
AI-сжатие для ускорения медиапайплайнов
Изучите методы AI-сжатия для видео, изображений, текстур и 3D-пайплайнов, а также паттерны рабочих процессов для быстрой доставки и снижения затрат на хранение.
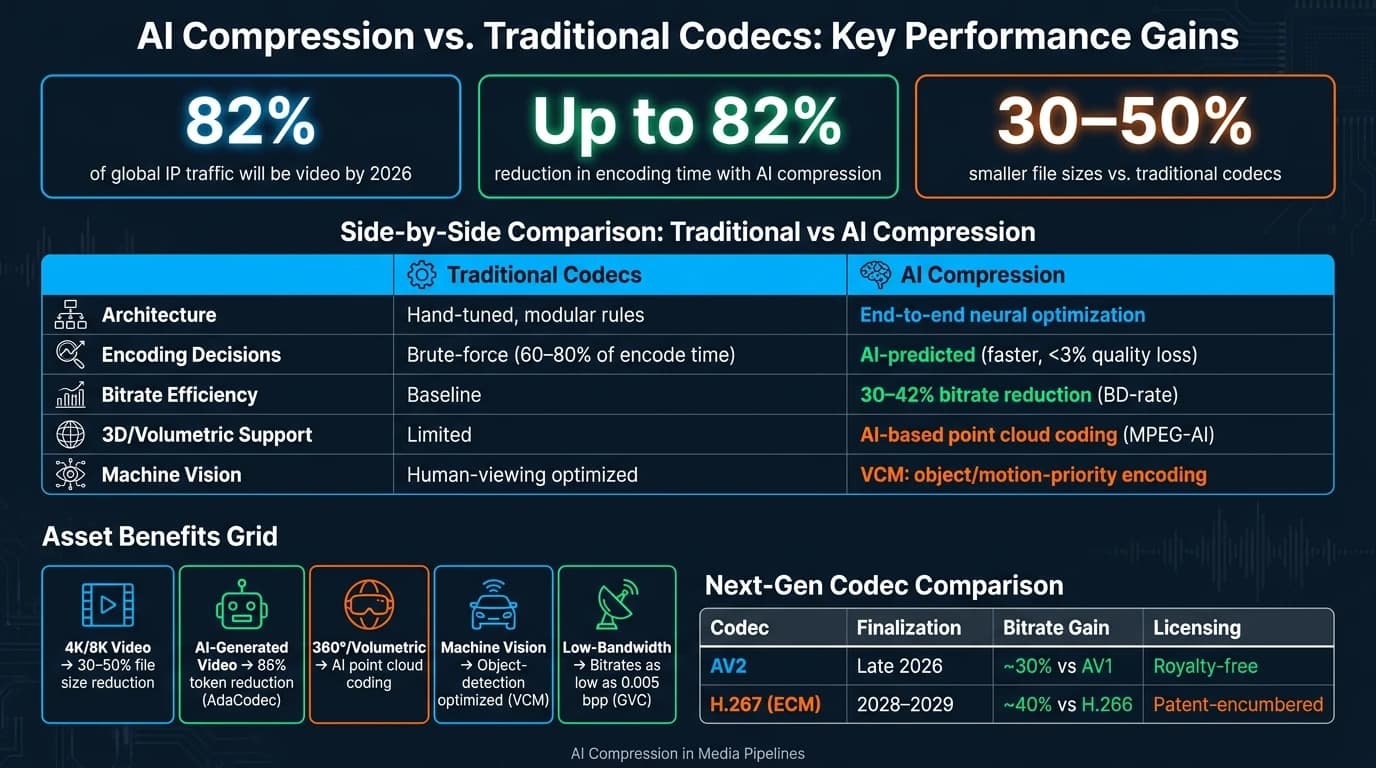
AI-сжатие меняет то, как медиаконтент обрабатывается, хранится и доставляется, используя машинное обучение для уменьшения размеров файлов, ускорения кодирования и сохранения визуального качества. Учитывая, что видео будет составлять 82% мирового IP-трафика к 2026 году, традиционные кодеки вроде H.264 и HEVC с трудом справляются с требованиями контента 4K/8K, рабочих процессов в реальном времени и ограничениями пропускной способности. Методы на основе AI, такие как нейросетевые кодеки и генеративное сжатие, решают эти задачи, оптимизируя принятие решений и сокращая время обработки до 82%, одновременно уменьшая размеры файлов на 30–50%.
Ключевые моменты:
- Типы AI-сжатия: AI-усиленное (улучшает традиционные кодеки) и AI-нативное (полностью заменяет традиционные пайплайны).
- Прирост эффективности: Время кодирования сокращается до 82%, размеры файлов уменьшаются на 30–50%.
- Генеративные модели: Продвинутые методы, такие как Generative Video Compression (GVC), достигают сверхнизких битрейтов для спутниковых и низкоскоростных приложений.
- Применения: Приносит пользу видео 4K/8K, объёмному видео, контенту, сгенерированному AI, и данным машинного зрения.
- Будущие тренды: Новые кодеки (AV2, H.267) и AI-инструменты вроде пре-энкодеров и автоэнкодеров ещё больше повысят эффективность и снизят затраты.
AI-сжатие — это не только про лучшие кодеки; оно интегрируется во весь медиапайплайн, от приёма до доставки, обеспечивая более быструю обработку, меньшие затраты и совместимость с существующими системами.
AI-сжатие в медиапайплайнах
Что такое AI-сжатие?
AI-сжатие, также известное как нейросетевое сжатие, использует методы машинного обучения — такие как трансформеры, свёрточные нейронные сети (CNN) и генеративные модели — для сжатия медиаконтента. В отличие от традиционных кодеков вроде H.264, которые полагаются на заранее заданные, вручную разработанные правила, AI-сжатие адаптируется, обучаясь на данных. Оно оптимизирует разбиение кадров, предсказание движения и кодирование данных сразу, стремясь обеспечить наилучшее качество при минимально возможном размере файлов.
"AI никогда не касается битового потока; оно затрагивает только логику принятия решений, которую энкодер использует для формирования битового потока." - Nikolay Sapunov, Forasoft [3]
В настоящее время существует два основных подхода к AI-сжатию:
- AI-усиленное сжатие: Этот метод интегрирует меньшие, более быстрые модели вроде LightGBM или SVM в традиционные энкодеры. Эти модели принимают конкретные решения — например, как разделить кадр на блоки — более эффективно.
- AI-нативное (сквозное) сжатие: Здесь глубокие нейронные сети полностью заменяют традиционные пайплайны. Они отображают медиаконтент в компактное «латентное пространство» и используют генеративные модели для реконструкции содержимого на принимающей стороне.
Опираясь на процесс, управляемый данными, AI-сжатие не только повышает эффективность кодирования, но и уменьшает задержки обработки, что делает его прорывом для медиапроцессов.
Почему AI-сжатие важно в медиапайплайнах
Чтобы понять важность AI-сжатия, рассмотрите проблему вычислительного времени в медиаобработке. Решения по кодированию для кодеков вроде HEVC, AV1 и VVC могут занимать 60–80% всего времени кодирования [3]. Эти решения, такие как разбиение каждого кадра на единицы кодирования, обычно принимаются с помощью трудоёмких методов полного перебора. С AI-моделями эти решения можно предсказывать гораздо быстрее, сокращая время кодирования на 30–82% при сохранении потерь качества менее 3% [3].
Для рабочих процессов, обрабатывающих контент 4K и 8K, эта экономия времени огромна. Задачи, которые раньше занимали часы, теперь можно выполнить значительно быстрее, без изменений в существующих системах доставки. AI-усиленные модели работают внутри текущих энкодеров и остаются полностью совместимыми со стандартными декодерами вроде H.264 или AV1.
"Свойство соответствия стандартам — это то, что делает пре-энкодер внедряемым продуктом, а не исследовательской статьёй. Затраты на интеграцию — это «добавить шаг в ваш существующий пайплайн транскодирования», а не «убедить весь мир на стороне клиента выпустить новый декодер»." - Marco Graziano, EncodeIQ [8]
Раздвигая границы ещё дальше, Generative Video Compression (GVC), представленная TeleAI (China Telecom) в марте 2026 года, продемонстрировала способность передавать видео при битрейтах всего 0,005 bpp (бит на пиксель). Этот прорыв позволяет доставлять высококачественное видео по спутниковым каналам, где традиционные кодеки испытывают трудности. Вместо передачи сжатого видеофайла GVC отправляет описание содержимого, позволяя AI-модели на принимающей стороне реконструировать его [6].
Медиаассеты, которые больше всего выигрывают от AI-сжатия
Преимущества AI-сжатия наиболее заметны для медиаассетов, которые большие, сложные или дорогие в передаче. Вот как эта технология влияет на конкретные категории ассетов:
| Тип ассета | Основное преимущество | Ключевой выигрыш |
|---|---|---|
| Видео 4K/8K | Снижает затраты на хранение и CDN | Уменьшение размера файла на 30–50% [11] |
| Видео, сгенерированное AI | Снижает затраты на инференс и токены | Сокращение токенов на ~86% [5] |
| Объёмное/360° видео | Обрабатывает огромные объёмы данных | Кодирование облаков точек на основе AI [9] |
| Данные машинного зрения | Оптимизировано для обнаружения объектов | Приоритет машинного анализа [9] |
| Низкоскоростное видео | Обеспечивает спутниковое/узкополосное использование | Битрейты всего 0,005 bpp [6] |
Контент, сгенерированный AI, в частности, может выиграть значительно. Например, в июне 2026 года исследователи из Shanghai Jiao Tong University и JD.com представили AdaCodec, который сокращает использование видеотокенов на 86%, вставляя полные опорные кадры только при смене сцен. Этот подход соответствует бенчмаркам вроде LongVideoBench, одновременно резко снижая вычислительные затраты [5].
Для приложений машинного зрения, таких как используемые в автономных транспортных средствах или промышленной робототехнике, появляется специализированный подход под названием Video Coding for Machines (VCM). В отличие от традиционных кодеков, VCM отдаёт приоритет таким признакам, как границы объектов и векторы движения, а не мелким текстурам, оптимизируя видео для машинной интерпретации, а не для человеческого просмотра.
Основные AI-методы сжатия медиаконтента
Нейросетевые видео- и изображенческие кодеки
Ускорение обработки медиаконтента начинается с переосмысления того, как проектируются кодеки. Традиционные кодеки вроде H.264 и HEVC полагаются на отдельные, вручную настроенные компоненты для таких задач, как оценка движения, преобразования и энтропийное кодирование. Нейросетевые кодеки, напротив, оптимизируют все эти компоненты вместе в рамках единого фреймворка «скорость–искажение», что приводит к более эффективному сжатию.
"Вручную спроектированная модульная архитектура [традиционных] кодеков накладывает неотъемлемые ограничения: каждый компонент... проектируется и оптимизируется в относительной изоляции, что препятствует совместной глобальной оптимизации." - Reka Sandaruwan Gallena Watthage, University of Strathclyde [2]
Возьмём, к примеру, систему DCVC-UF (Ultra-Fast). Разработанная Microsoft Research Asia в июне 2026 года, она кодирует несколько видеокадров в единое латентное представление. Этот подход достиг впечатляющих 1415,1 FPS для видео 1080p на NVIDIA B200, одновременно экономя 42,2% битрейта по сравнению с VTM (Low-Delay) [13]. Даже с потребительской RTX 4090 она достигла 371,1 FPS, делая развёртывание в реальном времени осуществимым.
Ещё один выдающийся пример — STAC (Spatio-Temporal Adaptive Context), представленный University of Strathclyde в мае 2026 года. Используя self-attention на основе трансформеров, STAC моделирует зависимости как в пространстве, так и во времени, достигая в среднем экономии BD-rate 32,20% относительно якоря VTM-17.0. Это означает, что он может обеспечить то же визуальное качество, используя примерно на треть меньше данных [2].
Эти нейросетевые достижения также распространяются на автоэнкодеры, которые дополнительно повышают эффективность за счёт прямой оптимизации текстур и представления данных.
Автоэнкодеры для оптимизации текстур и изображений
AI-автоэнкодеры привносят свежий подход к сжатию медиаконтента, отображая необработанные пиксели в компактное латентное пространство, которое сохраняет критически важные текстуры и детали. Затем декодер реконструирует исходное содержимое из этой сжатой формы. В отличие от традиционных кодеков, автоэнкодеры можно обучать на метриках перцептивного качества, таких как MS-SSIM или VMAF, гарантируя, что мелкие детали и текстуры остаются нетронутыми.
Одна из инноваций в этой области — Latent Transformation Engines (LTE), которые проецируют высокоразмерные признаки в меньшие, оптимизированные представления с использованием обучаемых Feature Distribution Matrices. Это снижает использование памяти и вычислительные требования без ущерба для контекста. Тем временем фреймворк Efficient Dual-path Parallel Compression (EDPC) разделяет задачи между GPU (для предсказания вероятностей) и CPU (для кодирования), позволяя обоим работать одновременно. Эта конфигурация обеспечивает в 2,7 раза более высокую скорость сжатия, одновременно сокращая использование памяти GPU почти на 50% по сравнению с традиционной последовательной обработкой [10].
Для AI-пайплайнов, где цель — машиночитаемость, а не человеческий просмотр, автоэнкодеры можно дообучать, чтобы отдавать приоритет признакам, которые нужны моделям. Система AdaCodec, разработанная Shanghai Jiao Tong University и JD.com в июне 2026 года, использует предиктивное кодирование для сокращения использования видеотокенов для мультимодальных моделей. Вставляя полные опорные кадры только при смене сцен, AdaCodec достиг сокращения на 86% в использовании видеотокенов, сохраняя при этом производительность Qwen3-VL-8B [5].
Помимо 2D-медиа, эти методы также адаптируются под уникальные задачи сжатия 3D-ассетов.
Сжатие геометрии для 3D-ассетов
Сжатие 3D-ассетов, таких как облака точек и полигональные сетки, — это совершенно другая история. Эти ассеты огромны и неструктурированы, что делает приложения реального времени вроде игр или AR/VR особенно сложными.
Implicit Neural Representations (INRs) предлагают остроумное решение, кодируя 3D-геометрию как веса нейронной сети вместо явных координатных данных. Это означает, что вместо хранения миллионов вершин сеть обучается непрерывной функции, которая может реконструировать геометрию при любом разрешении по запросу. Это резко уменьшает объём памяти даже для самых сложных ассетов [14]. Для крупномасштабных сцен такие методы, как geometry patching — который разбивает ассеты на меньшие, управляемые фрагменты — позволяют обрабатывать 3D-данные высокого разрешения в средах с ограниченными ресурсами [14].
Что касается стандартов, MPEG-AI (ISO/IEC 23888) включил в свою сферу кодирование облаков точек на основе AI, подчёркивая растущую важность сжатия геометрии в отрасли [9]. По мере того как 3D-контент реального времени становится всё более распространённым в таких областях, как игры, симуляции и пространственные вычисления, эти методы готовы играть центральную роль в производственных процессах.
Как интегрировать AI-сжатие в медиапайплайны
AI-сжатие на разных этапах пайплайна
AI-сжатие работает лучше всего, когда применяется на протяжении всего медиапайплайна, а не только на финальных этапах. Таблица ниже показывает, как различные AI-методы соотносятся с конкретными этапами пайплайна и какие преимущества они приносят:
| Этап пайплайна | AI-метод | Основное преимущество |
|---|---|---|
| Приём | Анализ сцен и качества | Рано определяет оптимальные пути кодирования [11] |
| Создание ассетов | Инкрементальный рендеринг | Сокращает время повторного рендеринга на 75–85% [12] |
| Рендеринг | Распределение битрейта по ROI | Сохраняет качество на лицах и экранном тексте [11] |
| Доставка | Потоковая передача с адаптивным битрейтом (ABR) | Устраняет буферизацию на нестабильных соединениях [1] |
На этапе приёма нейросетевые энкодеры анализируют такие факторы, как кодек, разрешение и частота кадров, чтобы определить наилучший путь кодирования для контента.
Во время создания ассетов инкрементальный рендеринг сосредотачивается на обновлении только тех частей таймлайна, которые изменились, экономя значительное время — до 75–85% — в задачах рендеринга.
На этапе рендеринга контекстно-зависимое кодирование гарантирует, что критически важные области, такие как лица и экранный текст, получают более высокое распределение битрейта. Этот подход балансирует качество и сжатие, фокусируясь на областях интереса (ROI).
Наконец, на этапе доставки потоковая передача с адаптивным битрейтом (ABR) динамически регулирует качество на основе сетевых условий. Она также форматирует контент для конкретных платформ, например вертикальные видео для TikTok или многобитрейтовые лестницы для YouTube [12].
Эти методы закладывают основу для того, чтобы современные медиапайплайны работали более эффективно и результативно.
Архитектурные паттерны для AI-сжатия
Успешная интеграция AI-сжатия в вашу инфраструктуру требует продуманного архитектурного планирования. Вот три распространённых паттерна, которые покрывают большинство производственных потребностей:
- Централизованная API-интеграция: Этот подход упрощает управление кодеками, абстрагируя сложность и обрабатывая глобальное распределение. Он снижает затраты на инфраструктуру до 40% и обеспечивает масштабируемость, которой часто не хватает локальным системам [15].
- Событийно-ориентированные процессы и гибридные конфигурации: Событийно-ориентированные процессы используют веб-хуки для запуска задач постобработки, устраняя необходимость в опросе или ручном вмешательстве. Для команд, не полностью работающих в облаке, гибридные конфигурации разделяют задачи между локальными системами и облачными узлами. Это позволяет держать конфиденциальные мастер-файлы локально, используя облачные ресурсы для параллельного рендеринга длинных видео [12].
- Аппаратно-ускоренное кодирование: Аппаратные энкодеры вроде NVIDIA NVENC или Intel Quick Sync повышают скорость обработки в реальном времени в 10–50 раз, что делает их идеальными для прямых трансляций. Для библиотек видео по запросу (VOD) программные энкодеры вроде SVT-AV1 обеспечивают лучшее качество на бит и предлагают обширные возможности настройки [7].
Согласовав свою архитектуру с этими паттернами, вы можете оптимизировать как производительность, так и экономическую эффективность вашего медиапайплайна.
Стратегии хранения и кэширования с AI-сжатием
В сочетании с AI-сжатием умные стратегии хранения могут значительно сократить затраты и уменьшить задержки в медиапайплайнах. Хорошо работает многоуровневый подход к хранению: высококачественные mezzanine-файлы архивируются для долгосрочных нужд, а AI-сжатые версии используются для активной доставки, минимизируя расходы на CDN [15].
Для VOD-архивов использование агрессивных методов AI-сжатия, таких как SVT-AV1 на уровнях пресетов 4–6, может дополнительно снизить затраты на хранение. Для кэширования почти в реальном времени аппаратное кодирование обеспечивает низкую задержку без ущерба для качества [7].
Нейросетевые фильтры шумоподавления также могут сыграть роль, удаляя случайный шум, что уменьшает размеры файлов на 12–15% [4]. Сочетание этого с граничным кэшированием — распределением сжатых ассетов через граничные серверы CDN — помогает снизить задержку и уменьшить нагрузку на исходные серверы [15].
Эти стратегии, используемые вместе, создают оптимизированное и экономически эффективное решение для управления медиаассетами в современных пайплайнах.
Лучшие практики запуска AI-сжатия в масштабе
Контроль качества и перцептивные метрики
При работе в масштабе даже один ошибочный пресет кодирования может повлиять на тысячи ассетов. Чтобы предотвратить это, внедрите автоматизированные шлюзы качества, которые отклоняют задания кодирования, падающие ниже заданного порога VMAF, прежде чем они достигнут вашего CDN. Оценка VMAF ниже 80 — распространённый порог отсечения, так как на этом уровне артефакты становятся заметны на большинстве экранов [16].
VMAF должен быть вашей основной метрикой качества, но разумно добавить PSNR, SSIM и VMAF-NEG для выявления артефактов повышения резкости, вносимых AI [8].
| Оценка VMAF | Уровень качества |
|---|---|
| 93+ | Отличное (эталонное качество) |
| 80–93 | Хорошее (вещательное качество) |
| 70–80 | Приемлемое (годится для мобильных) |
| < 70 | Плохое (видимые артефакты) |
Для команд, обрабатывающих огромные объёмы ассетов, проверки качества на базе CPU могут быстро стать узким местом. Переход на NVIDIA VMAF-CUDA увеличивает пропускную способность в 2,5–2,8 раза по сравнению с проверкой на CPU [16]. Это делает возможным проведение проверок качества для каждого ассета, устраняя необходимость в выборочной проверке.
После того как контроль качества налажен, следующим приоритетом становится эффективное управление ассетами.
Версионирование и управление ассетами
Никогда не перезаписывайте свои мастер-файлы. Храните несжатые оригиналы в постоянном холодном хранилище и рассматривайте сжатые версии как временные, одноразовые производные. Часто лучше всего работает трёхуровневая структура хранения:
- Уровень 1: Мастера полного качества
- Уровень 2: Сжатые файлы доставки (например, AV1 или HEVC)
- Уровень 3: Временные рабочие файлы, которые автоматически удаляются через 60–90 дней [17][19]
Правильное управление метаданными не менее важно. Прикрепляйте структурированные поля метаданных — такие как ID серии, производственная партия, язык и разрешение — во время приёма и обеспечивайте сохранение этих полей на всех последующих преобразованиях через веб-хуки. Например, идентификатор production_batch может стать спасением. Если пресет кодирования даёт сбой, вы можете изолировать и устранить проблему с затронутыми ассетами в этой партии, не прочёсывая всю вашу библиотеку [18].
"Масштабирование постпродакшена для минутных эпизодов — это не проблема кодирования. Это проблема оркестрации." - FastPix [18]
Для процессов, включающих повторное редактирование, поддерживайте две версии каждого файла: высококачественный мастер на CRF 18 для будущих правок и сжатую дистрибутивную копию на CRF 28 для доставки. Избегайте перекодирования из сжатых файлов, так как это вносит потери поколений — каждый проход слегка ухудшает качество. Всегда возвращайтесь к мастеру для любых изменений [19].
Оптимизация затрат и ресурсов
После того как вы обеспечили качество ассетов и контроль версий, следующий шаг — снижение затрат на доставку. Хотя затраты на кодирование относительно невелики, затраты на доставку доминируют. Sujeet Jaiswal, Principal Software Engineer, объясняет:
"Egress доминирует. Улучшение сжатия на 10% экономит 350 000 долларов в месяц — намного превышая любое увеличение затрат на кодирование от использования более медленных пресетов или лучших кодеков." [16]
Это подчёркивает ценность использования более медленных, высококачественных пресетов кодирования для видео по запросу (VOD). Например, SVT-AV1 на пресете 4 или 6 требует больше вычислительного времени изначально, но генерирует меньшие файлы, значительно снижая долгосрочные расходы на CDN. Для прямого или высокообъёмного кодирования, где скорость критична, рассмотрите NVIDIA NVENC или VPU-инстансы, которые могут снизить почасовые затраты на кодирование с ~0,68 до ~0,08 доллара [16].
Для дальнейшей оптимизации затрат используйте облачные spot-инстансы, которые могут снизить вычислительные расходы до 70% [12]. Сочетайте это с покадровым кодированием по названию (per-title), где каждый ассет получает индивидуальную лестницу битрейтов на основе его сложности. Простой контент вроде видео с говорящей головой использует меньше бит, тогда как сложные сцены (например, спорт или экшн) получают битрейт, который им нужен.
Вот пример из реальной жизни: OTT-платформа с 8000 часами VOD перекодировала свои 1500 самых просматриваемых наименований с помощью SVT-AV1 на аппаратуре Intel Arc QuickSync за 14 недель. Это усилие сократило их счёт за CDN со 145 000 до 103 000 долларов в месяц — экономия в 42 000 долларов ежемесячно с периодом окупаемости всего четыре месяца [20]. По мере того как AI-сжатие продолжает развиваться, потенциал для дальнейшего улучшения затрат и производительности будет только расти.
Что дальше для AI-управляемого сжатия медиаконтента
Нейросетевые кодеки нового поколения и адаптивное сжатие
Ландшафт сжатия видео быстро развивается, а кодеки нового поколения раздвигают границы эффективности. Возьмём, к примеру, DCVC-UF — эта передовая система кодирует фрагменты кадров в компактные латентные представления, достигая впечатляющих 371,1 FPS кодирования для видео 1080p при запуске на GPU 4090. Ещё более поразительно, она обеспечивает снижение битрейта на 42,2% по сравнению с VTM [13].
Что касается стандартов, выделяются два кодека:
| Кодек | Ожидаемое завершение | Прирост битрейта | Лицензирование |
|---|---|---|---|
| AV2 | Конец 2026 | ~30% против AV1 | Без роялти |
| H.267 (ECM) | 2028–2029 | ~40% против H.266 | Обременён патентами |
Достижения в адаптивном выборе контекста также играют ключевую роль в дальнейшем снижении битрейтов [2].
"Практическая задача 2026 года почти для каждого оператора — провести оценку AV1 против AV2 при одинаковом VMAF на собственном каталоге, построить дорожную карту аппаратного декодирования по семействам устройств и спроектировать резервную лестницу." - Nikolay Sapunov, CEO, Fora Soft [21]
AI-управляемая сквозная оптимизация пайплайна
Помимо улучшений кодеков, AI меняет весь пайплайн сжатия. Ажиотаж не только вокруг новых кодеков — он вокруг интеграции AI в каждый шаг процесса. Как выражается Nikolay Sapunov:
"Когда люди говорят «AI внутри энкодера» в 2026 году, они почти никогда не имеют в виду нейросетевой кодек, заменяющий H.264 или AV1 — они имеют в виду маленькую, быструю модель, прикрученную к классическому энкодеру, чтобы сделать одно конкретное решение быстрее или умнее." - Nikolay Sapunov, CEO, Fora Soft [3]
Отличный пример этого — EncodeIQ, которая представила нейросетевой пре-энкодер Kelvin v1.0 в мае 2026 года. Используя экстрактор признаков SigLIP-2, Kelvin v1.0 корректирует пиксели перед кодированием стандартным энкодером x264. Результат? Снижение BD-rate на 27,76% для контента 1080p, при сохранении совместимости с существующими декодерами. Этот подход оказался особенно значимым, учитывая, что H.264 всё ещё составлял 79% производственного использования среди разработчиков видео по состоянию на 2025 год [8].
С экспериментальной стороны, Generative Video Compression (GVC), впервые применённая TeleAI, придерживается смелого подхода. Вместо сжатия и передачи пикселей GVC отправляет компактное описание видео. «AI-художник» на принимающей стороне реконструирует визуальный ряд. TeleAI продемонстрировала это на World Artificial Intelligence Conference (WAIC) в 2025 году, показав сверхнизкий уровень сжатия всего 0,02% для морской спутниковой связи [6].
"Основной принцип GVC — обмен вычислений на степень сжатия... традиционное сжатие подобно фотографированию картины и отправке изображения; GVC, напротив, описывает композицию и стиль картины, а затем полагается на «AI-художника» на приёмнике, чтобы воссоздать её." - Xiangyu Chen et al., TeleAI [6]
Как платформы вроде APIMart поддерживают будущее сжатия
С этими продвинутыми кодеками и методами управление весами моделей становится значительной задачей. Нейросетевые кодеки полагаются на обученные веса моделей, и обеспечение их бесперебойной работы на разнообразных аппаратных архитектурах может быть непростым.
Платформы вроде APIMart упрощают этот процесс, предлагая единый доступ к обширной библиотеке AI-моделей. Это решение идеально для команд, изучающих нейросетевые пре-энкодеры или модели генерации видео без необходимости серьёзных вложений в инфраструктуру. Как отметил один отраслевой эксперт, использование управляемого API часто обеспечивает более быстрый путь к достижению экономии пропускной способности AV1 без необходимости настраивать кластер FFmpeg [7]. APIMart в настоящее время размещает более 500 AI-моделей для генерации видео, обработки изображений и мультимодальных процессов, предлагая простой способ интеграции технологий сжатия нового поколения в производственные пайплайны.
Первый AI-кодек, работающий в FFmpeg и VLC — прорыв Deep Render
Часто задаваемые вопросы
Нужны ли мне новые декодеры для использования AI-сжатия?
Большинство методов сжатия на основе AI спроектированы для бесперебойной работы с существующими декодерами. Эти методы улучшают традиционные энкодеры вроде H.264, HEVC, AV1 и VVC, генерируя стандартные битовые потоки, которые остаются совместимыми с текущими системами воспроизведения. Только экспериментальные нейросетевые кодеки, которые перестраивают весь пайплайн сжатия, требуют специализированных декодеров — и они пока не широко используются. Платформы вроде APIMart предоставляют доступ к продвинутым AI-моделям, которые упрощают медиапроцессы без необходимости каких-либо изменений в декодерах.
Когда следует использовать AI-усиленное против AI-нативного сжатия?
AI-усиленное сжатие направлено на улучшение текущих процессов без перестройки существующей конфигурации. Эти инструменты совершенствуют стандартные процессы кодирования — вроде разбиения и обнаружения сцен — сохраняя всё совместимым с вашими текущими декодерами и оборудованием. Это означает, что вы сразу получаете лучшую производительность, без необходимости в дорогостоящих обновлениях или изменениях вашего пайплайна.
С другой стороны, AI-нативное сжатие предназначено для более экспериментальных или специализированных приложений. Эти системы полностью заменяют традиционные пайплайны, предлагая полностью AI-управляемый подход. Однако они требуют нестандартных декодеров, что делает их непрактичными для широкого коммерческого использования на данном этапе. Для профессионалов, стремящихся интегрировать продвинутые AI-модели в свои процессы, платформы вроде APIMart делают процесс более гладким и доступным.
Как проверить качество в масштабе с AI-сжатием?
Чтобы обеспечить качество AI-сжатия в масштабе, важно интегрировать автоматизированные проверки качества в ваш пайплайн транскодирования. Надёжный инструмент для этого — VMAF (Video Multi-Method Assessment Fusion), который обеспечивает оценки, более тесно согласующиеся с человеческим восприятием по сравнению со старыми метриками вроде PSNR или SSIM.
Кроме того, проверка ваших исходных файлов критически важна для выявления проблем, таких как повреждённые данные или неподдерживаемые кодеки, до начала обработки. Для более продвинутых процессов вы можете анализировать сдвиги эмбеддингов, вызванные сжатием, и сравнивать их с приемлемыми вариациями для поддержания стабильного качества. Инструменты вроде APIMart упрощают включение этих моделей в ваши медиапроцессы.
Похожие статьи блога
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.