純なルールが欲しいなら、こうです。品質とレイテンシの目標をなお満たす最も低コストのモデルを選び、それを自分のプロンプトで自分のトラフィックレベルでテストする。 価格表は役立ちますが、p95 レイテンシ、リトライ率、キュー時間、出力中心の使用 が最終的な支払額を決めます。
簡易比較
| 選択肢 | 最適な用途 | 主なコストモデル | 注視すべき点 |
|---|---|---|---|
| APIMart | テキスト・画像・動画を一緒に使うチーム | トークン単位、画像単位、秒単位 | サードパーティ依存、バンドルの適合 |
| 直接の言語 API | 直接のモデルアクセスが必要なアプリ | 入出力トークン価格 | 出力トークンコスト、推論トークン、レート制限 |
| 直接の画像 API | 画像専用の製品とパイプライン | 画像単位 | 使える画像あたりのコスト、キュー時間、URL の失効 |
| 直接の動画 API | 非同期の動画ワークフロー | 秒単位 | レンダリング時間、リトライ、並行性の上限 |
| 統一 AI プラットフォーム | ベンダーをまたぐマルチモデルルーティング | 混合利用の価格設定 | ルーティングロジック、リトライ処理、フェイルオーバーの挙動 |
| エンタープライズスイート | 厳格な法務やインフラ要件を持つ大規模組織 | 予約容量とカスタム契約 | コミットメント、リージョン価格、サポート条件 |
これが、この話題の残りで私が使うレンズです。掲載価格だけでなく、スケールで使える結果を得るための総コストです。
APIMart
APIMart は、500 以上の言語・画像・動画モデルに 1 つの API を提供します。ほとんどのチームにとって、それは統合作業の削減、より単純な価格設定、スケーリングのための組み込み制御を意味します。その構成は、テキスト・画像・動画のユースケース間でコストを比較するときにいっそう有用になります。
従量課金の価格設定 を採用しており、月額の最低額も隠れた料金もありません。請求は使うモデルの種類によります。テキストは 100 万入力トークンあたり、画像は呼び出しごと、動画は秒単位で課金されます。下に挙げたモデルでは、APIMart は公式価格より安くなります。そして使用量が増えるにつれ、ボリューム割引とバンドル価格が単価をさらに下げられます。
| モダリティ | モデル | APIMart 価格 | 公式価格 | 単位 |
|---|---|---|---|---|
| テキスト | GPT-5 Nano | $0.05 | $0.0625 | 100 万入力トークンあたり |
| テキスト | Claude Sonnet 4.5 | $1.80 | $3.00 | 100 万入力トークンあたり |
| 画像 | Imagen 4.0 | $0.04 | $0.05 | 呼び出しごと |
| 動画 | Sora 2 | $0.08 | $0.10 | 秒あたり |
| 動画 | Hailuo 2.3 Fast | $0.025 | $0.031 | 秒あたり |
もちろん、価格はパズルの一片にすぎません。使用量が登り始めると、スループットと信頼性も同じくらい重要になります。
APIMart はトラフィック急増時のスロットリングを減らすためにプロバイダー間でトラフィックをルーティングし、大きなジョブにはタスク ID とウェブフックで非同期ジョブをサポートし、エッジ配信でグローバルなレイテンシを削減します [6][7]。本番ワークロード向けに 99.9% の稼働率 SLA も提供しています。トラフィックが増え始めると、監視と予算制御が応答時間と同じくらい重要になります。
初期の利用では、ダッシュボードがチームの支出監視に役立ちます。より高いボリュームでは、上限とアラートが急増や繰り返しのリトライによる想定外の請求を止めるのに役立ちます。ダッシュボードは支出、クォータ、使用量をリアルタイムで表示し、APIMart ブログ はコスト削減の追加のヒントを提供します。そして即時の応答を必要としない作業には、Batch API が入力と出力の両方のトークンコストを 50% 下げます。
直接の言語モデル API
直接の言語モデル API は、たいてい入力トークンと出力トークンを別々に課金します。そして出力トークンは、生成により多くの計算を要するため、しばしば入力トークンより 3〜10 倍高く つきます [4][8]。その差は、トークンあたりの表示価格が見せるより強く月次の請求を直撃しかねません。
2026 年 6 月時点の、一般的なモデル層にまたがる代表的な価格のスナップショットです。
| モデル | 入力(100 万トークンあたり) | 出力(100 万トークンあたり) | コンテキストウィンドウ |
|---|---|---|---|
| GPT-5.5(フラッグシップ) | $5.00 | $30.00 | 1M |
| Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M |
| GPT-5.4-mini | $0.75 | $4.50 | 400K |
| DeepSeek V4 Flash | $0.14 | $0.28 | 1M |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M |
本番では、これらのレートはワークロード次第で大きく異なって現れます。層の間の価格差は、すぐに巨大な支出差に変わりかねません。たとえば、月間 100,000 件の会話を処理するカスタマーサポートのチャットボットは、Gemini 1.5 Flash で月約 $96 に対し GPT-4o で月約 $3,200 かかります — 33 倍の差 です [4]。大量のチャットや要約を走らせているなら、出力中心のプロンプトが予算の大半を食いかねません。
モデルがあなたの見えないトークンを燃やすと、コストは再び上がります。推論モデルはここにもう一層を足します。OpenAI の o シリーズは、見える答えが短くても、出力レートで課金される内部の推論トークンを生成しうります。だから、200 トークンの見える答えを持つ返信でも、3,000 推論トークン 分が課金され、実コストを 15 倍 に押し上げることがあります [10]。理論上、直し方は単純です。max_completion_tokens か thinking_budget を設定して上限を設けます [2]。
支出が安定して見えてきたら、次の問題はたいてい容量です。スケール時には、レート制限が最初のボトルネックになりがちです。ティアのアップグレードは一夜では起きないので、チームは大量トラフィックのローンチの 数週間前 から計画する必要があります。Anthropic では、Tier 1 は $5 の支払い から始まり、Tier 4 は 累計 $400 の支出 後に 4,000 RPM と 毎分 400 万入力トークン を解放します [9]。
そしてトラフィックが当たると、レイテンシが表示価格より重要になりえます。負荷下では P99 レイテンシが急上昇します。50 の同時接続 で、Gemini 2.0 Flash は 0.05% のタイムアウト率 で 3,800 ms の P99 レイテンシ を記録し、GPT-4o は 8,400 ms に達し、Claude 3.7 Sonnet は 2.8% のタイムアウト率 で 16,200 ms に達します [11]。
直接の画像生成 API
直接の画像生成 API は、たいてい 画像単位 で課金しますが、計算時間やクレジットベースの価格設定を代わりに使うプロバイダーもあります [12][14][16]。実際には、価格は主に 解像度 と 品質ティア で駆動されます。だからサムネイルとヒーロー画像の両方を作るなら、必要以上に支出したくなければ同じ経路に通さないでください。
| モデル | プロバイダー | 1 枚あたりコスト(1024px) | プレミアムティア |
|---|---|---|---|
| Flux.1 Schnell | fal.ai / Replicate | $0.003 | N/A |
| Imagen 4 Fast | $0.010 | N/A | |
| Flux 2 Pro | BFL / fal.ai | $0.030 | $0.060 |
| Imagen 4 Standard | $0.040 | $0.120 | |
| Stable Image Ultra | Stability AI | $0.080 | N/A |
| GPT Image 1.5 | OpenAI | $0.100 | $0.180(HD) |
代表的な標準 1024px の価格。プレミアムティアは利用可能な場合に表示 [13][15][16]。
チームがいつもつまずく点が 1 つあります。プロンプトあたりのコストではなく、使える画像あたりのコストを追跡する ことです。ワークフローが出荷できる画像 1 枚を得るのに 4 回の生成を要するなら、実際の単価は掲載価格の 4 倍 です。失敗したリクエスト、モデレーションによる却下、インペインティング、アップスケーリングはすべてその合計に加わります [14]。
価格は話の半分にすぎません。速度も同じくらい大きく振れます。対話的な画像アプリでは、p50、p95、TTFB、キュー待ち時間 を追跡しましょう [17]。紙の上では安く見えるモデルも、製品の中では遅く感じることがあります。Flux.1 Schnell は 1024×1024 の画像で 1.2 秒の p50 レイテンシを記録するのに対し、DALL-E 3 HD は 11.9 秒の p50 と 21.4 秒の p95 です [17]。
スケールは API の裏にある制限に依存します。そしてここで人々がよく混同します。並行性の上限 と レート制限 は同じではありません。Black Forest Labs は標準エンドポイントで 24 の同時リクエスト を強制し、Stability AI は 60 秒のタイムアウト がかかる前に 10 秒で 150 リクエストのバースト制限 を使います [16]。その違いは、ボリュームが登り始めると大いに重要になります。
大量のパイプラインには、たいてい地味だが重要なパーツがいくつか必要です。
- 非同期ポーリング
- 一時的なアセットストレージ
- 短命の URL の処理
最後の 1 つは、無視すると痛い目に遭います。たとえば BFL の URL は 10 分 後に失効するので、リンクが死ぬ前に画像を自分のシステムへ移す必要があります [16]。
ほとんどの本番チームには、ハイブリッドスタック が最も理にかなっています。サムネイルやその他の大量のアセットは高速ティアへ送ります。生のスループットより画質が重要なヒーロー画像や最終アセットには、プレミアムティアを取っておきます。
動画生成 は同じ基本パターンに従いますが、コストとレイテンシは画像単位の出力から 秒単位のレンダリング へ移ります。
直接の動画生成 API
動画は価格とキューにいっそうの圧力をかけます。計算は単純です。秒単位で支払い、配信はたいてい非同期です。2026 年には、動画 API はモデルとティアに応じて 秒あたり $0.01 から $0.25 の課金です [19][20]。低価格帯では、Vidu Q3 Turbo が $0.03/秒。高価格帯では、Seedance 2.0 Pro が $0.247/秒 に達します。同じクリップ長で 約 8 倍の差 です [20]。
そして掲載レートは出発点にすぎません。1080p が通常の本番のベースラインです。4K や Cinematic ティアに上げると、秒あたりのコストは倍に、あるいは 4 倍にもなりえます。リトライもすぐに積み上がり、つまり実際の支出はしばしば掲載価格の 1.5〜2 倍 に着地し、やり取りの多いワークフローでは 3 倍 に達することもあります [20][22]。
ただし、価格は話の一部にすぎません。レンダリング時間と成功率も、単位経済を同じくらい形づくります。10 秒の 1080p クリップは、Seedance 2.0 で 60〜180 秒、Sora で 120〜600 秒 かかることがあります [22]。だからこそ本番システムは、ジョブを送信し、ジョブ ID を返し、ウェブフックやポーリングで配信を完了すべきです [22]。動画を通常の同期 API 呼び出しのように扱おうとすると、物事はすぐにぐちゃぐちゃになります。
Sora 2 は標準的なプロンプトで 85〜90% の成功率 を平均するので、リトライと却下された出力を初日からコストモデルの一部にする必要があります [25]。動画では、秒あたりの価格以上を追跡しましょう。次のものも注視する必要があります。
- キュー深度
- 並行性
- 成功率
それらの数字は痛い目を見せます。10 の同時リクエスト で、キューの急増が 7 秒 を超えることがあり、ほとんどのアカウントは並行性を 3〜10 のアクティブな生成に制限します [22][23][24][26]。そのため、Redis や BullMQ のようなツールは、何か気の利いた追加ではなく、ローンチ前の実用的な構成になります [22]。
下書き/最終のワークフローが、たいてい最も理にかなっています。チームは Wan 2.6 や Seedance 2.0 Fast のような速いモデルでプロンプトをテストし、それから最終レンダリングにプレミアムモデルへ切り替えられます [18][20]。これで反復を安く保ち、高価な実行を出荷するバージョンのために取っておけます。
いくつかのモデル機能は、付随コストも削れます。Veo 3.1 や Kling 3.0 のようなネイティブ音声生成を持つモデルは、別途の音声やライセンスの支出を 1 本あたり $0.50〜$2.00 取り除けます [20]。Kling 2.6 と Seedance 2.0 で利用できるネイティブ 9:16 出力も、短尺のソーシャルクリップの再エンコードを避けられます [21]。
その構成は特にマーケティングチームにうまく機能します。広告のバリアントを低コストでテストし、それから勝った案だけをプレミアム品質でレンダリングできます。テキスト・画像・動画のすべてが 1 つのパイプラインで連携する必要が出てくると、統一されたアクセスがずっと有用に見え始めます。
統一 AI API プラットフォーム
統一 AI API プラットフォームは、チームがテキスト・画像・動画のリクエストを 1 つの API キー で送れるようにします。それは、製品が複数のモダリティをサポートする必要があるときに統合作業を削減します。たとえば APIMart は、テキスト・画像・動画のモデルを単一の鍵の裏に置きます。その構成は、1 つの製品が安価な日常の呼び出しと、より高価で高リスクの出力をやりくりする必要があるときに最も重要になります。
価格設定は 階層的なモデルルーティング でうまくいく傾向があります。平易に言えば、単純なタスクを低コストモデルへ送り、最上位のモデルはより難しい推論作業のために取っておきます。このアプローチは支出を大きく削減できます。特に、あらゆるリクエストを 1 つのプレミアムモデルに押しやる企業は 60〜80% 過払いしかねないからです [27]。プロンプトキャッシュも役立ちます。システムプロンプトや RAG ドキュメントを再利用すると、入力コストを 50〜90% 削減できます [5]。そしてコストを見積もるとき、表示のトークン価格で止めないでください。出力レートで課金され総支出を大きく押し上げうる推論トークンも数える必要があります [5]。
対話的な機能では、2 つの指標がすぐ重要になります。time to first token と リトライ率 です。リトライ率が低ければ、トークンあたりの価格が一見高く見えても、有用な出力あたりのコストが低くなりえます [28][29][4]。リアルタイムチャット、ストリーミング、対話的アシスタントのようなレイテンシに敏感なユースケースでは、スループットも重要です。専用ハードウェアはおよそ 毎秒 750 トークン に達しうるのに対し、標準的な H100 エンドポイントでは約 毎秒 100〜150 トークン です [29]。使用量が登り始めると、ルーティングだけでは問題は解けません。レート制限、フェイルオーバー、予備容量が同じくらい重要になり始めます。
スケーラビリティこそ、統一プラットフォームが本領を発揮し始める場所です。自動フェイルオーバールーティングはサービス中断を 65% 削減します [27]。トラフィックが増えるにつれ、チームはレート制限の余裕をリアルタイムで注視し、容量の約 80% でクライアント側で事前にスロットルすべきです。その点を超えて押すと、P95 レイテンシが 2〜5 倍 に跳ね上がりえます [30][31]。より高いボリュームでは、鍵となる問題は単なるモデルアクセスではありません。ルーティング、制限、フェイルオーバーをプラットフォームがどれだけ制御させてくれるかです。
エンタープライズ AI API スイート
ルーティングとバッチ処理だけでは足りなくなると、エンタープライズスイートが予約容量、コンプライアンス制御、契約に裏打ちされたサポートを携えて登場します。統一プラットフォームはルーティングを助けます。エンタープライズスイートはガバナンス、調達、保証された容量を扱います。
価格モデルも変わります。純粋な使用量ベースの請求の代わりに、エンタープライズ AI API スイートはしばしばチームを予約容量とカスタム契約へ移します。それは組織により予測可能なスループットを与え、規制対象のワークロードやレイテンシの急増を許容できないアプリにとって重要です。大企業はしばしば、Azure Provisioned Throughput Units や AWS Bedrock Provisioned Capacity のような選択肢を通じて予約スループットを交渉します。トレードオフは単純です。柔軟性は下がるが、支出は安定します。固定の時間単位または月単位のレートが予約容量を買います [33][28][34]。
注意すべき追加料金があります。米国内のみの推論のようなデータ所在地の保証は、基本のトークンコストに 1.1 倍の乗数 を加えうります [32][1]。長いコンテキストのプロンプトは、コストを再び押し上げえます。一部のプロバイダーは、プロンプトが 200,000 トークン を超えると 2 倍を課金します [32][1]。
サービスのコミットメントは契約によって異なります。公開 SLA はたいてい 99.5〜99.9% の稼働率 に収まり、一部の MSA の付属文書は 99.99% まで上がります [35][36]。P95 や P99 のレイテンシ目標は、たいてい標準では付いてきません。チームは通常、モデルとリージョンごとに交渉する必要があります。
サポート条件も異なります。
- Google の Premium Support ティアは、重大度 1 の問題に 15 分 をコミットする
- OpenAI Enterprise は 1 時間 を目標にする
- Anthropic Enterprise は 営業時間内で最大 4 時間 を許容する [35][36]
規制された構成では、制御スタックにたいてい VPC サービス制御、VNET 分離、Private Link、CMEK 暗号化、ゼロデータ保持(ZDR) 契約が含まれます。Anthropic の ZDR は AWS Bedrock と Google Vertex AI を通じて利用でき、Azure OpenAI は特定の Enterprise Agreement を要します [37][38][39]。
コスト制御はアクセス制御と同じくらい重要です。エンタープライズスケールでは、トークンベースの制限がしばしば最も強力なてこです。単一の 100,000 トークン の RAG クエリは、1,000 件の短いチャットリクエスト と同じだけのコストがかかりえます [40]。それは予算をすぐ吹き飛ばしかねない種類の差です。これを管理する一般的な方法は、リクエスト前に推定トークン予算を予約し、完了後に実際の総量で照合することです。
API の種類別の長所と短所
成長の各段階で コスト、速度、日々の管理 において APIMart がどう比較されるかを見る単純な方法がこちらです。下の表で素早い横並びの比較が得られます。
| スケール段階 | 長所 | 短所 | 予算への影響 | 速度への影響 | 運用への影響 |
|---|---|---|---|---|---|
| 初期 / 低ボリューム | スケール時の低い単価;単一の請求 | 利用可能なバンドルに限られる;サードパーティ依存 | 最低額なしの従量課金 | 中立;プロバイダーのインフラに依存 | 低;単一の API キーと請求関係 |
| 成長 / 中ボリューム | 階層的なモデルルーティングが支出を削減;プロンプトキャッシュが入力コストを削減 | ボリューム割引には使用量のしきい値が必要 | ルーティングとキャッシュで大きな節約 | 小さなルーティング遅延;ほとんどのワークロードで最小 | 低;フェイルオーバーとルーティングはプラットフォームが処理 |
| 高ボリューム / 本番 | 非同期バッチがトークンコストを 50% 削減;エッジ配信がグローバルなレイテンシを削減 | バッチジョブは同期呼び出しより配信遅延が加わる | Batch API とボリューム価格で最低の単価 | 安定したスループット;非同期ジョブがレート制限のボトルネックを回避 | 低;ダッシュボード、上限、アラートがコスト制御を集約 |
これらのトレードオフを使って、API をユースケースに対応づける前に選択肢を絞りましょう。
自分のユースケースに合う AI API の選び方
上の比較を使って、品質とレイテンシの目標をなお満たす 最も低コストのモデル を選びましょう。そうする最も単純な方法は、主な制約から始めることです。
予算が最大の要因なら、最低限の品質基準をクリアする最も安いモデルから始めます。そして、的を外したときだけ上位へ移ります。速度が最も重要なら、高速な応答のために作られたモデルへ傾き、ローンチ前に実際のプロンプトテンプレートで p50 と p95 のレイテンシ をテストします。その部分は、多くのチームが思う以上に重要です。クロスリージョンの呼び出しは数百ミリ秒を加えうります [3][42]。
出力品質を落とせないなら、たいていフロンティアモデルが最も理にかなっています。ただし、モデル層の間には大きな価格の跳ね上がりがあります [1]。
何かを確定する前に、汎用のベンチマークプロンプトではなく、実際のユースケースからの 30〜50 件の実プロンプトでパイロットを実行 しましょう [42]。それが、何を買おうとしているかをずっと明確に読み取らせてくれます。測定するのは、
- 品質
- コスト
- 生のレイテンシ
そうすれば、ワークロードが 実際に どのモデル層を必要とするかが見えます。
パイロットのあと、負荷テストと予算制御へ移ります。現実的な並行性レベルで負荷テストし、プロバイダーレベルでハードな日次の支出上限を設定し、機能ごとのコスト異常にアラートを追加します [44][43]。このステップは、まだ小さく見えるときに飛ばしがちです。コストが忍び寄ってくる場所でもあります。
本番のトークン使用量は、プロンプトが長くなりエッジケースが積み上がるにつれ、プロトタイプからローンチまでに 5〜15 倍 増えることがよくあります [41]。その余裕を初日からコストモデルに組み込みましょう。
また、ルーティング・コスト・レイテンシがトラフィックの増加とともに見えたままになるよう、すべてのリクエストを APIMart でログに残しましょう — モデルバージョン、トークン数、機能名、レイテンシです [42][43]。
よくある質問
自分の本当の AI API コストをどう見積もればいい?
基本のトークンあたりレートの先を見て、リクエストの全ライフサイクル を見積もりましょう。この式から始めます。
月額コスト = (1 日のリクエスト数 × 30) × ((入力トークン × 入力価格) + (出力トークン × 出力価格)) ÷ 1,000,000
そこから、実際に現れる追加のコスト要因を織り込みます。
出力トークンはしばしば入力トークンより 3〜10 倍 高くつくので、長い答えはすぐに計算を変えます。マルチターンのチャットも、新しいメッセージごとに走るコンテキストにトークンを加えるためコストを押し上げます。さらに、リトライはたいてい 5〜15% を加えます。特にリクエストが失敗したりタイムアウトしたりするときです。
エージェント的ワークフローやツール呼び出しを使っているなら、跳ね上がりはもっと大きくなりえます。それらの構成は、1 つのユーザーアクションが 1 回ではなく複数のモデル呼び出しを引き起こしうるため、1.5〜10 倍 を加えうります。
支出を削れるてこが 1 つあります。プロンプトキャッシュ です。構成が対応していれば、キャッシュされた入力トークンのコストは 50〜90% 下がりえます。同じシステムプロンプトや繰り返しのコンテキストが多くのリクエストにまたがって現れるとき、大きな効果を出せます。
ローンチ前に最も重要な指標は?
ローンチ前は、安定性とコスト予測のバランスを取る指標に集中しましょう。
- p50 と p95 のレイテンシ
- リトライとフェイルオーバーを含むタスク成功率
- 代表的なプロンプト形状、入出力トークン数、予測される月次ボリュームに基づく実効価格
- 公開されたレート制限に対するスループットと並行性
ローンチ後の驚きを避けるため、本番に近い環境でテストしましょう。
バッチや非同期ジョブをいつ使うべき?
即時の返信が要らないときに、バッチや非同期ジョブを使いましょう。そのトレードオフはコストを 最大 50% 削減でき、非緊急の作業にこのアプローチが合います。
良い例には次のものがあります。
- 大規模な文書要約
- 動画分析
- 夜間のデータ処理
これらのジョブは、最大 24 時間 待てるなら理にかなっています。
逆に、速いフィードバックに依存するユーザー向けの機能には使わないでください。それにはチャット、オートコンプリート、リアルタイムのレコメンドが含まれます。人が座って待っているなら、非同期ジョブはたいてい間違ったツールです。
付随する配管もいくらかあります。ジョブが完了したら、キューイング、ポーリング、結果の照合のためのロジックが必要になります。