
Переключение AI-моделей без переписывания кода
Узнайте, как унифицированные AI API позволяют переключаться между 500+ моделями через один эндпоинт с помощью конфигурации, адаптерного слоя и безопасного A/B-тестирования на APIMart.
Переключение между AI-моделями может превратиться в настоящую головную боль: разные провайдеры — это разные настройки, SDK и форматы ответов. Но есть более удобный способ. Унифицированные AI API позволяют подключаться к нескольким моделям через единый интерфейс, делая переключение таким же простым, как изменение параметра конфигурации. Такой подход экономит время, снижает количество ошибок и избавляет от зависимости от одного провайдера.
Что вы узнаете из этой статьи:
- Унифицированные AI API упрощают интеграцию, стандартизируя эндпоинты, аутентификацию и параметры.
- Инструменты вроде APIMart подключают вас к 500+ моделям с помощью единственного API-ключа и эндпоинта.
- Такие приёмы проектирования, как централизация конфигураций и создание слоя маршрутизации, помогают переключать модели без усилий.
- A/B-тестирование и мониторинг обеспечивают плавные переходы при испытании новых моделей.
Унифицированные API устраняют необходимость в масштабных переработках кода, позволяя сосредоточиться на выборе подходящей модели для текущей задачи.
Понимание унифицированных AI API
Что такое унифицированные AI API?
Унифицированный AI API — это своего рода единое окно для подключения к множеству AI-моделей. Вместо того чтобы жонглировать разными настройками для каждого провайдера — будь то OpenAI, Anthropic, Google или другие — вы получаете единый интерфейс, который берёт на себя всю работу за кулисами. Не нужно разбираться в тонкостях процесса интеграции каждого провайдера.
При таком подходе переключение между моделями становится простым. Достаточно обновить строковое значение — не нужно переделывать аутентификацию или основную логику. Это делает унифицированные API идеальным выбором для тех, кто стремится упростить мультимодельную интеграцию без лишних переработок.
| Концепция | Унифицированный AI API | API одного провайдера |
|---|---|---|
| Эндпоинт | Один базовый URL (например, https://api.apimart.ai/v1) | Отдельные URL для каждого провайдера |
| Аутентификация | Authorization: Bearer KEY | Разные методы для каждого провайдера |
| Выбор модели | "model": "string-id" | Зависит от SDK или пути URL |
| Привязка к вендору | Низкая — переключение через изменение конфига [5] | Высокая — миграция затруднительна |
Ключевые компоненты унифицированной API-интеграции
Унифицированная API-интеграция опирается на четыре основных элемента: базовый URL, идентификатор модели, API-ключ и переменные окружения.
- Базовый URL упрощает всё, заменяя все специфические эндпоинты провайдеров одним универсальным адресом [1].
- Идентификатор модели — например,
"gpt-4o"или"claude-opus-4"— сообщает шлюзу, какую AI-модель использовать. - API-ключ обеспечивает защищённый доступ через унифицированный шлюз.
- Переменные окружения позволяют легко вносить изменения в конфигурацию, не затрагивая продуктивный код.
Одно из преимуществ использования унифицированного шлюза — он добавляет лишь около 3–50 мс дополнительной задержки на запрос [4]. Это едва заметно по сравнению со временем, которое требуется самой модели для обработки запроса. Кроме того, такие шлюзы часто решают непростую задачу нормализации параметров. Разные провайдеры используют разные термины для одних и тех же функций. Например, степень строгости следования модели вашему запросу может называться guidance_scale у Flux и Google, cfg_scale у Stability и quality у OpenAI [3]. Унифицированный API сглаживает эти различия, позволяя работать с единообразными параметрами вне зависимости от провайдера.
OpenRouter: единый API для 300+ AI-моделей
Как структурировать приложение для простого переключения моделей
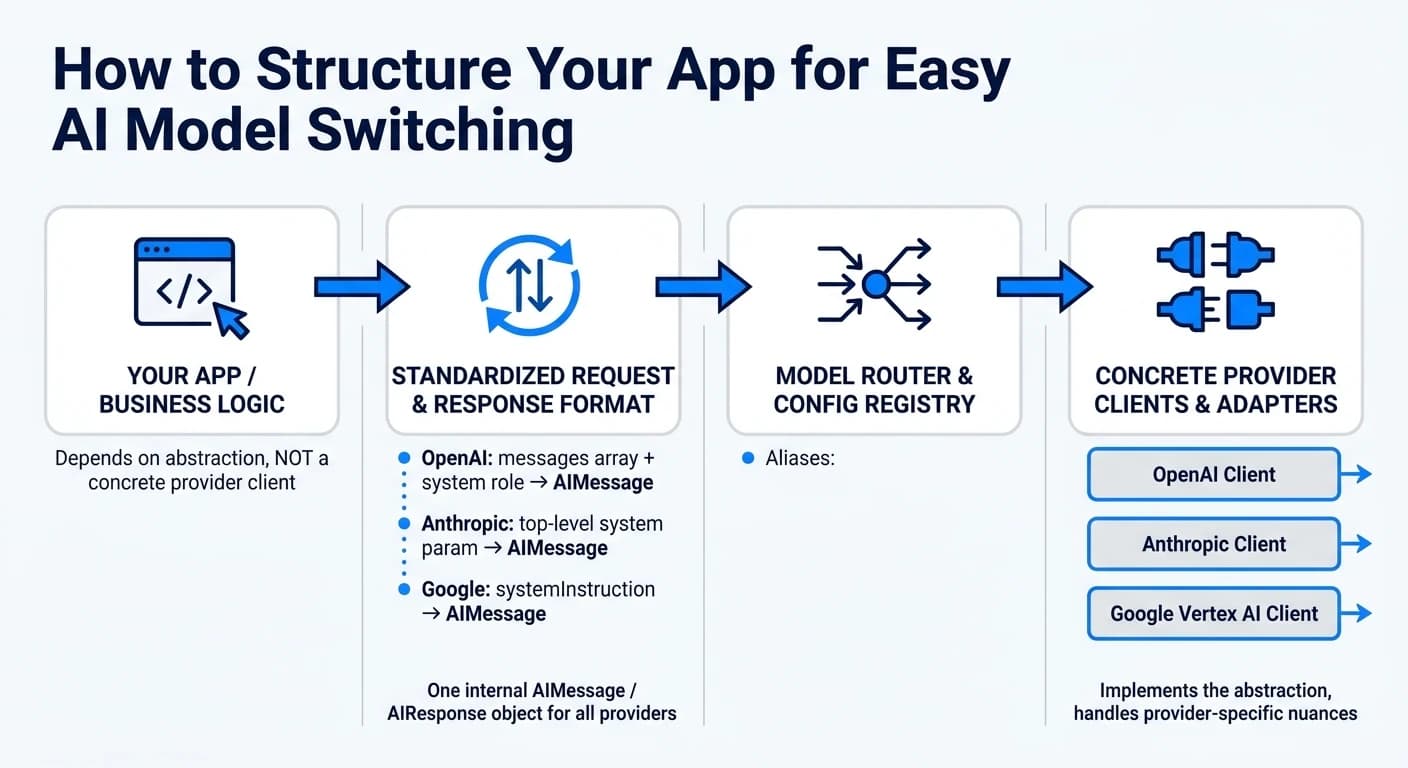
Чтобы получить максимум от унифицированной API-интеграции, важно проектировать приложение так, чтобы оно оставалось гибким при работе с разными моделями. Ключевой принцип — разделение бизнес-логики и API-специфичной логики. Как поясняет инженер и основатель Tian Pan:
«Ваша бизнес-логика должна зависеть от абстракции языковой модели, а не от конкретного клиента OpenAI или Anthropic.» [6]
Этот подход — не просто вопрос чистоты кода, это разумный способ избежать дорогостоящих проблем. Миграция производственной системы среднего масштаба, жёстко привязанной к одному провайдеру, может стоить от 50 000 до 100 000 долларов инженерного времени [6]. Описанные ниже стратегии помогут структурировать приложение так, чтобы избежать этих проблем.
Стандартизация форматов запросов и ответов
Создайте единый внутренний формат — например, интерфейс AIMessage или объект AIResponse — который остаётся неизменным независимо от используемой модели [2]. Адаптерный слой может переводить уникальные особенности каждого провайдера в этот стандартный формат, избавляя вас от масштабных изменений по всему коду.
Например, провайдеры по-разному обрабатывают запросы и ответы: OpenAI использует массив messages с ролью system, Anthropic требует параметр system на верхнем уровне, а Google применяет systemInstruction [2][9]. Со стороны ответов OpenAI помещает контент в choices[0], тогда как Anthropic — в content[0]. Адаптерный слой позволяет устранить эти несоответствия, экономя время и усилия при переключении моделей.
Централизация конфигурации модели
Используйте описательные псевдонимы вроде "text-fast" или "reasoning-premium" для обозначения конкретных идентификаторов моделей в центральном файле конфигурации [7]. Этот метод использует возможность унифицированного API изолировать специфические для провайдера детали, сохраняя бизнес-логику нетронутой. Когда выходит новая версия модели или вы хотите протестировать более экономичный вариант, вам нужно обновить лишь одну строку кода вместо того, чтобы искать по всему приложению.
Можно пойти дальше и создать реестр провайдеров, который связывает каждый псевдоним с фабричной функцией, динамически создающей нужного клиента во время выполнения [6][7]. Таким образом, остальная часть приложения не должна знать и заботиться о том, какой провайдер используется.
Построение слоя маршрутизации моделей
Слой маршрутизации выступает посредником между вашим приложением и провайдерами, решая, какая модель должна обрабатывать каждый запрос. Например, можно настроить маршрутизатор на основе правил, который отправляет сложные запросы в премиум-модели, а простые задачи — к более быстрым и дешёвым вариантам [10]. Этот слой работает в связке с унифицированным API, снижая сложность управления несколькими провайдерами.
Реальный пример: в апреле 2026 года SaaS-компания сократила ежедневные расходы на LLM на 58% — с 1420 до 594 долларов. Это удалось благодаря слою маршрутизации, направляющему простые задачи к дешёвым моделям и оставляющему премиум-модели для более сложных запросов [8]. Слой маршрутизации также управлял автоматическими резервными переключениями при ошибках вроде 429 или 5xx, обеспечивая бесперебойную работу [2][8].
Как переключать модели с помощью APIMart
APIMart как центральный хаб для управления моделями
APIMart упрощает управление AI-моделями, предоставляя централизованный доступ к более чем 500 моделям для работы с текстом, изображениями, видео и аудио — и всё это через единый эндпоинт: https://api.apimart.ai/v1. Один API-ключ, единый формат запросов и централизованные настройки делают переключение между моделями бесшовным.
Например, если вы используете OpenAI SDK для Python или Node.js, достаточно направить base_url на эндпоинт APIMart. Хотите перейти с GPT-5 на Claude 4.6 Sonnet? Просто обновите строку model — никаких новых SDK или процедур аутентификации.
Такая схема особенно удобна для команд, которым нужно быстро экспериментировать. Вместо создания отдельных интеграций для каждого AI-провайдера можно использовать одну streamlined-интеграцию и при необходимости корректировать конфигурации.
Переключение между видеомоделями в зависимости от потребностей проекта
В сфере генерации видео выбор правильной модели критически важен. Каждая модель имеет свои компромиссы в плане стоимости, качества и скорости в зависимости от задачи. APIMart упрощает этот процесс, предлагая несколько вариантов видеомоделей через один и тот же API, чтобы вы могли выбрать наилучший вариант для своего проекта, не меняя рабочий процесс.
Краткое сравнение популярных вариантов:
| Модель | Цена | Лучше всего для |
|---|---|---|
| MiniMax Hailuo 2.3 | $0.025/сек | Быстрые экономичные черновики |
| Kling V3 Omni (720P) | $0.0672/сек | Мультимодальные входные данные и универсальность |
| Sora 2 Preview | $0.08/сек | Высококачественные креативные результаты |
Например, MiniMax Hailuo 2.3 идеально подходит для ранних черновиков или внутреннего брейнсторминга, где приоритеты — скорость и экономия. Если нужно работать с текстовыми и графическими входными данными для создания коротких клипов, Kling V3 Omni — надёжный выбор. Для клиентских кампаний, где первостепенна качество, выбирайте Sora 2 Preview. Поскольку все эти модели используют одинаковую структуру запросов, переключение между ними сводится к обновлению одного значения в конфигурации.
Такая гибкость также упрощает интеграцию мультимодальных рабочих процессов в ваши проекты.
Выполнение мультимодальных рабочих процессов с помощью единого API
Унифицированный API APIMart создан для работы с мультимодальными рабочими процессами при минимальных усилиях. Выстраивая цепочки из разных типов моделей в едином пайплайне, вы можете корректировать идентификаторы моделей на разных этапах, не беспокоясь об аутентификации, выставлении счетов и отслеживании изменений.
Пример пайплайна для производства контента:
| Шаг | Пример модели | Задача |
|---|---|---|
| 1. Написание сценария | GPT-5 | Создание творческого брифа и видеоподсказок |
| 2. Раскадровка | Flux Pro | Генерация референсных изображений по сценарию |
| 3. Синтез видео | Kling V3 Omni | Превращение изображений в кинематографические клипы |
| 4. Финальная доработка | Sora 2 Preview | Создание высококачественных финальных сцен |
Секрет управляемости такого пайплайна — конфигурационно-ориентированный подход. Централизуйте такие детали, как идентификаторы моделей, форматы входных данных и параметры (например, resolution, duration, aspect_ratio) в один объект конфигурации. Тогда, если понадобится заменить видеомодель на шаге 3, это не затронет предыдущие этапы написания сценария или генерации изображений.
Для задач работы с видео и изображениями APIMart обрабатывает их асинхронно. Он предоставляет task_id, который можно использовать для опроса результатов с экспоненциальной задержкой (начиная с 10–20 секунд) до завершения задачи.
Лучшие практики безопасного и эффективного переключения моделей
Чтобы получить максимум от унифицированной API-интеграции APIMart, соблюдение ключевых практик в управлении конфигурацией, мониторинге и безопасности необходимо для плавных и защищённых переходов между моделями.
Версионирование и тестирование конфигураций моделей
При управлении конфигурациями моделей относитесь к ним как к коду. Используйте систему контроля версий для отслеживания изменений идентификаторов моделей, параметров и правил маршрутизации. Так при возникновении проблем вы сможете быстро откатиться к предыдущей версии. Подробная история изменений помогает диагностировать проблемы при переключении моделей.
Перед развёртыванием новой модели в продакшене проведите A/B-тестирование. Направьте небольшой процент живого трафика к новой модели и сравните её производительность с существующей. Такой подход даёт инсайты на основе реального использования, а не только тестовых данных. Для дополнительной проверки качества используйте подход LLM-as-judge: например, модели вроде GPT-5 или Claude 4.5 могут оценивать выборку 1–5% ответов новой модели, помогая выявить тонкие проблемы с качеством до того, как они затронут пользователей [8].
Ещё один важный инструмент — автоматические проверки работоспособности. Настройте периодические тестовые запросы (например, лёгкое завершение из 5 токенов) каждые 60–120 секунд. Это позволит рано обнаруживать сбои у провайдеров, снижая риск того, что о проблемах придётся узнавать из жалоб пользователей [2].
Мониторинг и логирование производительности моделей
Когда модель запущена в работу, внимательно следите за такими показателями, как задержка, стоимость и частота ошибок. Задержка, особенно время ответа P95 (95-й процентиль), — ключевой индикатор. Например, если модель отвечает за 30 секунд, она практически непригодна для пользовательских приложений, даже если технически возвращает HTTP 200 [2][8].
«Одна модель для всего — это прошлое. Выбирайте правильный инструмент для каждого запроса, и ваши расходы на AI снизятся на 40–70%.» — Akshay Ghalme, AWS DevOps Engineer, BytePhase Technologies [8]
Ваши логи также должны фиксировать метаданные о разрешённой модели — сведения о том, какая модель обработала каждый запрос. Это особенно важно в сценариях с резервным переключением. Если бюджетная модель часто эскалирует до премиум-варианта — скажем, более чем в 30% случаев — это сигнал о необходимости скорректировать логику маршрутизации [8].
Помимо мониторинга производительности, защита API-учётных данных критична для бесперебойной работы.
Безопасность API-ключей и соблюдение нормативных требований
Надёжные меры безопасности необходимы для поддержания стабильной мультимодельной среды и обеспечения плавных переходов между моделями без создания уязвимостей. Используйте один API-ключ APIMart, чтобы минимизировать поверхность атаки. Храните его безопасно в переменных окружения или менеджере секретов, избегая хардкодинга или фиксации в системе контроля версий.
Для команд, работающих в регулируемых отраслях, соблюдение нормативных требований обязательно. Как отмечает Akshay Ghalme:
«Маршрутизация должна соблюдать договорные и нормативные ограничения — некоторые данные не должны покидать определённый регион или вендора.» [8]
Убедитесь, что ваша логика маршрутизации соответствует правилам хранения данных. Используйте шлюзы с поддержкой соответствия SOC 2, единого входа (SSO) и централизованного аудита. Кроме того, реализуйте лимиты расходов для каждого тенанта, чтобы предотвратить неожиданные затраты — особенно в мультитенантных средах, где клиенты могут иметь разные уровни использования или требования к данным [8].
Наконец, резервируйте автоматические резервные переключения для конкретных типов ошибок. Например, используйте их для ответов 429 (превышен лимит запросов) и 5xx (ошибка сервера), где смена модели может решить проблему. Избегайте резервных переключений для ошибок 4xx вроде 400 Bad Request — они, как правило, указывают на некорректные входные данные, которые замена модели не исправит [2].
Заключение: гибкость с унифицированными AI API
Унифицированные AI API превращают переключение между AI-моделями в простую настройку — без масштабного кодирования и перестройки систем.
Стандартизируя форматы запросов и ответов, централизуя конфигурации моделей и маршрутизируя всё через единый интерфейс, вы избавляетесь от необходимости в сложной инженерной работе при смене моделей. Логика вашего приложения остаётся нетронутой, какую бы модель вы ни выбрали.
Возьмём APIMart в качестве примера. Его единственный эндпоинт подключается к более чем 500 моделям — для текста, изображений и генерации видео, — что позволяет командам переключаться между моделями без усилий. Представьте команду e-commerce из США, которая проводит A/B-тест двух языковых моделей для описаний товаров. Они могут скорректировать правило маршрутизации в APIMart, отслеживать результаты в USD и сравнивать конверсию — всё без развёртывания нового кода. Этот оптимизированный процесс помогает командам быстро адаптироваться к меняющимся потребностям проекта.
Такая схема масштабируется вместе с вами. Независимо от того, масштабируетесь ли вы под возросший трафик или интегрируете передовые инструменты вроде продвинутых видеогенераторов или узкоспециализированных моделей, этот унифицированный подход сохраняет простоту. Разработчики быстрее входят в работу, а система справляется с новыми технологиями, не нарушая работу основного приложения.
Сила унифицированных AI API в том, что они встраивают гибкость прямо в архитектуру. Переходы между моделями становятся рутинными корректировками, а не масштабными предприятиями. Такая адаптивность гарантирует готовность к любым изменениям.
Часто задаваемые вопросы
Как добавить переключение моделей в существующее приложение без полного рефакторинга?
Чтобы переключение моделей стало бесшовным без переписывания кода, рассмотрите использование унифицированного API-шлюза. Направив базовый URL вашего SDK на шлюз вроде APIMart, вы сможете легко управлять выбором модели, маршрутизацией и резервным переключением. Эта схема позволяет корректировать настройки — например, динамически обновлять параметр модели в коде — не трогая аутентификацию, логику SDK или обработку ошибок. Шлюз берёт на себя стандартизацию этих процессов, экономя ваше время и усилия.
Что должен включать слой маршрутизации моделей (и когда следует избегать резервных переключений)?
Слой маршрутизации моделей — это хаб, связывающий ваше приложение с разными AI-моделями. Его задача — управление маппингом запросов, выбор моделей на основе экономической эффективности, реализация стратегий резервного переключения и мониторинг производительности. Для поддержания стабильности используйте конфигурационно-управляемые карты маршрутизации, основанные на задаче-специфичных бенчмарках.
Для специализированных задач, требующих точного выполнения с единственной моделью, избегайте механизмов резервного переключения при семантических проблемах или проблемах качества. Такой подход обеспечивает строгий контроль качества и позволяет избежать компромиссов с результатами.
Как безопасно A/B-тестировать новую модель без нарушения работы продакшена?
Чтобы протестировать новую AI-модель без риска нарушить работу продакшена, начните с запуска модели в теневом режиме. При этой схеме продакшен-трафик направляется как к существующей, так и к новой модели. Текущая модель продолжает обслуживать пользователей, тогда как новая обрабатывает запросы в фоновом режиме — это позволяет сравнивать результаты, не влияя на живую систему.
Когда производительность новой модели подтверждена, можно использовать инструменты вроде унифицированного API-шлюза или feature flags для постепенного развёртывания. Они позволяют тщательно отслеживать метрики производительности и настраивать триггеры отката для поддержания стабильности системы при возникновении проблем.
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.