
Мультимодельный API против одной модели: анализ затрат
Сравните затраты на мультимодельный и одномодельный API — тарифы использования, интеграцию, обслуживание и маршрутизацию по уровням, чтобы найти меньшую полную стоимость.
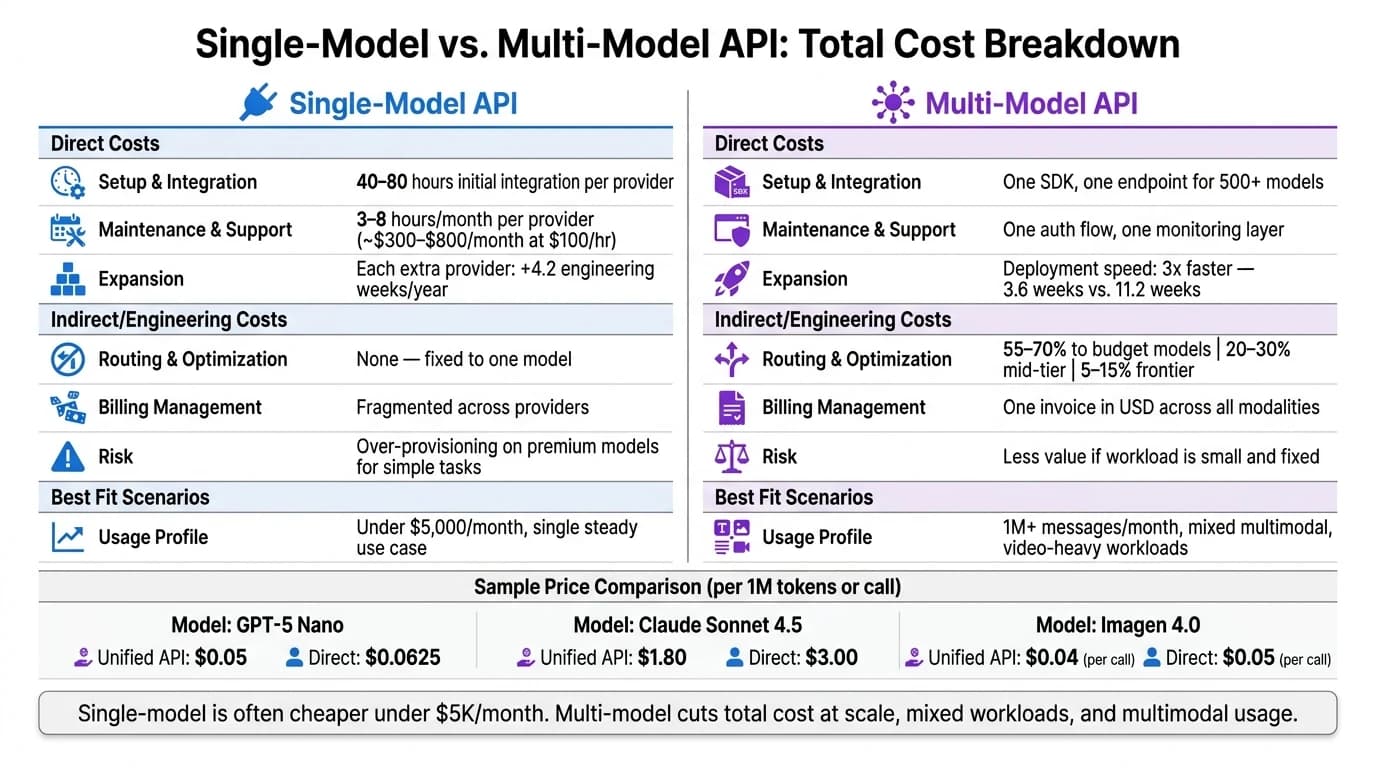
Если я смотрю только на прайс-лист API, я могу упустить самую большую часть счёта. В этом сравнении путь с меньшими затратами часто оказывается одномодельным для одной стабильной задачи с бюджетом до $5,000/month, тогда как мультимодельный подход часто выигрывает при смешанных нагрузках, мультимодальном использовании или больших объёмах.
Вот краткая версия:
- Одна модель означает одного провайдера, один SDK и одну настройку биллинга.
- Мультимодельный API означает одну интеграцию, которая может отправлять запросы к множеству моделей.
- Прямая цена API — это лишь часть затрат.
- Скрытые затраты часто складываются из:
- Инженерной настройки
- Ежемесячного обслуживания
- Проверки безопасности и соответствия требованиям
- Администрирования биллинга и работы с вендорами
- Прямая работа с провайдером может занимать 3–8 hours per month per provider, или около $300–$800/month при ставке $100/hour.
- Первоначальная прямая интеграция может занять 40–80 hours.
- Каждый дополнительный провайдер может добавить около 4.2 engineering weeks per year.
- Команды с мультимодельными настройками выпускали продакшн-агентов примерно в 3x faster: 3.6 weeks vs. 11.2 weeks.
- Маршрутизация работы по уровням моделей может сократить расходы, например:
- 55–70% на модели с меньшей стоимостью
- 20–30% на модели среднего уровня
- 5–15% на передовые модели
- Что касается тарифов использования, в статье приведены примеры, где единый доступ был дешевле:
- GPT-5 Nano: $0.05 vs. $0.0625 per 1M input tokens
- Claude Sonnet 4.5: $1.80 vs. $3.00
- Imagen 4.0: $0.04 vs. $0.05 per call
Если свести к одной строке: одна модель часто дешевле при малом фиксированном объёме; мультимодельный подход часто сокращает полные затраты, как только начинают играть роль масштаб, маршрутизация и время команды.
Методы оптимизации затрат для LLM-приложений — быстрее, дешевле и масштабируемо | Uplatz
Быстрое сравнение
| Критерий | Интеграция одной модели | Единый мультимодельный API |
|---|---|---|
| Настройка | Одно прямое подключение к провайдеру | Одно подключение к множеству моделей |
| Соответствие использованию | Лучше для одного стабильного сценария | Лучше для смешанных и растущих нагрузок |
| Биллинг | Один счёт от провайдера | Один счёт по всем моделям |
| Маршрутизация по цене/качеству | Нет | Да |
| Работа с доп. провайдерами | Растёт с каждым провайдером | Остаётся в одном слое |
| Инженерные накладные расходы | Сначала ниже, затем растут | Ниже при расширении объёма |
| Лучший сценарий по затратам | До $5,000/month, фиксированная задача | 1M+ messages/month, мультимодальность, много видео |
| Основной риск | Переплата за простые задачи на одной премиум-модели | Меньше пользы, если нагрузка мала и фиксирована |
Я бы использовал эту статью, чтобы принять решение по полной стоимости, а не только по прайс-листу.
Структура затрат интеграции одной модели
Прямые затраты: плата за использование и биллинг для узких нагрузок
Интеграция одной модели упрощает биллинг: один провайдер, одна настройка ценообразования. Для продукта на ранней стадии с одним основным сценарием такая простота помогает. У вас один счёт, один прайс-лист и меньше подвижных частей.
При этом простое не всегда означает дешёвое. Если использование резко вырастет, могут последовать доплаты за превышение. А на уровне предприятия некоторые провайдеры требуют минимальных обязательств. Такая схема работает лучше всего, когда спрос остаётся узким и легко прогнозируемым.
Косвенные затраты: интеграция, обслуживание и работа по соответствию требованиям
Счёт — лишь один фрагмент картины. Значительная часть расходов лежит за его пределами.
Команда среднего размера, интегрирующая провайдера напрямую, может ожидать 40–80 hours of initial integration work [2]. Обычно это означает написание кода адаптеров, обработку ошибок провайдера вроде ответов 429 и 5xx, настройку логики повторных попыток и работу с ротацией API-ключей. Это налог на интеграцию.
И это не заканчивается после запуска. Обновления моделей по-прежнему требуют внимания. Мониторинг по-прежнему отнимает инженерное время. Работа по соответствию требованиям может добавить ещё усилий. Вдобавок настройка на одной модели сосредотачивает доступ к данным в руках одного вендора, что может увеличить риск концентрации.
Когда одна модель дешевле и когда она становится дорогой
Настройки на одной модели остаются экономичными, когда нагрузка стабильна и узка. Это идеальная точка.
Проблемы начинаются, когда команды прогоняют каждую задачу через одну премиум-модель, даже самые простые. Именно здесь избыточное выделение ресурсов начинает съедать бюджет. А когда объём продукта растёт, отдельные интеграции провайдеров могут быстро накапливаться. Каждая добавленная прямая интеграция провайдера использует, по оценкам, 4.2 engineering weeks на первоначальную настройку и текущее обслуживание [1]. Эти накладные расходы накапливаются очень быстро.
Вот как это обычно выглядит по типу нагрузки:
| Сценарий | Поведение затрат при одной модели |
|---|---|
| Стабильный сценарий, низкий объём | Низкая стоимость, легко прогнозировать |
| Стабильный сценарий, всплески трафика | Риск доплат за превышение и минимальных обязательств |
| Несколько задач на одной премиум-модели | Избыточное выделение ресурсов повышает расходы |
| Больше интеграций со временем | Выше обслуживание и более фрагментированный биллинг |
Настройки на одной модели часто начинаются экономно. Но по мере роста объёма затраты могут расти вместе с ним. В следующем разделе эти затраты сравниваются по типу нагрузки.
Структура затрат единого мультимодельного API
Прямая экономия от консолидированного доступа и гибкого выбора модели
Настройки на одной модели часто стоят дороже, чем должны бы, потому что команды в итоге закупают лишнее. Единый API меняет это. Вместо отправки каждой задачи одной и той же модели вы можете направлять простую работу на модели с меньшей стоимостью, а более сильные модели держать для задач, которым они действительно нужны.
Это сдвигает затраты двумя чёткими способами: рутинные задачи идут на более дешёвые модели, а сложные задачи используют премиум-модели только при необходимости. На практике такая маршрутизация может ощутимо сократить расходы.
Биллинг тоже упрощается. Использование текста, изображений и видео отображается в one invoice in USD, что означает меньше уборки для финансов и меньше времени на сопоставление списаний между вендорами.
Корпоративные затраты на токены упали на 67% year-over-year by April 2026, во многом благодаря командам, которые уводили работу от дорогих передовых моделей, когда с задачей могли справиться варианты с меньшей стоимостью [1]. Одна распространённая схема — многоуровневый стек:
- Направляйте 55–70% of traffic на экономичные модели
- Резервируйте лишь 5–15% для передовых моделей [1]
Косвенная экономия от одной интеграции по множеству моделей
Бремя настройки от систем на одной модели не исчезает, когда команды добавляют больше провайдеров. Оно усугубляется. Каждый новый провайдер может означать ещё один поток аутентификации, ещё одну настройку мониторинга, ещё один путь управления и ещё один раунд обслуживания.
Единый API останавливает этот снежный ком на ранней стадии. Вы настраиваете один поток аутентификации, один слой мониторинга и один слой управления. Постройте это один раз — и оно работает для каждой модели за API.
Это важно, потому что накладные расходы на интеграцию растут каждый раз при добавлении нового провайдера. С единым слоем эта работа стягивается в одно подключение вместо того, чтобы распределяться по многим.
Команды, использующие мультимодельную инфраструктуру, развёртывают продакшн-агентов ИИ 3x faster: 3.6 weeks versus 11.2 weeks [1]. Меньше времени на инфраструктуру означает больше времени на выпуск продукта.
APIMart как практический пример этой модели
Пример платформы делает разницу в ценах проще для восприятия.
APIMart показывает, как единый доступ работает изо дня в день: один API, один поток биллинга и доступ к моделям для текста, изображений и видео.
Его линейка видеомоделей также показывает, почему маршрутизация важна. MiniMax Hailuo 2.3 Fast стоит $0.025/second, что делает его быстрым и недорогим вариантом. Kling V3 Omni стоит $0.0672/second (720p) и подходит для кинематографического результата по цене среднего уровня. Sora 2 Preview обходится в $0.08/second, обеспечивая баланс между качеством и стоимостью. Vidu Q3 Pro стоит $0.12/second и подходит для более требовательной, высокопроизводительной генерации.
| Модель | Цена | Лучше всего для |
|---|---|---|
| MiniMax Hailuo 2.3 Fast | $0.025/sec | Высокоскоростная, недорогая генерация видео |
| Kling V3 Omni (720p) | $0.0672/sec | Кинематографическая картинка и цена среднего уровня |
| Sora 2 Preview | $0.08/sec | Баланс качества и стоимости |
| Vidu Q3 Pro | $0.12/sec | Лучше для сложной, высокопроизводительной генерации |
| Единый мультимодельный API | Интеграция одной модели | |
|---|---|---|
| Биллинг | Один счёт в USD | Фрагментирован по провайдерам |
| Работа по интеграции | Один SDK, одна конечная точка | Уникальная настройка для каждого провайдера |
| Гибкость маршрутизации | Маршрутизация по стоимости или качеству | Привязана к одной модели |
| Обновления | Обновления провайдеров обрабатываются централизованно | Ручные обновления по каждому провайдеру |
| Лучше всего подходит | Смешанные, растущие нагрузки | Приложения с одной задачей и низким объёмом |
В следующем разделе эта экономия сравнивается по типу нагрузки.
Сравнение прямых затрат по типу нагрузки
Метрики затрат, используемые в этом сравнении
Затраты что-то значат только тогда, когда вы привязываете их к типу работы, которую выполняете.
Основные числа для сравнения — это cost per 1M input tokens, cost per image call, cost per video second и monthly USD spend. Это даёт гораздо более точное представление о полной стоимости нагрузки, чем один только прайс-лист.
Несколько примеров делают разрыв очевидным. GPT-5 Nano стоит $0.05 per 1M input tokens через APIMart против $0.0625 напрямую. Claude Sonnet 4.5 обходится в $1.80 против $3.00. Imagen 4.0 стоит $0.04 per call против $0.05. На небольшом проекте это может не ощущаться серьёзным. При масштабе это быстро накапливается.
Нагрузки, где одна модель часто стоит меньше
Для узких, предсказуемых нагрузок маршрутизация часто мало что вам даёт.
Представьте одну внутреннюю конвейерную задачу суммаризации или другой рабочий процесс с фиксированным объёмом и стабильными размерами входных данных. Если месячные расходы остаются below $5,000 и задача не меняется, обычно нет большой повседневной пользы в маршрутизации между несколькими моделями. В такой схеме прямая интеграция часто оказывается путём с меньшими затратами.
Нагрузки, где мультимодельный подход часто снижает общие расходы
Как только объём растёт и в картину входит более одной модальности, маршрутизация начинает играть роль.
Смешанные и высокообъёмные нагрузки, как правило, меняют расчёты. Если команда генерирует текст, изображения и видео — или обрабатывает 1M+ chat messages per month — затраты растут по мере распределения задач по разным сценариям. Именно здесь мультимодельная схема может сэкономить деньги: отправляйте простые запросы на модели с меньшей стоимостью, а премиум-модели держите для более сложных задач.
| Категория нагрузки | Оценка месячных расходов | Ключевые факторы затрат | Вероятный подход с меньшими затратами |
|---|---|---|---|
| Высокообъёмный чат (1M+ messages/month) | $10,000–$25,000 | Объём выходных токенов; токены рассуждений | Мультимодель (простые задачи на бюджетные модели) |
| Смешанная мультимодальность (текст + изображение + видео) | $15,000+ | Мультимодальные вычисления | Мультимодель (консолидированный биллинг, единый SDK) |
| Творчество с упором на видео (100+ hrs/mo) | $25,000+ | Тарифы рендеринга за секунду | Мультимодель (до 20% экономии на премиум-видеомоделях) |
| Стабильный внутренний инструмент (суммаризация) | Под $5,000 | Фиксированное использование; низкая сложность | Одна модель (если гибкость маршрутизации не нужна) |
Бюджетный фреймворк и итоговое руководство по решению
Пошаговый метод бюджетирования для команд в США
Используйте описанные выше паттерны нагрузки, чтобы превратить ценообразование в бюджетное решение. Этот метод состоит из трёх шагов.
Начните с базовой стоимости. Сначала оцените весь трафик через одну премиум-модель. Это даёт вам потолок, чтобы вы видели максимально вероятные расходы прежде, чем тестировать другие схемы маршрутизации.
Далее рассчитайте стоимость многоуровневой маршрутизации. Направьте 55–70% трафика на экономичные модели, 20–30% на модели среднего уровня, а передовые модели держите для 5–15% задач, которым нужны сложные рассуждения. Затем взвесьте каждый уровень по его доле в общем объёме и его ставке за токен, чтобы получить более дешёвую смесь.
Затем рассчитайте полную стоимость. Добавьте инженерные накладные расходы к обоим вариантам. Каждая дополнительная интеграция провайдера добавляет около 4.2 engineering weeks per year [1]. У этого времени есть денежная стоимость, и оно может быстро изменить решение.
После того как вы добавили использование и накладные расходы, лучший вариант — тот, у которого меньше полная месячная стоимость.
Когда выбирать одну модель и когда мультимодельный подход
Настройка на одной модели работает лучше всего, когда у вас один стабильный сценарий и низкая сложность. Она проще, легче в управлении и часто достаточно хороша для узких потребностей.
Мультимодельная настройка имеет больше смысла, когда нагрузки смешанные, использование растёт или важна избыточность. Если одни задачи простые, а другим нужны более глубокие рассуждения, маршрутизация работы по уровням моделей может сократить расходы, не загоняя вас в рамки.
APIMart предлагает один API для 500+ models, что сокращает дублирующую работу по интеграции по мере роста использования ИИ.
Заключение: самый низкий счёт не всегда означает самую низкую полную стоимость
Низкая ставка за токен на одной модели может выглядеть отлично в таблице. Но это число не показывает весь счёт. Время на интеграцию, циклы обслуживания и логика отказоустойчивости — всё это добавляет затраты. Единый мультимодельный доступ помогает по своей сути снизить многие из этих скрытых затрат.
Ключевые выводы:
- Цена использования — лишь одна часть полной стоимости.
- Многоуровневая маршрутизация сокращает расходы, когда нагрузки смешанные или мультимодальные.
- Накладные расходы на интеграцию растут с каждым добавленным провайдером.
- Одна модель подходит для стабильных, узких сценариев.
- Мультимодельный подход подходит для растущих, мультимодальных нагрузок.
Часто задаваемые вопросы
Как рассчитать полную стоимость сверх цены API?
Загляните на минуту дальше цены за токены. Более крупный отток часто исходит из повседневной работы по жонглированию несколькими провайдерами.
Дело не только в оплате использования API. Это дополнительное инженерное время, потраченное на построение слоёв адаптеров, обработку ошибок, написание собственной логики повторных попыток и управление беспорядком из отдельных API-ключей. Эта работа быстро накапливается. Во многих командах одно только обслуживание интеграции занимает 15–20 hours per month.
Безопасность тоже добавляет ещё один слой затрат. Когда токены доступа разбросаны по разным вендорам, управление усложняется. Становится проще оставить бесхозные ключи, что может привести к напрасным расходам и утечке средств, которую никто не замечает сразу.
Единая платформа вроде APIMart может свести эти подвижные части в одну панель управления, значительно упрощая контроль доступа и отслеживание расходов, сокращая при этом ручные накладные расходы.
Когда мультимодельный API становится дешевле одной модели?
Мультимодельный API становится дешевле, когда вы используете интеллектуальную маршрутизацию задача-модель вместо универсальной схемы.
Вот основная идея: отправляйте более простые задачи вроде классификации, суммаризации и извлечения данных на модели с меньшей стоимостью. Затем приберегите премиум-модели для более сложной или ответственной работы. Один этот сдвиг может сократить затраты на ИИ на 30% to 80%.
APIMart упрощает это, предоставляя доступ к 500+ models вместе с единым биллингом, объёмным ценообразованием и агрегированными скидками по всем нагрузкам ИИ.
Какие нагрузки больше всего выигрывают от маршрутизации моделей?
Маршрутизация моделей работает лучше всего для высокообъёмных, чувствительных к затратам нагрузок, где сложность задачи меняется от запроса к запросу. Основная идея проста: отправляйте лёгкую работу на модели с меньшей стоимостью, а передовые модели приберегите для сложного.
Это делает маршрутизацию отличным решением для работы вроде классификации, тегирования, суммаризации и фонового обогащения данных. В этих случаях большая доля запросов не требует самой дорогой модели, чтобы выполнить задачу.
Это также может помочь с:
- высокообъёмной пакетной обработкой
- чувствительными к задержке приложениями для пользователей
- ресурсоёмкими задачами вроде генерации видео
- агентными рабочими процессами, которые переключаются между рассуждением, инструментами и извлечением данных
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.