
統合AI API設計:ベストプラクティス
抽象化レイヤー、標準スキーマ、プロバイダー分離、オブザーバビリティ、バージョニング、セキュリティを網羅した統合AI API設計の開発者向けガイド。
統合AI APIは、GPT-5、Claude、画像・動画生成モデルなど多様なプロバイダーへの単一インターフェースを提供することで、複数のAIモデルを扱う際の複雑さを軽減します。このアプローチにより、プロバイダーごとに個別のSDK、認証プロセス、カスタム統合が不要になります。目的は、複雑さを削減し、効率を向上させ、テクノロジーの進化に合わせてモデルの切り替えや組み合わせを容易にすることです。
主要なポイント:
- 統合抽象化レイヤー: 各種AIプロバイダーとのやり取りを標準化し、アプリケーションが一つのインターフェースのみを操作するようにします。
- 標準化スキーマ: 一貫したリクエスト・レスポンス形式を使用して、マルチモデル統合を効率化します。
- プロバイダー分離: アダプターを実装することで、コアコードにプロバイダー固有のロジックを埋め込むことを避けます。
- オブザーバビリティ: レイテンシー、トークン使用量、エラー率を追跡してパフォーマンスを監視します。
- バージョニング: 後方互換性を確保し、モデルを特定バージョンに固定することで安定性を維持します。
- セキュリティ: 認証を集中管理し、入出力を検証し、レート制限を実装します。
例えば、APIMart のようなプラットフォームは、集中課金と自動フェイルオーバーなどの機能とともに500以上のモデルにアクセスできる統合APIを提供しています。これにより、AI統合の管理がよりシンプルで信頼性の高いものになります。
統合API vs. ワークフロー自動化:開発者はどちらを選ぶべきか?
統合抽象化レイヤーを定義する
統合抽象化レイヤーは、アプリケーションと使用するAIプロバイダーの間の橋渡しとして機能します。各プロバイダー固有のインターフェースに適応する代わりに、アプリケーションはリクエストとレスポンスを変換する単一の標準化インターフェースと対話します。AI Roadsは次のように説明しています:
「統合APIレイヤーの核心的な価値は、マルチプロバイダーの差異を限定された境界にまとめ、上位レイヤーが安定したコントラクトに向き合えるようにすることです。」[2]
このアプローチはビジネスロジックを合理化します。プロバイダーがスキーマを更新したり新しいモデルが利用可能になったりしても、抽象化レイヤーを調整するだけで済み、コードの他の部分には手を触れる必要がありません。
最小限の有用なインターフェースから始める
最初からすべての機能を含めようとしないでください。ほとんどのプロバイダーが共有する本質的な要素に集中しましょう。リクエストには model、messages、temperature、max_tokens などのパラメーターが含まれます。レスポンスには answer、usage、finish_reason などの出力を標準化します [2][3]。
まずリクエスト構造を定義し、次にレスポンスを正規化します。エラー処理とログを随時追加し、複雑なルーティングは後回しにします。インターフェースを早期に複雑にしすぎると、新しいプロバイダーを追加する際に脆弱な設計につながる可能性があります。
Nullableまたは欠損プロパティを処理する
モデルによってサポートするパラメーターが異なります。例えば、GPT-5は temperature パラメーターを使用しますが、Sora のような動画生成モデルは使用しません。これを管理するために、各モデルの機能メタデータオブジェクトを使用します。has_temperature、supports_json_schema、supported_modalities などのプロパティを追跡します [3]。これにより、抽象化レイヤーがサポートされていないパラメーターを下流に送信する前にこれらのフラグを確認できます。
レスポンス処理については、プロバイダー固有のフィールドをデフォルトでNullableにします。特定のモデルから finish_reason などのフィールドが返されない場合、抽象化レイヤーはデフォルト値または null を提供することで適切に処理する必要があります。混乱を避けるために、必須フィールドと任意フィールドを明確に文書化してください。
この設定はパラメーター管理を簡素化するだけでなく、複数のモデルとのシームレスな統合にシステムを備えさせます。
例:APIMart によるマルチモデル統合
APIMart は、この抽象化が実際にどのように機能するかを示しています。統合APIを通じて、開発者はGPT-5やClaudeなどの言語モデルから、Sora 2 Preview($0.08/秒)やKling V3(720Pで$0.0672/秒)などの動画生成モデルまで、500以上のモデルにアクセスできます。インターフェースはOpenAIのAPIと互換性があるため、開発者は同じ統合を使用して、あるモデルでテキストスクリプトを生成し、別のモデルで動画を制作することができます。複数のSDK、認証システム、レスポンスパーサーを扱う必要はありません。
この統合アプローチは開発を簡素化し、幅広いAI機能にアクセスするための単一の信頼性の高いインターフェースを提供します。
リクエストおよびレスポンススキーマを標準化する
マルチモデル統合をシームレスにするためには、リクエストとレスポンスに対して一貫したプロバイダー非依存スキーマを確立することが不可欠です。このアプローチにより、プロバイダー固有の条件分岐が不要になり、ビジネスロジックがよりクリーンになり、統合抽象化レイヤーが効果的に機能します。
Charlie Hollandが説明するように:「JSON Schemaはスキーマ定義の『アセンブリ言語』となり、高レベル言語はそれにコンパイルされます」[5]。つまり、単一のスキーマコントラクトを作成することで、すべてのプロバイダーがネイティブフォーマットに関係なく同じ構造に準拠するようになります。
マルチモーダル入力を正規化する
一貫性のために、すべての入力タイプで統一された type フィールドを使用します。動作は次のとおりです:
- テキスト:
{"type": "text", "text": "..."}として表現。 - 画像:
image_urlとオプションのdetailパラメーター("low"、"high"、または"auto"に設定可能)を使用。 - 動画:
task_idと非同期処理用のWebhookコールバックURLで処理 [7]。
detail パラメーターは特にトークン使用量の最適化に役立ちます。例えば、細かいディテールが不要な場合に "low" を選択するとトークン消費を削減できます。
入力が正規化されたら、次のステップはエラーとメタデータを標準化して、すべてのやり取りにわたって均一性を確保することです。
エラー形式とレスポンスメタデータを標準化する
エラーは一貫性を維持するために4フィールド構造に従う必要があります:
code:安定したバージョン管理された識別子。category:機械可読カテゴリ(例:auth_required、rate_limit、validation、transient、またはpermanent)。message:人間が読める説明。details:明確なリトライ指示とフィールド固有のガイダンス [8]。
Spec Coding Editorial Teamは次のように述べています:
「修正策はより良い文章ではありません。修正策は、機械を主要な読者として、人間を二次的な読者として扱うエラーエンベロープです」[8]。
さらに、すべてのレスポンスには追跡用の trace_id と、プロバイダー間のコスト監視のための prompt_tokens、completion_tokens、total_tokens などの標準化された使用フィールドを含める必要があります [9][2]。X-RateLimit-Remaining や X-RateLimit-Reset などのヘッダーは、429 エラー時だけでなく、すべてのレスポンスに含めて、クライアントがリクエストペースを積極的に管理できるようにする必要があります [10]。
スキーマ比較表
さまざまなレイヤーにわたる主要な標準化フィールドの内訳を以下に示します:
| レイヤー | 標準化フィールド | 目的 |
|---|---|---|
| リクエスト | model, provider, messages, parameters | ベンダーSDK向けの統一入力フォーマットを提供 [2][3] |
| レスポンス | answer/content, usage, model_id | ビジネスロジック向けの一貫した構造を確保 [2] |
| 使用状況 | prompt_tokens, completion_tokens, total_tokens | コストとクォータ追跡を集中管理 [2][6] |
| エラー | code, category, message, details | 統一されたエラー処理と自動フォールバックを実現 [8] |
| ログ | trace_id, latency_ms, cost, timestamp | オブザーバビリティと予算追跡をサポート [2][3] |
スキーマ検証のストリクトモード
スキーマを検証する際は、本番環境でストリクトモードの採用を検討してください。JSONが解析可能なことのみを確認する標準JSONモードとは異なり、ストリクトモードは出力がスキーマに正確に一致することを強制します [4]。構造的な適合性を保証する一方で、ビジネスルールの検証は行わないことに注意してください。この精度の向上により、システムの一貫性と信頼性を確保できます。
プロバイダー固有のロジックを分離する
スキーマを標準化したら、次の課題はプロバイダー固有のロジックをコアコードに直接埋め込むことを避けることです。例えば、コードベース全体で openai.chat.completions.create() のような呼び出しに過度に依存すると、フォールバックモデルを追加したりプロバイダーを切り替えたりする際に悪夢となります。エンジニア・ファウンダーのTian Panは次のように説明しています:
「プロバイダーの切り替えやモデルバージョンのアップグレードにかかるエンジニアリングコストは、統合時に行われた決定によって大部分が決まります。」[11]
これに対処するスマートな方法は、プロバイダーアダプターパターンを使用することです。基本的に、各プロバイダーに対して薄いアダプターを作成し、安定した内部インターフェースに準拠させます。プロバイダーがスキーマやエラー処理を更新した場合、特定のアダプターを調整するだけで済み、コードベース全体を修正する必要はありません。このパターンは統合操作とプロバイダー固有の特性をきれいに分離し、システムをより柔軟で保守しやすくします。
認証とトークン処理を集中管理する
ロジックがコード全体に分散していると、認証はすぐに混乱を招きます。プロバイダーによって、キーフォーマット、トークン更新サイクル、ヘッダー規約が異なります。これらのタスクを専用の認証レイヤーに集中させることで、コードをクリーンに保ち、監査を簡素化できます。優れた認証レイヤーは以下を処理する必要があります:
- アプリレベルの単一キー管理:アプリケーションレベルで1つのAPIキーを使用し、プロバイダーキーとOAuthトークンの処理は抽象化レイヤーに任せます [11]。
- バックエンドサービスのマネージドID:プロバイダー固有のキーのハードコーディングや手動ローテーションを避けます [12]。
- レート制限とサーキットブレーカー:ローカルでレート制限を実装し、繰り返しエラーやレイテンシースパイクの後、障害を起こしているプロバイダーへのリクエストを一時停止するステートマシンを使用します [11]。
- メタデータ伝播:一貫したログと追跡のために、リクエスト識別子、コストセンター、ユーザー情報を伝達します [11]。
このアプローチの好例は、Uniperです。2026年2月にAPIマネジメントを刷新したヨーロッパのエネルギー会社です。Azure API Managementを使用して、API Centre of Excellence LeadのIan Beesonと、Head of Cloud EngineeringのHinesh Pankhania は、API定義を7つの環境からシングルワイルドカード定義に削減し、85%削減を達成しました。また、自動フェイルオーバーとサーキットブレーカーにより99.99%の可用性を実現しました [12]。
認証を集中化することで、一般的なタスクを簡素化しながら、プロバイダー固有の操作をそれぞれのアダプターに委ねることができます。
統合 vs. プロバイダー固有の動作
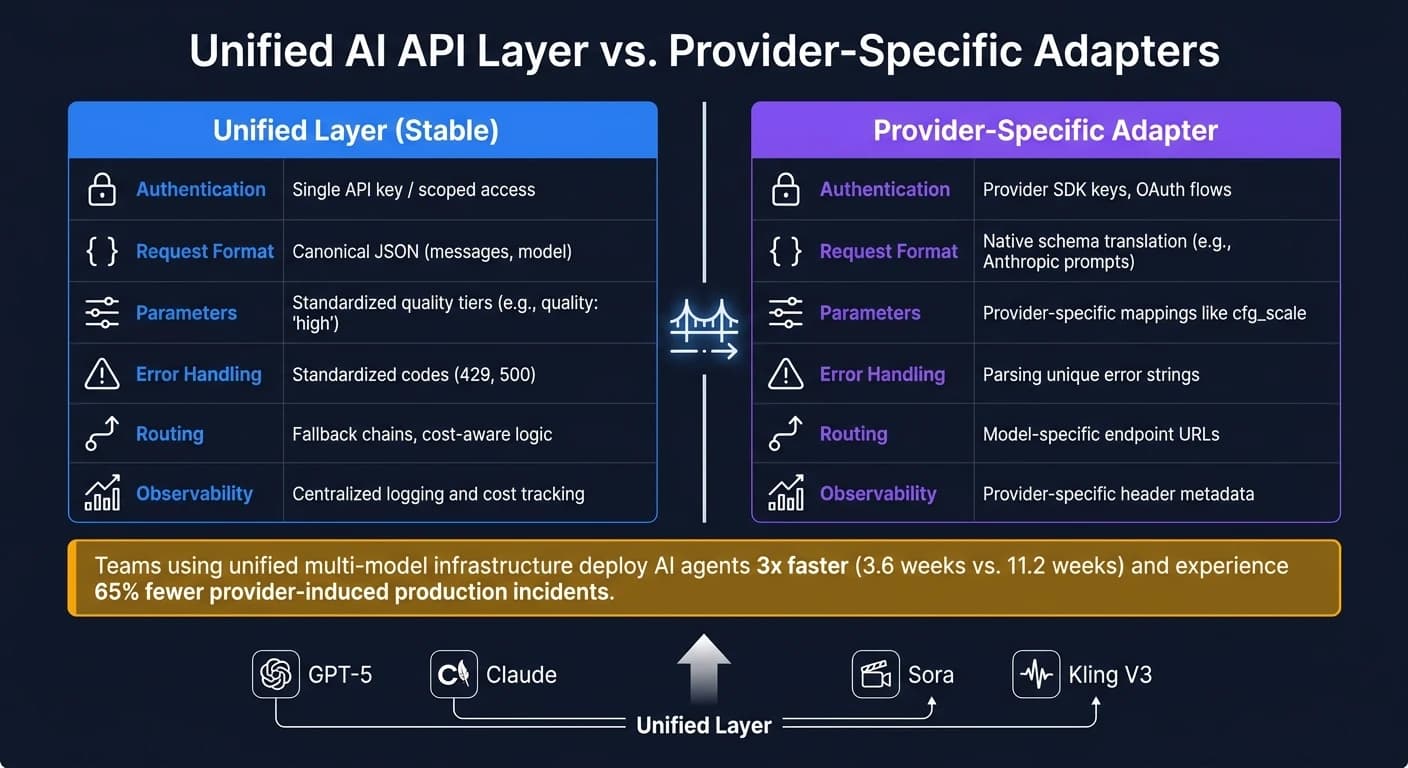
統合レイヤーに何を含めるべきか、プロバイダー固有のアダプターに何を属させるべきかの適切なバランスを取ることが重要です。以下にその内訳を示します:
| 機能 | 統合レイヤー(安定) | プロバイダー固有アダプター |
|---|---|---|
| 認証 | 単一APIキー / スコープ付きアクセス [12] | プロバイダーSDKキー、OAuthフロー [12] |
| リクエスト形式 | 正規JSON(messages、model) [2] | ネイティブスキーマ変換(例:Anthropicプロンプト) [2] |
| パラメーター | 標準化された品質ティア(例:quality: "high") [13] | cfg_scale などプロバイダー固有のマッピング [13] |
| エラー処理 | 標準化コード(429、500) [2] | 固有エラー文字列の解析 [2] |
| ルーティング | フォールバックチェーン、コスト考慮ロジック [11] | モデル固有のエンドポイントURL [11] |
| オブザーバビリティ | 集中ログとコスト追跡 [11] | プロバイダー固有のヘッダーメタデータ [11] |
有用な戦略の一つはモデルエイリアシングです。gpt-4o や claude-opus-4 などの具体的な識別子をハードコーディングする代わりに、fast-cheap や reasoning-heavy などの汎用識別子を使用します。抽象化レイヤーがこれらのエイリアスを最適なプロバイダーモデルにマッピングし、将来の更新をはるかに容易にします [11]。
統合をやめるタイミング
統合抽象化の構築は有用ですが、どこまで進めるかには限界があります。例えば、あるモデル(Claude Mythosなど)向けに最適化されたプロンプトは、別のモデル(GPT-5.5など)では良好に機能しない場合があります。統合レイヤーは一貫したインターフェースを維持しながら、必要に応じてプロバイダー固有のプロンプトテンプレートも許可する必要があります [2]。
同様に、過度な抽象化は独自の問題セットを生み出す可能性があります。プロバイダーが独自のツール呼び出し形式や他ではサポートされていないベータ機能など、ユニークな機能を提供する場合、パススルーエンドポイントを実装する方が良いでしょう。これにより、生のリクエストが汎用スキーマに強制されることなくプロバイダーに直接送信されます。目標は、ビジネスロジックのための安定したインターフェースと、価値あるプロバイダー固有機能へのアクセスのバランスを取ることです [14]。
「重要なのは、どのツールを選択するかではなく、そのレイヤーが必要になった後ではなく、前に存在することです。」 - Tian Pan、エンジニア・ファウンダー [11]
信頼性とオブザーバビリティを考慮して構築する
抽象化レイヤーを確立したら、次のステップはそれを本番環境に対応させることです。標準的なWebAPIとは異なり、統合AI APIは適切な監視なしに見過ごされやすい独自の障害モードを導入します。これに対処するために、堅牢なログと監視が不可欠です。
ログと監視を設定する
AIAPIには従来のアップタイムチェックでは不十分です。標準的なHTTPメトリクスに加えて、最初のトークンまでの時間(TTFT)、1秒あたりのトークン数(TPS)、レート制限余裕(TPM/RPM)を監視する必要があります [15][18]。すべてのリクエストに対して、完全なプロンプト、レスポンス、レイテンシー、トークン数、一意のリクエストIDを含む構造化JSONデータをログに記録します [16][17]。
p50、p95、p99レベルのレイテンシーメトリクスに細心の注意を払ってください。p95レイテンシーのスパイクは、完全な障害に発展する前に上流の問題を示すことが多いです [15][18]。レート制限の使用率が**70%**に達したらアラートを設定し、予期しないトラフィックスパイクが制限を超える前に対応する時間を確保します [15][18]。
| シグナル | 測定内容 | アラート閾値の例 |
|---|---|---|
| レイテンシー | p95/p99 TTFTと総処理時間 | 5分間でp99 > 5秒 |
| トラフィック | 1秒あたりのリクエスト数(RPS) | RPSが1時間平均比で>50%減少 |
| エラー | 5xxと429のレート | 2分間で5xxレート > 1% |
| 飽和度 | TPM/RPMの使用率 | レート制限余裕 < 20% |
「30秒でその質問に答えられるチームは監視が整っているチームです。20分かかるチームは、インシデント中に初めてこのガイドを読んでいるチームです。」 - API Status Check [15]
障害とグレースフルデグラデーションに備える
リアルタイムログを設定したら、次のステップは不可避の障害に備えることです。
LLM APIは通常99.7%の可用性を提供しており、年間約22時間のダウンタイムに相当します [19]。例えば、2025年12月には主要なAIプロバイダーがわずか1ヶ月で47件のインシデントを報告しました [21]。システムはクラッシュする代わりに、これらの障害を適切に処理する必要があります。
異なるエラータイプには適切な対応が必要です。429(レート制限)や 500/503(サーバーエラー)などの一時的なエラーは、指数バックオフとランダムジッターを使用したリトライをトリガーする必要があります。ジッターにより、回復中のシステムに同期したリトライが集中することを防ぎます [19][21]。一方、400、401、404 などの永続的なエラーは即座に失敗させる必要があります。リトライは、不正なリクエストや無効なAPIキーなどの問題を解決しません [19]。
カスケード障害を最小化するために、繰り返し障害の後にリクエストを一時停止するサーキットブレーカーを実装し(例:30秒のクールダウン)、テストリクエストで再開します [20][22]。これを「プライマリー → セカンダリー → 緊急」のフォールバックチェーンと組み合わせて、プロバイダーが完全に停止してもアプリケーションを機能させ続けます。研究によると、サーキットブレーカーとフォールバックチェーンを使用することで、ユーザー向けのAIエラーを**91%**削減できます [19]。すべてが失敗した場合は、キャッシュされたデフォルトレスポンスを返すか、非AIオプションに完全に切り替えます [18]。
入力、出力、バックグラウンドタスクを検証する
データの整合性を確保することは、信頼性を維持し、コストのかかるミスを避けるために重要です。
入力検証は、深刻な問題を引き起こすまでしばしば見過ごされます。あるスタートアップは、エンドポイントに max_tokens パラメーターを設定し忘れたために、月額**$47,000**の請求に直面しました [19]。常に max_tokens を明示的に定義し、プロバイダーに到達する前にコンテキストオーバーフローを防ぐためにリクエスト時にトークン数を見積もってください [19][23]。
出力については、PydanticやJSONスキーマ検証などのツールを使用して構造化レスポンスを強制し、責任をプロンプトからコードに移すことで管理が容易になります [24]。また、メインLLM呼び出しと並行して毒性とPIIチェックを実行します [24]。品質を維持するために、OpenAI o3のような高推論モデルを使用して低コストの本番モデルを定期的に評価します。これにより、メトリクスだけでは現れない可能性のある静かな品質劣化を検出できます [17]。
「プロンプトエンジニアリングは本質的に確率の演習です...本番環境では、『ほぼ正しい』は『壊れている』と同義です。」 - Nino、シニアテックエディター、n1n.ai [24]
バージョニングとスキーマ変更に対応した設計
統合AI APIを開発する際、バージョニングはモデルの進化に伴う安定性の維持において重要な役割を果たします。これは信頼性とオブザーバビリティの標準的な実践を超えるもので、時間の経過に伴う構造と動作の一貫性を確保します。
統合AI APIは2つの重要なコントラクトを持ちます:構造的コントラクト(JSONスキーマで定義)と動作的コントラクト(モデルが実際にどのように応答するか)。ほとんどのバージョニング戦略は構造的側面に集中していますが、動作的側面を無視すると静かな障害につながる可能性があります。両方に対処することで、ユーザーにとって信頼性を確保する安定した抽象化レイヤーを作成できます。
変更を後方互換性を保つ
既存の統合を壊さないために、追加優先アプローチを採用してください。これは、既存のものを変更または削除するのではなく、オプションフィールドや新しいエンドポイントを導入することを意味します。クライアントが「寛容な読者」として機能するよう促し、レスポンスの未知フィールドを適切に処理するようにします。このアプローチは更新時の混乱を最小化します [27][28]。
よくある落とし穴の一つはモデルエイリアシングです。スタンフォードとUCバークレーによる2023年の研究では、GPT-4の素数タスクの精度が汎用エイリアスの背後にある変更により、わずか3ヶ月で84%から51%に低下したことが明らかになりました [26]。解決策はスナップショットピンニングです。フローティングエイリアスの代わりに gpt-4o-2024-08-06 のような明示的な日付スタンプ付きモデル識別子を使用します。このアプローチは動作を固定し、時間の経過に伴う静かな変化を防ぎます [25][26]。
「モデルエイリアスは安定したコントラクトではありません...暗黙のコントラクトは静かに壊れます。」 - Tian Pan、エンジニア・ファウンダー [26]
構造を超えて、動作エンベロープを監視することが重要です。精度、レスポンスの長さ、拒否率などのメトリクスの統計的境界です。モデルの更新がこれらの分布を変更した場合、スキーマが変わらなくても破壊的変更として扱います [25]。
後方互換性を確保したら、次のステップは更新と廃止を効果的に伝達することです。より多くの技術的洞察については、APIMart Blog をご覧ください。
廃止と新機能を伝達する
クライアントが変更に適応できるよう、明確かつタイムリーなコミュニケーションが不可欠です。業界標準では、機能を廃止する前に最大12ヶ月の廃止期間と90日の最低通知期間を推奨しています [30][31]。
Sunset HTTPヘッダー(RFC 8594)と Link ヘッダーを使用して移行ドキュメントを提供します [27][30]。APIレスポンスに model_deprecated_at フィールドを含めることで、クライアントが今後の変更を自動的にログに記録してアラートを設定できます [25]。これらの通知を見逃す可能性のあるチームのために、廃止されたエンドポイントの短期スロットリング期間である「ブラウンアウト」の実装を検討してください [27]。
「そのヘッダーは機械可読です。クライアントはそれに対してアラートを設定できます。使用してください。」 - Madhuban Mukherjee、Cadence blog [31]
2026年までに、/api/changelog.json エンドポイントを提供することが推奨されます。これには、重大度レベル、影響を受けるフィールド、移行リンクなどの詳細を含める必要があります。AIエージェントがAPIを直接消費するようになるにつれ、電子メール通知のみに依存することはもはや十分ではありません [28][32]。
破壊的変更 vs. 非破壊的変更:比較
| 変更タイプ | 破壊的? | 管理アクション |
|---|---|---|
| 新しいオプションフィールド | いいえ | 自由にデプロイ;ドキュメント更新 [33] |
| 新しいエンドポイント | いいえ | 自由にデプロイ [33] |
| パフォーマンス / レイテンシー改善 | いいえ | 動作ドリフトを監視 [30] |
| フィールドの名前変更または削除 | はい | バージョンバンプ + 廃止通知 [29][33] |
| 新しい必須フィールド | はい | バージョンバンプ + 移行ガイド [33] |
| 型変更(例:文字列→整数) | はい | バージョンバンプ必須 [33] |
| モデルのトーンや推論の変化 | はい | スナップショットピンニング + シャドウテスト [25] |
トーンや推論の変化などの動作的変更には慎重な管理が必要です。スナップショットピンニングとシャドウテストは、下流のユーザー体験を妨げないために不可欠です。Tian Panが説明するように、「核心的な洞察は、AIエンドポイントには2つの異なるコントラクトがある:構造的コントラクトと動作的コントラクト」[25]。モデルのトーンがプロフェッショナルからカジュアルに変わるような微妙な変化は、フィールド名の変更と同様にユーザーの期待を壊す可能性がありますが、気づきにくい方法で起こります。
統合APIを保護する
統合APIの保護は、マルチモデル統合を守るために不可欠です。2022年から2025年の間にAPIトラフィックが300%急増し、80%以上の企業がサービス提供にAPIを依存している中、リスクはかつてないほど高まっています [34]。統合AI APIは特に脆弱で、単一の侵害されたエンドポイントが多数のモデルとデータストリームへのアクセスを露出させる可能性があります。
認証とスコープ付きアクセスを設定する
SPAやモバイルアプリなどのパブリッククライアントに対して、2026年のベースライン標準は OAuth 2.1 with PKCEであり、ImplicitやResource Owner Password Credentialsグラントなどの古くて安全でないフローを置き換えます。サービス間通信には、簡単に漏洩する可能性のある静的APIキーよりも、mTLSまたは SPIFFE-ベースのワークロードIDが推奨されます。トークンセキュリティを強化するために、「alg: none」攻撃などの脆弱性を軽減する PASETO をJWTの代わりに採用してください [35]。
「認証はアイデンティティを確認し(あなたが誰であるか)、認可は権限を決定します(あなたが何をできるか)。認証は認可に先行します。」 - API7.ai [34]
各クライアントが必要なものにのみアクセスできるよう最小権限スコープを実装します。5〜15分のTTLのアクセストークンを使用し、必要に応じて更新します [34][35]。署名キーを四半期ごとにローテーションし、プロセスを自動化して人的エラーを最小化します [35]。管理ダッシュボードには、認証情報を保護するために**多要素認証(MFA)**を適用します [36]。
強固な認証フレームワークが整ったら、次のステップはAPIの入力と出力の検証に集中することです。
すべての入力と出力を検証する
OpenAPI 3.1またはJSON Schemaなどのツールを使用したスキーマベース検証を使用して、すべての入力を厳密にチェックします。AI固有の脆弱性には、プロンプトインジェクションに対する防御を実装します。キーワードフィルタリング、正規表現パターン、セマンティック分析を使用して、ジェイルブレイクの試みがモデルに到達する前にブロックします [36][39]。制御を維持するために常にサーバー側で検証を実施します。
出力側では、データ転送オブジェクト(DTO)またはシリアライザーを使用して、共有すべきフィールドのみにレスポンスを制限し、内部ID、スタックトレース、またはデータベースメタデータが露出するリスクを軽減します [38][39]。PII、PHI、PCI情報を含む機密データの漏洩を検出してブロックするためのゲートウェイレベルのDLPスキャンを追加します [36]。エラーレスポンスを処理する際は、RFC 7807に準拠した汎用メッセージを返しながら、詳細な診断情報を内部システム内に安全にログに記録します。
「ゼロトラストのルール:証明されるまで、すべてのAPI呼び出し元を潜在的な脅威として扱います。すべてを検証し、すべてをログに記録し、防御がテストされることを前提とします。」 - AquilaX [40]
データフローの検証は方程式の一部に過ぎません。セキュリティポリシーを定期的にレビューすることで、防御の有効性を維持します。
定期的なスケジュールでセキュリティポリシーをレビューする
監視がシステムの健全性を維持するのと同様に、定期的なセキュリティレビューはAPI整合性を保護するために不可欠です。継続的なメンテナンスなしでは、セキュリティ対策は時間とともに劣化する可能性があります。トークンスコープとシークレットローテーションスケジュールを含むアクセス制御の四半期レビューを実施します。スコープクリープを防ぐためにサービスアカウントを監査します [37]。
APIゲートウェイは中央施行ポイントとして機能し、トークン検証、ポリシー評価、すべてのアクセス決定のログを処理する必要があります。また、必要に応じてアクセストークンを自動的に期限切れにする必要があります [37]。AIエージェントがタスクを自律的に実行するようになるにつれ、ゼロスタンディングトラストの採用が実用的な必要性となります。認証情報は特定のタスクのために発行され、時間制限があり、目的主導型です [37]。
結論:統合AI API設計の主要なポイント
これで、この記事で議論された統合AI API設計の核心的なアイデアをまとめます。
統合AI APIの構築を選択することは、速度、信頼性、保守性を向上させたいチームにとってスマートな選択です。統合マルチモデルインフラストラクチャを使用するチームは、本番AIエージェントを3倍速くデプロイします(11.2週間に対して3.6週間)。また、65%少ないプロバイダー起因の本番インシデントを扱います [1]。
ここで概説された主要な実践は協調して強固なフレームワークを作成します。抽象化は複雑なプロバイダー固有の詳細を単一のユーザーフレンドリーなインターフェースに簡素化します。標準化スキーマは異なるモデル間でリクエストとレスポンス形式の一貫性を確保します。プロバイダー分離は単一ベンダーの問題によって引き起こされる障害からシステムを保護します。オブザーバビリティ(トークン、リクエスト時間、モデルIDの詳細なログを通じて)はデバッグとパフォーマンス最適化のための重要な可視性を提供します。バージョニングはモデルが更新される際の予期しない変更から本番環境を守ります。最後に、集中認証や定期的なポリシーレビューなどの堅牢なセキュリティ対策は、スケールに応じてAPIを安全に保ちます。これらの原則が合わさって、優れた統合AI APIの基盤を作ります。
「統合AIゲートウェイパターンは、エンタープライズ全体でAIをスケールし統治する方法を根本的に変えました...このアプローチにより、パフォーマンス、可用性、またはガバナンスを犠牲にすることなく、AIエコシステムが要求するペースで新しいモデルと機能を採用できます。」 - Hinesh Pankhania、Head of Cloud Engineering & CCoE、Uniper [12]
Uniperの2026年2月の実装は好例です。99.99%の可用性を達成し、定義を統合することでAPIマネジメントのオーバーヘッドを削減しました [12]。
独自の抽象化レイヤーの構築という重労働をスキップしたいチームには、APIMart が堅実な選択肢です。GPT-5、Claude、Sora、Kling V3を含む500以上のモデルをサポートする単一のOpenAI互換APIを提供しています。集中課金、マルチモーダルサポート、競争力のある価格設定などの機能により、AIモデルへの統合アクセスの容易な出発点となっています。
よくある質問
統合AI APIの最初のバージョンに何を含めるかをどう決めますか?
最初に、プロバイダー固有のロジックをコアビジネスコードから分離する強固な境界の構築を優先してください。これは、いくつかの重要な要素を標準化することを意味します:リクエスト構造、レスポンス形式、エラー処理、ログ。これにより、アプリケーションを異なるモデルの特性から効果的に保護できます。
さらに、トークン使用量、モデルID、リクエスト時間などのメタデータを含めてください。これらの詳細はパフォーマンスの追跡とトラブルシューティングに非常に価値があります。バージョニングとデザインファーストの考え方を採用することで、将来の更新がはるかにスムーズになり、大幅なコードの見直しが不要になります。
APIはどこにでも存在しないモデル機能をどのように処理すべきですか?
モデル間の機能の違いを処理するには、統合APIレイヤーを使用することが賢明です。これにより、プロバイダー間の差異が集中管理され、コアビジネスロジックから除外されます。APIMart などのツールにより、モデル機能、トークン制限、設定オプションを探索する機能が提供され、このプロセスが容易になります。これらの違いをアダプテーションレイヤーに分離することで、カスタムコードを書くことなく、ツールサポートやエラー処理などのプロバイダー固有の特性を管理しながら、一貫したインターフェースを維持できます。
アプリを壊さずにモデルバージョンの変更を管理する最も安全な方法は何ですか?
AIモデルに依存するアプリを構築する際、最も安全な方法はモデル抽象化レイヤーを使用することです。このアプローチにより、アプリのロジックがさまざまなプロバイダーの特定のAPIから分離されます。APIMart などのツールにより、コードの変更なしに設定更新だけでモデルを切り替えることができ、作業が簡素化されます。
安定性を確保するために、以下の主要な実践を覚えておいてください:
- 特定のモデルスナップショットを固定する:予期しない変更を避けるために、例えば
gpt-4o-2024-08-06のようなバージョンを使用します。 - 出力スキーマを強制する:これにより一貫したフォーマットが維持され、「フォーマットドリフト」が防止されます。
- シャドウテストとカナリーロールアウトを実装する:これらの方法により、完全にロールアウトする前に変更を安全に監視できます。
これらのステップに従うことで、モデルが進化してもアプリを安定した適応力のある状態に保つことができます。
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。