
Как интегрировать несколько AI-моделей через один унифицированный API
Единый OpenAI-совместимый шлюз: один ключ, failover, маршрутизация GPT/Claude/Gemini, мультимодальность и примеры на Python; чеклист продакшена APIMart.
Хотите упростить интеграции с AI? Унифицированные API позволяют подключать несколько моделей — например GPT, Claude и Gemini — через единый интерфейс. Вместо разрозненных SDK, учётных данных и протоколов вы управляете всем с одного endpoint. Это экономит время, снижает затраты и помогает приложению оставаться доступным даже при сбоях у провайдеров.
Вот что дают унифицированные API:
- Один API для всех моделей: доступ к текстовым, графическим и видеомоделям без переписывания кода под каждого провайдера.
- Экономия: направляйте простые задачи на более дешёвые модели, а сложные — на премиальные — расходы можно сократить до ~60%.
- Автоматический failover: при простоях сервис переключается на резервные модели без ручного вмешательства.
- Централизованный биллинг: один счёт и одна панель для отслеживания затрат и качества.
- Быстрый старт: на OpenAI-совместимых платформах вроде APIMart интеграция занимает минуты.
Унифицированные API упрощают мультимодельные сценарии, оптимизируют бюджет и повышают надёжность. Готовы разобраться глубже? Поехали.
Видеоучебник Lightning Model API Hub
Основные моменты из связанного разбора
Смотрите видео Lightning Model API Hub выше, чтобы увидеть в интерфейсе поиск моделей, переключение провайдеров и мультимодальные нагрузки из одной панели.
Что такое унифицированные API для мультимодельной интеграции
Унифицированный AI API — это единая точка доступа к нескольким провайдерам под одним интерфейсом [7]. Вместо отдельных интеграций с OpenAI, Anthropic или Google вы отправляете запросы на один шлюз. Он занимается маршрутизацией, адаптацией формата под каждого провайдера и возвращает унифицированные ответы.
Представьте переводчика между разными AI-протоколами. Вы отправляете запрос в общем формате — часто по мотивам структуры chat/completions OpenAI — а унифицированный API преобразует его под Messages API Anthropic или протокол Gemini.
Так выбор провайдера превращается в настройку конфигурации, а не в архитектурный проект [7]. Например, переход с модели OpenAI на Claude 3.5 может свестись к смене одной строки в настройках — без тяжёлого обновления SDK и перенастройки аутентификации. Яркий пример — «CoCounsel» Thomson Reuters, AI-ассистент для юристов: в начале 2026 команда завершила проект за два месяца на унифицированном API, не пишя провайдер-специфичный обвяз [7].
Ключевые возможности унифицированных API
Унифицированные API обычно включают:
- Мультимодальность: генерация текста, анализ изображений, синтез видео и даже речь — через одну интеграцию [7]. Отдельные SDK на каждый тип задачи не обязательны.
- Обнаружение моделей: программно смотрите список моделей, лимиты токенов, температуру и выбирайте модель динамически [6].
- Автоматический failover: при даунтайме или лимитах провайдера запрос уходит на другую модель.
- Сводный биллинг и аналитика: одна панель затрат по фичам, агентам или типам задач — проще находить неэффективность.
Зачем нужен унифицированный API
На практике это даёт:
Упрощение секретов и доступа: один API-ключ вместо зоопарка учётных данных у разных провайдеров.
Быстрая внедряемость: если вы уже на OpenAI SDK, часто достаточно сменить base_url и ключ — за минуты. Это важно, когда 37% предприятий используют пять и более моделей, а корпоративные расходы на LLM выросли с $3,5 млрд до $8,4 млрд за два квартала 2025 года [7].
Оптимизация затрат: маршрутизируйте задачи на самые выгодные модели. Простые — на недорогие вроде MiniMax Hailuo 2.3 ($0.025 за секунду), сложные — на топовые. Сводные тарифы и объёмные скидки упрощают контроль бюджета.
«Унифицированный AI API решает это. Один endpoint, один SDK, один счёт. Приложение говорит с одним интерфейсом, а API маршрутизирует запросы к нужному провайдеру».
— PremAI [7]
Надёжность за счёт резерва: при падении провайдера система может переключиться на альтернативу без переписывания кода — и гибче реагировать на изменения цен и качества.
Как интегрировать несколько AI-моделей: пошагово
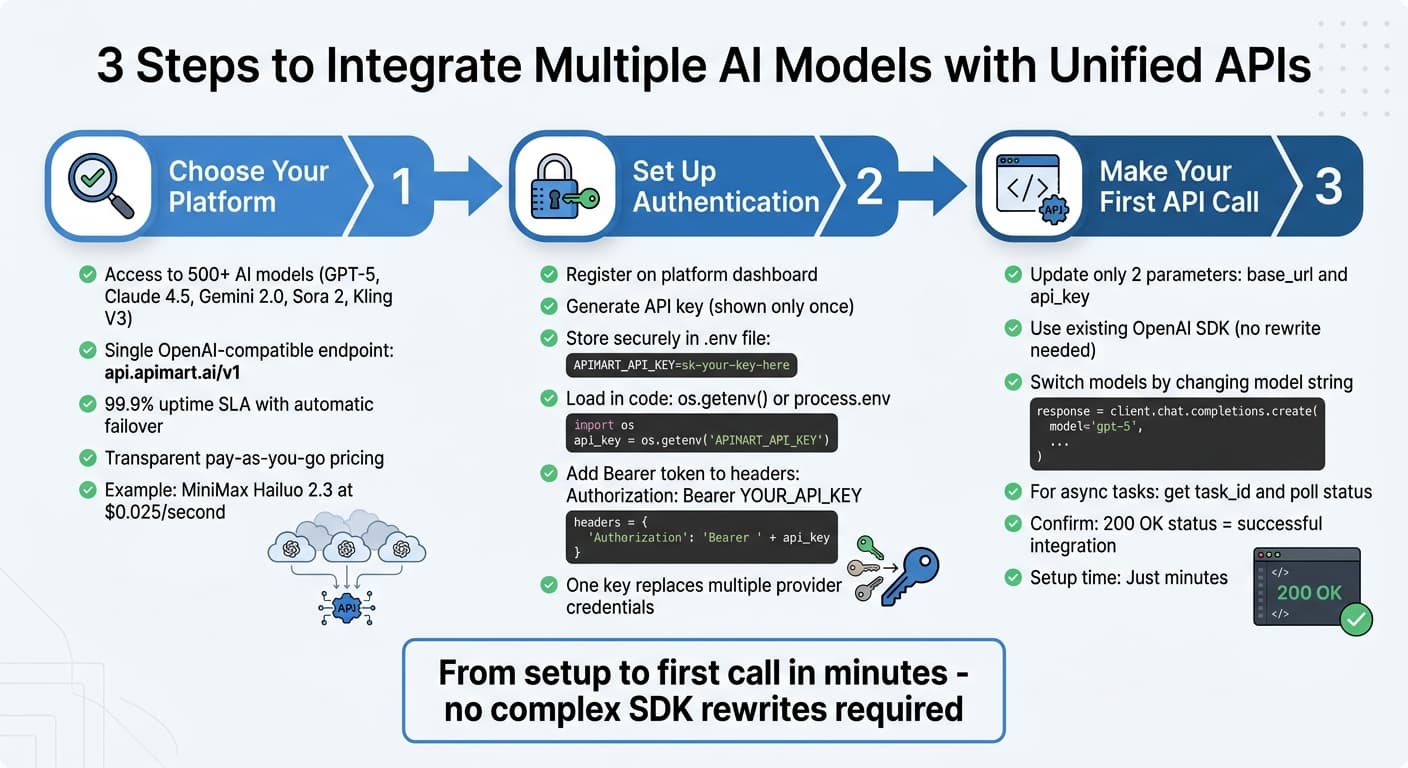
Интеграция через унифицированный API обычно включает три шага: получить доступ, настроить окружение, отправить запрос. Платформы вроде APIMart упрощают связку текстовых, графических и видеомоделей.
Выбор платформы
Ищите разнообразие моделей, прозрачные цены и мультимодальность. Например, APIMart даёт доступ к 500+ моделям, включая GPT-5, Claude 4.5, Gemini 2.0 и видео вроде Sora 2 и Kling V3 — через единый OpenAI-совместимый endpoint https://api.apimart.ai/v1 [10]. Совместимость позволяет не выбрасывать текущие SDK.
Учитывайте аптайм и инфраструктуру: у APIMart заявлены SLA 99,9%, автоматический failover и глобальный CDN для низкой задержки [10]. Оплата прозрачная, pay-as-you-go. Простые задачи можно деплоить на экономичные модели вроде MiniMax Hailuo 2.3 ($0.025/с), тяжёлые — резервировать под топ [10].
После выбора платформы — аутентификация и безопасность.
Настройка аутентификации и безопасности
Зарегистрируйтесь в панели, сгенерируйте API-ключ и храните его в переменной окружения (например .env). Ключ часто показывается один раз — сразу сохраните [9]. Не хардкодьте ключ в репозиторий.
Создайте .env в корне проекта:
APIMART_API_KEY=sk-your-key-here
В коде загружайте через os.getenv("APIMART_API_KEY") в Python или process.env.APIMART_API_KEY в Node.js [4]. В продакшене лучше secret manager. Каждый запрос — с Bearer-токеном в заголовке:
Authorization: Bearer YOUR_API_KEY
Один ключ заменяет отдельные учётные данные OpenAI, Anthropic и Google [9]. Далее — тестовый вызов.
Первый API-запрос
Если знакомы с OpenAI SDK, обычно меняете только base_url и api_key. Пример с GPT-5:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.apimart.ai/v1",
api_key=os.getenv("APIMART_API_KEY")
)
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Explain quantum computing in simple terms"}]
)
print(response.choices[0].message.content)
Смена модели — смена строки model. Для асинхронных задач (например видео) первый ответ может вернуть task_id; статус опрашивайте GET /v1/tasks/YOUR_TASK_ID до завершения [9]. Успех — статус 200 и корректное тело ответа. Добавьте обработку ошибок: 401 часто значит просроченный ключ или нехватка баланса [11]. При опыте с OpenAI SDK всё можно собрать за несколько минут.
Расширенные сценарии: мультимодельные пайплайны
Связывание текстовых, графических и видеомоделей через один API выводит интеграцию на следующий уровень.
Связка текста, изображения и видео
Можно строить цепочки: конвейер, где каждая модель — шаг [14]. Например: GPT-5 пишет бриф → Flux Pro рисует кадры → Kling V3 собирает видео.
Чтобы сэкономить, начинайте с картинок: статика $0.02-$0.08 за изображение, после утверждения переводите в видео через Sora 2 ($0.10 за генерацию) или Kling 2.6 ($0.04 за генерацию). Так вы избегаете дорогих итераций только на видео и держите стиль [15].
Для асинхронного видео используйте task_id и опрос каждые 5-30 с [13]. Нормализуйте ответы в единый JSON [14], чтобы вывод одной модели шёл параметрами в следующую. Бинарные данные (JPEG, PNG, WAV) удобно кодировать в base64 внутри JSON [12].
Производительность мультимодельного пайплайна
Оптимизируйте каскадом: простое — на дешёвые модели вроде Gemini Flash ($0.075 за 1M токенов), сложное — на Claude Sonnet ($3.00 за 1M токенов). Так можно снизить расходы на 60-80% [3][14][8].
Для real-time критична низкая задержка: ответ 30 с для пользовательского UI часто неприемлем, даже при HTTP 200 [17]. Следите за P95, включайте фолбэки по латентности и параллельные вызовы (например asyncio.gather) [8][14].
Эффективность начинается с препроцессинга: уменьшайте изображения до 1024-2048 px, для анализа видео — около 1 кадра/с [1][16]. При повторном использовании длинных материалов включайте prompt caching (OpenAI и Anthropic) — дешевле и быстрее [14]. Для визуальной согласованности прокидывайте фиксированные seed и соотношения сторон (например 16:9) через весь пайплайн [15].
Лучшие практики мультимодельной интеграции
В продакшене решают не только «подключили», но и сбои провайдеров, лимиты и разгон бюджета.
Ошибки и отладка
Не на каждую ошибку нужен фолбэк: 4xx (например 400) часто значит невалидный ввод — смена провайдера не поможет. Фолбэки логичны для 429 и 5xx [17].
От каскадных отказов помогает circuit breaker: при серии сбоев временно перестаёте бить в провайдера, ждёте cooldown, затем пробный запрос [18].
Задержка важна не меньше аптайма: 30 с на ответ для пользовательского приложения почти всегда «не работает», даже при успешном 200 [17]. Контролируйте P95 и маршрутизируйте на более быструю модель при деградации.
Почему цепочка фолбэков важна: у OpenAI в 2024 было 47 инцидентов со статусом — в среднем раз в восемь дней [17]. Заложите фолбэк с начала и прогоните тест: отзовите ключ в staging и убедитесь, что трафик уходит на запасного провайдера [3][17].
| Ошибка интеграции | Последствие | Исправление |
|---|---|---|
| Нет цепочки фолбэков | Падение при даунтайме провайдера | Минимум два провайдера [17] |
| Одна модель на все задачи | Переплата за простые запросы | Маршрутизация по сложности [17] |
| Фолбэк на любую ошибку | Лишние задержки | Только 5xx и 429 [17] |
| Игнор лимитов | Лавина ответов 429 | Ограничения частоты по провайдерам [17] |
Дальше — удержание бюджета.
Контроль и снижение затрат
Маршрутизируйте по сложности: гонять всё в GPT-4o или Claude Sonnet дорого. Для классификации и извлечения данных берите дешёвле — например Gemini Flash ($0.075 за 1M входных токенов) — в разы дешевле GPT-4o и Claude Sonnet [17]. Премиум оставьте для рассуждений, ревью кода и креатива.
Сразу задайте лимиты бюджета: дневные и часовые потолки на шлюзе, чтобы циклы не сожрали месячный лимит за часы [3].
Кэш снижает расходы на 40-60% и ускоряет повторяющиеся запросы [2][14] — особенно при больших справочных текстах. У OpenAI и Anthropic есть prompt caching.
Снимайте метрики по моделям — успех, латентность, стоимость — а не только общий счёт; так проще крутить правила маршрутизации. Если большая часть бюджета всё ещё уходит на самую дорогую модель, каскад, возможно, не срабатывает [3][5].
| Модель | Вход (за 1M токенов) | Выход (за 1M токенов) | Лучше всего для |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | Универсальные и креативные задачи |
| Claude Sonnet | $3.00 | $15.00 | Код и анализ |
| Gemini Flash | $0.075 | $0.30 | Высокий объём, чувствительность к цене |
| GPT-4o mini | $0.15 | $0.60 | Бюджетная альтернатива |
| Claude Haiku | $0.25 | $1.25 | Бюджетная альтернатива Sonnet |
Не откладывайте проверку фолбэков до инцидента: отключите ключи в тесте и убедитесь, что трафик переключается [3][5].
Итог: упрощаем разработку с унифицированными API
Несколько моделей без общего шлюза — головная боль; унифицированный API сводит всё к одному endpoint, одному SDK и одному счёту. Выбор провайдера становится правкой конфигурации, а не жёстким архитектурным коммитом [7]. Мультимодальные сценарии проще, vendor lock-in слабее, смена моделей — минимальные правки кода.
Прирост продуктивности заметен: в начале 2026 Thomson Reuters на унифицированном SDK за два месяца и командой из трёх разработчиков выпустила CoCounsel для юристов [7].
Надёжность растёт за счёт автоматического failover и маршрутизации по сложности. При 37% предприятий с пятью и более моделями в продакшене [7] и 47 инцидентах OpenAI в 2024 (~раз в восемь дней) [17] команды с фолбэками держали сервис, а «один провайдер» — нет.
Бюджет тоже проще: умная маршрутизация, централизованные лимиты и учёт по моделям освобождают время для продукта [7][17].
Платформы вроде APIMart развивают идею дальше: 500+ моделей через один OpenAI-совместимый API — для мультимодальных пайплайнов и оптимизации затрат, с фокусом на продукт, а не на «пожар» инфраструктуры.
FAQ
Как выбрать модель под каждый запрос?
Учитывайте тип задачи, сложность, стоимость и надёжность модели. Внедряйте маршрутизацию по сложности или по цене: простое — на дешёвые модели, сложное — на мощные. Добавьте фолбэки при сбоях основной модели — так балансируете качество, цену и устойчивость.
Как унифицировать выходы текста, изображений и видео?
Задайте общую схему: поля status, оценки уверенности, данные по модальности (текст, URL изображения, метаданные видео). Нормализуйте ответы: визуальный контент — в структурированный JSON, текст — в единый формат. Control plane может централизованно приводить ответы к одному виду.
Как безопаснее обходиться с простоями и лимитами через фолбэки?
Опирайтесь на мультипровайдерную архитектуру с автоматическим failover и мониторингом здоровья.
Схема: API-шлюз или control plane маршрутизирует запросы, следит за провайдерами и переключает трафик при сбоях или всплесках 429.
Добавьте цепочку фолбэков: при отказе основного провайдера повтор с запасными. Так минимизируете простой и сохраняете непрерывность сервиса.
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.