
Цены, производительность и масштабируемость AI API
Руководство по затратам AI API на 2026: как на деле складываются цены за токены, за изображение и за секунду, плюс задержка, лимиты и повторы, решающие, сколько вы платите.
Затраты на AI API в 2026 разбросаны повсюду: одна только цена за вывод колеблется от $0.28 до $50.00 за 1 миллион токенов — разрыв в 179 раз. Если бы я выбирал API сегодня, я бы прежде всего смотрел на стоимость, задержку, лимиты скорости и то, как система держится, когда трафик растёт.
Вот краткая версия:
- APIMart создан для команд, которым нужен один API для моделей текста, изображений и видео, плюс маршрутизация, асинхронные задачи и контроль расходов.
- Прямые API языковых моделей дают прямой доступ, но выходные токены часто стоят в 3–10 раз дороже входных, а токены рассуждений могут сильно поднять счета.
- Прямые API изображений часто оплачиваются за изображение, но ваша настоящая стоимость зависит от повторов, доли отказов, апскейлинга и того, сколько генераций нужно, чтобы получить одно пригодное изображение.
- Прямые API видео обычно оплачиваются за секунду, с долгими ожиданиями, асинхронной доставкой, затратами на повторы и жёсткими лимитами конкурентности.
- Унифицированные платформы AI API помогают, когда вам нужны маршрутизация моделей, отказоустойчивость и один биллинговый слой поверх нескольких провайдеров.
- Корпоративные пакеты подходят командам, которым нужны зарезервированная ёмкость, условия комплаенса, частное сетевое соединение и контрактная поддержка.
Если хотите простое правило, оно такое: выбирайте самую дешёвую модель, которая всё ещё отвечает вашей цели по качеству и задержке, затем протестируйте её на ваших собственных промптах при вашем собственном уровне трафика. Прайс-листы помогают, но p95-задержка, частота повторов, время в очереди и использование с большим выводом решают, сколько вы в итоге заплатите.
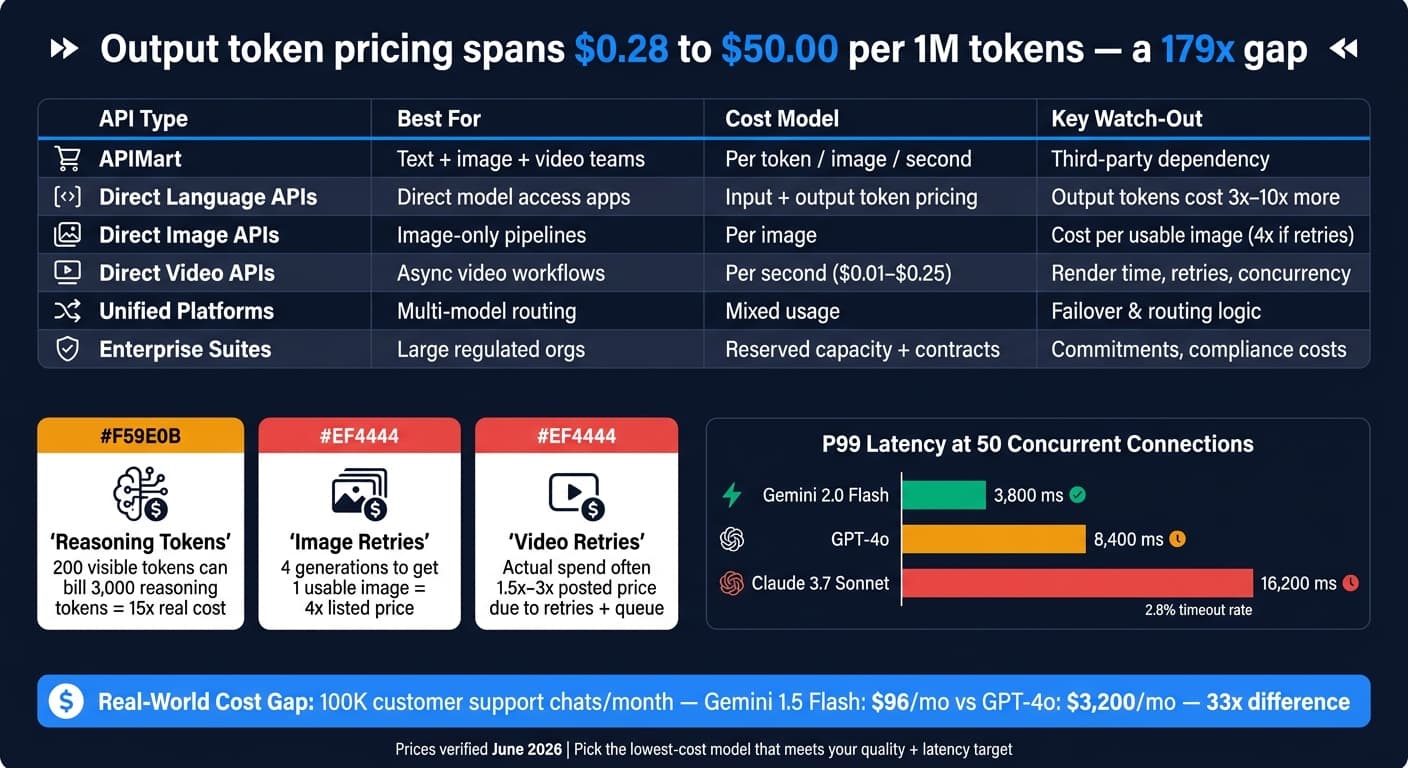
Быстрое сравнение
| Вариант | Лучше всего для | Основная модель стоимости | На что смотреть |
|---|---|---|---|
| APIMart | Команды, использующие текст, изображения и видео вместе | За токен, за изображение, за секунду | Зависимость от третьей стороны, соответствие пакета |
| Прямые языковые API | Приложения, которым нужен прямой доступ к модели | Цена за входные/выходные токены | Стоимость выходных токенов, токены рассуждений, лимиты скорости |
| Прямые API изображений | Продукты и конвейеры только для изображений | За изображение | Стоимость на пригодное изображение, время в очереди, истечение URL |
| Прямые API видео | Асинхронные видео-процессы | За секунду | Время рендера, повторы, лимиты конкурентности |
| Унифицированные AI-платформы | Мультимодельная маршрутизация по вендорам | Смешанная оплата за использование | Логика маршрутизации, обработка повторов, поведение при отказоустойчивости |
| Корпоративные пакеты | Крупные организации со строгими юридическими или инфраструктурными нуждами | Зарезервированная ёмкость и кастомные контракты | Обязательства, региональные цены, условия поддержки |
Вот линза, которую я бы использовал для остальной части этой темы: не просто заявленная цена, а полная стоимость получения пригодного результата на масштабе.
APIMart
APIMart даёт вам единый API для 500+ языковых, графических и видео-моделей. Для большинства команд это означает меньше работы по интеграции, более простое ценообразование и встроенные средства контроля для масштабирования. Эта настройка становится ещё полезнее, когда вы сравниваете затраты по сценариям текста, изображений и видео.
Он использует оплату по факту использования, без месячных минимумов и скрытых комиссий. Биллинг зависит от типа используемой модели: текст оплачивается за 1M входных токенов, изображения — за вызов, а видео — за секунду. На моделях, перечисленных ниже, APIMart выходит дешевле официальной цены. А по мере роста использования объёмные скидки и пакетное ценообразование могут снизить стоимость за единицу ещё больше.
| Модальность | Модель | Цена APIMart | Официальная цена | Единица |
|---|---|---|---|---|
| Текст | GPT-5 Nano | $0.05 | $0.0625 | За 1M входных токенов |
| Текст | Claude Sonnet 4.5 | $1.80 | $3.00 | За 1M входных токенов |
| Изображение | Imagen 4.0 | $0.04 | $0.05 | За вызов |
| Видео | Sora 2 | $0.08 | $0.10 | За секунду |
| Видео | Hailuo 2.3 Fast | $0.025 | $0.031 | За секунду |
Конечно, цена — лишь один кусочек пазла. Как только использование начинает расти, пропускная способность и надёжность важны не меньше.
APIMart маршрутизирует трафик по провайдерам, чтобы сократить троттлинг во время всплесков трафика, поддерживает асинхронные задачи с ID задач и вебхуками для более крупных задач и использует краевую доставку для снижения глобальной задержки [6][7]. Он также предлагает SLA на аптайм 99.9% для прод-нагрузок. Когда трафик начинает нарастать, мониторинг и бюджетный контроль важны не меньше, чем время отклика.
Для раннего использования панель помогает командам следить за тратами. На большем объёме лимиты и оповещения помогают остановить неожиданные списания, вызванные всплесками или повторяющимися повторами. Панель показывает расходы, квоты и использование в реальном времени, а блог APIMart даёт дополнительные советы по экономии. А для работы, которой не нужен мгновенный ответ, Batch API снижает стоимость и входных, и выходных токенов на 50%.
Прямые API языковых моделей
Прямые API языковых моделей обычно выставляют счёт за входные и выходные токены отдельно. И выходные токены часто стоят в 3–10 раз дороже входных, потому что генерация требует больше вычислений [4][8]. Этот разрыв может ударить по вашему месячному счёту сильнее, чем кажется по заголовочной цене за токен.
Вот снимок представительных цен по распространённым уровням моделей по состоянию на июнь 2026:
| Модель | Ввод (за 1M токенов) | Вывод (за 1M токенов) | Окно контекста |
|---|---|---|---|
| GPT-5.5 (Флагман) | $5.00 | $30.00 | 1M |
| Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M |
| GPT-5.4-mini | $0.75 | $4.50 | 400K |
| DeepSeek V4 Flash | $0.14 | $0.28 | 1M |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M |
Цены проверены в июне 2026 [1][4].
В проде эти ставки разыгрываются очень по-разному в зависимости от нагрузки. Ценовой разрыв между уровнями может быстро превратиться в огромный разрыв в расходах. Например, чат-бот клиентской поддержки, обрабатывающий 100 000 разговоров в месяц, стоит около $96 в месяц на Gemini 1.5 Flash против $3 200 в месяц на GPT-4o — разница в 33 раза [4]. Если вы запускаете высокообъёмный чат или суммаризацию, промпты с большим выводом могут съесть большую часть бюджета.
Затраты могут вырасти снова, когда модели сжигают токены, которых вы даже не видите. Рассуждающие модели добавляют здесь ещё один слой. О-серия OpenAI может генерировать внутренние токены рассуждений, оплачиваемые по ставке вывода, даже если видимый ответ короток. Так что ответ с видимым ответом в 200 токенов может всё равно выставить счёт за 3 000 токенов рассуждений, что толкает реальную стоимость вверх в 15 раз [10]. Решение простое в теории: задайте max_completion_tokens или thinking_budget, чтобы поставить потолок [2].
Как только расходы выглядят стабильными, следующая проблема — обычно ёмкость. На масштабе лимиты скорости, как правило, становятся первым узким местом. Повышение уровней не происходит за ночь, так что командам нужно планировать на недели вперёд перед запуском с высоким трафиком. У Anthropic Tier 1 начинается с платежа $5, тогда как Tier 4 открывает 4 000 RPM и 4M входных токенов в минуту после $400 совокупных расходов [9].
И как только трафик приходит, задержка может значить больше, чем ценник. Под нагрузкой P99-задержка быстро карабкается: при 50 одновременных соединениях Gemini 2.0 Flash выдаёт 3 800 мс P99-задержки с долей таймаутов 0.05%, GPT-4o достигает 8 400 мс, а Claude 3.7 Sonnet добирается до 16 200 мс с долей таймаутов 2.8% [11].
Прямые API генерации изображений
Прямые API генерации изображений обычно выставляют счёт за изображение, хотя некоторые провайдеры используют вместо этого вычислительное время или ценообразование на основе кредитов [12][14][16]. На практике цена в основном определяется разрешением и уровнем качества. Так что если вы делаете и миниатюры, и герой-изображения, не отправляйте их по одному пути, если только не хотите тратить больше, чем нужно.
| Модель | Провайдер | Стоимость за изображение (1024px) | Премиум-уровень |
|---|---|---|---|
| Flux.1 Schnell | fal.ai / Replicate | $0.003 | N/A |
| Imagen 4 Fast | $0.010 | N/A | |
| Flux 2 Pro | BFL / fal.ai | $0.030 | $0.060 |
| Imagen 4 Standard | $0.040 | $0.120 | |
| Stable Image Ultra | Stability AI | $0.080 | N/A |
| GPT Image 1.5 | OpenAI | $0.100 | $0.180 (HD) |
Представительные цены за стандартные 1024px; премиум-уровни показаны там, где доступны [13][15][16].
Одна вещь постоянно сбивает команды: отслеживайте стоимость на пригодное изображение, а не стоимость на промпт. Если вашему процессу нужно четыре генерации, чтобы получить одно изображение, которое можно выпустить, ваша фактическая стоимость за единицу — в 4 раза выше заявленной цены. Неудачные запросы, отказы модерации, инпейнтинг и апскейлинг — всё это добавляется к этому итогу [14].
Цена — лишь половина истории. Скорость может колебаться так же сильно. Для интерактивных приложений с изображениями отслеживайте p50, p95, TTFB и время ожидания в очереди [17]. Модель может выглядеть дешёвой на бумаге и всё равно ощущаться медленной в продукте. Flux.1 Schnell выдаёт p50-задержку в 1.2 секунды для изображений 1024×1024, тогда как DALL-E 3 HD выходит на 11.9 секунды p50 и 21.4 секунды p95 [17].
Масштаб зависит от лимитов, сидящих за API. И вот где люди часто всё путают: лимиты конкурентности и лимиты скорости — не одно и то же. Black Forest Labs применяет 24 одновременных запроса на стандартных эндпоинтах, тогда как Stability AI использует burst-лимит в 150 запросов за 10 секунд, прежде чем срабатывает 60-секундный таймаут [16]. Эта разница сильно важна, как только объём начинает расти.
Высокообъёмные конвейеры обычно нуждаются в нескольких скучных-но-важных частях:
- Асинхронный опрос
- Временное хранилище ассетов
- Обработка короткоживущих URL
Последний может укусить вас, если его игнорировать. URL от BFL, например, истекают через 10 минут, так что вам нужно переместить изображение в вашу собственную систему до того, как ссылка умрёт [16].
Для большинства прод-команд гибридный стек имеет больше всего смысла. Отправляйте миниатюры и другие высокообъёмные ассеты к быстрым уровням. Держите премиум-уровни для герой-изображений и финальных ассетов, где качество изображения важнее сырой пропускной способности.
Генерация видео следует тому же базовому паттерну, но стоимость и задержка перемещаются с вывода за изображение на рендер за секунду.
Прямые API генерации видео
Видео оказывает ещё больше давления на ценообразование и очереди. Математика проста: вы платите за секунду, а доставка обычно асинхронна. В 2026 видео-API берут от $0.01 до $0.25 за секунду, в зависимости от модели и уровня [19][20]. На нижнем конце Vidu Q3 Turbo стоит $0.03/сек. На верхнем конце Seedance 2.0 Pro достигает $0.247/сек. Это разница примерно в 8 раз за ту же длину клипа [20].
И заявленная ставка — лишь отправная точка. 1080p — нормальная прод-база. Поднимитесь до уровней 4K или Cinematic, и стоимость за секунду может удвоиться или даже учетвериться. Повторы тоже быстро складываются, что означает, что фактические расходы часто оказываются в 1.5–2 раза выше заявленной цены, а в процессах с обменом туда-сюда могут достигать 3 раз [20][22].
Однако цена — лишь часть истории. Время рендера и доля успеха формируют юнит-экономику не меньше. 10-секундный 1080p-клип может занять от 60 до 180 секунд на Seedance 2.0 и от 120 до 600 секунд на Sora [22]. Вот почему прод-системы должны отправить задачу, вернуть ID задачи и завершить доставку через вебхуки или опрос [22]. Если вы попытаетесь относиться к видео как к обычному синхронному вызову API, всё быстро станет беспорядочным.
Sora 2 в среднем имеет долю успеха от 85% до 90% на стандартных промптах, так что повторы и отклонённые выводы нужно делать частью модели затрат с первого дня [25]. Для видео отслеживайте больше, чем цену за секунду. Вам также нужно следить за:
- Глубиной очереди
- Конкурентностью
- Долей успеха
Эти числа могут укусить. При 10 одновременных запросах всплески очереди могут перевалить за 7 секунд, и большинство аккаунтов ограничивают конкурентность 3–10 активными генерациями [22][23][24][26]. Это делает инструменты вроде Redis или BullMQ практичной настройкой перед запуском, а не каким-то приятным дополнением [22].
Процесс черновик/финал обычно имеет больше всего смысла. Команды могут использовать более быстрые модели вроде Wan 2.6 или Seedance 2.0 Fast для тестирования промптов, затем переключаться на премиум-модели для финального рендера [18][20]. Это держит итерации дешёвыми и бережёт дорогие запуски для версии, которую вы выпустите.
Несколько фич моделей также могут урезать побочные затраты. Модели с нативной генерацией аудио, вроде Veo 3.1 и Kling 3.0, могут убрать $0.50–$2.00 за видео в отдельных расходах на аудио или лицензирование [20]. Нативный вывод 9:16, доступный на Kling 2.6 и Seedance 2.0, также избегает перекодирования для коротких социальных клипов [21].
Эта настройка особенно хорошо работает для маркетинговых команд. Они могут тестировать рекламные варианты по низкой цене, затем рендерить только победившую концепцию в премиум-качестве. Как только текст, изображения и видео все должны работать вместе в одном конвейере, унифицированный доступ начинает выглядеть гораздо полезнее.
Унифицированные платформы AI API
Унифицированные платформы AI API позволяют командам отправлять запросы по тексту, изображениям и видео через один API-ключ. Это сокращает работу по интеграции, когда продукту нужно поддерживать более одной модальности. APIMart, например, ставит модели текста, изображений и видео за единым ключом. Эта настройка важна больше всего, когда одному продукту нужно жонглировать дешёвыми повседневными вызовами и более дорогими выводами с высокими ставками.
Ценообразование, как правило, работает лучше с уровневой маршрутизацией моделей. Простыми словами, отправляйте простые задачи к моделям подешевле и берегите топовые модели для более сложной рассуждающей работы. Этот подход может сильно сократить расходы, особенно потому что компании, проталкивающие каждый запрос к одной премиум-модели, могут переплачивать на 60–80% [27]. Кэширование промптов тоже помогает. Оно может сократить входные затраты на 50–90%, когда вы переиспользуете системные промпты или RAG-документы [5]. И когда вы оцениваете стоимость, не останавливайтесь на заголовочной цене за токен. Вам также нужно учитывать токены рассуждений, оплачиваемые по ставкам вывода и способные сильно поднять общие расходы [5].
Для интерактивных функций две метрики быстро становятся важными: время до первого токена и частота повторов. Более низкая частота повторов может означать более низкую стоимость на полезный вывод, даже когда цена за токен поначалу выглядит выше [28][29][4]. Для чувствительных к задержке сценариев вроде чата в реальном времени, стриминга и интерактивных ассистентов пропускная способность тоже важна. Специализированное железо может выдавать примерно 750 токенов в секунду, по сравнению с примерно 100–150 токенами в секунду на стандартных H100-эндпоинтах [29]. Как только использование начинает расти, одна маршрутизация проблему не решит. Лимиты скорости, отказоустойчивость и резервная ёмкость начинают значить не меньше.
Масштабируемость — там, где унифицированные платформы начинают оправдывать себя. Автоматическая маршрутизация с отказоустойчивостью сокращает перебои сервиса на 65% [27]. По мере роста трафика командам стоит следить за запасом по лимитам скорости в реальном времени и предварительно троттлить на стороне клиента примерно на 80% ёмкости. Проталкивайте дальше этой точки — и P95-задержка может подскочить в 2–5 раз [30][31]. На большем объёме ключевой вопрос — не просто доступ к модели. Это то, сколько контроля платформа даёт вам над маршрутизацией, лимитами и отказоустойчивостью.
Корпоративные пакеты AI API
Когда маршрутизации и пакетной обработки перестаёт хватать, в дело вступают корпоративные пакеты с зарезервированной ёмкостью, средствами контроля комплаенса и поддержкой, подкреплённой контрактом. Унифицированные платформы помогают с маршрутизацией. Корпоративные пакеты занимаются управлением, закупками и гарантированной ёмкостью.
Модель ценообразования тоже меняется. Вместо чистого биллинга на основе использования корпоративные пакеты AI API часто переводят команды на зарезервированную ёмкость и кастомные контракты. Это даёт организациям более предсказуемую пропускную способность, что важно для регулируемых нагрузок или приложений, которые не могут позволить себе всплески задержки. Крупные компании часто договариваются о зарезервированной пропускной способности через опции вроде Azure Provisioned Throughput Units или AWS Bedrock Provisioned Capacity. Компромисс прост: меньше гибкости, но более стабильные расходы. Фиксированные почасовые или месячные ставки покупают зарезервированную ёмкость [33][28][34].
Есть дополнительные начисления, за которыми нужно следить. Гарантии резидентности данных, вроде инференса только в США, могут добавить множитель 1.1x к базовой стоимости токена [32][1]. Длинноконтекстные промпты могут снова поднять затраты. Некоторые провайдеры берут двойную цену, как только промпты выходят за 200 000 токенов [32][1].
Сервисные обязательства варьируются по контракту. Публичные SLA обычно сидят между 99.5% и 99.9% аптайма, тогда как некоторые приложения к MSA доходят до 99.99% [35][36]. Цели по P95- или P99-задержке обычно не стандартны из коробки. Командам обычно приходится договариваться о них по модели и региону.
Условия поддержки тоже различаются:
- Уровень Premium Support от Google обязуется отвечать за 15 минут на проблемы Severity 1
- OpenAI Enterprise целится в 1 час
- Anthropic Enterprise допускает до 4 часов в рабочее время [35][36]
В регулируемых настройках стек контроля обычно включает VPC service controls, изоляцию VNET, Private Link, CMEK-шифрование и контракты нулевого хранения данных (ZDR). ZDR от Anthropic доступен через AWS Bedrock и Google Vertex AI, тогда как Azure OpenAI требует специфического Enterprise Agreement [37][38][39].
Контроль затрат важен не меньше, чем контроль доступа. На корпоративном масштабе ограничение на основе токенов часто самый сильный рычаг. Один RAG-запрос на 100 000 токенов может стоить столько же, сколько 1 000 коротких чат-запросов [40]. Это тот разрыв, который может быстро взорвать бюджет. Распространённый способ управлять этим — зарезервировать оценочный бюджет токенов перед запросом, а затем сверить фактический итог после завершения.
Плюсы и минусы по типу API
Вот простой способ увидеть, как APIMart сравнивается по стоимости, скорости и повседневному управлению на разных стадиях роста. Таблица ниже даёт вам быстрый параллельный обзор.
| Стадия масштаба | Плюсы | Минусы | Влияние на бюджет | Влияние на скорость | Операционное влияние |
|---|---|---|---|---|---|
| Ранняя / Низкий объём | Более низкая стоимость за единицу на масштабе; единый биллинг | Ограничено доступными пакетами; зависимость от третьей стороны | Оплата по факту без минимумов | Нейтрально; зависит от инфраструктуры провайдера | Низкое; единый API-ключ и биллинговое отношение |
| Рост / Средний объём | Уровневая маршрутизация моделей сокращает расходы; кэширование промптов снижает входные затраты | Объёмные скидки требуют порогов использования | Значительная экономия через маршрутизацию и кэширование | Небольшая задержка маршрутизации; минимальна в большинстве нагрузок | Низкое; отказоустойчивость и маршрутизация обрабатываются платформой |
| Высокий объём / Прод | Асинхронная пакетная обработка сокращает стоимость токенов на 50%; краевая доставка снижает глобальную задержку | Пакетные задачи добавляют задержку доставки против синхронных вызовов | Самая низкая стоимость за единицу через Batch API и объёмное ценообразование | Стабильная пропускная способность; асинхронные задачи избегают узких мест лимитов скорости | Низкое; панель, лимиты и оповещения централизуют контроль затрат |
Используйте эти компромиссы, чтобы сузить ваши варианты, прежде чем сопоставлять API с вашим сценарием.
Как выбрать правильный AI API для вашего сценария
Используйте сравнения выше, чтобы выбрать самую дешёвую модель, всё ещё попадающую в ваши цели по качеству и задержке. Самый простой способ это сделать — начать с вашего главного ограничения.
Если бюджет — самый большой фактор, начните с самой дешёвой модели, преодолевающей вашу минимальную планку качества. Затем поднимайтесь выше только если она бьёт мимо. Если скорость важнее всего, склоняйтесь к моделям, созданным для быстрых ответов, и тестируйте p50- и p95-задержку на ваших фактических шаблонах промптов перед запуском. Эта часть важнее, чем многие команды ожидают. Кросс-региональные вызовы могут добавить сотни миллисекунд [3][42].
Если качество вывода не может проседать, фронтир-модели обычно имеют больше всего смысла. Но между уровнями моделей есть большой ценовой скачок [1].
Прежде чем что-либо фиксировать, запустите пилот с 30–50 реальными промптами из вашего фактического сценария, а не общими бенчмарк-промптами [42]. Это даёт вам гораздо более ясное понимание того, что вы покупаете. Измеряйте:
- Качество
- Стоимость
- Сырую задержку
Так вы можете увидеть, какой уровень модели вашей нагрузке действительно нужен.
После пилота переходите к нагрузочному тестированию и бюджетному контролю. Нагружайте на реалистичных уровнях конкурентности, задайте жёсткие дневные лимиты расходов на уровне провайдера и добавьте оповещения об аномалиях затрат на каждую функцию [44][43]. Этот шаг легко пропустить, когда всё ещё выглядит мелким. Это также там, где затраты могут подкрасться к вам.
Прод-использование токенов часто вырастает в 5–15 раз от прототипа к запуску, по мере удлинения промптов и накопления крайних случаев [41]. Встройте этот буфер в вашу модель затрат с первого дня.
Также логируйте каждый запрос в APIMart — версию модели, количество токенов, имя функции и задержку — чтобы маршрутизация, стоимость и задержка оставались видимыми по мере роста трафика [42][43].
Частые вопросы
Как оценить мою реальную стоимость AI API?
Смотрите дальше базовой ставки за токен и оценивайте полный жизненный цикл запроса. Начните с этой формулы:
Monthly cost = (requests_per_day × 30) × ((input_tokens × input_price) + (output_tokens × output_price)) ÷ 1,000,000
Отсюда учтите дополнительные драйверы затрат, проявляющиеся на практике.
Выходные токены часто стоят в 3–10 раз дороже входных, так что длинные ответы могут быстро изменить расчёты. Многораундовые чаты тоже толкают затраты вверх, потому что каждое новое сообщение добавляет больше токенов к текущему контексту. Вдобавок повторы обычно добавляют 5–15%, особенно когда запросы падают или таймаутятся.
Если вы используете агентные процессы или вызов инструментов, скачок может быть гораздо больше. Такие настройки могут добавить в 1.5–10 раз, потому что одно действие пользователя может запустить несколько вызовов модели вместо всего одного.
Есть один рычаг, способный урезать расходы: кэширование промптов. Если ваша настройка его поддерживает, стоимость кэшированных входных токенов может упасть на 50–90%. Это может сильно ударить, когда одни и те же системные промпты или повторяющийся контекст появляются во многих запросах.
Какие метрики важнее всего перед запуском?
Перед запуском сфокусируйтесь на метриках, балансирующих стабильность и прогноз затрат:
- p50- и p95-задержка
- доля успеха задач, включая повторы и отказоустойчивость
- эффективное ценообразование на основе представительных форм промптов, количества входных/выходных токенов и прогнозируемого месячного объёма
- пропускная способность и конкурентность против опубликованных лимитов скорости
Тестируйте в окружении, похожем на прод, чтобы избежать сюрпризов после запуска.
Когда использовать пакетную обработку или асинхронные задачи?
Используйте пакетную обработку или асинхронные задачи, когда вам не нужен мгновенный ответ. Этот компромисс может сократить затраты до 50%, что делает такой подход хорошо подходящим для несрочной работы.
Хорошие примеры включают:
- Крупномасштабную суммаризацию документов
- Анализ видео
- Ночную обработку данных
Эти задачи имеют смысл, когда ожидание до 24 часов нормально.
С другой стороны, не используйте их для пользовательских функций, зависящих от быстрой обратной связи. Сюда входят чат, автодополнение и рекомендации в реальном времени. Если человек сидит и ждёт, асинхронные задачи — обычно неправильный инструмент.
Есть и дополнительная сантехника. Вам понадобится логика для постановки в очередь, опроса и сверки результатов после завершения задачи.