
Мультимодальная интеграция датасетов: полное руководство
Как работает мультимодальная интеграция датасетов: выравнивание текста, изображений, аудио и видео, предобработка, кросс-модальное выравнивание, управление данными и унифицированные API.
ИИ эволюционирует, чтобы обрабатывать сразу несколько типов данных — текст, изображения, аудио и видео. Это называется мультимодальной интеграцией датасетов. В отличие от одномодальных моделей, которые работают с одним типом данных за раз, мультимодальные системы объединяют и выравнивают разнообразные форматы для лучшего понимания сложных ситуаций — например, обращений в поддержку, включающих скриншоты, голосовые сообщения и переписку в чате. Вот что нужно знать:
- Мультимодальные датасеты: объединяют различные типы данных (текст, изображения, аудио) в выровненные группы — например, подпись, звук океана, фотография пляжа и видео прибоя, описывающие одну и ту же сцену.
- Почему это важно: модели, обученные на мультимодальных данных, превосходят одномодальные — в частности, задачи видео-вопросов-ответов улучшаются более чем на 20%.
- Проблемы: различные форматы данных, выравнивание информации между модальностями и неполные датасеты.
- Решения: такие техники, как data remixing, маскирование модальностей и унифицированные API, упрощают интеграцию и повышают производительность. Инструменты вроде APIMart упрощают доступ к мультимодальным моделям.
Вывод: мультимодальные датасеты открывают возможности передового ИИ за счёт улучшения кросс-модального рассуждения. Успех зависит от высококачественного выравнивания данных, предобработки и управления.
От текста до видео: единое мультимодальное озеро данных для ИИ следующего поколения
Проблемы интеграции мультимодальных датасетов
Интеграция мультимодальных датасетов — это не простое объединение файлов из разных источников. Настоящая сложность состоит в том, чтобы заставить эти источники эффективно работать вместе. Выделяются три повторяющихся препятствия: работа с разными форматами данных, обеспечение кросс-модального выравнивания и обработка отсутствующих или неполных модальностей.
Работа с гетерогенностью данных
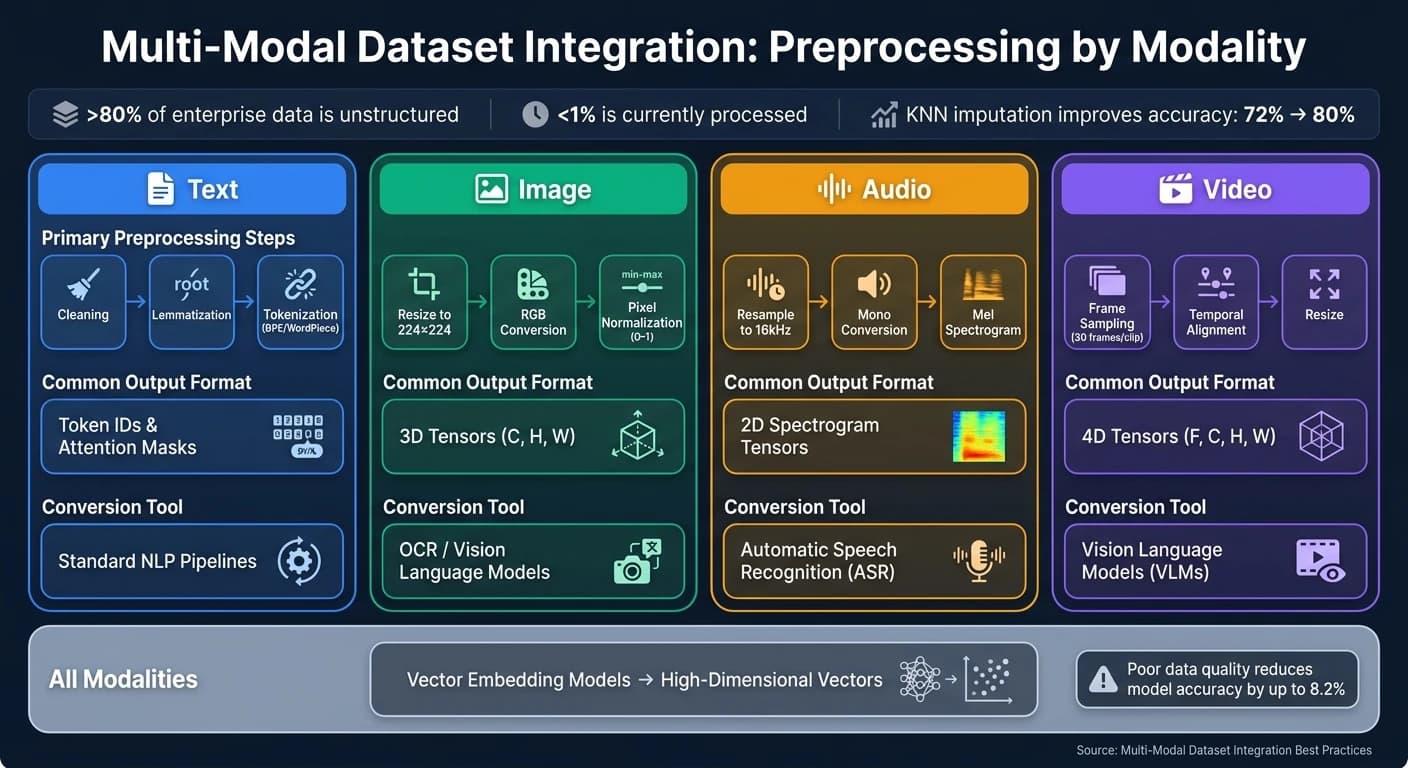
Знаете ли вы, что более 80% корпоративных данных существует в неструктурированных форматах — аудио, изображения, видео? При этом обрабатывается или анализируется менее 1% [9]. Это наглядно демонстрирует, насколько сложно преобразовать такие данные в нечто пригодное для моделей.
У каждого типа данных — модальности — есть своя специфика. Например, видеофайлы часто имеют непоследовательную частоту кадров, аудиоклипы могут быть повреждены или закодированы по-разному, а разрешение изображений может сильно варьироваться. Даже текстовые данные бывают как чистыми, так и зашумлёнными. Чтобы разобраться в этом хаосе, необходимо преобразовать сырые входные данные в унифицированный формат: ASR для аудио, OCR для изображений и модели «видение-язык» (VLM) для видео [9].
| Модальность | Основная стратегия преобразования | Выходной формат |
|---|---|---|
| Аудио | Автоматическое распознавание речи | Текст / транскрипты |
| Изображения | OCR / модели «видение-язык» | Текст / описания |
| Видео | Модели «видение-язык» (VLM) | Описания сцен с временными метками |
| Все | Модели векторных эмбеддингов | Высокоразмерные векторы |
Обеспечение кросс-модального выравнивания
Даже после преобразования данных в совместимые форматы семантическое выравнивание информации между модальностями остаётся отдельной задачей. Эта проблема, известная как семантический разрыв, возникает потому, что признаки из разных модальностей не выравниваются естественным образом.
«Семантический разрыв между модальностями по-прежнему остаётся недостаточно решённой проблемой. Если этот разрыв не устранён надлежащим образом, он может порождать ошибочные результаты, включая галлюцинации». — Shezheng Song и др., обзор мультимодальных больших языковых моделей [4]
Ещё одна проблема — «лень» и «конфликт» модальностей. В ходе совместного обучения модели часто отдают приоритет той модальности, которая оптимизируется быстрее, в результате чего другие модальности остаются недообученными. Исследователи Xiaoyu Ma, Hao Chen и Yongjian Deng объясняют это так:
«Разные модальности существенно различаются в траекториях оптимизации — по скорости и путям, — что при совместном обучении мультимодальных моделей приводит к лени и конфликту модальностей». [3]
Для решения этой проблемы применялась техника «Data Remixing», выравнивающая направления градиентов, что позволило повысить точность на 6,50% на датасете CREMAD и на 3,41% на Kinetic-Sounds — без каких-либо дополнительных вычислительных затрат [3].
Управление отсутствующими или частичными модальностями
В реальных сценариях датасеты редко бывают полными. Например, датасет может включать текст и изображения для большинства образцов, но не содержать аудио для значительной их части. Если модель не рассчитана на такую ситуацию, она может давать сбои или чрезмерно полагаться на наиболее сильную модальность.
Одно из решений — маскирование модальностей: отсутствующие модальности обнуляются во время обучения, позволяя модели учиться на доступных данных. Когда модальности имеют разную размерность эмбеддингов, обучаемые проекционные слои могут отображать их в общее векторное пространство, обеспечивая слияние даже при неполных данных [5][7]. Современные архитектуры, например Qwen2.5-Omni, созданы именно для такой гибкости и seamlessly обрабатывают комбинации вроде «текст + аудио» или «видео + текст» [6].
Создание надёжного мультимодального датасета — задача нетривиальная. Когда Encord в октябре 2025 года разработал датасет из 100 миллионов образцов, проверка автоматических кросс-модальных совпадений потребовала 976 863 оценок от людей и более 6 000 рабочих часов [1]. Это доказывает: автоматизации недостаточно — человеческая проверка остаётся критически важным этапом.
Эти проблемы лежат в основе лучших практик, которые рассматриваются в следующем разделе.
Лучшие практики интеграции мультимодальных датасетов
Сбор данных и проектирование схемы
Прежде чем собирать данные, необходимо установить единые стандарты схемы. Это включает согласованное использование идентификаторов, временны́х меток и соглашений об именовании для поддержания порядка и совместимости датасетов [10].
Эффективный подход — использование чередующегося (interleaved) формата со специальными токенами (например, <|__dj__eoc|>) и плейсхолдерами, специфичными для каждой модальности (например, <__dj__image>). Эти маркеры помогают упорядочить пути к медиафайлам в выделенных полях [8]. Применяя маппинг полей — связывая плейсхолдеры шаблонов, такие как {image_uris}, с конкретными столбцами датасета, — вы обеспечите гибкость схемы, применимость к различным типам задач без постоянного переформатирования [11].
Встраивание метаданных, специфичных для каждой модальности, например image_widths для изображений или audio_duration для аудиофайлов, служит двойной цели: поддерживает проверку качества и упрощает предобработку по модальностям. YAML-конфигурационные файлы особенно удобны для определения этих параметров, поскольку позволяют вести версионирование и обеспечивают воспроизводимость логики предобработки [8][12]. Низкое качество данных в мультимодальных промптах может существенно снижать производительность модели — точность падает до 8,2% [12]. Поэтому ранние проверки качества — выгодная инвестиция.
После создания единой схемы можно приступать к предобработке, адаптированной под каждую модальность при сохранении общей согласованности.
Предобработка по модальностям
Каждая модальность требует уникальных этапов предобработки перед интеграцией. Вот краткий обзор:
| Модальность | Основные этапы предобработки | Типичный выходной формат |
|---|---|---|
| Текст | Очистка, лемматизация, токенизация (BPE/WordPiece) | ID токенов и маски внимания |
| Изображения | Изменение размера (например, 224×224), конвертация в RGB, нормализация пикселей (0–1) | 3D-тензоры (C, H, W) |
| Аудио | Ресэмплинг до 16 кГц, конвертация в моно, преобразование в мел-спектрограмму | 2D-тензоры спектрограммы |
| Видео | Семплинг кадров (например, 30 кадров/clip), временно́е выравнивание, изменение размера | 4D-тензоры (F, C, H, W) |
Для аудио стандартизируйте до 16 кГц моно. Для изображений нормализуйте значения пикселей из исходного диапазона 0–255, разделив на 255,0, — это масштабирует их до диапазона 0–1, с которым нейронные сети работают эффективно. Для видео убедитесь, что последовательности кадров дополнены или обрезаны до фиксированной длины — это упрощает батчевую обработку. Устранение пропущенных данных с помощью методов вроде KNN позволяет повысить точность модели с 72% до 80% в промышленных приложениях [12].
«Чистые данные гарантируют, что модель работает с надёжной и согласованной информацией, помогая нашим моделям делать выводы на основе точных данных». — Latitude Blog [12]
Эти этапы предобработки создают стандартизированные выходы, подготавливая почву для эффективного выравнивания по модальностям.
Техники кросс-модального выравнивания
Большие языковые модели (LLM) могут служить универсальным интерфейсом для связи модальностей. Используя данные, сопряжённые с языком, — например, комбинации «изображение–текст» или «аудио–текст», — можно избежать зависимости от редких многосторонних сопряжённых образцов, таких как тройки «видео–аудио–текст» [2].
«Язык может выступать универсальным интерфейсом для универсального помощника: различные задачи могут быть явно представлены и разрешены на языке». — Zijia Zhao и др., Институт автоматики Китайской академии наук [2]
Для временно́го выравнивания полезен метод чередования аудио-визуальных токенов (AVTI). Он объединяет видео- и аудиоэмбеддинги в единую чередующуюся последовательность, сохраняя их внутренний порядок. Это позволяет LLM обрабатывать обе модальности как единый контекст без потери временно́й синхронизации [13]. При геометрическом несовпадении эмбеддингов модальностей поможет стратегия ReAlign — этот метод без обучения корректирует статистику первого порядка и исправляет дрейф центроидов без дополнительного обучения [14]. Вместе эти техники обеспечивают масштабируемый рабочий процесс выравнивания, подходящий для датасетов разного размера.
Техники и сценарии использования на основе мультимодальных датасетов
Выровненные и тщательно подготовленные мультимодальные данные открывают доступ к передовым техникам ИИ и практическим приложениям.
Совместные эмбеддинги и контрастивное обучение
Когда датасеты выровнены и предобработаны, становятся доступны такие техники, как совместные эмбеддинги: текст, изображения, аудио и другие форматы отображаются в единое векторное пространство. В этом пространстве семантически связанный контент группируется вместе независимо от исходного формата.
Ключевой метод — контрастивное обучение, в котором функция потерь InfoNCE сближает совпадающие пары и отдаляет несовпадающие. Этот подход выигрывает от внутрибатчевых негативов, генерируя O(N²) обучающих сигналов на батч. Модель OpenAI CLIP использует это в полной мере, применяя батчи до 32 768 пар и максимизируя воздействие «жёстких негативов» — контента, схожего по контексту, но различного по смыслу [15].
Однако может возникать разрыв между модальностями: эмбеддинги из разных форматов кластеризуются отдельно. Техника GR-CLIP решает это, вычитая средние эмбеддинги для перецентровки кластеров, что улучшает производительность поиска (NDCG@10) на 26 процентных пунктов по сравнению со стандартным CLIP. При этом достигается в 75 раз меньшее потребление вычислительных ресурсов по сравнению с генеративными методами эмбеддинга [16].
Эти стратегии эмбеддинга закладывают основу для более глубоких связей между модальностями.
Механизмы кросс-модального внимания
Кросс-модальное внимание связывает разные модальности — например, изображения и текст — путём сопоставления областей изображения с конкретными словами. Трансформерные архитектуры достигают этого, преобразуя различные форматы в общее семантическое пространство, где расстояния последовательно отражают смысл.
Модуль Perceiver реализует это, используя кросс-внимание для сжатия эмбеддингов переменной длины от нескольких энкодеров в фиксированный набор токенов запросов. Это снижает вычислительные затраты для больших мультимодальных моделей. Между тем архитектуры только с декодером, например Emu3, обрабатывают все модальности как единую последовательность токенов, превосходя другие в задачах генерации изображений и реконструкции видео. Например, Emu3 достигает превосходной реконструкции видео (rFVD: 27,893 vs. 139,930), используя при этом вчетверо меньше токенов, чем автономные токенизаторы изображений [18]. Настройка инструкций на разнообразных датасетах дополнительно повысила точность на бенчмарках видео-ответов-на-вопросы, например MSVDQA, на 21,8% [2].
Отраслевые применения
Эти передовые техники движут преобразованиями в различных отраслях.
В здравоохранении объединение данных — рентгеновских снимков, заметок радиологов и голосовых описаний пациентов — в единые датасеты улучшает точность диагностики. Платформы телемедицины теперь используют такие данные для создания автоматических предварительных сводок, интегрирующих видео, аудио и медицинские записи [17].
В электронной коммерции кросс-модальные эмбеддинги открывают инновационный шопинг-опыт. Например, покупатели могут искать товары по фотографии вместо текста. Изображение кодируется в то же векторное пространство, что и описания товаров и видеодемонстрации, что позволяет находить результаты через косинусное сходство [15]. Платформы вроде APIMart упрощают этот процесс, предлагая единый API, который подключается к более чем 500 моделям для изображений, видео и языка, делая кросс-модальный поиск и генерацию контента доступными.
В образовании объединение видеолекций с автоматически созданными транскриптами и структурированными метаданными позволяет создавать интеллектуальные системы обучения, поисковые видеобиблиотеки и персонализированные рекомендации контента. Область расширяется от бимодальных систем (изображение + текст) до пятимодальных установок, включающих аудио и 3D-облака точек. Датасет из 100 миллионов образцов, построенный на 5-кортежах, уже позволяет моделям одновременно «слышать» и «видеть» [1].
«Представьте, что было бы возможно, если бы существовала модель вроде CLIP, которая переваривает больше, чем просто текст и зрение? Что, если бы она ещё могла слышать аудио и ощущать окружение?» — Frederik Hvilshøj, ML Lead, Encord [1]
Управление и операции с мультимодальными датасетами
Управление мультимодальными датасетами в продакшене выходит за рамки простой технической интеграции. Это требует строгого управления данными для обеспечения воспроизводимости и соответствия правовым стандартам. Когда модели работают, нужны системы отслеживания использования данных, защиты конфиденциальной информации и поддержания возможности аудита.
Версионирование и происхождение датасетов
По мере усложнения мультимодальных датасетов отслеживание их происхождения становится необходимостью. Ключевая проблема — воспроизводимость: точное знание того, какие данные использовались для обучения, критически важно для отладки.
Для этого используйте хэши SHA-256 для каждого обучающего образца, хранящегося в манифесте с версионированием. Отслеживание зависимостей на уровне модальностей позволяет ограничивать обновления конкретными областями. Например, изменение в аудиопайплайне не должно требовать переобработки всего датасета, если этап распознавания лиц зависит только от видеокадров. Такие инструменты, как Metaxy (обновлён в мае 2026 г.), поддерживают целевое отслеживание зависимостей, сокращая ненужные усилия на переобучение [21].
Ещё одна важная практика — привязка снимков датасета к запускам обучения моделей. Такие инструменты, как Weights & Biases или MLflow, помогают замкнуть петлю между данными и результатами. Как объясняет Eren Hukumdar, сооснователь Entrapeer:
«Каждый запуск обучения модели теперь привязан к уникальному ID снимка, поэтому мы всегда знаем, какие данные дали какие результаты. Отладка, которая раньше занимала недели, теперь занимает часы, потому что нет никакой двусмысленности относительно версий датасета». — Eren Hukumdar, сооснователь, Entrapeer [20]
Вот краткое сравнение практик управления по размеру команды:
| Уровень управления | Для кого подходит | Ключевые инструменты | Компромиссы |
|---|---|---|---|
| Лёгкий | Небольшие команды (<5 человек, <100К образцов) | CSV-манифесты, SHA-256 | Ограниченная масштабируемость, нет принуждения [19] |
| Средний | Команды среднего размера (5–30 человек, 100К–10М образцов) | DVC, lakeFS | Высокие затраты на настройку, возможно замедление процессов [19][20] |
| Корпоративный | Крупные команды (30+ человек, регулируемые отрасли) | Неизменяемые журналы аудита, RBAC | Сложная настройка, развёртывание 6–12 недель [19] |
Конфиденциальность, безопасность и соответствие требованиям
Мультимодальные датасеты часто содержат конфиденциальную информацию: лица на видео, голоса в аудио или персональные данные в документах. Неправильное обращение с этими данными может привести к правовым и регуляторным проблемам, особенно в условиях ужесточения глобальных стандартов.
Для снижения этих рисков внедряйте многоуровневые средства контроля: обеспечьте законный сбор данных, подтвердите надлежащие права на использование и храните доказательства соответствия через журналы удалений и подписанные события [26]. При каждой задаче приёма данных генерируйте подписанное событие с идентификаторами источника и контрольными суммами. Если у входящих данных нет действительного основания прав или отсутствует запись в манифесте, немедленно останавливайте пайплайн, чтобы непроверенные данные не попали в обучающий пул [23][25].
Аудит 44 крупных датасетов для дообучения показал: более 70% не имели чёткого лицензирования, а ошибки в классификации лицензий превысили 50% [22]. Это создаёт серьёзный риск несоответствия требованиям, особенно в контексте таких регуляторных актов, как EU AI Act (вступил в силу в августе 2024 г., правоприменение началось в августе 2025 г.), который обязывает документировать управление обучающими данными в системах ИИ общего назначения [22].
«Идеально отформатированный датасет всё равно может оказаться непригодным, если его права не обоснованы или невозможно подтвердить его происхождение». — Daniel Mercer, старший редактор по управлению ИИ [23]
Для мультимодальных датасетов особенно полезны графы происхождения. Один видеоисточник может генерировать транскрипты, отдельные кадры и эмбеддинги — каждый из них рассматривается как производный. Графы происхождения отслеживают эти связи, позволяя эффективно удалять все производные при удалении исходного актива [24].
Когда практики управления прочно внедрены, фокус смещается на обеспечение бесперебойной операционной производительности.
Запуск мультимодальных моделей через унифицированные API
Хорошее управление поддерживает масштабируемые и надёжные рабочие процессы. Продакшн-системы должны обрабатывать ограничения скорости, доступность моделей и управление стоимостью по нескольким модальностям без необходимости отдельных интеграций для каждой из них.
Такие платформы, как APIMart, упрощают этот процесс, предлагая единый API, подключающийся к более чем 500 моделям для языка, изображений и видео. Унифицированная кредитная система позволяет командам легко прогнозировать затраты и избегать управления отдельными расчётными отношениями с несколькими поставщиками. Модели вроде GPT-5, Claude, Sora и Kling V3 доступны через один эндпоинт, поэтому не нужно переделывать мультимодальный пайплайн при каждой смене или добавлении модели. Для команд, выполняющих сложные продакшн-нагрузки, эта операционная согласованность снижает инженерные накладные расходы и минимизирует риск проблем интеграции.
Заключение
Интеграция мультимодальных датасетов — непростая задача, но результаты стоят усилий. Более 40% лидирующих компаний уже используют мультимодальные системы [17] и сообщают об ускорении решения задач поддержки на 35% [17]. Эти результаты задают высокую планку для команд, стремящихся улучшить модели с помощью реальных мультимодальных данных. Примечательно, что хорошо подготовленный датасет может превзойти модели, в четыре раза превосходящие его по числу параметров [1].
Вывод здесь предельно ясен: качество и выравнивание данных важнее простого масштаба. Как метко замечает Nature Machine Intelligence:
«Узкое место мультимодального ИИ — не размер модели, а качество и выравнивание исходных данных». [17]
Для этого необходим дисциплинированный подход: продуманное проектирование схемы, адаптированная предобработка для каждой модальности, эффективное кросс-модальное выравнивание и строгое управление. Практический первый шаг? Применить стратегию среднего слияния — объединять данные модальностей на промежуточном уровне. Это делает пайплайны модульными, упрощая отладку и адаптацию по мере изменения требований [27].
Кроме того, асинхронная параллельная обработка может значительно сократить время ожидания приёма данных на 40%–60%, а унифицированный шлюз способен снизить затраты на API на 60%–80% за счёт сжатия изображений и кэширования признаков [27]. Такие инструменты, как APIMart, упрощают этот процесс, предлагая единый API, поддерживающий более 500 моделей, включая GPT-5, Sora, Claude и Kling V3, — команды могут поддерживать согласованный интерфейс без полного обновления пайплайнов при каждом обновлении моделей.
Часто задаваемые вопросы
Как обеспечить выравнивание модальностей?
Чтобы модальности эффективно взаимодействовали, критически важно, чтобы они разделяли общее семантическое пространство. Простыми словами: они должны согласованно представлять понятия вне зависимости от формата или носителя.
Вот как поддерживать выравнивание:
- Структурированные проверки качества: используйте такие процессы, как самопроверки аннотаторов, взаимные проверки для обеспечения кросс-модальной согласованности и проверки старшими специалистами как финальный уровень контроля.
- Количественные метрики: такие инструменты, как центрированное ядерное выравнивание (CKA), могут измерять связи между наборами признаков, помогая оценить качество выравнивания модальностей.
- Платформы для интеграции: решения вроде APIMart умеют обрабатывать мультимодальные входные данные, облегчая интеграцию и работу с разнообразными типами данных в ваших проектах.
Сосредоточившись на этих шагах, вы сможете создать бесшовный и согласованный опыт работы с различными модальностями.
Что делать, если модальность отсутствует?
Чтобы эффективно справляться с отсутствующими типами данных (модальностями), необходимо построить систему, способную адаптироваться и сохранять функциональность. Такие стратегии, как постепенная деградация или передача знаний, помогут обеспечить надёжность системы при недоступности отдельных входных данных.
В процессе обучения такие техники, как отсев модальностей (modality dropout), подготавливают модель к работе с неполными данными, имитируя отсутствующие входы. Как альтернатива, фреймворк «учитель–ученик» обучает систему эффективно справляться с такими пробелами.
В продакшене можно реализовать резервные механизмы вроде интерполяции или оконного метода для заполнения недостающих данных или динамической адаптации рабочих процессов. APIMart обработает мультимодальные входные данные, позволяя проектировать рабочие процессы, которые надёжно и стабильно справляются с различными сценариями данных.
Какое управление требуется для мультимодальных обучающих данных?
Эффективное управление мультимодальными обучающими данными требует пристального внимания к происхождению данных. Это включает документирование способа сбора данных, подтверждение статуса согласия и определение условий, при которых может потребоваться их удаление.
Ключевые практики включают обеспечение кросс-модального выравнивания — например, корректного соответствия изображений соответствующему тексту или аудио. Кроме того, управление соответствием лицензий крайне важно для избежания правовых осложнений.
Организациям необходимо уделять первоочередное внимание обеспечению качества и поддерживать тщательные журналы аудита. Эти меры помогают справляться с такими проблемами, как запросы на удаление по GDPR, споры об авторских правах и проверки безопасности. Тем самым обеспечивается прозрачность и точность на протяжении всего жизненного цикла модели.
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.