
Единый AI API: лучшие практики проектирования
Руководство разработчика по проектированию единого AI API — слои абстракции, стандартные схемы, изоляция провайдеров, наблюдаемость, версионирование и безопасность.
Единые AI API упрощают работу с несколькими AI-моделями, предоставляя единый интерфейс для доступа к различным провайдерам, таким как GPT-5, Claude, а также моделям генерации изображений и видео. Такой подход исключает необходимость в отдельных SDK, процессах аутентификации и пользовательской интеграции для каждого провайдера. Цель? Снизить сложность, повысить эффективность и упростить переключение между моделями или их комбинирование по мере развития технологий.
Ключевые тезисы:
- Единый слой абстракции: Стандартизирует взаимодействие с различными AI-провайдерами, обеспечивая работу приложения только с одним интерфейсом.
- Стандартизированные схемы: Используйте согласованные форматы запросов и ответов для упрощения интеграции нескольких моделей.
- Изоляция провайдеров: Избегайте встраивания логики конкретного провайдера в основной код, используя адаптеры.
- Наблюдаемость: Отслеживайте задержку, использование токенов и частоту ошибок для мониторинга производительности.
- Версионирование: Поддерживайте стабильность, обеспечивая обратную совместимость и закрепляя модели за определёнными версиями.
- Безопасность: Централизуйте аутентификацию, проверяйте входные и выходные данные, внедряйте ограничение частоты запросов.
Например, платформы вроде APIMart предлагают единый API для доступа к 500+ моделям с такими функциями, как централизованное выставление счетов и автоматическое переключение при сбое. Это делает управление AI-интеграциями проще и надёжнее.
Единые API vs. автоматизация рабочих процессов: что выбрать разработчикам?
Определение единого слоя абстракции
Единый слой абстракции служит мостом между вашим приложением и используемыми AI-провайдерами. Вместо адаптации к уникальному интерфейсу каждого провайдера ваше приложение взаимодействует с единым стандартизированным интерфейсом, который транслирует запросы и ответы. Как объясняет AI Roads:
«Основная ценность единого слоя API заключается в том, чтобы собрать различия нескольких провайдеров в ограниченной границе, чтобы верхний уровень работал со стабильным контрактом.» [2]
Такой подход упрощает бизнес-логику. Когда провайдер обновляет схему или появляется новая модель, вам нужно лишь скорректировать слой абстракции, не трогая остальной код.
Начните с наименьшего полезного интерфейса
Не пытайтесь с самого начала включить все возможные функции. Сосредоточьтесь на том, что есть у большинства провайдеров. Для запросов это могут быть параметры model, messages, temperature и max_tokens. Для ответов стандартизируйте такие поля, как answer, usage и finish_reason [2][3].
Начните с определения структуры запроса, затем нормализуйте ответы. Добавляйте обработку ошибок и логирование по мере необходимости, оставив сложную маршрутизацию на потом. Чрезмерное усложнение интерфейса на раннем этапе может привести к хрупкой архитектуре при добавлении новых провайдеров.
Обработка nullable-свойств и отсутствующих полей
Разные модели поддерживают разные параметры. Например, GPT-5 использует параметр temperature, тогда как модель генерации видео Sora — нет. Для управления этим используйте объект метаданных о возможностях для каждой модели. Отслеживайте такие свойства, как has_temperature, supports_json_schema и supported_modalities [3]. Это гарантирует, что слой абстракции проверяет эти флаги перед отправкой неподдерживаемых параметров провайдеру.
Для обработки ответов делайте специфичные для провайдера поля nullable по умолчанию. Если поле вроде finish_reason не возвращается конкретной моделью, слой абстракции должен корректно обработать это, предоставив значение по умолчанию или null. Чётко документируйте, какие поля обязательны, а какие опциональны, чтобы избежать путаницы.
Такая настройка упрощает управление параметрами и подготавливает систему к бесшовной интеграции с несколькими моделями.
Пример: мультимодельная интеграция с APIMart
APIMart демонстрирует, как эта абстракция работает на практике. Через единый API разработчики получают доступ к более чем 500 моделям — от языковых моделей GPT-5 и Claude до моделей генерации видео, таких как Sora 2 Preview ($0.08/сек) и Kling V3 ($0.0672/сек при 720P). Интерфейс совместим с API OpenAI, то есть разработчики могут использовать одну и ту же интеграцию для генерации текстовых сценариев одной моделью и создания видео другой — без необходимости жонглировать несколькими SDK, системами аутентификации или парсерами ответов.
Такой единый подход упрощает разработку, предлагая единый надёжный интерфейс для доступа к широкому спектру AI-возможностей.
Стандартизация схем запросов и ответов
Для бесшовной интеграции нескольких моделей необходимо создать согласованную, независимую от провайдера схему запросов и ответов. Такой подход исключает необходимость в условных операторах для конкретных провайдеров, сохраняет бизнес-логику чистой и позволяет слою единой абстракции эффективно выполнять свою работу.
Как объясняет Charlie Holland: «JSON Schema становится „языком ассемблера" определений схем, а языки высокого уровня компилируются в него» [5]. Иными словами, создание единого контракта схемы гарантирует, что все провайдеры придерживаются одной структуры независимо от их нативных форматов.
Нормализация мультимодальных входных данных
Для единообразия используйте унифицированное поле type для всех типов входных данных. Вот как это работает:
- Текст: Представляется как
{"type": "text", "text": "..."}. - Изображения: Используйте
image_urlи необязательный параметрdetail, который можно установить в"low","high"или"auto". - Видео: Обрабатываются через
task_idи URL webhook-коллбэка для асинхронной обработки [7].
Параметр detail особенно полезен для оптимизации использования токенов. Например, выбор "low" снижает потребление токенов, когда детальное изображение не нужно.
После нормализации входных данных следующий шаг — стандартизировать ошибки и метаданные для обеспечения единообразия во всех взаимодействиях.
Стандартизация форматов ошибок и метаданных ответа
Ошибки должны следовать четырёхпольной структуре для поддержания согласованности:
code: Стабильный версионированный идентификатор.category: Машиночитаемая категория (например,auth_required,rate_limit,validation,transientилиpermanent).message: Читаемое человеком объяснение.details: Чёткие инструкции по повторным попыткам и полевое руководство [8].
Как выразилась редакционная команда Spec Coding:
«Решение — не более красивый текст. Решение — конверт ошибки, который рассматривает машину как основного читателя, а человека — как вторичного» [8].
Кроме того, каждый ответ должен включать trace_id для отслеживания и стандартизированные поля использования — prompt_tokens, completion_tokens и total_tokens — для мониторинга затрат у разных провайдеров [9][2]. Заголовки вроде X-RateLimit-Remaining и X-RateLimit-Reset должны присутствовать во всех ответах — не только в ошибках 429 — чтобы клиенты могли проактивно управлять темпом запросов [10].
Таблица сравнения схем
Ниже приведена разбивка ключевых стандартизированных полей по уровням:
| Уровень | Стандартизированные поля | Назначение |
|---|---|---|
| Запрос | model, provider, messages, parameters | Единый формат входных данных для SDK провайдеров [2][3] |
| Ответ | answer/content, usage, model_id | Обеспечивает согласованную структуру для бизнес-логики [2] |
| Использование | prompt_tokens, completion_tokens, total_tokens | Централизует отслеживание затрат и квот [2][6] |
| Ошибка | code, category, message, details | Обеспечивает единообразную обработку ошибок и автоматические запасные варианты [8] |
| Логирование | trace_id, latency_ms, cost, timestamp | Поддерживает наблюдаемость и отслеживание бюджета [2][3] |
Строгий режим для валидации схем
При валидации схем рассмотрите использование строгого режима в продакшене. В отличие от стандартного режима JSON, который лишь проверяет возможность разбора JSON, строгий режим требует, чтобы выходные данные точно соответствовали схеме [4]. Хотя он гарантирует структурное соответствие, помните, что бизнес-правила он не проверяет. Такая повышенная точность помогает обеспечить согласованность и надёжность системы.
Изоляция логики конкретного провайдера
После стандартизации схем следующей задачей является избегание встраивания логики конкретного провайдера непосредственно в основной код. Например, обилие вызовов вроде openai.chat.completions.create() по всему коду превращается в кошмар, когда нужно добавить запасные модели или сменить провайдера. Как объясняет Tian Pan, инженер-основатель:
«Инженерные затраты на смену провайдеров или обновление версий моделей во многом определяются решениями, принятыми при интеграции.» [11]
Умным способом решить эту проблему является использование паттерна адаптера провайдера. По сути, вы создаёте тонкий адаптер для каждого провайдера, обеспечивая его соответствие стабильному внутреннему интерфейсу. Если провайдер обновляет схему или обработку ошибок, вам нужно лишь подправить конкретный адаптер, а не всю кодовую базу. Этот паттерн аккуратно разделяет унифицированные операции и специфические особенности провайдера, делая систему более гибкой и простой в обслуживании.
Централизация аутентификации и работы с токенами
Аутентификация быстро превращается в хаос, если её логика разбросана по коду. У разных провайдеров часто разные форматы ключей, циклы обновления токенов и соглашения о заголовках. Централизуя эти задачи в выделенном слое аутентификации, вы сохраняете код чище и упрощаете аудит. Хороший слой аутентификации должен обрабатывать:
- Управление одним ключом на уровне приложения: Используйте один API-ключ на уровне приложения, оставив обработку ключей провайдеров и OAuth-токенов слою абстракции [11].
- Управляемые удостоверения для бэкенд-сервисов: Избегайте жёсткого кодирования или ручной ротации ключей конкретного провайдера [12].
- Ограничение частоты запросов и автоматы защиты: Внедряйте ограничения частоты локально и используйте конечный автомат для приостановки запросов к сбоящему провайдеру после повторных ошибок или скачков задержки [11].
- Распространение метаданных: Передавайте идентификаторы запросов, центры затрат и информацию о пользователях для согласованного логирования и отслеживания [11].
Отличным примером такого подхода является Uniper — европейская энергетическая компания, обновившая управление API в феврале 2026 года. Используя Azure API Management, Ian Beeson (руководитель API Centre of Excellence) и Hinesh Pankhania (руководитель облачной инженерии) сократили число определений API на 85% — с семи на среду до одного универсального определения. Они также достигли доступности 99,99% за счёт автоматического переключения при сбое и автоматов защиты [12].
Централизуя аутентификацию, вы упрощаете общие задачи, оставляя провайдерно-специфические операции соответствующим адаптерам.
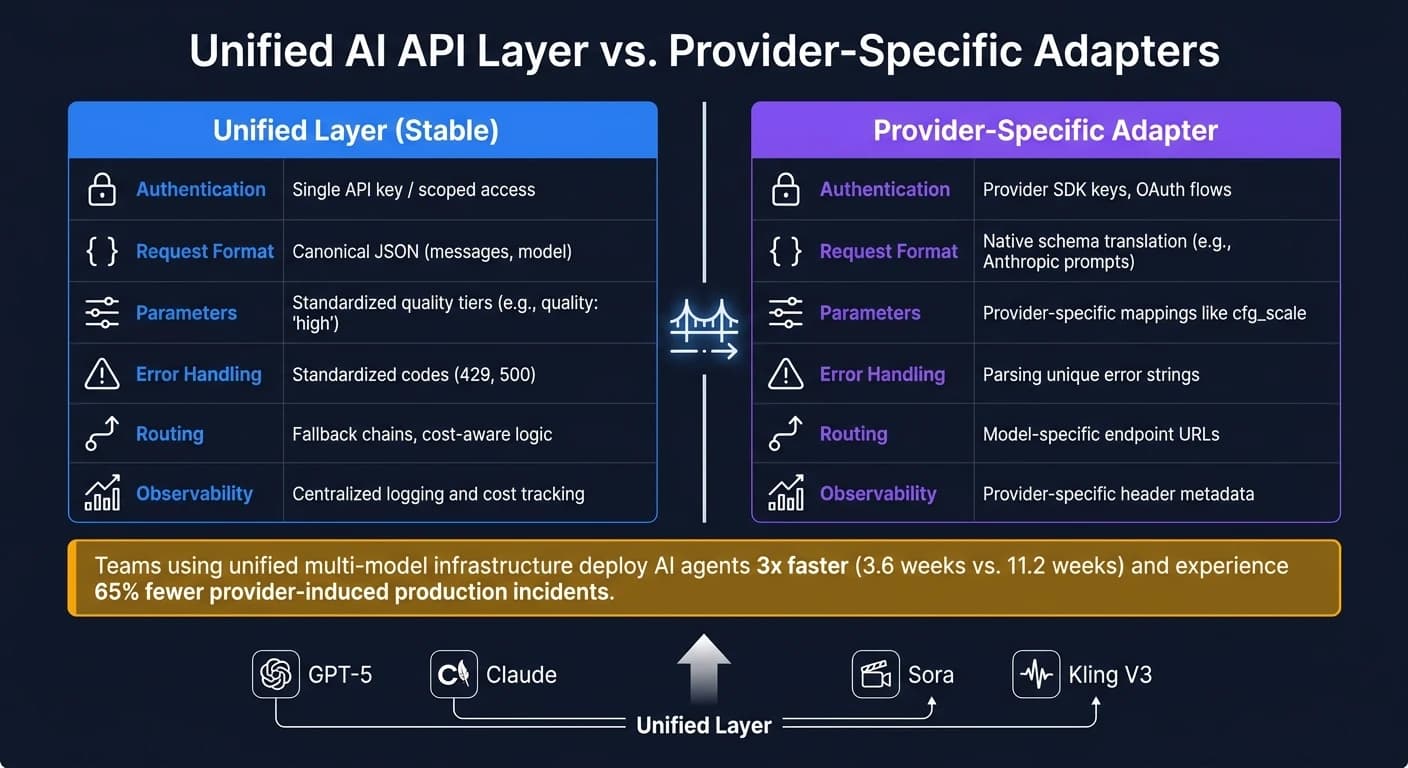
Единое vs. провайдерно-специфическое поведение
Соблюдать правильный баланс между тем, что должно входить в единый слой, и тем, что принадлежит адаптерам конкретного провайдера, — это ключевой момент. Вот разбивка:
| Функциональность | Единый слой (стабильный) | Адаптер конкретного провайдера |
|---|---|---|
| Аутентификация | Единый API-ключ / ограниченный доступ [12] | Ключи SDK провайдера, OAuth-потоки [12] |
| Формат запроса | Канонический JSON (messages, model) [2] | Трансляция нативной схемы (например, промпты Anthropic) [2] |
| Параметры | Стандартизированные уровни качества (например, quality: "high") [13] | Провайдерно-специфические маппинги вроде cfg_scale [13] |
| Обработка ошибок | Стандартизированные коды (429, 500) [2] | Разбор уникальных строк ошибок [2] |
| Маршрутизация | Цепочки запасных вариантов, логика с учётом стоимости [11] | URL конечных точек для конкретных моделей [11] |
| Наблюдаемость | Централизованное логирование и отслеживание затрат [11] | Метаданные заголовков конкретного провайдера [11] |
Одной полезной стратегией является псевдонимизация моделей — использование общих идентификаторов вроде fast-cheap или reasoning-heavy вместо жёстко закодированных конкретных, таких как gpt-4o или claude-opus-4. Слой абстракции затем сопоставляет эти псевдонимы с наиболее подходящей моделью провайдера, значительно упрощая будущие обновления [11].
Когда остановить унификацию
Хотя построение единой абстракции полезно, у неё есть пределы. Например, промпты, оптимизированные для одной модели (вроде Claude Mythos), могут плохо работать с другой (вроде GPT-5.5). Единый слой должен поддерживать согласованный интерфейс, при этом допуская провайдерно-специфические шаблоны промптов при необходимости [2].
Аналогично, чрезмерная абстракция может создать собственный набор проблем. Если провайдер предлагает уникальную функцию — например, проприетарный формат вызова инструментов или бета-функциональность, не поддерживаемую другими, — лучше реализовать сквозную конечную точку. Это позволяет сырым запросам идти непосредственно к провайдеру, минуя универсальную схему. Цель — найти баланс между стабильным интерфейсом для бизнес-логики и доступом к ценным провайдерно-специфическим функциям [14].
«Важно не то, какой инструмент вы выбираете: важно то, что слой существует до того, как он вам понадобится, а не после.» — Tian Pan, инженер-основатель [11]
Проектирование с учётом надёжности и наблюдаемости
Создав слой абстракции, следующим шагом является подготовка его к продакшену. В отличие от стандартных веб-API, единый AI API вводит уникальные режимы сбоев, которые без надлежащего мониторинга легко не заметить. Для этого необходимы надёжное логирование и мониторинг.
Настройка логирования и мониторинга
Традиционных проверок доступности недостаточно для AI API. Помимо стандартных HTTP-метрик необходимо отслеживать время до первого токена (TTFT), токены в секунду (TPS) и запас ограничения частоты (TPM/RPM) [15][18]. Для каждого запроса логируйте структурированные данные JSON, включающие полный промпт, ответ, задержку, количество токенов и уникальный идентификатор запроса [16][17].
Уделяйте пристальное внимание метрикам задержки на уровнях p50, p95 и p99. Скачок p95-задержки нередко сигнализирует о проблемах выше по цепочке до того, как они перерастут в полный сбой [15][18]. Установите оповещения при достижении 70% использования ограничения частоты, чтобы успеть отреагировать до того, как неожиданные всплески трафика превысят лимит [15][18].
| Сигнал | Что измерять | Пример порога оповещения |
|---|---|---|
| Задержка | p95/p99 TTFT и общее время | p99 > 5 с в течение 5 минут |
| Трафик | Запросов в секунду (RPS) | RPS упал более чем на 50% от среднего за час |
| Ошибки | Доля ошибок 5xx и 429 | Доля 5xx > 1% в течение 2 минут |
| Насыщенность | Использование TPM/RPM | Запас ограничения частоты < 20% |
«Команды, отвечающие на этот вопрос за 30 секунд, — те, у кого мониторинг уже настроен. Те, кто тратит 20 минут, — те, кто читает этот гайд впервые в разгар инцидента.» — API Status Check [15]
Планирование сбоев и постепенной деградации
Настроив логирование в реальном времени, переходите к подготовке к неизбежным сбоям.
LLM API обычно обеспечивают доступность 99,7%, что соответствует примерно 22 часам простоя в год [19]. Например, в декабре 2025 года крупные AI-провайдеры сообщили о 47 инцидентах всего за один месяц [21]. Ваша система должна корректно обрабатывать эти сбои, а не падать целиком.
Разные типы ошибок требуют разных подходов. Временные ошибки вроде 429 (ограничение частоты) и 500/503 (ошибки сервера) должны инициировать повторные попытки с экспоненциальным откатом и случайным джиттером. Джиттер предотвращает перегрузку восстанавливающейся системы синхронизированными повторными попытками [19][21]. Постоянные ошибки вроде 400, 401 и 404 должны немедленно завершаться неудачей — повторные попытки не устранят проблемы вроде некорректных запросов или недействительных API-ключей [19].
Чтобы минимизировать каскадные сбои, внедрите автомат защиты, приостанавливающий запросы после повторных сбоев (например, 30-секундный период охлаждения) и возобновляющий работу пробным запросом [20][22]. Сочетайте это с цепочкой запасных вариантов «Основной → Вторичный → Аварийный», чтобы приложение оставалось работоспособным даже при полном сбое провайдера. Исследования показывают, что использование автоматов защиты и цепочек запасных вариантов сокращает клиентские AI-ошибки на 91% [19]. В крайнем случае отдайте кешированный ответ по умолчанию или полностью переключитесь на вариант без AI [18].
Валидация входных данных, выходных данных и фоновых задач
Обеспечение целостности данных критически важно для поддержания надёжности и предотвращения дорогостоящих ошибок.
Валидация входных данных нередко остаётся без внимания до тех пор, пока не вызывает серьёзных проблем. Один стартап получил счёт на $47 000 в месяц из-за того, что забыл установить параметр max_tokens на конечной точке [19]. Всегда явно определяйте max_tokens и оценивайте количество токенов во время запроса, чтобы предотвратить переполнение контекста до отправки провайдеру [19][23].
Для выходных данных используйте инструменты вроде Pydantic или валидацию JSON-схем для обеспечения структурированных ответов — это переносит ответственность с промпта на код, где ею проще управлять [24]. Параллельно с основным LLM-вызовом запускайте проверки на токсичность и персональные данные [24]. Для поддержания качества периодически оценивайте более дешёвые производственные модели с помощью высокоинтеллектуальной модели, такой как OpenAI o3. Это помогает обнаружить незаметную деградацию качества, которая не видна в метриках [17].
«Разработка промптов — это, по сути, работа с вероятностями... В производственной среде "в основном правильно" равнозначно "сломано".» — Nino, старший технический редактор, n1n.ai [24]
Проектирование с учётом версионирования и изменений схем
При разработке единого AI API версионирование играет ключевую роль в поддержании стабильности по мере эволюции моделей. Это выходит за рамки стандартных практик надёжности и наблюдаемости — оно обеспечивает согласованность как структуры, так и поведения с течением времени.
Единый AI API содержит два существенных контракта: структурный контракт (определяемый JSON-схемой) и поведенческий контракт (то, как модель фактически отвечает). Большинство стратегий версионирования фокусируются на структурной стороне, однако игнорирование поведенческого аспекта может приводить к незаметным сбоям. Работая с обоими аспектами, вы создаёте стабильный слой абстракции, обеспечивающий надёжность для пользователей.
Обратная совместимость изменений
Чтобы не нарушить существующие интеграции, применяйте подход «расширение вместо изменений». Это означает добавление необязательных полей или новых конечных точек вместо изменения или удаления существующих. Поощряйте клиентов действовать как «снисходительные читатели» — то есть корректно обрабатывать неизвестные поля в ответах. Такой подход минимизирует сбои при обновлениях [27][28].
Одной из распространённых ловушек является псевдонимизация моделей. Исследование Стэнфорда и UC Berkeley 2023 года показало, что точность GPT-4 на задаче определения простых чисел упала с 84% до 51% всего за три месяца из-за изменений за общим псевдонимом [26]. Решение? Фиксация снапшотов. Используйте явные идентификаторы моделей с датой, вроде gpt-4o-2024-08-06, вместо плавающих псевдонимов. Такой подход закрепляет поведение и предотвращает незаметные изменения [25][26].
«Псевдонимы моделей — не стабильные контракты... неявные контракты ломаются незаметно.» — Tian Pan, инженер-основатель [26]
Помимо структуры, критически важно отслеживать поведенческие конверты — статистические границы таких метрик, как точность, длина ответа и частота отказов. Если обновление модели изменяет эти распределения, расценивайте это как критическое изменение, даже если схема осталась прежней [25].
Обеспечив обратную совместимость, следующим шагом является эффективное информирование об обновлениях и устаревании. Больше технических материалов можно найти в APIMart Blog.
Информирование об устаревании и новых функциях
Чёткая и своевременная коммуникация необходима, чтобы клиенты могли адаптироваться к изменениям. Отраслевые стандарты рекомендуют период устаревания до 12 месяцев с минимальным уведомлением за 90 дней до прекращения поддержки функций [30][31].
Используйте HTTP-заголовок Sunset (RFC 8594) и заголовок Link для предоставления документации по миграции [27][30]. Добавление поля model_deprecated_at в ответы API позволяет клиентам автоматически логировать и оповещать о предстоящих изменениях [25]. Для команд, которые могут пропустить эти уведомления, рассмотрите внедрение «браунаутов» — коротких периодов троттлинга устаревших конечных точек — чтобы привлечь внимание к проблеме [27].
«Заголовок машиночитаем; клиенты могут настроить на него оповещения. Используйте его.» — Madhuban Mukherjee, блог Cadence [31]
К 2026 году рекомендуется предоставить конечную точку /api/changelog.json. Она должна включать такие детали, как уровни серьёзности, затронутые поля и ссылки на миграцию. Поскольку AI-агенты всё активнее потребляют API напрямую, полагаться исключительно на email-уведомления уже недостаточно [28][32].
Критические vs. некритические изменения: сравнение
| Тип изменения | Критическое? | Действие |
|---|---|---|
| Новое необязательное поле | Нет | Развёртывайте свободно; обновите документацию [33] |
| Новая конечная точка | Нет | Развёртывайте свободно [33] |
| Улучшение производительности / задержки | Нет | Следите за поведенческим дрейфом [30] |
| Переименование или удаление поля | Да | Повышение версии + уведомление об устаревании [29][33] |
| Новое обязательное поле | Да | Повышение версии + руководство по миграции [33] |
| Изменение типа (например, строка → целое число) | Да | Необходимо повышение версии [33] |
| Изменение тона или логики модели | Да | Фиксация снапшотов + теневое тестирование [25] |
Поведенческие изменения, такие как смена тона или логики рассуждений, требуют тщательного управления. Фиксация снапшотов и теневое тестирование необходимы, чтобы не нарушить пользовательский опыт. Как объясняет Tian Pan: «Ключевое понимание состоит в том, что конечная точка AI имеет два отдельных контракта: структурный и поведенческий» [25]. Незаметное изменение — например, смена тона модели с профессионального на непринуждённый — может нарушить ожидания пользователей так же сильно, как переименование поля, но выявить это значительно сложнее.
Обеспечение безопасности единого API
Защита единого API критически важна для обеспечения безопасности мультимодельных интеграций. При росте трафика API на 300% с 2022 по 2025 год и более чем 80% бизнесов, полагающихся на API для оказания услуг, ставки как никогда высоки [34]. Единый AI API особенно уязвим, поскольку одна скомпрометированная конечная точка может открыть доступ ко многим моделям и потокам данных.
Настройка аутентификации и ограниченного доступа
Для публичных клиентов, таких как SPA и мобильные приложения, базовым стандартом 2026 года является OAuth 2.1 с PKCE, заменяющий устаревшие и небезопасные потоки — Implicit и Resource Owner Password Credentials. Для межсервисного взаимодействия предпочтительнее mTLS или SPIFFE-удостоверения рабочих нагрузок, а не статические API-ключи, которые легко утечь. Для усиления безопасности токенов используйте PASETO вместо JWT — он устраняет уязвимости вроде атак «alg: none» [35].
«Аутентификация подтверждает личность (кто вы), а авторизация определяет разрешения (что вы можете делать). Аутентификация предшествует авторизации.» — API7.ai [34]
Внедряйте принцип наименьших привилегий, чтобы каждый клиент имел доступ только к тому, что ему необходимо. Используйте токены доступа с TTL от 5 до 15 минут и обновляйте их по мере необходимости [34][35]. Ротируйте ключи подписи ежеквартально и автоматизируйте этот процесс, чтобы минимизировать человеческий фактор [35]. Для панелей администратора обязательно применяйте многофакторную аутентификацию (MFA) для защиты учётных данных [36].
Создав надёжную систему аутентификации, следующим шагом является фокус на валидации входных и выходных данных API.
Валидация всех входных и выходных данных
Используйте валидацию на основе схем с помощью инструментов вроде OpenAPI 3.1 или JSON Schema, чтобы тщательно проверять все входные данные. Для AI-специфических уязвимостей внедрите защиту от инъекций промптов — фильтрацию ключевых слов, регулярные выражения и семантический анализ — для блокировки попыток обхода защиты до того, как они достигнут моделей [36][39]. Всегда применяйте валидацию на стороне сервера для сохранения контроля.
На стороне выходных данных используйте объекты передачи данных (DTO) или сериализаторы, чтобы ответы содержали только те поля, которые должны быть открыты, снижая риск утечки внутренних ID, трассировок стека или метаданных базы данных [38][39]. Добавьте DLP-сканирование на уровне шлюза для обнаружения и блокировки утечки конфиденциальных данных, включая персональные, медицинские данные и данные платёжных карт [36]. При обработке ответов об ошибках возвращайте обобщённые сообщения, соответствующие RFC 7807, логируя подробную диагностику безопасным образом во внутренних системах.
«Правило нулевого доверия: относитесь к каждому вызывающему API как к потенциальному злоумышленнику, пока не доказано обратное. Проверяйте всё, логируйте всё и исходите из того, что ваша защита будет проверена.» — AquilaX [40]
Валидация потоков данных — лишь часть уравнения. Регулярный пересмотр политик безопасности обеспечивает сохранение эффективности защиты.
Регулярный пересмотр политик безопасности
Как мониторинг помогает поддерживать работоспособность системы, так и регулярные проверки безопасности необходимы для сохранения целостности API. Без постоянного обслуживания меры безопасности со временем могут деградировать. Проводите ежеквартальные проверки средств контроля доступа, включая области действия токенов и расписания ротации секретов. Выполняйте аудит сервисных аккаунтов, чтобы предотвратить расширение привилегий [37].
Шлюз API должен выступать центральной точкой применения политик — обрабатывать валидацию токенов, оценку политик и логировать каждое решение о предоставлении доступа. Он также должен автоматически отзывать токены доступа при необходимости [37]. По мере того как AI-агенты всё чаще выполняют задачи автономно, принятие принципа нулевого постоянного доверия — когда учётные данные выдаются для конкретных задач, ограничены по времени и ориентированы на цель — становится практической необходимостью [37].
Заключение: ключевые выводы по проектированию единого AI API
Это завершает рассмотрение основных идей проектирования единого AI API, обсуждённых в статье.
Решение создать единый AI API — это умный шаг для команд, стремящихся повысить скорость, надёжность и удобство обслуживания. Команды, использующие единую мультимодельную инфраструктуру, разворачивают продакшн AI-агентов в три раза быстрее (3,6 недели против 11,2 недели) и сталкиваются с на 65% меньшим числом производственных инцидентов, вызванных провайдерами [1].
Ключевые практики, описанные здесь, работают вместе, создавая надёжную основу. Абстракция упрощает сложные провайдерно-специфические детали до единого удобного интерфейса. Стандартизированные схемы обеспечивают согласованность форматов запросов и ответов для разных моделей. Изоляция провайдеров защищает систему от сбоев, вызванных проблемами у одного поставщика. Наблюдаемость — детальное логирование токенов, времени запроса и ID модели — даёт необходимую видимость для отладки и оптимизации производительности. Версионирование защищает производственную среду от неожиданных изменений при обновлении моделей. Наконец, надёжные меры безопасности — централизованная аутентификация и регулярные проверки политик — поддерживают безопасность API по мере его масштабирования. Эти принципы в совокупности создают основу хорошо спроектированного единого AI API.
«Паттерн единого AI-шлюза коренным образом изменил то, как мы масштабируем и управляем AI в масштабах предприятия... этот подход позволяет нам принимать новые модели и возможности с той скоростью, которую требует экосистема AI, — не жертвуя производительностью, доступностью или управляемостью.» — Hinesh Pankhania, руководитель облачной инженерии и CCoE, Uniper [12]
Реализация Uniper в феврале 2026 года — отличный пример. Они достигли доступности 99,99% и снизили накладные расходы на управление API, объединив определения [12].
Для команд, желающих избежать трудоёмкой работы по созданию собственного слоя абстракции, APIMart — основательный вариант. Он предлагает единый API, совместимый с OpenAI, с поддержкой 500+ моделей, включая GPT-5, Claude, Sora и Kling V3. Такие функции, как централизованное выставление счетов, мультимодальная поддержка и конкурентоспособные цены, делают его удобной отправной точкой для единого доступа к AI-моделям.
Часто задаваемые вопросы
Как решить, что включить в первую версию единого AI API?
Для начала сосредоточьтесь на создании чёткой границы, отделяющей логику конкретного провайдера от основного бизнес-кода. Это означает стандартизацию нескольких критически важных элементов: структур запросов, форматов ответов, обработки ошибок и логирования. Так вы эффективно защитите приложение от особенностей разных моделей.
Дополнительно включите метаданные: использование токенов, ID модели и длительность запроса. Эти данные бесценны для отслеживания производительности и устранения неполадок. Принятие версионирования и подхода «проектирование в первую очередь» также сделает будущие обновления значительно более гладкими, устраняя необходимость в масштабном переписывании кода.
Как API должен обрабатывать возможности моделей, которые есть не у всех?
Для работы с различиями в возможностях моделей разумно использовать единый слой API. Это централизует различия между провайдерами, исключая их из основной бизнес-логики. Такие инструменты, как APIMart, упрощают этот процесс, предлагая функции для изучения возможностей моделей, лимитов токенов и параметров конфигурации. Изолируя эти различия в слое адаптации, вы поддерживаете единый интерфейс, управляя провайдерно-специфическими особенностями — поддержкой инструментов или обработкой ошибок — без написания пользовательского кода.
Как безопаснее всего управлять изменениями версий моделей, не ломая приложения?
При создании приложений, зависящих от AI-моделей, самый безопасный вариант — использовать слой абстракции модели. Такой подход отделяет логику приложения от конкретных API разных провайдеров. Инструменты вроде APIMart упрощают задачу, позволяя переключать модели простым обновлением конфигурации без изменений в коде.
Для обеспечения стабильности помните о ключевых практиках:
- Фиксируйте конкретные снапшоты моделей: Используйте версии вроде
gpt-4o-2024-08-06, чтобы избежать неожиданных изменений. - Обязательно применяйте схемы выходных данных: Это обеспечивает согласованное форматирование и предотвращает «дрейф формата».
- Внедряйте теневое тестирование и канареечные развёртывания: Эти методы позволяют безопасно наблюдать за изменениями перед их полным внедрением.
Следуя этим шагам, вы сможете сохранить стабильность и адаптируемость приложения по мере эволюции моделей.
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.