
더 빠른 미디어 파이프라인을 위한 AI 압축
비디오, 이미지, 텍스처, 3D 파이프라인을 위한 AI 압축 기술과 함께 더 빠른 전송과 낮은 스토리지 비용을 위한 워크플로 패턴을 살펴봅니다.
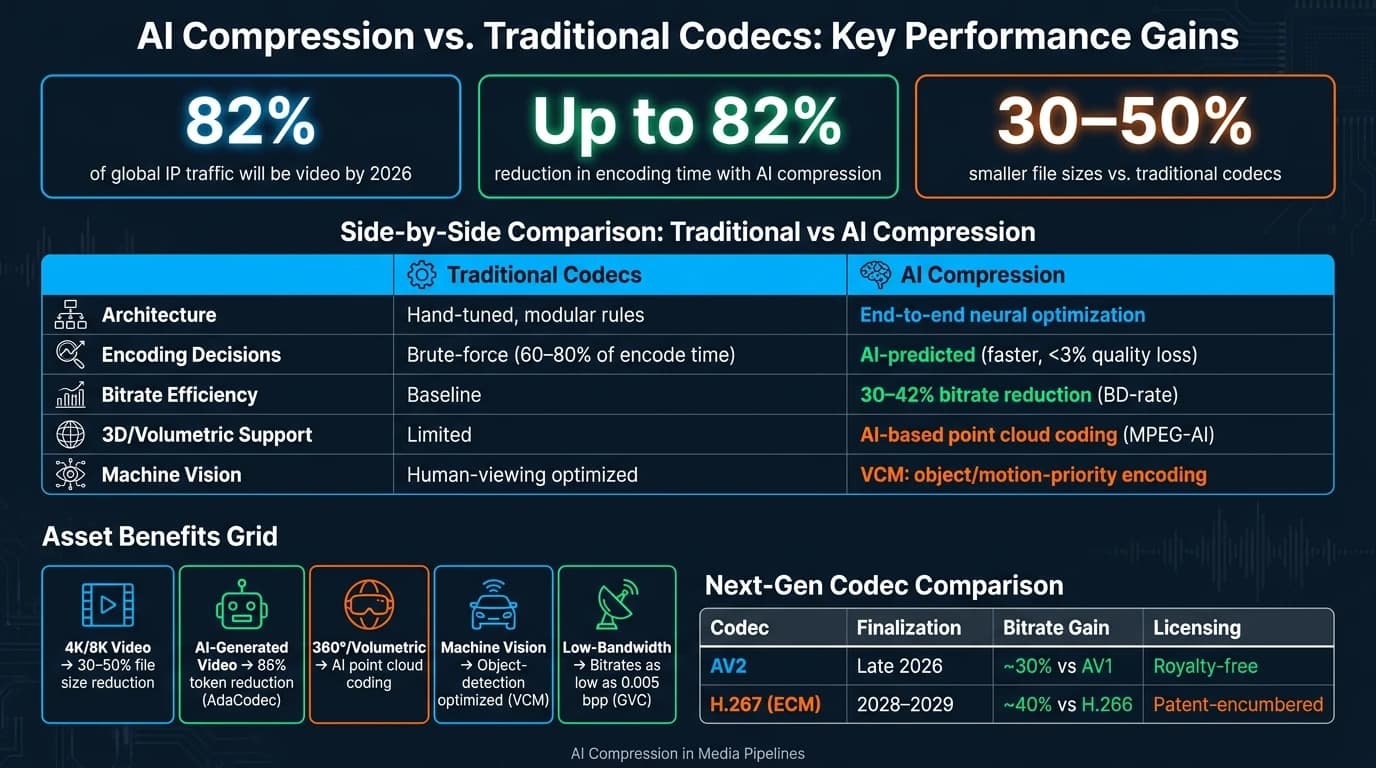
AI 압축은 머신러닝을 활용해 파일 크기를 줄이고, 인코딩 속도를 높이며, 시각적 품질을 유지함으로써 미디어를 처리, 저장, 전송하는 방식을 혁신하고 있습니다. 2026년까지 비디오가 전 세계 IP 트래픽의 82%를 차지하게 되면서, H.264와 HEVC 같은 전통적인 코덱은 4K/8K 콘텐츠, 실시간 워크플로, 대역폭 제약의 요구를 충족하기 어려워지고 있습니다. 뉴럴 코덱과 생성형 압축 같은 AI 기반 방식은 의사결정을 최적화하고 처리 시간을 최대 82% 단축하는 동시에 파일 크기를 30~50% 줄임으로써 이러한 과제를 해결합니다.
핵심 요약:
- AI 압축 유형: AI 강화형(전통 코덱을 개선) 및 AI 네이티브형(전통 파이프라인을 완전히 대체).
- 효율성 향상: 인코딩 시간 최대 82% 단축, 파일 크기 30~50% 감소.
- 생성형 모델: Generative Video Compression(GVC) 같은 고급 방식은 위성 및 저대역폭 애플리케이션을 위한 초저비트레이트를 달성합니다.
- 응용 분야: 4K/8K 비디오, 볼류메트릭 비디오, AI 생성 콘텐츠, 머신 비전 데이터에 유용합니다.
- 미래 트렌드: 새로운 코덱(AV2, H.267)과 프리인코더, 오토인코더 같은 AI 도구가 효율성을 더욱 높이고 비용을 낮출 것입니다.
AI 압축은 단순히 더 나은 코덱에 관한 것이 아닙니다. 인제스트부터 전송까지 전체 미디어 파이프라인 전반에 통합되어 더 빠른 처리, 낮은 비용, 기존 시스템과의 호환성을 제공합니다.
미디어 파이프라인에서의 AI 압축
AI 압축이란?
뉴럴 압축이라고도 하는 AI 압축은 트랜스포머, 컨볼루션 신경망(CNN), 생성형 모델 같은 머신러닝 기법을 사용해 미디어를 압축합니다. 사전 정의된 수작업 규칙에 의존하는 H.264 같은 전통 코덱과 달리, AI 압축은 데이터로부터 학습해 적응합니다. 프레임 분할, 모션 예측, 데이터 인코딩을 동시에 최적화하여 파일 크기를 최대한 작게 유지하면서도 최상의 품질을 제공하려고 합니다.
"AI는 비트스트림을 절대 건드리지 않습니다. 인코더가 비트스트림을 생성하는 데 사용하는 의사결정 로직만 건드릴 뿐입니다." - Nikolay Sapunov, Forasoft [3]
현재 AI 압축에는 두 가지 주요 접근 방식이 있습니다:
- AI 강화형 압축: 이 방식은 LightGBM이나 SVM 같은 더 작고 빠른 모델을 전통 인코더에 통합합니다. 이러한 모델은 프레임을 블록으로 나누는 방법과 같은 특정 의사결정을 더 효율적으로 수행합니다.
- AI 네이티브(엔드투엔드) 압축: 여기서는 딥러닝 네트워크가 전통 파이프라인을 완전히 대체합니다. 미디어를 압축된 "잠재 공간(latent space)"으로 매핑하고, 수신 측에서 생성형 모델을 사용해 콘텐츠를 재구성합니다.
데이터 기반 프로세스에 의존함으로써 AI 압축은 코딩 효율성을 개선할 뿐만 아니라 처리 지연도 줄여, 미디어 워크플로의 판도를 바꾸는 기술이 됩니다.
미디어 파이프라인에서 AI 압축이 중요한 이유
AI 압축의 중요성을 이해하려면 미디어 처리에서 연산 시간이라는 과제를 생각해 보세요. HEVC, AV1, VVC 같은 코덱의 인코딩 의사결정은 전체 인코딩 시간의 60~80%를 차지할 수 있습니다 [3]. 각 프레임을 코딩 유닛으로 나누는 방법 같은 이러한 의사결정은 일반적으로 시간이 많이 걸리는 브루트포스 방식으로 이루어집니다. AI 모델을 사용하면 이러한 의사결정을 훨씬 빠르게 예측할 수 있어, 품질 손실을 3% 미만으로 유지하면서 인코딩 시간을 30%에서 82%까지 단축합니다 [3].
4K 및 8K 콘텐츠를 처리하는 워크플로에서 이러한 시간 절감은 막대합니다. 예전에는 몇 시간씩 걸리던 작업을 이제 훨씬 빠르게 완료할 수 있으며, 기존 전송 시스템을 변경할 필요도 없습니다. AI 강화형 모델은 현재 인코더 내에서 작동하며 H.264나 AV1 같은 표준 디코더와 완전히 호환됩니다.
"표준 준수 특성이야말로 프리인코더를 연구 논문이 아닌 배포 가능한 제품으로 만드는 요소입니다. 통합 비용은 '기존 트랜스코딩 파이프라인에 단계 하나를 추가하는 것'이지, '전 세계 클라이언트 측이 새로운 디코더를 출시하도록 설득하는 것'이 아닙니다." - Marco Graziano, EncodeIQ [8]
경계를 더욱 넓혀, 2026년 3월 TeleAI(China Telecom)가 선보인 **Generative Video Compression(GVC)**은 0.005 bpp(픽셀당 비트)라는 낮은 비트레이트로 비디오를 전송하는 능력을 입증했습니다. 이 돌파구는 전통 코덱이 어려움을 겪는 위성 연결 환경에서도 고품질 비디오 전송을 가능하게 합니다. GVC는 압축된 비디오 파일을 전송하는 대신 콘텐츠에 대한 설명을 전송하여, 수신 측의 AI 모델이 이를 재구성할 수 있게 합니다 [6].
AI 압축의 이점을 가장 많이 누리는 미디어 에셋
AI 압축의 이점은 크고, 복잡하거나, 전송 비용이 많이 드는 미디어 에셋에서 가장 두드러집니다. 이 기술이 특정 에셋 범주에 미치는 영향은 다음과 같습니다:
| 에셋 유형 | 주요 이점 | 핵심 효과 |
|---|---|---|
| 4K/8K 비디오 | 스토리지 및 CDN 비용 절감 | 파일 크기 30~50% 감소 [11] |
| AI 생성 비디오 | 추론 및 토큰 비용 절감 | 토큰 약 86% 감소 [5] |
| 볼류메트릭/360° 비디오 | 방대한 데이터 볼륨 처리 | AI 기반 포인트 클라우드 코딩 [9] |
| 머신 비전 데이터 | 객체 탐지에 최적화 | 머신 분석 우선 처리 [9] |
| 저대역폭 비디오 | 위성/협대역 활용 가능 | 0.005 bpp만큼 낮은 비트레이트 [6] |
특히 AI 생성 콘텐츠가 큰 이점을 얻을 것으로 보입니다. 예를 들어 2026년 6월, 상하이 자오퉁 대학교와 JD.com의 연구진은 장면 전환 시에만 전체 참조 프레임을 삽입하여 비디오 토큰 사용량을 86% 줄이는 AdaCodec을 선보였습니다. 이 접근 방식은 LongVideoBench 같은 벤치마크에 필적하면서도 연산 비용을 대폭 줄입니다 [5].
자율주행 차량이나 산업용 로보틱스에 사용되는 것과 같은 머신 비전 애플리케이션에서는 Video Coding for Machines(VCM) 라는 특화된 접근 방식이 등장하고 있습니다. 전통 코덱과 달리 VCM은 미세한 텍스처보다 객체 경계와 모션 벡터 같은 특징을 우선시하여, 인간이 보는 것이 아니라 머신이 해석하는 데 최적화된 비디오를 만듭니다.
미디어 압축을 위한 핵심 AI 기술
뉴럴 비디오 및 이미지 코덱
미디어 처리 속도를 높이는 일은 코덱 설계 방식을 재고하는 것에서 시작됩니다. H.264와 HEVC 같은 전통 코덱은 모션 추정, 변환, 엔트로피 코딩 같은 작업을 위해 별도로 수작업 조정된 컴포넌트에 의존합니다. 반면 뉴럴 코덱은 이러한 모든 컴포넌트를 단일 레이트-왜곡(rate-distortion) 프레임워크 하에서 함께 최적화하여 더 효율적인 압축을 이끌어냅니다.
"[전통] 코덱의 수작업 설계된 모듈형 아키텍처는 본질적인 한계를 부과합니다. 각 컴포넌트는... 상대적으로 고립된 상태에서 설계되고 최적화되므로 전역적 공동 최적화가 불가능합니다." - Reka Sandaruwan Gallena Watthage, University of Strathclyde [2]
예를 들어 DCVC-UF(Ultra-Fast) 시스템을 살펴봅시다. 2026년 6월 Microsoft Research Asia가 개발한 이 시스템은 여러 비디오 프레임을 단일 잠재 표현으로 인코딩합니다. 이 접근 방식은 NVIDIA B200에서 1080p 비디오에 대해 놀라운 1,415.1 FPS를 달성했으며, VTM(Low-Delay) 대비 비트레이트도 42.2% 절감했습니다 [13]. 소비자용 RTX 4090에서도 371.1 FPS를 기록하여 실시간 배포가 실현 가능함을 보여주었습니다.
또 다른 주목할 만한 것은 2026년 5월 University of Strathclyde가 선보인 **STAC(Spatio-Temporal Adaptive Context)**입니다. 트랜스포머 기반 셀프 어텐션을 사용하는 STAC는 공간과 시간 양쪽에 걸친 종속성을 모델링하여, VTM-17.0 앵커 대비 평균 32.20% BD-rate 절감을 달성합니다. 이는 동일한 시각적 품질을 약 3분의 1 적은 데이터로 제공할 수 있음을 의미합니다 [2].
이러한 뉴럴 기술의 발전은 오토인코더로도 확장되어, 텍스처와 데이터 표현을 직접 최적화함으로써 효율성을 더욱 높입니다.
텍스처 및 이미지 최적화를 위한 오토인코더
AI 오토인코더는 원시 픽셀을 중요한 텍스처와 세부 정보를 유지하는 압축된 잠재 공간으로 매핑하여 미디어 압축에 새로운 접근 방식을 제시합니다. 그런 다음 디코더가 이 압축된 형태로부터 원본 콘텐츠를 재구성합니다. 전통 코덱과 달리 오토인코더는 MS-SSIM이나 VMAF 같은 지각 품질 지표로 학습될 수 있어, 미세한 세부 정보와 텍스처가 온전하게 유지되도록 보장합니다.
이 분야의 한 가지 혁신은 학습 가능한 특징 분포 행렬(Feature Distribution Matrices)을 사용해 고차원 특징을 더 작고 최적화된 표현으로 투영하는 **Latent Transformation Engines(LTE)**입니다. 이는 컨텍스트를 희생하지 않으면서 메모리 사용량과 연산 요구를 줄입니다. 한편 Efficient Dual-path Parallel Compression(EDPC) 프레임워크는 작업을 GPU(확률 예측용)와 CPU(인코딩용)로 분할하여 양쪽이 동시에 작동하도록 합니다. 이 구성은 전통적인 순차 처리 대비 GPU 메모리 사용량을 거의 50% 줄이면서 2.7배 빠른 압축 속도를 제공합니다 [10].
인간의 시청이 아니라 머신 판독성이 목표인 AI 파이프라인에서는, 오토인코더를 모델이 필요로 하는 특징을 우선시하도록 미세 조정할 수 있습니다. 2026년 6월 상하이 자오퉁 대학교와 JD.com이 개발한 AdaCodec 시스템은 예측 코딩을 사용해 멀티모달 모델의 비디오 토큰 사용량을 줄입니다. 장면 전환 시에만 전체 참조 프레임을 삽입함으로써 AdaCodec은 Qwen3-VL-8B의 성능을 유지하면서 비디오 토큰 사용량을 86% 감소시켰습니다 [5].
2D 미디어를 넘어 이러한 기술은 3D 에셋 압축의 고유한 과제에도 적용되고 있습니다.
3D 에셋을 위한 지오메트리 압축
포인트 클라우드와 메시 같은 3D 에셋을 압축하는 것은 완전히 다른 영역입니다. 이러한 에셋은 방대하고 비정형적이어서 게임이나 AR/VR 같은 실시간 애플리케이션을 특히 까다롭게 만듭니다.
**Implicit Neural Representations(INR)**는 명시적인 좌표 데이터 대신 신경망의 가중치로 3D 지오메트리를 인코딩하는 영리한 해결책을 제공합니다. 즉, 수백만 개의 정점을 저장하는 대신, 네트워크가 필요에 따라 어떤 해상도로든 지오메트리를 재구성할 수 있는 연속 함수를 학습합니다. 이는 가장 복잡한 에셋의 메모리 사용량조차 대폭 줄입니다 [14]. 대규모 장면의 경우, 에셋을 더 작고 관리하기 쉬운 청크로 분할하는 지오메트리 패칭(geometry patching) 같은 기술을 통해 리소스가 제한된 환경에서도 고해상도 3D 데이터를 처리할 수 있습니다 [14].
표준 측면에서는 MPEG-AI **(ISO/IEC 23888)**가 AI 기반 포인트 클라우드 코딩을 그 범위에 통합하여, 업계에서 지오메트리 압축의 중요성이 커지고 있음을 강조합니다 [9]. 게임, 시뮬레이션, 공간 컴퓨팅 같은 분야에서 실시간 3D 콘텐츠가 보편화됨에 따라, 이러한 기술은 프로덕션 워크플로에서 핵심적인 역할을 할 준비가 되어 있습니다.
AI 압축을 미디어 파이프라인에 통합하는 방법
파이프라인 단계별 AI 압축
AI 압축은 최종 단계뿐만 아니라 미디어 파이프라인 전반에 적용될 때 가장 잘 작동합니다. 아래 표는 다양한 AI 기술이 특정 파이프라인 단계와 어떻게 부합하며 어떤 이점을 가져오는지 보여줍니다:
| 파이프라인 단계 | AI 기술 | 주요 이점 |
|---|---|---|
| 인제스트 | 장면 및 품질 분석 | 최적의 인코딩 경로를 조기에 식별 [11] |
| 에셋 생성 | 증분 렌더링 | 재렌더링 시간을 75~85% 단축 [12] |
| 렌더링 | ROI 비트레이트 할당 | 얼굴과 화면 텍스트의 품질 유지 [11] |
| 전송 | 적응형 비트레이트(ABR) 스트리밍 | 불안정한 연결에서 버퍼링 제거 [1] |
인제스트 단계에서는 뉴럴 인코더가 코덱, 해상도, 프레임 레이트 같은 요소를 분석하여 콘텐츠에 가장 적합한 인코딩 경로를 결정합니다.
에셋 생성 단계에서는 증분 렌더링이 타임라인에서 변경된 부분만 업데이트하는 데 집중하여, 렌더링 작업에서 최대 75~85%의 상당한 시간을 절약합니다.
렌더링 단계에서는 콘텐츠 인식 인코딩이 얼굴과 화면 텍스트 같은 중요한 영역에 더 높은 비트레이트가 할당되도록 보장합니다. 이 접근 방식은 관심 영역(ROI)에 집중함으로써 품질과 압축의 균형을 맞춥니다.
마지막으로 전송 단계에서는 적응형 비트레이트(ABR) 스트리밍이 네트워크 상황에 따라 품질을 동적으로 조정합니다. 또한 TikTok용 세로 비디오나 YouTube용 멀티비트레이트 래더처럼 특정 플랫폼에 맞게 콘텐츠를 포맷팅합니다 [12].
이러한 기술은 현대 미디어 파이프라인이 더 효율적이고 효과적으로 작동하기 위한 토대를 마련합니다.
AI 압축을 위한 아키텍처 패턴
AI 압축을 인프라에 성공적으로 통합하려면 신중한 아키텍처 계획이 필요합니다. 대부분의 프로덕션 요구를 해결하는 세 가지 일반적인 패턴은 다음과 같습니다:
- 중앙 집중식 API 통합: 이 접근 방식은 복잡성을 추상화하고 글로벌 배포를 처리하여 코덱 관리를 단순화합니다. 인프라 비용을 최대 40% 줄이고, 온프레미스 시스템에 종종 부족한 확장성을 제공합니다 [15].
- 이벤트 기반 워크플로 및 하이브리드 구성: 이벤트 기반 워크플로는 웹훅을 사용해 후처리 작업을 트리거하여, 폴링이나 수동 개입의 필요성을 없앱니다. 완전히 클라우드 기반이 아닌 팀의 경우, 하이브리드 구성은 작업을 온프레미스 시스템과 클라우드 노드로 분할합니다. 이를 통해 민감한 마스터 파일은 로컬에 유지하면서 긴 비디오의 병렬 렌더링에는 클라우드 리소스를 활용할 수 있습니다 [12].
- 하드웨어 가속 인코딩: NVIDIA NVENC나 Intel Quick Sync 같은 하드웨어 인코더는 실시간 처리 속도를 10~50배 높여 라이브 스트리밍에 이상적입니다. 주문형 비디오(VOD) 라이브러리의 경우, SVT-AV1 같은 소프트웨어 인코더가 비트당 더 나은 품질을 제공하고 광범위한 튜닝 옵션을 제공합니다 [7].
이러한 패턴에 아키텍처를 맞춤으로써 미디어 파이프라인에서 성능과 비용 효율성을 모두 최적화할 수 있습니다.
AI 압축을 활용한 스토리지 및 캐싱 전략
AI 압축과 결합하면 스마트한 스토리지 전략은 미디어 파이프라인에서 비용을 크게 절감하고 지연을 줄일 수 있습니다. 계층형 스토리지 접근 방식이 효과적입니다. 고품질 메자닌 파일은 장기 보관용으로 아카이브하고, AI 압축된 렌디션은 활성 전송에 사용하여 CDN 비용을 최소화합니다 [15].
VOD 아카이브의 경우, 프리셋 레벨 4~6의 SVT-AV1 같은 공격적인 AI 압축 기술을 활용하면 스토리지 비용을 더욱 줄일 수 있습니다. 준실시간 캐싱의 경우, 하드웨어 기반 인코딩이 품질을 저하시키지 않으면서 낮은 지연을 보장합니다 [7].
뉴럴 디노이징 필터도 무작위 노이즈를 제거하여 파일 크기를 12~15% 줄이는 역할을 할 수 있습니다 [4]. 이를 엣지 캐싱(CDN 엣지 서버를 통해 압축된 에셋을 배포)과 결합하면 지연을 낮추고 오리진 서버의 부하를 줄이는 데 도움이 됩니다 [15].
이러한 전략들을 함께 사용하면 현대 파이프라인에서 미디어 에셋을 관리하기 위한 간소하고 비용 효율적인 솔루션을 만들 수 있습니다.
대규모로 AI 압축을 운영하기 위한 모범 사례
품질 관리 및 지각 지표
대규모로 작업할 때는 단 하나의 결함 있는 인코딩 프리셋이 수천 개의 에셋에 영향을 미칠 수 있습니다. 이를 방지하려면 인코딩 작업이 CDN에 도달하기 전에 정의된 VMAF 임계값 이하로 떨어지는 작업을 거부하는 자동화된 품질 게이트를 구현하세요. VMAF 점수 80 미만이 일반적인 기준선인데, 이 수준에서는 대부분의 화면에서 아티팩트가 눈에 띄게 되기 때문입니다 [16].
VMAF가 주요 품질 지표여야 하지만, AI가 유발하는 샤프닝 아티팩트를 포착하기 위해 PSNR, SSIM, VMAF-NEG를 추가하는 것이 현명합니다 [8].
| VMAF 점수 | 품질 수준 |
|---|---|
| 93+ | 뛰어남 (레퍼런스 품질) |
| 80~93 | 양호 (방송 품질) |
| 70~80 | 보통 (모바일 허용 가능) |
| < 70 | 미흡 (아티팩트가 보임) |
방대한 양의 에셋을 처리하는 팀의 경우, CPU 기반 품질 검사는 금세 병목이 될 수 있습니다. NVIDIA VMAF-CUDA로 전환하면 CPU 검증 대비 처리량이 2.5~2.8배 증가합니다 [16]. 이를 통해 샘플링 없이 모든 에셋에 대해 품질 검사를 실행하는 것이 가능해집니다.
품질 관리가 마련되면, 다음 우선순위는 에셋을 효과적으로 관리하는 것입니다.
버전 관리 및 에셋 관리
마스터 파일을 절대 덮어쓰지 마세요. 비압축 원본은 영구적인 콜드 스토리지에 보관하고, 압축 버전은 임시적이고 폐기 가능한 파생물로 취급하세요. 3계층 스토리지 구조가 종종 가장 효과적입니다:
적절한 메타데이터 관리도 그만큼 중요합니다. 시리즈 ID, 프로덕션 배치, 언어, 해상도 같은 구조화된 메타데이터 필드를 인제스트 중에 첨부하고, 이러한 필드가 웹훅을 통해 모든 다운스트림 변환에서 유지되도록 하세요. 예를 들어 production_batch 식별자는 큰 도움이 될 수 있습니다. 인코딩 프리셋이 실패하면 전체 라이브러리를 뒤지지 않고도 해당 배치의 영향을 받은 에셋을 격리하고 처리할 수 있습니다 [18].
"1분 에피소드를 위한 후반 작업 확장은 인코딩 문제가 아닙니다. 오케스트레이션 문제입니다." - FastPix [18]
재편집이 필요한 워크플로의 경우, 각 파일의 두 가지 버전을 유지하세요. 향후 편집을 위한 CRF 18의 고품질 마스터와 전송을 위한 CRF 28의 압축된 배포 사본입니다. 압축된 파일에서 재인코딩하는 것은 피하세요. 이는 세대 손실(generation loss)을 유발하며, 각 패스마다 품질이 조금씩 저하됩니다. 어떤 변경이든 항상 마스터로 돌아가세요 [19].
비용 및 리소스 최적화
에셋 품질과 버전 관리를 확보했다면, 다음 단계는 전송 비용을 줄이는 것입니다. 인코딩 비용은 상대적으로 미미한 반면, 전송 비용이 지배적입니다. Principal Software Engineer인 Sujeet Jaiswal은 이렇게 설명합니다:
"이그레스가 지배적입니다. 10%의 압축 개선은 월 350,000달러를 절약하며, 이는 더 느린 프리셋이나 더 나은 코덱을 사용해서 발생하는 어떤 인코딩 비용 증가도 훨씬 능가합니다." [16]
이는 주문형 비디오(VOD)에 더 느리고 고품질의 인코딩 프리셋을 사용하는 것의 가치를 강조합니다. 예를 들어 프리셋 4 또는 6의 SVT-AV1은 초기에 더 많은 연산 시간을 요구하지만 더 작은 파일을 생성하여 장기적인 CDN 비용을 크게 줄입니다. 속도가 중요한 라이브 또는 대용량 인코딩의 경우, 시간당 인코딩 비용을 약 0.68달러에서 약 0.08달러로 줄일 수 있는 NVIDIA NVENC나 VPU 인스턴스를 고려하세요 [16].
비용을 더욱 최적화하려면 연산 비용을 최대 70% 줄일 수 있는 클라우드 스팟 인스턴스를 사용하세요 [12]. 이를 각 에셋이 복잡도에 따라 맞춤형 비트레이트 래더를 받는 **타이틀별 인코딩(per-title encoding)**과 결합하세요. 토킹 헤드 비디오 같은 단순한 콘텐츠는 더 적은 비트를 사용하는 반면, 복잡한 장면(예: 스포츠나 액션)은 필요한 비트레이트를 받습니다.
실제 사례를 살펴보겠습니다. 8,000시간의 VOD를 보유한 한 OTT 플랫폼은 가장 많이 시청된 상위 1,500개 타이틀을 Intel Arc QuickSync 하드웨어에서 SVT-AV1을 사용해 14주에 걸쳐 재인코딩했습니다. 이 작업으로 CDN 비용을 월 145,000달러에서 103,000달러로 줄였으며, 이는 월 42,000달러의 절감으로 회수 기간이 단 4개월에 불과했습니다 [20]. AI 압축이 계속 발전함에 따라, 추가적인 비용 및 성능 개선의 잠재력은 더욱 커질 것입니다.
AI 기반 미디어 압축의 다음 단계는?
차세대 뉴럴 코덱과 적응형 압축
비디오 압축의 지형은 차세대 코덱이 효율성의 경계를 넓히면서 빠르게 진화하고 있습니다. 예를 들어 DCVC-UF를 보면, 이 최첨단 시스템은 프레임 청크를 압축된 잠재 표현으로 인코딩하여, 4090 GPU에서 실행할 때 1080p 비디오에 대해 놀라운 371.1 인코딩 FPS를 달성합니다. 더욱 놀랍게도, VTM 대비 42.2%의 비트레이트 감소를 제공합니다 [13].
표준 측면에서는 두 가지 코덱이 두드러집니다:
| 코덱 | 예상 확정 시기 | 비트레이트 향상 | 라이선싱 |
|---|---|---|---|
| AV2 | 2026년 말 | AV1 대비 약 30% | 로열티 프리 |
| H.267 (ECM) | 2028~2029년 | H.266 대비 약 40% | 특허 부담 있음 |
적응형 컨텍스트 선택의 발전 또한 비트레이트를 더욱 줄이는 데 핵심적인 역할을 하고 있습니다 [2].
"거의 모든 사업자에게 2026년의 실질적인 과제는 자체 카탈로그에 대해 동일 VMAF 기준으로 AV1 대 AV2 평가를 실행하고, 디바이스 계열별 하드웨어 디코드 로드맵을 구축하며, 폴백 래더를 설계하는 것입니다." - Nikolay Sapunov, CEO, Fora Soft [21]
AI 기반 엔드투엔드 파이프라인 최적화
코덱 개선을 넘어, AI는 전체 압축 파이프라인을 재편하고 있습니다. 화두는 단지 새로운 코덱이 아니라 프로세스의 모든 단계에 AI를 통합하는 것입니다. Nikolay Sapunov는 이렇게 말합니다:
"2026년에 사람들이 '인코더 안의 AI'라고 말할 때, 그들은 거의 절대 H.264나 AV1을 대체하는 뉴럴 코덱을 의미하지 않습니다. 그들은 특정 의사결정 하나를 더 빠르거나 더 똑똑하게 만들기 위해 고전적 인코더에 부착된 작고 빠른 모델을 의미합니다." - Nikolay Sapunov, CEO, Fora Soft [3]
이에 대한 훌륭한 예는 2026년 5월 Kelvin v1.0 뉴럴 프리인코더를 선보인 EncodeIQ입니다. SigLIP-2 특징 추출기를 사용하는 Kelvin v1.0은 표준 x264 인코더로 인코딩하기 전에 픽셀을 조정합니다. 그 결과는? 기존 디코더와의 호환성을 유지하면서 1080p 콘텐츠에 대해 BD-rate를 27.76% 감소시켰습니다. 이 접근 방식은 2025년 기준 H.264가 여전히 비디오 개발자들 사이에서 프로덕션 사용의 79%를 차지했다는 점을 고려하면 특히 큰 영향을 미쳤습니다 [8].
실험적 측면에서는 TeleAI가 개척한 **Generative Video Compression(GVC)**이 대담한 접근을 취합니다. 픽셀을 압축하고 전송하는 대신, GVC는 비디오에 대한 압축된 설명을 전송합니다. 수신 측의 "AI 화가"가 시각적 요소를 재구성합니다. TeleAI는 2025년 세계인공지능대회(WAIC)에서 이를 선보이며, 해상 위성 통신을 위한 단 0.02%의 초저압축률을 시연했습니다 [6].
"GVC의 핵심 원리는 연산을 압축률과 맞바꾸는 것입니다... 전통적인 압축은 그림을 촬영해 이미지를 보내는 것과 비슷합니다. 반면 GVC는 그림의 구도와 스타일을 설명한 다음, 수신 측의 'AI 화가'에 의존해 이를 재현합니다." - Xiangyu Chen et al., TeleAI [6]
APIMart 같은 플랫폼이 압축의 미래를 지원하는 방법
이러한 고급 코덱과 기술을 사용하면 모델 가중치를 관리하는 것이 상당한 과제가 됩니다. 뉴럴 코덱은 학습된 모델 가중치에 의존하며, 이것이 다양한 하드웨어 아키텍처에서 원활하게 작동하도록 보장하는 일은 벅찰 수 있습니다.
APIMart 같은 플랫폼은 방대한 AI 모델 라이브러리에 대한 통합 액세스를 제공하여 이 과정을 단순화합니다. 이 솔루션은 인프라에 막대한 투자를 하지 않고도 뉴럴 프리인코더나 비디오 생성 모델을 탐색하려는 팀에 이상적입니다. 한 업계 전문가가 언급했듯이, 관리형 API를 사용하면 FFmpeg 클러스터를 구축할 필요 없이 AV1 대역폭 절감을 달성하는 더 빠른 경로를 제공하는 경우가 많습니다 [7]. APIMart는 현재 비디오 생성, 이미지 처리, 멀티모달 워크플로를 위한 500개 이상의 AI 모델을 호스팅하며, 차세대 압축 기술을 프로덕션 파이프라인에 통합하는 간단한 방법을 제공합니다.
FFmpeg 및 VLC에서 실행되는 최초의 AI 코덱 – Deep Render의 돌파구
자주 묻는 질문
AI 압축을 사용하려면 새로운 디코더가 필요한가요?
대부분의 AI 기반 압축 방식은 기존 디코더와 원활하게 작동하도록 설계되었습니다. 이러한 기술은 H.264, HEVC, AV1, VVC 같은 전통 인코더를 강화하여, 현재 재생 시스템과 호환되는 표준 비트스트림을 생성합니다. 전체 압축 파이프라인을 개편하는 실험적 뉴럴 코덱만이 특수 디코더를 필요로 하며, 이들은 아직 널리 사용되지 않습니다. APIMart 같은 플랫폼은 디코더를 변경할 필요 없이 미디어 워크플로를 단순화하는 고급 AI 모델에 대한 액세스를 제공합니다.
AI 강화형 압축과 AI 네이티브형 압축은 언제 사용해야 하나요?
AI 강화형 압축은 기존 설정을 개편하지 않고 현재 워크플로를 개선하는 데 중점을 둡니다. 이러한 도구는 분할이나 장면 탐지 같은 표준 인코딩 프로세스를 정교하게 다듬으면서도 현재 디코더 및 하드웨어와의 호환성을 유지합니다. 즉, 값비싼 업그레이드나 파이프라인 변경 없이 즉시 더 나은 성능을 얻을 수 있습니다.
반면 AI 네이티브형 압축은 더 실험적이거나 특화된 애플리케이션을 위해 설계되었습니다. 이러한 시스템은 전통 파이프라인을 완전히 대체하여 온전히 AI 기반의 접근 방식을 제공합니다. 그러나 비표준 디코더를 필요로 하여 현 단계에서는 광범위한 상업적 사용에 비현실적입니다. 고급 AI 모델을 워크플로에 통합하려는 전문가에게 APIMart 같은 플랫폼은 이 과정을 더 매끄럽고 접근하기 쉽게 만듭니다.
AI 압축으로 대규모 품질을 어떻게 검증하나요?
대규모로 AI 압축 품질을 보장하려면 자동화된 품질 검사를 트랜스코딩 파이프라인에 통합하는 것이 필수적입니다. 이를 위한 신뢰할 수 있는 도구는 VMAF(Video Multi-Method Assessment Fusion)로, PSNR이나 SSIM 같은 오래된 지표보다 인간의 지각에 더 밀접하게 부합하는 평가를 제공합니다.
또한 처리를 시작하기 전에 손상된 데이터나 지원되지 않는 코덱 같은 문제를 포착하기 위해 소스 파일을 검증하는 것이 중요합니다. 더 고급 워크플로의 경우, 압축으로 인한 임베딩 이동(embedding shift)을 분석하고 이를 허용 가능한 변동과 비교하여 일관된 품질을 유지할 수 있습니다. APIMart 같은 도구는 이러한 모델을 미디어 워크플로에 원활하게 통합하는 것을 더 쉽게 만듭니다.
관련 블로그 게시물
모델 마켓에서 원하는 모델을 선택하세요
APIMart 모델 마켓에서 채팅, 이미지, 비디오 모델을 사용해 보고 하나의 통합 API로 모델 기능을 빠르게 경험하세요.