
AI API Cost Comparison: Pay-As-You-Go Models
Compare 2026 pay-as-you-go AI API pricing across APIMart, OpenAI, Google Cloud, and Amazon Bedrock — token rates, volume discounts, and cost-saving strategies.
Looking for the best AI API pricing in 2026? Here’s what you need to know.
Pay-as-you-go (PAYG) models charge based on token usage, making them flexible for businesses of all sizes. With token prices dropping 80% over the past two years, providers like APIMart, OpenAI, Google Cloud AI, and Amazon AI Services offer competitive options. However, costs vary significantly - up to 625× for similar tasks.
Key takeaways:
- APIMart: Access 500+ models with 20% savings over official pricing. Best for diverse needs and unified billing.
- OpenAI: Advanced tools and features like prompt caching, but premium models can be expensive.
- Google Cloud AI: Offers the largest context window (up to 2 million tokens) and multimodal capabilities.
- Amazon AI Services: Low entry costs and deep AWS integration, but Bedrock’s unified API adds a slight markup.
Quick Tip: Use lower-cost models for high-volume tasks and reserve premium models for critical use cases. Strategies like batch processing and prompt caching can cut costs by 50–90%.
Here’s a detailed breakdown of each provider’s pricing, features, and discounts.
AI Model API Pricing Compared: Claude, Kimi, GPT-4o and More
1. APIMart
APIMart simplifies access to over 500 AI models using just one API key, one invoice, and a single dashboard.
Cost per unit
APIMart follows a pay-as-you-go pricing model with no monthly minimums or hidden fees. The sample rates below show a consistent 20% savings compared to official pricing [7]:
| Model | APIMart Price | Official Price | Savings |
|---|---|---|---|
| Wan 2.7 Image | $0.0216/call | $0.027/call | 20% |
| GPT Image 2 | $0.006/call | $0.0075/call | 20% |
| Imagen 4.0 | $0.04/call | $0.05/call | 20% |
| Qwen Image 2.0 | $0.02/1K tokens | $0.025/1K tokens | 20% |
| Z Image Turbo | $0.01/call | $0.0125/call | 20% |
In addition to cost savings, APIMart provides a wide selection of models across different AI capabilities.
Model variety and modalities
APIMart's catalog includes models for chat, image generation, video generation, and editing, all accessible from a single endpoint. For video, options like Sora 2 ($0.08/sec), Veo 3, and Kling V3 (priced at $0.0672/sec for 720p) are available. On the image and language side, models include Flux.1, Imagen 4.0, GPT-5, and Claude Sonnet 4.5. This variety allows you to pick the best model for each task, enabling workflows that span text, images, and videos without the hassle of managing multiple vendors.
Volume discounts and scalability
As usage grows, volume discounts are automatically applied. APIMart also offers "Discount Bundles", which reward teams that use multiple model types under one account. For example, combining GPT-5 for reasoning tasks with Flux.1 for image generation can unlock better discount tiers. A unified dashboard tracks real-time usage and quotas across all model families, making it easier to manage and forecast expenses at scale [7].
These cost advantages are paired with simple integration and strong support services.
Integration and support features
Setting up APIMart is quick and straightforward - it takes just 3 minutes. Generate your API key, update the base URL, and you're ready to go [7]. For those already using OpenAI SDKs, only a one-line code change is required. The platform is fully compatible with OpenAI, supports Python and JavaScript SDKs, and handles streaming, function calling, vision, and multi-modal inputs. Switching between models, such as GPT-5 and Claude Sonnet 4.5, is seamless and requires no code adjustments [8].
Support is handled by human engineers via chat, and the platform has earned a 4.6/5 rating from 320 reviews. Users often praise its single-key integration and low latency as standout features [9].
2. OpenAI API
OpenAI uses a token-based, pay-as-you-go pricing model, where costs are calculated per 1 million (1M) tokens processed. Pricing varies significantly depending on the model. For instance, GPT‑5 nano starts at just $0.05 per 1M input tokens, while GPT‑5.5 Pro can cost up to $30.00 per 1M input tokens - a staggering 600× difference[11]. Below is a detailed breakdown of costs by model.
Cost per Unit
The cost depends heavily on the model tier you choose. Here's a closer look at the pricing:
| Model | Input (per 1M tokens) | Cached Input | Output (per 1M tokens) |
|---|---|---|---|
| GPT‑5.5 Pro (Reasoning) | $30.00 | – | $180.00 |
| GPT‑5.5 (Standard Edition) | $5.00 | $0.50 | $30.00 |
| GPT‑5.4 | $2.50 | $0.25 | $15.00 |
| GPT‑5.4 mini | $0.75 | $0.075 | $4.50 |
| GPT‑5.4 nano | $0.20 | $0.02 | $1.25 |
| GPT‑5 nano | $0.05 | $0.005 | $0.40 |
Non-text workloads are billed separately. For example, Sora‑2 video processing costs $0.10 per second for 720p resolution or $0.70 per second for 1080p. The Realtime API for audio is priced at $32.00 per 1M input tokens and $64.00 per 1M output tokens[10].
Model Variety and Modalities
OpenAI supports a wide range of tasks, including text, vision, audio, video, web search, and code execution. The Realtime API offers live speech-to-speech and translation services, with translation priced at $0.034 per minute and transcription at $0.017 per minute. Web search is billed at $10.00 per 1,000 calls, while hosted code execution ("Containers") costs between $0.03 and $1.92 per 20-minute session depending on memory usage[10].
Volume Discounts and Scalability
To help users manage costs, OpenAI offers several cost-saving options:
- Batch API: Reduces both input and output costs by 50% for tasks that can be processed asynchronously within 24 hours - ideal for batch operations.
- Flex Tier: Provides a 50% discount for real-time requests that can tolerate slower response times.
- Priority Processing: Costs 150% more than the standard rate but ensures faster and more consistent throughput. For example, GPT‑5.5's priority rate is $12.50 per 1M input tokens compared to the standard $5.00 rate.
"Priority processing generates tokens faster and at a more consistent speed than the Standard processing service, even during peak demand." - OpenAI [14]
Automatic prompt caching can further reduce input costs by up to 90%, making it a great option for repetitive or long-context tasks[14].
Integration and Support Features
OpenAI offers a robust suite of tools for seamless integration. These include a standard SDK, an Agents SDK, and a CLI, all of which support WebRTC, WebSocket, and SIP connections for real-time applications[12]. Developers can adjust processing speed by setting the service_tier parameter to "priority", "auto", or "default" in the Chat Completions API[15].
To help teams monitor and manage costs, the Usage Dashboard provides detailed spending insights by service tier or line item. For users with specific data residency needs, OpenAI also offers regional processing endpoints, though these come with a 10% price increase[13].
3. Google Cloud AI APIs
Google Cloud's AI pricing uses a pay-as-you-go, per-token approach similar to OpenAI, but its model lineup and cost structure are distinct. Google categorizes its Gemini models into two tiers: "Flash", which prioritizes speed and cost-efficiency, and "Pro", designed for more complex reasoning. This setup helps developers align model capabilities with budget constraints.
Cost per Unit
Pricing varies significantly across models. For instance, Gemini 3 4B is the most affordable at $0.04 per 1M input tokens, while Gemini 3.1 Pro costs $2.00 per 1M input tokens for prompts under 200,000 tokens, increasing to $4.00 for larger prompts [17]. Output tokens generally cost 4 to 10 times more than input tokens [17].
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| Gemini 3.1 Pro (Preview) | $2.00 | $12.00 | 1M–2M tokens |
| Gemini 2.5 Pro | $1.25 | $10.00 | 2M tokens |
| Gemini 3 Flash (Preview) | $0.50 | $3.00 | 1M tokens |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | 1M tokens |
| Gemini 2.5 Flash-Lite / 2.0 Flash | $0.10 | $0.40 | 1M tokens |
| Gemini 3 4B | $0.04 | $0.08 | 131K tokens |
For image and video generation, Imagen 4.0 costs between $0.02 and $0.06 per image, depending on quality, while Veo 3.1 video generation costs $0.40 per second for standard processing or $0.15 per second for preview mode [16].
Model Variety and Modalities
Google's models handle a broad range of tasks, covering text, images, video, audio, and code. This eliminates the need for external tools like transcription services [20]. A standout feature is the 2-million-token context window available on Gemini 2.5 Pro and Gemini 3.1 Pro models, offering unmatched capacity in the industry [16][3]. However, audio inputs are priced higher than text. For instance, Gemini 3.1 Flash-Lite charges $0.25 per 1M tokens for text but $0.50 per 1M tokens for audio [17]. Additionally, newer reasoning models use "thinking tokens", which increase costs for complex outputs [17][19].
Volume Discounts and Scalability
Google Cloud offers several cost-saving options for businesses. The Batch API cuts input and output costs by 50% for tasks processed asynchronously within 24 hours [17][19]. For example, Gemini 3.1 Pro's input cost drops from $2.00 to $1.00 per 1M tokens in batch mode. Another feature, context caching, stores frequently used prompts or documents at $1.00 per 1M tokens per hour, reducing costs for repetitive tasks like RAG pipelines or extended chat sessions [17]. Developers can further optimize costs by implementing smart routing across different providers.
Additionally, Google operates a spend-based throughput system: organizations spending over $2,000 in 30 days unlock higher rate limits automatically [18]. For large-scale operations, the Enterprise tier offers guaranteed capacity and custom pricing [17].
Integration and Support Features
Google Cloud's tools are built for seamless integration and scalability. Its APIs work natively with Google Workspace, Drive, and mobile platforms through Vertex AI [20][19]. A notable feature is Grounding with Google Search, which enhances model responses with real-time data. This feature is free for the first 5,000 prompts per month on Gemini 3 models, with additional usage billed at $14 per 1,000 queries [17].
Other built-in tools include Function Calling, Streaming, and Code Execution. However, privacy policies vary by tier. In the free tier (Google AI Studio), data submitted may be used for product development. Paid and Enterprise tiers, on the other hand, ensure that data is not used for such purposes - a key consideration for teams handling sensitive information [17][3].
4. Amazon AI Services
Amazon's AI offerings are divided between two main platforms: Amazon Bedrock, which provides access to foundation models through a managed API, and Amazon SageMaker, designed for creating and deploying custom models. Both platforms use a pay-as-you-go pricing model, though their structures vary according to their Terms of Service. Like many competitors, Amazon offers flexible, usage-based pricing with tiered options designed to meet different business requirements.
Cost per Unit
Amazon Bedrock pricing is organized into four tiers: Standard (on-demand), Flex (lower cost with slower response times), Priority (faster but more expensive), and Batch (asynchronous processing). Here's a breakdown of costs for the Amazon Nova 2 Lite model:
| Tier | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Standard | $0.30 | $2.50 |
| Priority | $0.525 | $4.375 |
| Flex | $0.15 | $1.25 |
| Batch | $0.15 | $1.25 |
The Nova model family offers a wide range of pricing options. For instance, Nova Micro starts at $0.035 per 1M input tokens, whereas Nova Premier costs $2.50 per 1M input tokens. Third-party models are priced higher; for example, Claude 4.7 Opus is $5.00 per 1M input tokens and $25.00 per 1M output tokens [22].
Model Variety and Modalities
Amazon Nova models support multiple content types, including images, video, speech, and embeddings. Here’s what you can expect:
- Nova Canvas: Image generation costs $0.04–$0.06 per image.
- Nova Reel: Video generation is priced at $0.08 per second (720p/24fps).
- Nova Sonic: Speech processing ranges from $3.00–$3.40 per 1M input tokens [22].
Additionally, web grounding for Nova models is available at a flat rate of $30.00 per 1,000 requests [22].
Volume Discounts and Scalability
Amazon offers substantial cost-saving options for businesses with predictable or large-scale requirements:
- Batch inference reduces costs by 50% compared to standard on-demand pricing [22].
- Machine Learning Savings Plans offer up to 64% savings for SageMaker users who commit to 1- or 3-year plans [23].
- Managed Spot Training can lower compute costs by as much as 90% by utilizing unused AWS capacity [23].
As AWS explains:
"With a pay as you go model, you can adapt your business depending on need and not on forecasts, reducing the risk of overprovisioning or missing capacity." [21]
Integration and Support Features
Amazon Bedrock simplifies access to foundation models from providers like Anthropic, Meta, Cohere, AI21 Labs, DeepSeek, and Amazon's Nova family. Its unified API allows seamless switching or combining of capabilities without requiring major changes to existing integrations [24][25]. Bedrock integrates natively with Amazon S3, AWS Lambda, and SageMaker, and includes features such as Amazon Bedrock Guardrails for safety and Amazon Augmented AI (A2I) for workflows involving human review [26].
For added reliability, AWS automatically routes inference requests to the most suitable region, ensuring data never travels over the public internet [25].
Pros and Cons by Provider
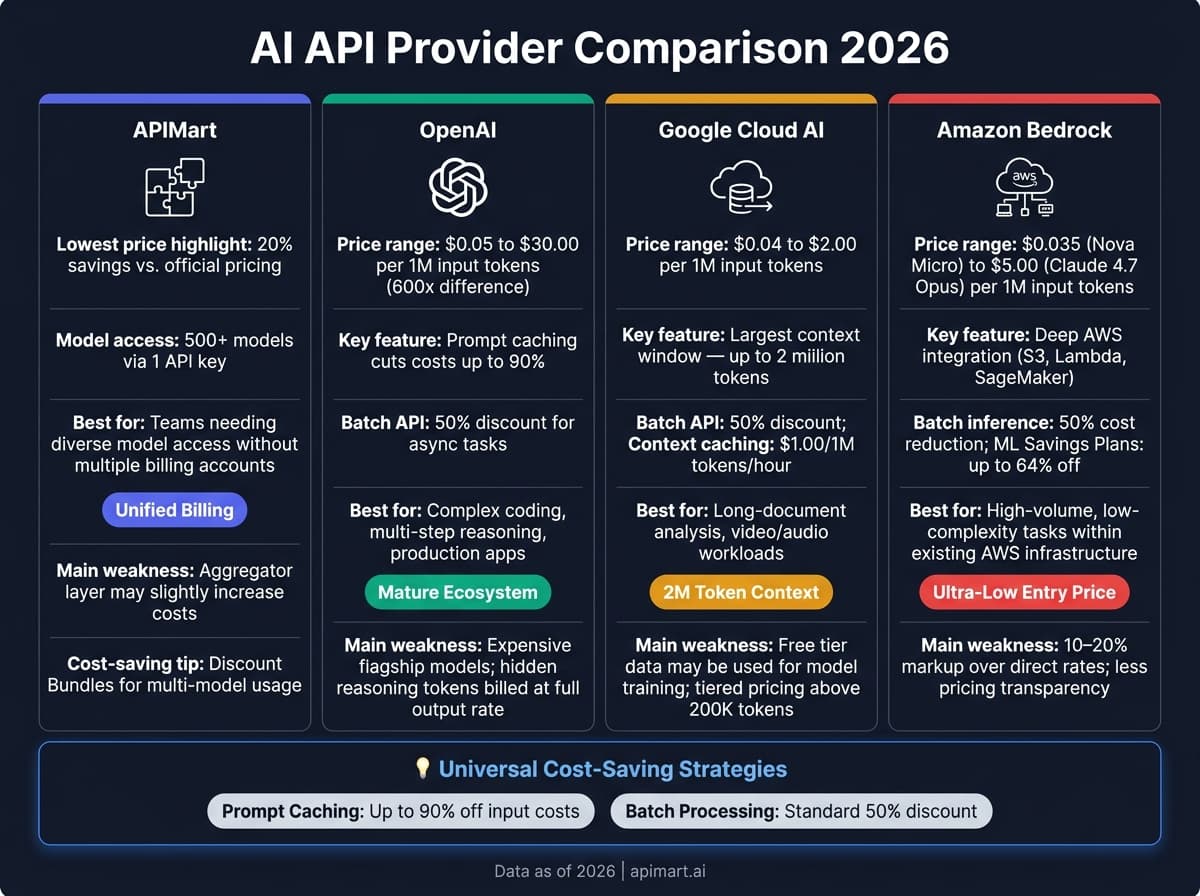
Each provider tailors its pricing and features to meet different workload sizes and technical demands. Here's a quick look at the strengths and weaknesses of the major players.
APIMart simplifies API management by offering access to over 500 models through a single, unified API. This eliminates the hassle of managing multiple billing accounts. However, the aggregator layer can slightly increase costs compared to direct relationships with individual model providers. For large-scale projects, this streamlined approach to cost management can be a big plus.
OpenAI stands out with a mature developer ecosystem and a robust prompt caching system, which can cut costs for cached inputs by up to 50%. That said, its premium models are pricey, and reasoning models (like the o-series) come with a hidden cost: reasoning tokens are billed at full output rates, even though they don’t show up in the final output [1][5].
"A small change in prompt design, model selection, or context length can swing a monthly bill by 10x." - Lyne Carolyne, CloudZero [5]
Google Cloud AI offers the largest context window - up to 2 million tokens - and strong multimodal capabilities. Its free tier is appealing, but it comes with a potential tradeoff: submitted data may be used for model training, which could be a concern for privacy-sensitive users [3]. Additionally, models like Gemini 3.1 Pro use tiered pricing, doubling the input rate once prompts exceed 200,000 tokens [5].
Amazon AI Services (Bedrock) is an excellent fit for teams already using AWS. The Nova Micro model provides one of the lowest entry points at $0.035 per 1M input tokens, and batch inference can cut costs by 50% for non-urgent workloads [2]. However, using Amazon Bedrock’s unified API typically adds a 10–20% markup over direct API pricing from the underlying model providers [5].
Here’s a quick comparison of their main tradeoffs:
| Provider | Main Strength | Main Weakness | Best Fit |
|---|---|---|---|
| APIMart | Access to 500+ models via one API, multi-modal support | Aggregator layer may slightly increase costs | Teams needing diverse model access without juggling multiple billing accounts |
| OpenAI | Mature ecosystem, prompt caching, Batch API | Expensive flagship/reasoning models; hidden thinking tokens | Complex coding, multi-step reasoning, production apps |
| Google Cloud AI | Largest context window (2M tokens), multimodal | Free tier may use submitted data for model training; tiered pricing above 200K tokens | Long-document analysis, video/audio workloads |
| Amazon Bedrock | Deep AWS integration, ultra-low entry pricing | 10–20% markup over direct rates; less pricing transparency | High-volume, low-complexity tasks within existing AWS infrastructure |
These tradeoffs highlight how each provider aligns with specific technical needs and budgets. For applications that generate a lot of output, factors like output tokens costing 3× to 10× more than input tokens make strategies like batch processing and prompt caching particularly cost-effective [4][6].
Conclusion
Picking the right AI API provider boils down to matching your specific needs with the most suitable tool. While AI API prices have dropped by about 10x over the past two years (as of early 2026) [2], the cost difference between the cheapest and most expensive options for the same task can still be as much as 625x [4]. This makes choosing the right provider a crucial decision for any development team in the U.S.
A practical approach is to use budget-friendly models for high-volume, low-complexity tasks like classification and data extraction. Save the more expensive flagship models for tasks that are absolutely mission-critical. By adopting this kind of smart model routing, teams can reduce costs by 60–80% [28] without sacrificing quality. Beyond cost savings, this strategy also simplifies operations by reducing the hassle of managing multiple API accounts, especially when using consolidated platforms.
Operational efficiency is another key factor. Managing multiple providers can create significant overhead. Platforms like APIMart tackle this by offering access to over 500 models through a single API and billing system. This tradeoff prioritizes speed and simplicity over squeezing every possible cent from direct provider relationships.
"The consolidation value isn't just cost - it's the engineering hours that don't get spent on infrastructure instead of product." - Louis Amira, Co-founder, ATXP [28]
Finally, there are two cost-saving strategies every team should implement, no matter which provider they choose: prompt caching and batch processing. Prompt caching can cut input costs by up to 90% for repeated context [27], while batch processing offers a standard 50% discount for tasks that don't require immediate results [2]. These methods not only save money but also reduce the complexity of managing workflows - making them essential for any team.
FAQs
How can I estimate tokens for my workload before deploying?
Tokens are essentially small text fragments, roughly equivalent to 0.75 words each. They’re used to measure both the input prompts you provide and the output responses you receive. To get a clear picture of your token usage, start by using token counter tools. These tools can analyze sample prompts and responses, giving you a better idea of how many tokens your content will require.
Once you’ve gathered this data, estimate the number of tokens needed for both input and output based on your specific workload. Afterward, calculate your costs by applying the provider’s pricing for tokens (usually charged per million tokens). This step is key to understanding your expenses and planning your budget before moving forward with deployment.
What’s the best way to cut PAYG costs without hurting quality?
Cutting down on pay-as-you-go (PAYG) AI API costs doesn’t mean you have to compromise on performance. Here’s how you can manage costs effectively:
- Batch Your Requests: Instead of sending multiple small requests, combine them into larger batches. This reduces the number of API calls and saves money.
- Simplify Prompts: Avoid unnecessary or overly complex prompts. Clear and concise instructions can lower token usage without affecting the quality of results.
- Choose the Right Model: Use smaller, more cost-efficient models for simpler or non-critical tasks. Save the advanced (and pricier) models for when they’re absolutely necessary.
- Track Token Usage: Keep a close eye on how many tokens you’re using. Adjust your approach or switch models if you notice inefficiencies.
For workloads that vary or have low volume, focus on token efficiency and batching requests. On the other hand, if your needs are high-volume and consistent, a subscription plan might be a better fit, offering predictable costs and potentially lower rates.
When does a unified AI API like APIMart make more financial sense?
A unified AI API like APIMart can save your organization money, especially if you rely on multiple models from different vendors. By bringing everything together on one platform, it streamlines management and helps cut down on expenses.
For tasks that vary widely - think multimedia projects or language processing - APIMart offers tools like multi-modal inputs, advanced editing capabilities, and simplified billing. These features help manage costs effectively, even when your usage patterns are unpredictable or constantly changing.
Related Blog Posts
Choose the model you want in the model marketplace
Try chat, image and video models in the APIMart model marketplace, and experience model capabilities quickly with one unified API.