
Сравнение цен на AI API: модели Pay-As-You-Go 2026
Сравнение цен Pay-As-You-Go на AI API в 2026: APIMart, OpenAI, Google Cloud и Amazon Bedrock — ставки за токены, скидки и стратегии экономии.
Ищете лучшие цены на AI API в 2026 году? Вот что вам нужно знать.
Модели Pay-as-you-go (PAYG) тарифицируются на основе использования токенов, что делает их гибкими для бизнеса любого масштаба. За последние два года цены на токены упали на 80%, и такие провайдеры, как APIMart, OpenAI, Google Cloud AI и Amazon AI Services предлагают конкурентные варианты. Однако стоимость значительно различается — разница достигает 625× для аналогичных задач.
Ключевые выводы:
- APIMart: доступ к 500+ моделям со скидкой 20% по сравнению с официальными ценами. Оптимально для разнообразных задач и единого биллинга.
- OpenAI: продвинутые инструменты и функции, такие как prompt caching, но премиум-модели обходятся дорого.
- Google Cloud AI: самое большое контекстное окно (до 2 миллионов токенов) и мультимодальные возможности.
- Amazon AI Services: низкий порог входа и глубокая интеграция с AWS, но унифицированный API Bedrock добавляет небольшую наценку.
Совет: используйте более дешёвые модели для высокообъёмных задач и оставляйте премиум-модели для критических сценариев. Стратегии вроде batch-обработки и prompt caching могут сократить расходы на 50–90%.
Ниже подробный разбор цен, возможностей и скидок каждого провайдера.
Сравнение цен на API моделей: Claude, Kimi, GPT-4o и другие
1. APIMart
APIMart упрощает доступ к более чем 500 AI-моделям, используя всего один API-ключ, один счёт и единую панель управления.
Стоимость за единицу
APIMart работает по модели pay-as-you-go без месячных минимумов и скрытых платежей. Приведённые ниже примеры ставок демонстрируют стабильную экономию в 20% по сравнению с официальными ценами [7]:
| Модель | Цена APIMart | Официальная цена | Экономия |
|---|---|---|---|
| Wan 2.7 Image | $0.0216/call | $0.027/call | 20% |
| GPT Image 2 | $0.006/call | $0.0075/call | 20% |
| Imagen 4.0 | $0.04/call | $0.05/call | 20% |
| Qwen Image 2.0 | $0.02/1K tokens | $0.025/1K tokens | 20% |
| Z Image Turbo | $0.01/call | $0.0125/call | 20% |
Помимо экономии, APIMart предлагает широкий выбор моделей с разными AI-возможностями.
Разнообразие моделей и модальностей
В каталоге APIMart представлены модели для чата, генерации изображений, видео и редактирования — все они доступны через один эндпоинт. Для видео доступны Sora 2 ($0.08/sec), Veo 3 и Kling V3 (цена $0.0672/sec для 720p). Для изображений и текста представлены Flux.1, Imagen 4.0, GPT-5 и Claude Sonnet 4.5. Такое разнообразие позволяет выбрать оптимальную модель под каждую задачу и строить рабочие процессы, охватывающие текст, изображения и видео, без необходимости управлять несколькими вендорами.
Объёмные скидки и масштабируемость
С ростом потребления объёмные скидки применяются автоматически. APIMart также предлагает «Discount Bundles», которые поощряют команды, использующие несколько типов моделей в рамках одного аккаунта. Например, сочетание GPT-5 для задач reasoning и Flux.1 для генерации изображений может открыть более выгодные уровни скидок. Единая панель отслеживает использование и квоты в реальном времени по всем семействам моделей, упрощая управление и прогнозирование расходов при масштабировании [7].
Эти преимущества по стоимости дополняются простой интеграцией и качественной поддержкой.
Интеграция и поддержка
Настройка APIMart занимает всего 3 минуты. Сгенерируйте API-ключ, обновите базовый URL — и можно работать [7]. Для тех, кто уже использует OpenAI SDK, достаточно изменить одну строку кода. Платформа полностью совместима с OpenAI, поддерживает Python и JavaScript SDK, обрабатывает streaming, function calling, vision и мультимодальные входные данные. Переключение между моделями, например между GPT-5 и Claude Sonnet 4.5, выполняется без изменений в коде [8].
Поддержку оказывают живые инженеры через чат, платформа имеет рейтинг 4.6/5 на основе 320 отзывов. Пользователи часто отмечают интеграцию по одному ключу и низкую задержку как ключевые преимущества [9].
2. OpenAI API
OpenAI использует ценообразование pay-as-you-go на основе токенов: стоимость рассчитывается за каждый 1 миллион (1M) обработанных токенов. Цена существенно зависит от модели. Например, GPT‑5 nano стартует с $0.05 за 1M входных токенов, а GPT‑5.5 Pro может стоить до $30.00 за 1M входных токенов — разница достигает 600×[11]. Ниже — подробная разбивка стоимости по моделям.
Стоимость за единицу
Цена сильно зависит от выбранного уровня модели. Вот более детальное сравнение:
| Модель | Input (per 1M tokens) | Cached Input | Output (per 1M tokens) |
|---|---|---|---|
| GPT‑5.5 Pro (Reasoning) | $30.00 | – | $180.00 |
| GPT‑5.5 (Standard Edition) | $5.00 | $0.50 | $30.00 |
| GPT‑5.4 | $2.50 | $0.25 | $15.00 |
| GPT‑5.4 mini | $0.75 | $0.075 | $4.50 |
| GPT‑5.4 nano | $0.20 | $0.02 | $1.25 |
| GPT‑5 nano | $0.05 | $0.005 | $0.40 |
Нетекстовые нагрузки тарифицируются отдельно. Например, обработка видео Sora‑2 стоит $0.10 за секунду для разрешения 720p или $0.70 за секунду для 1080p. Realtime API для аудио тарифицируется по $32.00 за 1M входных токенов и $64.00 за 1M выходных токенов[10].
Разнообразие моделей и модальностей
OpenAI поддерживает широкий спектр задач, включая текст, vision, аудио, видео, web-поиск и выполнение кода. Realtime API обеспечивает живой speech-to-speech и сервисы перевода: перевод стоит $0.034 за минуту, транскрипция — $0.017 за минуту. Web-поиск тарифицируется по $10.00 за 1000 вызовов, а hosted-исполнение кода («Containers») стоит от $0.03 до $1.92 за 20-минутную сессию в зависимости от использования памяти[10].
Объёмные скидки и масштабируемость
Для управления расходами OpenAI предлагает несколько вариантов экономии:
- Batch API: сокращает стоимость input и output на 50% для задач, которые можно обработать асинхронно в течение 24 часов — идеально для пакетных операций.
- Flex Tier: даёт скидку 50% на real-time запросы, допускающие более медленные ответы.
- Priority Processing: стоит на 150% больше стандартного тарифа, но обеспечивает более быстрый и стабильный throughput. Например, priority-ставка GPT‑5.5 составляет $12.50 за 1M входных токенов против стандартных $5.00.
«Priority processing генерирует токены быстрее и с более стабильной скоростью, чем стандартный сервис, даже в часы пиковой нагрузки.» - OpenAI [14]
Автоматический prompt caching может дополнительно сократить стоимость input до 90%, что делает его отличным вариантом для повторяющихся задач или задач с длинным контекстом[14].
Интеграция и поддержка
OpenAI предлагает развитый набор инструментов для бесшовной интеграции. Сюда входят стандартный SDK, Agents SDK и CLI — все они поддерживают WebRTC, WebSocket и SIP-соединения для real-time приложений[12]. Разработчики могут регулировать скорость обработки, указывая параметр service_tier со значением «priority», «auto» или «default» в Chat Completions API[15].
Для мониторинга и управления расходами Usage Dashboard предоставляет детализированные данные по уровню сервиса или статье расходов. Для пользователей с особыми требованиями к локализации данных OpenAI также предлагает региональные эндпоинты обработки, но они обходятся на 10% дороже[13].
3. Google Cloud AI APIs
Google Cloud использует pay-as-you-go ценообразование за токены, аналогичное OpenAI, но линейка моделей и структура цен у него своя. Google делит модели Gemini на два уровня: «Flash» — с приоритетом на скорость и экономичность, и «Pro» — для более сложного reasoning. Такой подход помогает разработчикам сопоставлять возможности моделей с бюджетными ограничениями.
Стоимость за единицу
Цены значительно различаются между моделями. Например, Gemini 3 4B — самая доступная модель, $0.04 за 1M входных токенов, в то время как Gemini 3.1 Pro стоит $2.00 за 1M входных токенов для промптов до 200 000 токенов и $4.00 для более длинных [17]. Выходные токены обычно стоят в 4–10 раз дороже входных [17].
| Модель | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| Gemini 3.1 Pro (Preview) | $2.00 | $12.00 | 1M–2M tokens |
| Gemini 2.5 Pro | $1.25 | $10.00 | 2M tokens |
| Gemini 3 Flash (Preview) | $0.50 | $3.00 | 1M tokens |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | 1M tokens |
| Gemini 2.5 Flash-Lite / 2.0 Flash | $0.10 | $0.40 | 1M tokens |
| Gemini 3 4B | $0.04 | $0.08 | 131K tokens |
Для генерации изображений и видео Imagen 4.0 стоит от $0.02 до $0.06 за изображение в зависимости от качества, а генерация видео Veo 3.1 обойдётся в $0.40 за секунду для стандартной обработки или $0.15 за секунду в режиме preview [16].
Разнообразие моделей и модальностей
Модели Google охватывают широкий спектр задач: текст, изображения, видео, аудио и код. Это избавляет от необходимости подключать внешние сервисы вроде транскрипции [20]. Заметная особенность — контекстное окно в 2 миллиона токенов на Gemini 2.5 Pro и Gemini 3.1 Pro, что является непревзойдённой ёмкостью в индустрии [16][3]. Однако аудио-входы стоят дороже текста. Например, Gemini 3.1 Flash-Lite берёт $0.25 за 1M токенов для текста, но $0.50 за 1M токенов для аудио [17]. Кроме того, новые reasoning-модели используют «thinking tokens», что увеличивает стоимость для сложных выводов [17][19].
Объёмные скидки и масштабируемость
Google Cloud предлагает бизнесу несколько вариантов экономии. Batch API снижает стоимость input и output на 50% для задач, обрабатываемых асинхронно в течение 24 часов [17][19]. Например, стоимость input для Gemini 3.1 Pro падает с $2.00 до $1.00 за 1M токенов в режиме batch. Ещё одна функция — context caching — хранит часто используемые промпты или документы по цене $1.00 за 1M токенов в час, что сокращает расходы для повторяющихся задач, таких как RAG-пайплайны или продолжительные чат-сессии [17]. Разработчики могут дополнительно оптимизировать расходы, внедряя умную маршрутизацию между разными провайдерами.
Кроме того, Google использует систему throughput на основе расходов: организации, тратящие более $2,000 за 30 дней, автоматически получают более высокие rate limits [18]. Для крупных операций уровень Enterprise предлагает гарантированную ёмкость и индивидуальные тарифы [17].
Интеграция и поддержка
Инструменты Google Cloud рассчитаны на бесшовную интеграцию и масштабируемость. API нативно работают с Google Workspace, Drive и мобильными платформами через Vertex AI [20][19]. Примечательная функция — Grounding with Google Search, обогащающая ответы моделей данными в реальном времени. Эта функция бесплатна для первых 5000 промптов в месяц на моделях Gemini 3, дополнительное использование тарифицируется по $14 за 1000 запросов [17].
Среди встроенных инструментов также Function Calling, Streaming и Code Execution. Однако политика конфиденциальности зависит от уровня. В бесплатном уровне (Google AI Studio) отправленные данные могут использоваться для разработки продуктов. Платные и Enterprise-уровни, наоборот, гарантируют, что данные не используются для подобных целей — это важный фактор для команд, работающих с чувствительной информацией [17][3].
4. Amazon AI Services
AI-предложение Amazon разделено между двумя основными платформами: Amazon Bedrock — обеспечивает доступ к foundation-моделям через управляемый API, и Amazon SageMaker — предназначен для создания и развёртывания собственных моделей. Обе платформы используют ценообразование pay-as-you-go, хотя структура отличается согласно их Terms of Service. Как и многие конкуренты, Amazon предлагает гибкое ценообразование на основе использования с уровневыми опциями, рассчитанными на разные потребности бизнеса.
Стоимость за единицу
Цены Amazon Bedrock организованы в четыре уровня: Standard (on-demand), Flex (дешевле, но медленнее), Priority (быстрее, но дороже) и Batch (асинхронная обработка). Вот разбивка стоимости для модели Amazon Nova 2 Lite:
| Tier | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Standard | $0.30 | $2.50 |
| Priority | $0.525 | $4.375 |
| Flex | $0.15 | $1.25 |
| Batch | $0.15 | $1.25 |
Семейство Nova предлагает широкий диапазон цен. Например, Nova Micro стартует с $0.035 за 1M входных токенов, тогда как Nova Premier стоит $2.50 за 1M входных токенов. Сторонние модели обходятся дороже: например, Claude 4.7 Opus — $5.00 за 1M входных токенов и $25.00 за 1M выходных токенов [22].
Разнообразие моделей и модальностей
Модели Amazon Nova поддерживают несколько типов контента, включая изображения, видео, речь и embeddings. Вот чего стоит ожидать:
- Nova Canvas: генерация изображений стоит $0.04–$0.06 per image.
- Nova Reel: генерация видео — $0.08 per second (720p/24fps).
- Nova Sonic: обработка речи — от $3.00 до $3.40 per 1M input tokens [22].
Кроме того, web grounding для моделей Nova доступен по фиксированной ставке $30.00 за 1000 запросов [22].
Объёмные скидки и масштабируемость
Amazon предлагает существенные варианты экономии для бизнеса с предсказуемыми или крупномасштабными потребностями:
- Batch inference сокращает стоимость на 50% по сравнению со стандартным on-demand ценообразованием [22].
- Machine Learning Savings Plans дают экономию до 64% для пользователей SageMaker, которые подписываются на 1- или 3-летние планы [23].
- Managed Spot Training может снизить compute-расходы до 90% за счёт использования свободных мощностей AWS [23].
Как объясняет AWS:
«С моделью pay as you go вы можете адаптировать бизнес к реальной потребности, а не к прогнозам, снижая риски избыточного провижининга или нехватки ёмкости.» [21]
Интеграция и поддержка
Amazon Bedrock упрощает доступ к foundation-моделям от таких провайдеров, как Anthropic, Meta, Cohere, AI21 Labs, DeepSeek и собственное семейство Nova. Единый API позволяет легко переключаться между моделями или комбинировать их возможности без серьёзных изменений в существующих интеграциях [24][25]. Bedrock нативно интегрирован с Amazon S3, AWS Lambda и SageMaker, а также включает такие функции, как Amazon Bedrock Guardrails для безопасности и Amazon Augmented AI (A2I) для рабочих процессов с участием человека [26].
Для дополнительной надёжности AWS автоматически маршрутизирует inference-запросы в наиболее подходящий регион, гарантируя, что данные не передаются через публичный интернет [25].
Плюсы и минусы провайдеров
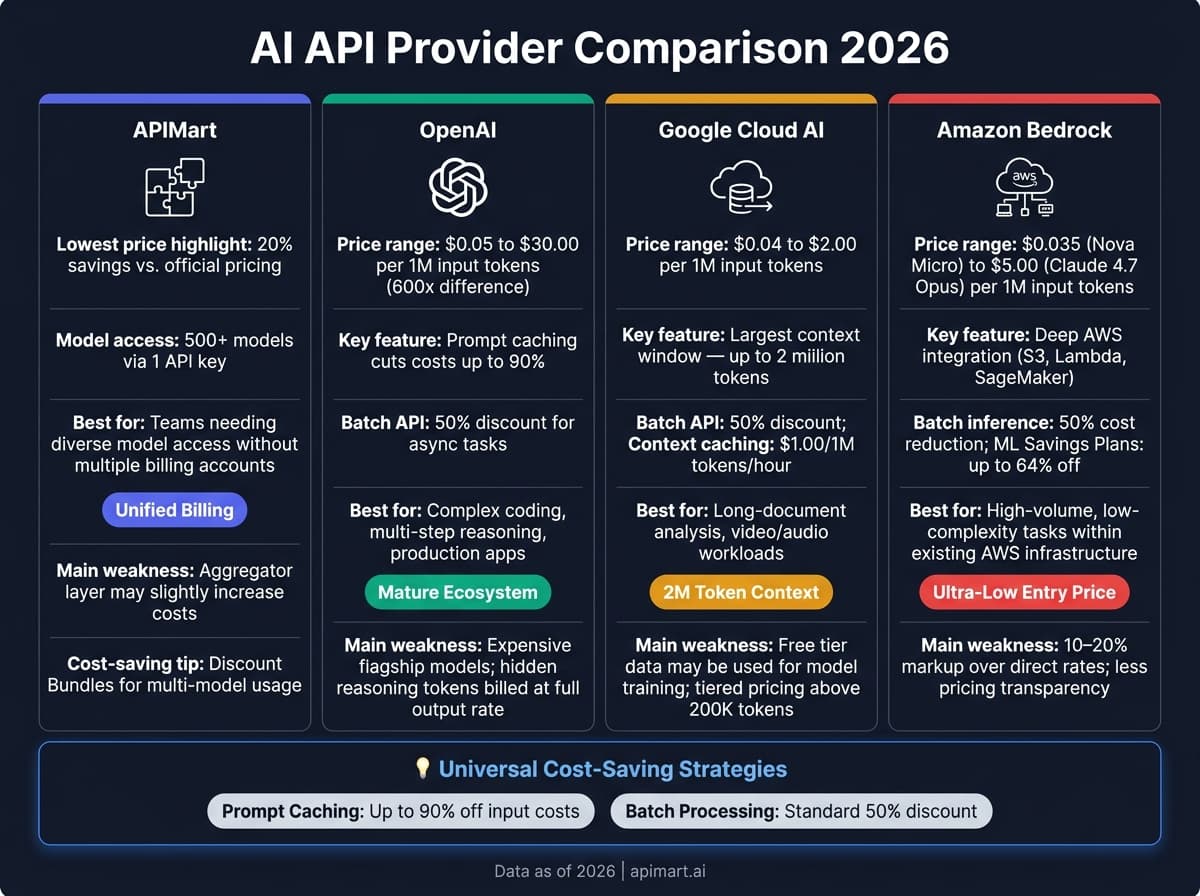
Каждый провайдер подстраивает цены и функции под разные объёмы нагрузок и технические требования. Вот краткий обзор сильных и слабых сторон ключевых игроков.
APIMart упрощает управление API, предлагая доступ к более чем 500 моделям через единый унифицированный API. Это снимает головную боль с управлением несколькими биллинговыми аккаунтами. Однако агрегационный слой может слегка увеличить стоимость по сравнению с прямыми отношениями с провайдерами отдельных моделей. Для крупных проектов такой упорядоченный подход к управлению расходами становится большим плюсом.
OpenAI выделяется зрелой экосистемой для разработчиков и развитой системой prompt caching, которая может снизить стоимость кешированных input до 50%. Тем не менее, премиум-модели дороги, а reasoning-модели (например, серия o) скрывают подвох: reasoning-токены тарифицируются по полным выходным ставкам, хотя и не появляются в финальном ответе [1][5].
«Небольшое изменение в дизайне промпта, выборе модели или длине контекста может изменить месячный счёт в 10 раз.» - Lyne Carolyne, CloudZero [5]
Google Cloud AI предлагает самое большое контекстное окно — до 2 миллионов токенов — и мощные мультимодальные возможности. Бесплатный уровень выглядит привлекательно, но имеет потенциальный компромисс: отправленные данные могут использоваться для обучения моделей, что может беспокоить пользователей, чувствительных к приватности [3]. Кроме того, такие модели, как Gemini 3.1 Pro, используют уровневое ценообразование, удваивая ставку input после превышения 200 000 токенов [5].
Amazon AI Services (Bedrock) отлично подходит командам, уже использующим AWS. Модель Nova Micro предлагает один из самых низких порогов входа — $0.035 за 1M входных токенов, а batch inference может сократить расходы на 50% для несрочных нагрузок [2]. Однако использование унифицированного API Amazon Bedrock обычно добавляет наценку 10–20% по сравнению с прямыми тарифами провайдеров моделей [5].
Вот краткое сравнение основных компромиссов:
| Провайдер | Главная сила | Главная слабость | Лучше всего подходит |
|---|---|---|---|
| APIMart | Доступ к 500+ моделям через один API, мультимодальная поддержка | Агрегационный слой может слегка увеличить стоимость | Командам, которым нужен разнообразный доступ к моделям без жонглирования биллингом |
| OpenAI | Зрелая экосистема, prompt caching, Batch API | Дорогие флагманские/reasoning модели; скрытые thinking-токены | Сложный код, многошаговый reasoning, продакшен-приложения |
| Google Cloud AI | Самое большое контекстное окно (2M токенов), мультимодальность | Бесплатный уровень может использовать данные для обучения; уровневые цены свыше 200K токенов | Анализ длинных документов, видео/аудио нагрузки |
| Amazon Bedrock | Глубокая интеграция с AWS, сверхнизкий порог входа | Наценка 10–20% над прямыми тарифами; меньше прозрачности цен | Высокообъёмные простые задачи внутри существующей инфраструктуры AWS |
Эти компромиссы показывают, как каждый провайдер соотносится со специфическими техническими и бюджетными требованиями. Для приложений, генерирующих много вывода, тот факт, что выходные токены стоят в 3–10 раз дороже входных, делает стратегии вроде batch-обработки и prompt caching особенно эффективными для экономии [4][6].
Заключение
Выбор подходящего провайдера AI API сводится к тому, чтобы соотнести ваши конкретные потребности с наиболее подходящим инструментом. Хотя цены на AI API упали примерно в 10 раз за последние два года (по состоянию на начало 2026) [2], разница между самым дешёвым и самым дорогим вариантами для одной задачи всё ещё может достигать 625× [4]. Это делает выбор провайдера критически важным решением для любой команды разработчиков в США.
Практичный подход — использовать бюджетные модели для высокообъёмных и простых задач вроде классификации и извлечения данных. Дорогие флагманские модели стоит беречь для действительно критически важных задач. Применяя такой умный роутинг моделей, команды могут сократить расходы на 60–80% [28] без потери качества. Помимо экономии, эта стратегия упрощает операции, уменьшая хлопоты с управлением несколькими API-аккаунтами — особенно при использовании консолидированных платформ.
Операционная эффективность — ещё один ключевой фактор. Управление несколькими провайдерами создаёт значительные накладные расходы. Платформы вроде APIMart решают это, предлагая доступ к более чем 500 моделям через единый API и систему биллинга. Этот компромисс отдаёт приоритет скорости и простоте, а не выжиманию каждого цента из прямых отношений с провайдерами.
«Ценность консолидации — это не только стоимость, но и инженерные часы, которые не уходят на инфраструктуру вместо продукта.» - Louis Amira, со-основатель ATXP [28]
Наконец, есть две стратегии экономии, которые стоит внедрить любой команде, независимо от выбранного провайдера: prompt caching и batch-обработка. Prompt caching способен сократить стоимость input до 90% для повторяющегося контекста [27], а batch-обработка даёт стандартную скидку 50% для задач, не требующих немедленного результата [2]. Эти методы не только экономят деньги, но и снижают сложность управления рабочими процессами — что делает их обязательными для любой команды.
Частые вопросы
Как оценить количество токенов для своей задачи перед развёртыванием?
Токены — это небольшие фрагменты текста, примерно эквивалентные 0.75 слова каждый. Они используются для измерения как входных промптов, которые вы отправляете, так и получаемых ответов. Чтобы получить чёткое представление о потреблении токенов, начните с использования инструментов token counter. Эти инструменты анализируют примеры промптов и ответов, помогая лучше понять, сколько токенов потребует ваш контент.
После сбора данных оцените количество токенов для input и output исходя из вашей конкретной нагрузки. Затем рассчитайте расходы, применив цены провайдера (обычно тарифицируется за миллион токенов). Этот шаг важен для понимания затрат и планирования бюджета до запуска.
Как лучше всего сократить расходы PAYG без потери качества?
Снижение расходов на pay-as-you-go (PAYG) AI API не означает, что нужно жертвовать производительностью. Вот как эффективно управлять затратами:
- Группируйте запросы: вместо множества мелких запросов объединяйте их в более крупные пачки. Это сокращает количество API-вызовов и экономит деньги.
- Упрощайте промпты: избегайте излишне сложных или объёмных промптов. Чёткие и краткие инструкции снижают потребление токенов без потери качества.
- Выбирайте подходящую модель: используйте более компактные и экономичные модели для простых или некритичных задач. Оставляйте продвинутые (и более дорогие) модели для случаев, когда это действительно необходимо.
- Отслеживайте использование токенов: внимательно следите за расходом токенов. Корректируйте подход или меняйте модель при обнаружении неэффективности.
Для нагрузок с переменным или низким объёмом сосредоточьтесь на эффективности токенов и группировке запросов. С другой стороны, если у вас высокообъёмные и стабильные потребности, подписочный план может оказаться выгоднее, обеспечивая предсказуемые расходы и потенциально более низкие ставки.
Когда унифицированный AI API вроде APIMart становится финансово выгоднее?
Унифицированный AI API вроде APIMart может сэкономить деньги вашей организации, особенно если вы используете несколько моделей от разных вендоров. Объединяя всё на одной платформе, он упрощает управление и помогает сократить расходы.
Для задач с большой вариативностью — например, мультимедийные проекты или языковая обработка — APIMart предлагает такие инструменты, как мультимодальные входы, продвинутые возможности редактирования и упрощённый биллинг. Эти функции помогают эффективно управлять расходами, даже когда характер использования непредсказуем и постоянно меняется.
Похожие посты
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.