
How to Integrate Multiple AI Models with One API
Wire GPT Claude Gemini behind one unified OpenAI-style API with single-key auth failover multimodal routing Python samples and APIMart production essentials.
Want to simplify your AI integrations? Unified APIs let you connect multiple AI models - like GPT, Claude, and Gemini - through a single interface. Instead of juggling different SDKs, credentials, and protocols, you can manage everything with one endpoint. This approach saves time, reduces costs, and ensures your app stays online even during provider outages.
Here’s what you’ll gain with unified APIs:
- One API for All Models: Access text, image, and video models without rewriting code for each provider.
- Cost Savings: Route tasks to cheaper models for simpler jobs and premium models for complex tasks, cutting expenses by up to 60%.
- Automatic Failover: Ensure uninterrupted service by switching to backup models during outages.
- Centralized Billing: Get one invoice and a single dashboard for tracking costs and performance.
- Quick Setup: With OpenAI-compatible platforms like APIMart, you can integrate in minutes.
Unified APIs make it easier to manage multi-model workflows, optimize spending, and keep your app reliable. Ready to learn how? Let’s dive deeper into the details.
Lightning Model API Hub video tutorial
Related walkthrough highlights
Watch the Lightning Model API Hub tutorial above for UI-level navigation of model discovery, switching providers and multimodal workloads from a single dashboard.
What Are Unified APIs for Multi-Model Integration?
A unified AI API acts as a single access point that connects multiple AI providers under one interface [7]. Instead of creating separate integrations for providers like OpenAI, Anthropic, or Google, you send requests to a single gateway. This gateway handles everything: routing requests, formatting them for each provider, and delivering standardized responses.
Think of it as a translator for different AI protocols. You send a request in a common format - often modeled after OpenAI's chat/completions structure - and the unified API adapts it for the provider you're using, like Anthropic's Messages API or Google's Gemini protocol.
This setup turns the choice of AI provider into a simple configuration tweak rather than a major development decision [7]. For example, switching from an OpenAI model to Claude 3.5 can be as easy as changing a single string in your settings. This eliminates the need for complex SDK updates or reconfiguring authentication. A great example of this in action is Thomson Reuters’ "CoCounsel", an AI assistant for legal professionals. Built in early 2026, the development team used a unified API to complete the project in just two months, avoiding the hassle of writing provider-specific code [7].
Core Features of Unified APIs
Unified APIs come packed with features that make integration more efficient:
- Multi-Modal Compatibility: These APIs support various functionalities - text generation, image analysis, video synthesis, and even speech processing - all through one integration [7]. No need to learn separate SDKs for each task.
- Model Discovery: You can programmatically explore available models and their capabilities, like token limits or temperature settings, allowing for dynamic model selection based on your needs [6].
- Automated Failover: If a provider experiences downtime or hits rate limits, the API automatically switches to another model, ensuring uninterrupted service.
- Consolidated Billing and Analytics: Instead of managing multiple invoices, you get a single dashboard to track costs by feature, agent, or task type. This makes it easier to spot inefficiencies and manage spending.
Why Use a Unified API?
These features translate into real-world benefits that make unified APIs a game-changer:
Simplified Credential Management: You only need to manage one API key, eliminating the hassle of juggling multiple authentication systems for different providers.
Faster Implementation: Transitioning to a unified API is quick. If you're already using something like the OpenAI SDK, you can switch in minutes by updating the base URL and API key. This speed is especially critical now that 37% of enterprises use five or more AI models, and enterprise LLM spending jumped from $3.5 billion to $8.4 billion in just two quarters of 2025 [7].
Cost Optimization: Unified APIs let you route tasks to the most cost-effective models. For example, simple tasks can be sent to lower-cost options like MiniMax Hailuo 2.3, which costs $0.025 per second, while reserving premium models for more demanding tasks. Consolidated pricing and volume discounts further simplify cost management.
"A unified AI API fixes this. One endpoint, one SDK, one bill. Your application talks to a single interface, and the API routes requests to whatever provider you need."
Reliability Through Redundancy: Unified APIs ensure your app stays online even if a provider goes down. The system automatically switches to alternative providers without requiring you to rewrite code. This flexibility also helps you adapt to changes in pricing or performance seamlessly.
How to Integrate Multiple AI Models: Step-by-Step
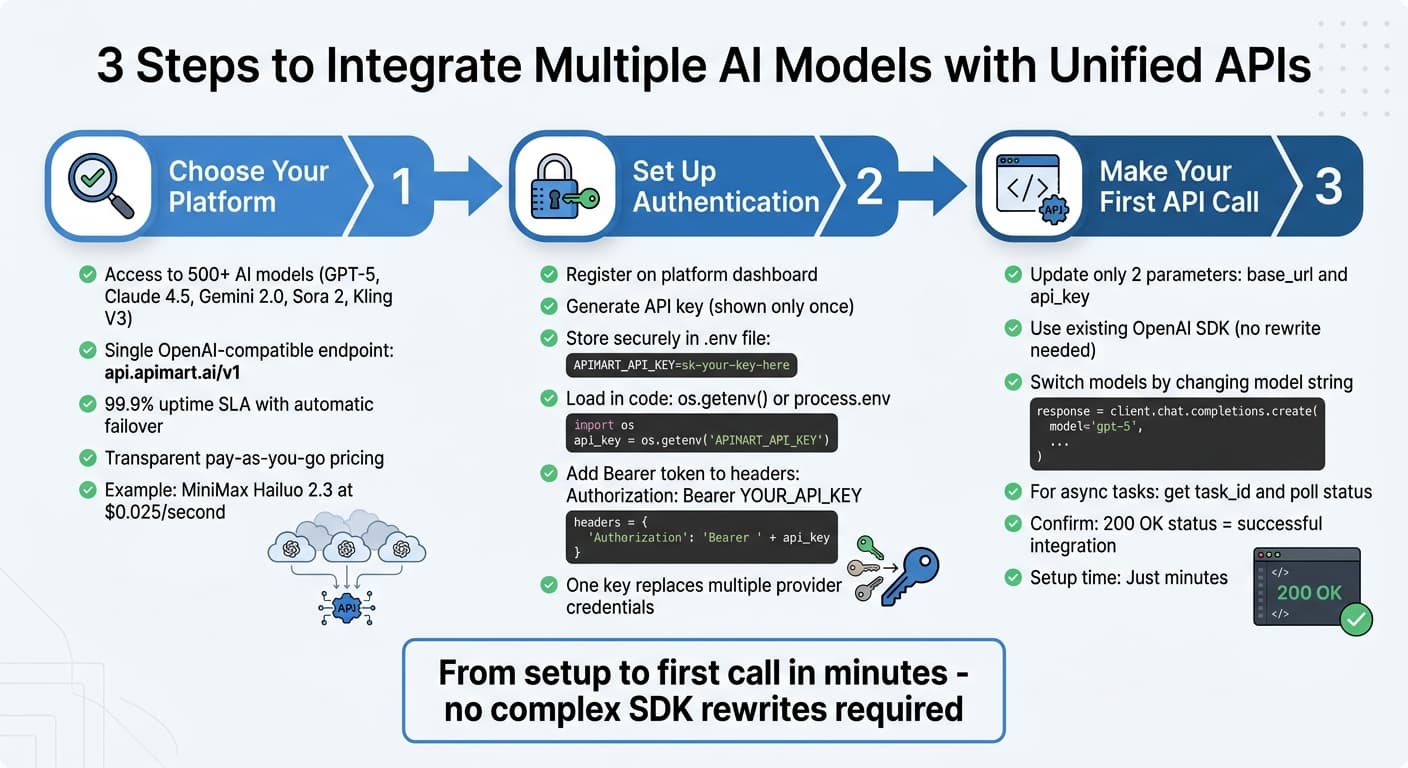
Integrating multiple AI models through a unified API involves three key steps: securing access, configuring your environment, and sending a request. Platforms like APIMart simplify this process, allowing seamless connections between text, image, and video models.
Choosing the Right Platform
When selecting a platform, look for one that offers a variety of models, straightforward pricing, and multi-modal capabilities. For example, APIMart provides access to over 500 AI models, including GPT-5, Claude 4.5, Gemini 2.0, and video generation models like Sora 2 and Kling V3. All of this is accessible through a single OpenAI-compatible endpoint: https://api.apimart.ai/v1 [10]. This compatibility means you can continue using your existing SDKs without needing to rewrite code.
Consider uptime and infrastructure as well. APIMart ensures a 99.9% uptime SLA, automatic failover, and global CDN acceleration for low-latency performance no matter where you are [10]. Pricing is transparent and pay-as-you-go, with clear per-token rates. For example, you can assign simpler tasks to cost-effective models like MiniMax Hailuo 2.3 at $0.025 per second, while reserving high-end models for more demanding tasks [10].
Once you’ve chosen the right platform, the next step is to set up authentication and security.
Setting Up Authentication and Security
Start by registering on the platform's dashboard, generating your API key, and storing it securely in an environment variable (e.g., in a .env file). Remember, the key is displayed only once, so secure it immediately [9]. Avoid hardcoding the key directly into your source code.
Create a .env file in your project’s root directory and insert your key like this:
APIMART_API_KEY=sk-your-key-here
In your code, you can load the key using os.getenv("APIMART_API_KEY") in Python or process.env.APIMART_API_KEY in Node.js [4]. For production environments, consider using a dedicated secret management service. Every API request must include a Bearer token in the header:
Authorization: Bearer YOUR_API_KEY
This single API key eliminates the need to manage separate credentials for OpenAI, Anthropic, and Google [9]. After securing your credentials, you’re ready to test your integration with a sample API call.
Making Your First API Call
Integrating with the platform is straightforward if you're familiar with OpenAI's SDK. You only need to update two parameters: the base_url and your api_key. Here’s an example using GPT-5:
from openai import OpenAI
import os
client = OpenAI(
base_url="https://api.apimart.ai/v1",
api_key=os.getenv("APIMART_API_KEY")
)
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Explain quantum computing in simple terms"}]
)
print(response.choices[0].message.content)
Switching models is as simple as updating the model string. For asynchronous tasks, such as video generation, the initial request will return a task_id. You can poll the status by sending a GET request to /v1/tasks/YOUR_TASK_ID until processing is complete [9]. A successful integration is confirmed when you receive a 200 OK status and a properly formatted response. Don’t forget to implement error handling for issues like 401 errors, which often indicate an expired key or insufficient balance [11]. If you’re already familiar with OpenAI’s SDK, this setup can be completed in just a few minutes.
Building Multi-Model Workflows: Advanced Use Cases
Creating advanced workflows takes integration to the next level by connecting text, image, and video models through unified APIs.
Connecting Text, Image, and Video Models
With unified APIs, you can chain different models together to create advanced multi-modal workflows. This often involves a pipeline approach, where each model plays a role in a multi-step process [14]. For instance, you might start with GPT-5 to draft a creative brief, pass that to Flux Pro for generating images, and then use Kling V3 to transform those images into a video.
To save costs, consider starting with image-first prototyping. Generate and refine static images at a cost of $0.02-$0.08 per image, and once approved, convert them into videos using video synthesis tools like Sora 2 ($0.10 per generation) or Kling 2.6 ($0.04 per generation). This method avoids expensive video-only iterations while ensuring consistent style across the process [15].
For asynchronous video tasks, use a task_id to track progress and poll every 5-30 seconds [13]. Normalize responses into a standard JSON format [14]. This allows the output from one model, such as text, to be seamlessly used as input parameters for subsequent models like image or video generators. For binary data like JPEGs, PNGs, or WAV files, embed them into JSON using base64 encoding [12].
Improving Multi-Model Pipeline Performance
Once your workflow is set up, the next step is to optimize its performance. One effective strategy is the Cascade pattern. Route simple tasks to cost-efficient models like Gemini Flash ($0.075 per 1M tokens), and reserve premium models like Claude Sonnet ($3.00 per 1M tokens) for more complex tasks. This approach can lower costs by 60-80% [3][14][8].
For real-time applications, low latency is critical. If a model takes 30 seconds to respond, it’s essentially unusable for most user-facing applications, even if it technically works (e.g., returning HTTP 200) [17]. Track P95 latency and set up latency-based fallbacks to handle delays. You can also use parallel execution with tools like asyncio.gather to call multiple models at the same time [8][14].
Efficiency starts with preprocessing. For example, downscale images to 1024-2048px and sample video frames at 1 frame per second for analysis tasks [1][16]. If your workflow involves reusing long reference materials, take advantage of prompt caching (available with OpenAI and Anthropic) to cut down on both costs and latency [14]. Additionally, maintain visual consistency by passing fixed seeds and aspect ratios (like 16:9) through all models in the pipeline [15].
Best Practices for Multi-Model Integration
Ensuring your multi-model pipeline performs well in production is about more than just solid integration techniques. Even the most well-planned setups can stumble when faced with unexpected conditions - like provider outages, hitting rate limits, or runaway costs. The key difference between a system that thrives in production versus one that falters often lies in how you handle errors and manage expenses.
Handling Errors and Troubleshooting
Not all errors need a fallback. For example, if a model returns a 4xx error (like a 400 Bad Request), it usually means the input is invalid, and retrying with another provider will likely fail too. Instead, focus fallbacks on 429 (rate limit) or 5xx (server error) responses [17].
One way to safeguard your system from cascading failures is by using a circuit breaker pattern. If a provider fails repeatedly, pause requests to it temporarily, allow a cooldown period, and then send a test request to check if it’s back online [18]. This prevents your system from overloading a struggling provider and wasting rate limits.
Latency is just as important as uptime. For user-facing applications, a provider that takes 30 seconds to respond is practically unusable - even if it eventually returns a successful HTTP 200 response [17]. Keep an eye on your P95 latency and implement latency-based fallbacks. If your primary model is too slow, reroute the next request to a faster alternative.
Here’s why fallbacks matter: OpenAI experienced 47 status incidents in 2024, averaging one every eight days [17]. To prepare for such disruptions, configure a fallback chain from the start. Test it thoroughly by revoking an API key in a staging environment to ensure requests shift seamlessly to a secondary provider [3][17].
| Integration Mistake | Impact | Fix |
|---|---|---|
| No fallback chain | App fails when a provider is down | Set up at least two providers [17] |
| Using the same model for all tasks | Overspending on simple tasks | Route tasks based on complexity [17] |
| Treating all errors as fallback-worthy | Adds unnecessary delays | Only fall back on 5xx and 429 errors [17] |
| Ignoring rate limits | Triggers cascading 429 errors | Use per-provider rate limits [17] |
Once error handling and latency are under control, the next challenge is keeping costs in check.
Managing and Reducing Costs
Optimize costs by routing tasks based on complexity. Sending every request to premium models like GPT-4o or Claude Sonnet can quickly become expensive. For simpler, high-volume tasks like classification or data extraction, opt for a more affordable model like Gemini Flash, which costs $0.075 per 1M input tokens - 33 times cheaper than GPT-4o and 40 times cheaper than Claude Sonnet [17]. Save the premium models for complex tasks like reasoning, code reviews, or creative writing.
Set strict budget limits from the start. Use your API gateway to enforce daily and hourly spending caps to avoid situations where runaway loops drain your monthly budget in hours [3].
Caching is another effective way to cut costs, reducing expenses by 40-60% while also improving response times for repeated queries [2][14]. This is especially useful for workflows that reuse extensive reference materials, such as documentation or product catalogs. Both OpenAI and Anthropic support prompt caching for this purpose.
Track metrics for each model - like success rates, latency, and cost - rather than just monitoring your total spending. This granular view helps you fine-tune your routing rules. For instance, if the majority of your budget is still going to the most expensive model, it might indicate that your cascade logic isn’t working as intended [3][5].
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Best For |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | General-purpose, creative tasks |
| Claude Sonnet | $3.00 | $15.00 | Code and analysis |
| Gemini Flash | $0.075 | $0.30 | High-volume, cost-sensitive tasks |
| GPT-4o mini | $0.15 | $0.60 | Budget-friendly alternative |
| Claude Haiku | $0.25 | $1.25 | Budget alternative to Sonnet |
Finally, don’t wait for a crisis to test your fallback logic. Simulate provider outages by temporarily disabling API keys to confirm that your system redirects requests as expected [3][5].
Conclusion: Simplifying AI Development with Unified APIs
Managing multiple AI models can be a headache, but unified APIs simplify the process by consolidating everything into a single endpoint, one SDK, and one bill. This means your choice of AI provider becomes as easy as changing a configuration setting, rather than committing to a rigid architectural decision [7]. By streamlining multi-modal integrations, unified APIs eliminate vendor lock-in and make switching models a breeze with minimal code adjustments.
The benefits are clear when it comes to productivity. For example, in early 2026, Thomson Reuters leveraged a unified SDK to develop CoCounsel, an AI assistant for legal professionals, in just two months with a team of only three developers [7]. This approach transforms what would typically be separate, time-consuming engineering projects into efficient, scalable solutions.
Beyond speeding up development, unified APIs also enhance operational reliability. Features like automatic failover and complexity-based routing keep systems running smoothly, even during disruptions. With 37% of enterprises now using five or more AI models in production [7], and OpenAI experiencing 47 status incidents in 2024 - an average of one every eight days [17] - teams with fallback mechanisms remained operational while single-provider setups faced downtime.
Cost management is another advantage. Unified APIs allow you to route tasks intelligently, using more affordable models for basic operations and reserving high-end models for complex tasks. Centralized budget controls and per-model cost tracking further simplify financial oversight, freeing up your team to focus on innovation rather than infrastructure [7][17].
Platforms like APIMart take this concept to the next level, offering access to over 500 AI models through a single OpenAI-compatible API. Whether you're creating multi-modal workflows or optimizing costs, unified APIs help you concentrate on building and innovating, not wrestling with infrastructure.
FAQs
How do I choose which model to use for each request?
To choose the best model for your needs, think about the type of task, its complexity, cost considerations, and the reliability of the model. Implement routing strategies like complexity-based routing or cost-based routing to manage tasks efficiently - direct simpler tasks to less expensive models, while reserving powerful models for more demanding tasks. Always include fallback mechanisms to reroute requests if the primary model encounters issues. This approach helps balance performance, cost efficiency, and reliability effectively.
How can I standardize outputs across text, image, and video models?
To ensure consistency in outputs, create a unified schema with standardized fields such as status, confidence scores, and modality-specific data (like text, image URLs, or video details). Responses should be normalized by converting visual content - like images and videos - into structured JSON metadata, while text outputs should follow a uniform format. A control plane can oversee these transformations, guaranteeing predictable and consistent outputs across all models. This approach simplifies processing and enhances the overall user experience.
What’s the safest way to handle outages and rate limits with fallbacks?
When it comes to managing outages and rate limits, the most reliable approach is to implement a multi-provider architecture. This setup includes automatic failover mechanisms and consistent health monitoring to ensure seamless operation.
Here's how it works: Use an API gateway or control plane to handle request routing. This gateway monitors the health of your providers and automatically reroutes traffic if one provider experiences issues, such as an outage or rate limit spike.
To further enhance reliability, establish a fallback chain. This ensures that if a primary provider fails, requests are retried with secondary providers. By doing this, you can maintain service continuity while keeping downtime to an absolute minimum.
Choose the model you want in the model marketplace
Try chat, image and video models in the APIMart model marketplace, and experience model capabilities quickly with one unified API.