
Паттерны интеграции мультимодального ИИ
Сравнение паттернов интеграции мультимодального ИИ для рабочих процессов с текстом, изображениями, аудио и видео: прямые вызовы, единые шлюзы, оркестрация, граница-облако.
Мультимодальный ИИ меняет то, как системы обрабатывают данные, объединяя такие входные данные, как текст, изображения, аудио и видео, в единый рабочий процесс. Эта технология позволяет осуществлять кросс-модальное рассуждение — связывая то, что видит камера, с тем, что слышит микрофон, — что открывает путь к более интеллектуальным приложениям в самых разных отраслях. Например, Duolingo использует её для изучения языков, а ритейлеры применяют для визуального поиска товаров.
Вот краткий обзор четырёх методов интеграции мультимодального ИИ:
- Прямая интеграция «модель — приложение» (Direct Model-to-Application): проста и быстра, идеальна для задач в реальном времени, таких как голосовые агенты. Однако она может быть дорогой и менее гибкой.
- Единый мультимодальный шлюз (Unified Multi-Modal Gateway): направляет задачи к нужным моделям через единый API, снижая инженерную сложность и повышая производительность.
- Оркестрированный многошаговый рабочий процесс (Orchestrated Multi-Step Workflow): последовательно использует специализированные модели для детальных задач, требующих высокой точности, но может увеличивать задержку.
- Гибрид «на устройстве и в облаке» (Hybrid On-Device and Cloud): балансирует скорость, стоимость и конфиденциальность, распределяя задачи между локальными устройствами и облачными системами.
Каждый подход имеет свои компромиссы по стоимости, масштабируемости и сложности, поэтому крайне важно согласовать выбор с потребностями вашего проекта. Платформы вроде APIMart упрощают такие интеграции, предлагая более 500 моделей в рамках одного API.
От изображений к агентам: создание и оценка мультимодальных рабочих процессов ИИ
1. Прямая интеграция «модель — приложение»
Эта схема напрямую связывает приложение с мультимодальной моделью — такой как GPT-4o, Gemini 1.5 Pro или Claude 3.5 Sonnet, — которая способна обрабатывать текст, изображения и аудио в одном вызове API.
«Мультимодальная способность существует на уровне модели, но надёжность мультимодальности обеспечивается проектированием на уровне системы». — Zro2One [6]
Главное преимущество здесь — низкая задержка. Например, GPT-4o выдаёт аудиоответы примерно за 320 миллисекунд, комфортно укладываясь в естественный диапазон разговорной речи в 300–500 миллисекунд [4][7]. Это делает его сильным выбором для приложений реального времени. Примеры включают голосовых агентов, визуальное устранение неполадок в реальном времени (например, загрузка фотографии сломанного устройства для немедленного получения инструкций по ремонту), а также задачи в режиме hands-free, где работники полагаются на голосовые команды, пока система обрабатывает визуальные данные [4][9].
Тем не менее, за эту простоту приходится платить. Мультимодальные запросы, как правило, в три-пять раз дороже, чем обработка только текста [8][10]. Для управления расходами можно предпринять такие шаги, как снижение разрешения изображений до 1024–2048 пикселей, сжатие файлов в форматы JPEG или WebP (с качеством 80–90 %) и использование хеширования контента (например, MD5) для кеширования результатов по повторяющимся медиавходам. Это позволяет избежать ненужных вызовов API [1][10].
Надёжность — ещё один ключевой аспект. Проблемы с сетью и ограничение частоты запросов могут приводить к частоте отказов от 3 % до 8 % [8]. Чтобы справиться с этим, системы должны включать механизмы резервного перехода (fallback). Например, если обработка изображения завершилась неудачей, система может перейти к обработке только текста вместо полной остановки [6][8].
Этот подход лучше всего работает, когда одна модель способна эффективно обрабатывать все типы входных данных. Платформы вроде APIMart упрощают развёртывание, предлагая единый API и облегчая внедрение мультимодальных решений. В следующих разделах мы подробнее рассмотрим более продвинутые стратегии интеграции для случаев, требующих дополнительной гибкости и контроля.
2. Единый мультимодальный шлюз
Единый мультимодальный шлюз работает как умный маршрутизатор, эффективно направляя запросы к нужной модальности через единую интеграцию. Этот подход упрощает процессы, снижая инженерную сложность и повышая производительность.
Преимущества для инженерных команд очевидны. Вместо того чтобы жонглировать четырьмя отдельными интеграциями — каждая со своей обработкой ошибок, аутентификацией и версионированием — вам нужно управлять только одной. Раджеш Наир, управляющий директор TechCloudPro, подчёркивает это преимущество:
«Преимущество мультимодальности по затратам заключается в снижении инженерной сложности — один конвейер заменяет несколько интеграций». [5]
Эта оптимизированная система также поддерживает интегрированное кросс-модальное рассуждение, которого трудно достичь с помощью отдельных конвейеров. Например, когда модель обрабатывает и фотографию повреждения, и письменное описание в одном проходе вывода, она может выявить несоответствия, которые фрагментированные системы могли бы упустить. Устраняя промежуточные шаги (такие как преобразование речи в текст, прогон его через LLM, а затем обратное преобразование текста в речь), задержку можно снизить на 40–60 %, гарантируя, что голосовые ответы остаются в пределах оптимальных скоростных границ [9].
Эти технические улучшения приводят к измеримым бизнес-результатам. В начале 2026 года ритейлер товаров для дома внедрил функцию визуального поиска товаров, позволяющую покупателям загружать фотографии для поиска подходящих позиций в каталоге. Это привело к повышению конверсии корзины на 34 % по сравнению с традиционным поиском по ключевым словам в течение первых трёх месяцев [2]. Аналогично, производитель автокомпонентов сократил 45-минутный процесс эскалации дефектов до менее чем четырёх минут, интегрировав фотографии техников и руководства по обслуживанию в единую систему [2].
Единый шлюз APIMart служит примером такого подхода, предлагая доступ к более чем 500 моделям (таким как GPT-5, Claude, Sora и Kling V3) через единый API. Эта схема позволяет бесшовно обрабатывать текстовые, графические и видеонагрузки. Для мультимодальных приложений, где критичны простота и производительность, этот паттерн оказывается переломным.
3. Оркестрированный многошаговый рабочий процесс
В отличие от единого шлюза, обрабатывающего запросы через один вывод, оркестрированный многошаговый рабочий процесс соединяет специализированные модели в последовательность, где каждая модель сосредоточена на конкретной задаче — например, распознавании речи (STT), классификации, рассуждении или синтезе речи (TTS). Представьте это как конвейерную линию, где каждая станция оптимизирована под свою уникальную роль и передаёт результат на следующий этап для дальнейшей доработки.
В основе этой системы лежит оркестратор. Этот компонент управляет потоком, маршрутизируя входные данные, проверяя выходные, обрабатывая повторные попытки и запуская механизмы резервного перехода при необходимости [1]. Рабочий процесс начинается с экономичных моделей для базовых задач и переходит к более продвинутым моделям только при необходимости. Этот подход не только снижает затраты, но и повышает надёжность и прослеживаемость [5].
«Относитесь к моделям как к вероятностным компонентам за надёжным оркестратором: проверяйте выходные данные, используйте потоковую передачу для отзывчивости, применяйте инструменты для заземления (grounding) и непрерывно измеряйте стоимость и качество». — ASOasis [1]
Именно в надёжности эти оркестрированные рабочие процессы проявляют себя лучше всего, особенно в продакшен-средах. Поскольку каждый этап имеет чётко определённые параметры входа и выхода, проще проверять данные, заменять модели без полной перестройки системы и встраивать логику соответствия требованиям или бизнес-логику между этапами. Такой уровень контроля необходим для продвинутых мультимодальных приложений, требующих гибкости и точности. Однако есть компромисс: задержка. Хотя нативная модель «речь — речь» может выполнить задачу за 250–300 мс, оптимизированный оркестрированный конвейер обычно занимает 465–800 мс на полный цикл [7]. Для голосовых приложений перекрытие этапов — например, запуск TTS, как только LLM генерирует своё первое предложение, — может удерживать время отклика в пределах разговорного оптимума в 800 мс [7].
Преимущества этого рабочего процесса очевидны в реальных сценариях. Например, в 2026 году клиент-NBFC (небанковская финансовая компания) из Мумбаи внедрил оркестрированный рабочий процесс для обработки кредитов для ММСП (микро-, малых и средних предприятий). Эта система одновременно принимала кредитные заявки, отсканированные удостоверения личности и банковские выписки, выполняя кросс-документную проверку согласованности. Результат? Время обработки одной заявки аналитиком сократилось с 45 минут всего до 8 минут — впечатляющее сокращение на 82 % [2]. Этот пример подчёркивает, насколько эффективно оркестрация может справляться со сложными многоэтапными задачами.
Этот рабочий процесс особенно эффективен для процессов, включающих отдельные этапы, требующих детальной прослеживаемости или объединяющих несколько модальностей, которые естественным образом не укладываются в один вывод. Хотя добавленные этапы могут увеличивать задержку, они обеспечивают больший контроль и прозрачность.
Единый API APIMart поддерживает эту модель интеграции, позволяя организациям без труда подключать специализированные модели ИИ, необходимые для оркестрированных конвейеров. Эта возможность укрепляет более широкую рамочную систему единого API, позволяя командам с лёгкостью тонко настраивать свои мультимодальные решения.
4. Гибридная интеграция «на устройстве и в облаке»
Гибридная интеграция объединяет сильные стороны локальных и облачных вычислений, чтобы сбалансировать производительность и эффективность. Распределяя задачи между устройством пользователя и удалёнными моделями ИИ, этот подход гарантирует, что более простые и быстрые задачи — например, определение момента, когда кто-то начинает говорить, — обрабатываются локально, тогда как более сложные процессы, такие как глубокое понимание языка или продвинутое рассуждение, перекладываются на облако. Такое разделение позволяет получать более быстрые первоначальные ответы перед передачей данных в облако для более ресурсоёмкой обработки.
Возьмём в качестве примера детектирование голосовой активности (VAD). Выполнение VAD непосредственно на устройстве удерживает задержку на невероятно низком уровне — около 10 миллисекунд [7][11], — что критически важно для поддержания естественного, отзывчивого пользовательского опыта в голосовых приложениях. Напротив, более сложные задачи, такие как отправка изображения высокого разрешения в GPT-4o для мультимодального анализа, могут занимать значительно больше времени — от 4 до 12 секунд [2]. С точки зрения стоимости обработка на устройстве также имеет преимущества. Например, сжатие изображения 1024×1024 до 800×600 может сократить использование токенов в промпте на целых 60–80 % [8], что очень важно для команд, управляющих высоконагруженными приложениями в таких областях, как образование, электронная коммерция или развлечения. Инструменты вроде APIMart, поддерживающего более 500 моделей для зрения, языка и видео, упрощают маршрутизацию предобработанных данных к наиболее подходящей облачной модели в зависимости от задачи и бюджета.
Конфиденциальность — ещё одна область, в которой обработка на устройстве проявляет себя наилучшим образом. Скрывая персонально идентифицируемую информацию (PII) ещё до того, как данные покинут устройство, этот подход отвечает строгим требованиям к управлению данными в таких отраслях, как здравоохранение, финансы и юридические услуги [1]. Кроме того, гибридные модели обеспечивают подстраховку: если облачное соединение прерывается, локальные системы резервного перехода всё ещё могут выполнять базовые функции, гарантируя, что пользователи не остаются без обслуживания [1].
Однако гибридная интеграция не лишена сложностей. Синхронизация между компонентами на устройстве и в облаке может быть непростой. Например, если пользователь говорит «вот это», указывая на объект, разработчики должны обеспечить, чтобы локальный контекст безупречно совпадал с выводом облачной модели зрения. Хотя управление этим общим состоянием требует тщательной инженерной проработки, компромиссы в скорости, экономии затрат и конфиденциальности делают этот подход привлекательной стратегией для многих приложений. Правильная синхронизация — ключ к полному раскрытию этих преимуществ.
Плюсы и минусы
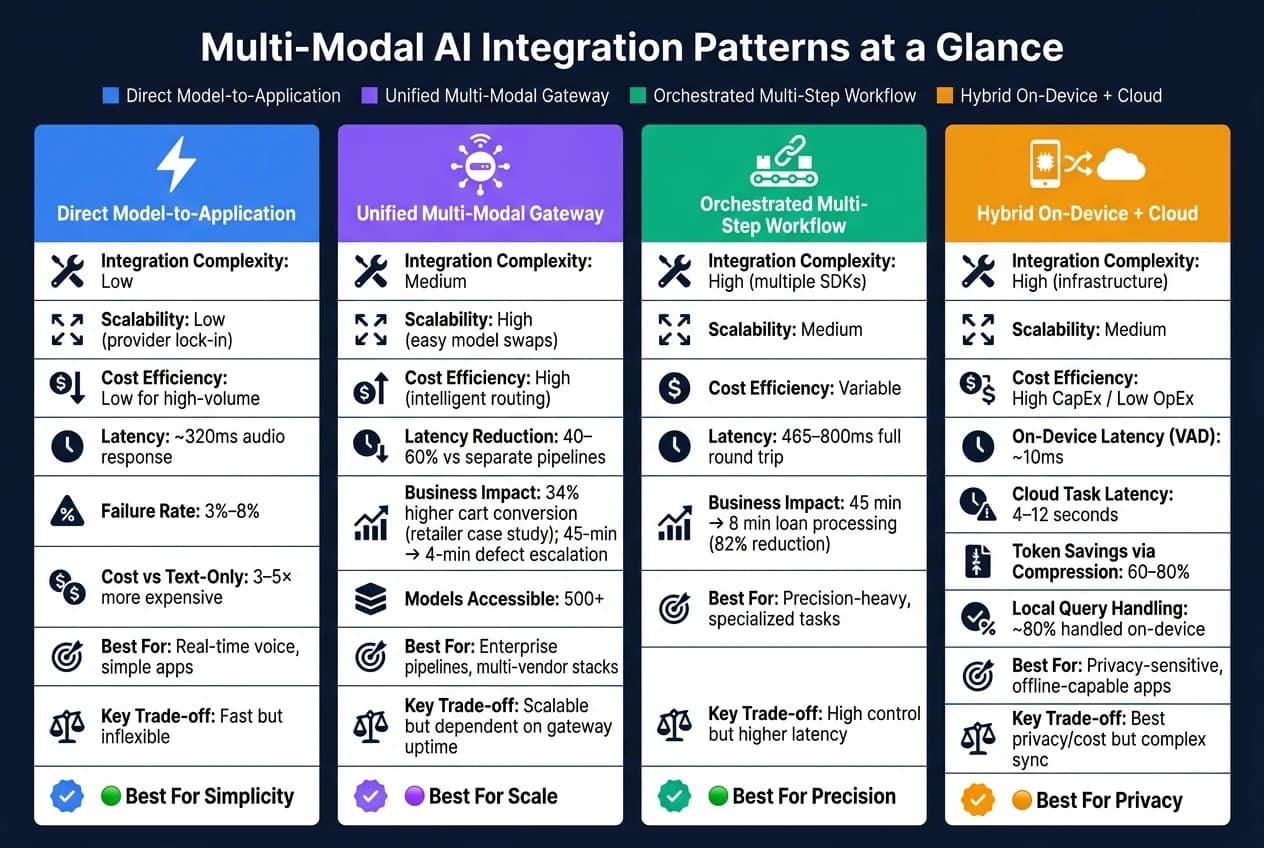
При выборе паттернов интеграции важно взвесить их сильные стороны и ограничения относительно целей вашей команды и потребностей проекта. В таблице ниже выделены ключевые практические различия между этими подходами:
| Паттерн | Сложность интеграции | Масштабируемость | Экономическая эффективность | Лучший сценарий использования |
|---|---|---|---|---|
| Прямая интеграция «модель — приложение» | Низкая | Низкая (привязка к поставщику) | Низкая при больших объёмах | Голос в реальном времени, простые приложения |
| Единый мультимодальный шлюз | Средняя | Высокая (лёгкая замена моделей) | Высокая (интеллектуальная маршрутизация) | Корпоративные конвейеры, мультивендорные стеки |
| Оркестрированный многошаговый рабочий процесс | Высокая (несколько SDK) | Средняя | Переменная | Задачи, требующие высокой точности и специализации |
| Гибрид «на устройстве + в облаке» | Высокая (инфраструктура) | Средняя | Высокие капзатраты / низкие операционные расходы | Приложения, чувствительные к конфиденциальности и работающие офлайн |
Прямая интеграция обеспечивает самое быстрое развёртывание и минимальную задержку, что делает её идеальной для несложных приложений вроде обработки голоса в реальном времени. Однако она привязывает вас к одному поставщику, что может ограничивать гибкость и увеличивать затраты по мере роста использования [4][6].
Единый мультимодальный шлюз решает проблемы масштабируемости и адаптивности. Например, переход с GPT-5 на более новую модель требует лишь изменения конфигурации, а не полной перестройки. Платформы вроде APIMart ещё больше упрощают это, предлагая единый API, подключённый к более чем 500 моделям. Они также обеспечивают интеллектуальную маршрутизацию задач — направляя более лёгкие задачи к экономичным моделям и резервируя продвинутые модели для сложных запросов. Основная зависимость здесь — обеспечение времени безотказной работы и совместимости API [3].
Оркестрированные рабочие процессы проявляют себя лучше всего, когда критична точность. Например, можно объединить Whisper для аудио, Sora для видео и специализированную модель зрения для анализа изображений — всё в рамках одного конвейера [3]. Хотя такая модульность мощна, она влечёт более высокую задержку из-за последовательных вызовов API и требует значительных инженерных усилий для поддержания синхронизации [4].
Наконец, гибридная интеграция «на устройстве/в облаке» наиболее требовательна технически. Она требует надёжной инфраструктуры, но превосходит другие подходы в конфиденциальности и долгосрочном управлении затратами. Лёгкие локальные модели могут обрабатывать примерно 80 % запросов, и лишь самые сложные 20 % отправляются к облачным моделям для продвинутой обработки [4]. Этот баланс делает её сильным выбором для приложений, чувствительных к конфиденциальности или способных работать офлайн.
Заключение
Рассмотренные паттерны интеграции — от прямых связей с приложением до оркестрированных рабочих процессов — предлагают решения, адаптированные под разные задачи интеграции мультимодального ИИ. Прямая интеграция обеспечивает быстрое внедрение, но жертвует адаптивностью. Оркестрированные рабочие процессы, напротив, повышают точность, но сопровождаются дополнительной сложностью. Между тем гибридные модели занимают промежуточное положение, превосходно проявляя себя в таких областях, как конфиденциальность и экономическая эффективность. Единый мультимодальный шлюз предлагает привлекательное сочетание масштабируемости, бесшовной замены моделей и оптимизированной маршрутизации затрат.
Эти паттерны приносят измеримые преимущества в различных отраслях. Например, в образовании каскадные паттерны позволяют лёгким моделям обрабатывать рутинные запросы учащихся, передавая сложные вопросы более продвинутым системам. В развлечениях, где скорость имеет решающее значение, нативные мультимодальные модели могут давать почти мгновенные ответы «речь — речь», достигая задержки всего в 120–150 миллисекунд [9]. Это обеспечивает плавный, захватывающий пользовательский опыт.
Часто задаваемые вопросы
Какой паттерн мультимодальной интеграции выбрать для моего приложения?
Лучший паттерн интеграции для вашего приложения зависит от таких факторов, как задержка, контроль и сложность. Если вы стремитесь к простоте, единый мультимодальный контекст — надёжный выбор. С другой стороны, приложения, полагающиеся на специализированные модели, лучше подходят для оркестрированных конвейеров. Для динамичных и итеративных задач хорошо работают последовательные агенты, хотя их может быть сложнее отлаживать. При работе со статичным контентом стоит выбрать предобработку и извлечение (retrieval). Инструменты вроде APIMart облегчают этот процесс, предлагая бесшовную обработку мультимодальных входных данных через единый API.
Как сократить затраты на мультимодальность, не жертвуя качеством?
Чтобы держать расходы на низком уровне без ущерба для качества, рассмотрите многоуровневую стратегию. Делегируйте несложные задачи более доступным специализированным инструментам, таким как ASR (автоматическое распознавание речи) или OCR (оптическое распознавание символов), вместо того чтобы полагаться на дорогостоящие мультимодальные модели для всего. Вы также можете тонко настраивать входные данные для экономии ресурсов — понижать разрешение изображений до значений вроде 768x768, сэмплировать видео с меньшей частотой (например, 0,5–2 кадра в секунду) и кешировать промпты, чтобы сократить ненужные повторения. Инструменты вроде APIMart облегчают этот процесс, предоставляя единый интерфейс для тестирования и комбинирования экономичных моделей без необходимости разбираться со сложными интеграциями.
Когда использовать обработку на устройстве, а когда — в облаке?
Выбирайте обработку на устройстве, когда задачи требуют строгой конфиденциальности или немедленных ответов с низкой задержкой. Этот подход лучше всего работает для обработки конфиденциальных данных или выполнения операций в реальном времени, где критичны скорость и конфиденциальность.
Для ресурсоёмких задач, таких как крупномасштабный анализ видео или продвинутое визуальное рассуждение, оптимальны облачные платформы вроде APIMart. Облако предоставляет доступ к мощным моделям ИИ и поддерживает мультимодальные входные данные, что делает его идеальным для обработки требовательных приложений, превышающих возможности локального оборудования.
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.