
Switch AI Models Without Rewriting Code
Learn how unified AI APIs let you switch between 500+ models through one endpoint using config-driven routing, adapter layers, and safe A/B testing on APIMart.
Switching between AI models can be a headache - different providers mean different setups, SDKs, and response formats. But there's a better way. Unified AI APIs let you connect to multiple models through a single interface, making switching as easy as updating a configuration setting. This approach saves time, reduces errors, and ensures your app isn’t tied to one provider.
Here’s what you’ll learn:
- Unified AI APIs simplify integration by standardizing endpoints, authentication, and parameters.
- Tools like APIMart connect you to 500+ models with a single API key and endpoint.
- Design tips like centralizing configurations and creating a routing layer help you switch models effortlessly.
- A/B testing and monitoring ensure smooth transitions when trying new models.
Unified APIs eliminate the need for major rewrites, letting you focus on choosing the right model for the task at hand.
Understanding Unified AI APIs
What Are Unified AI APIs?
A unified AI API is like a one-stop shop for connecting with multiple AI models. Instead of juggling different setups for each provider - whether it's OpenAI, Anthropic, Google, or others - you get a single interface that handles everything behind the scenes. No need to dive into the quirks of each provider's integration process.
With this approach, switching between models becomes a breeze. All it takes is updating a string value, rather than overhauling your authentication or core logic. This makes unified APIs a perfect choice for anyone aiming to streamline multi-model integrations without getting bogged down in rewrites.
| Concept | Unified AI API | Single-Provider API |
|---|---|---|
| Endpoint | One base URL (e.g., https://api.apimart.ai/v1) | Separate URLs per provider |
| Authentication | Authorization: Bearer KEY | Different methods for each provider |
| Model Selection | "model": "string-id" | Varies by SDK or URL path |
| Vendor Lock-in | Low - switch via config change [5] | High - migration is challenging |
Key Components of Unified API Integration
Unified API integration relies on four main elements: a base URL, a model identifier, an API key, and environment variables.
- The base URL simplifies things by replacing all provider-specific endpoints with one universal address [1].
- A model identifier - like
"gpt-4o"or"claude-opus-4"- tells the gateway which AI model to use. - Your API key ensures secure access through the unified gateway.
- Environment variables make configuration changes easy without touching production code.
One of the perks of using a unified gateway is that it adds only about 3ms to 50ms of extra latency per request [4]. That’s barely noticeable compared to the time it takes for the model itself to process a request. Plus, these gateways often handle a tricky issue: parameter normalization. Different providers use different terms for the same features. For instance, controlling how strictly a model sticks to your prompt might be called guidance_scale by Flux and Google, cfg_scale by Stability, and quality by OpenAI [3]. A unified API smooths out these differences, letting you work with consistent parameters no matter the provider.
OpenRouter: One API for 300+ AI Models
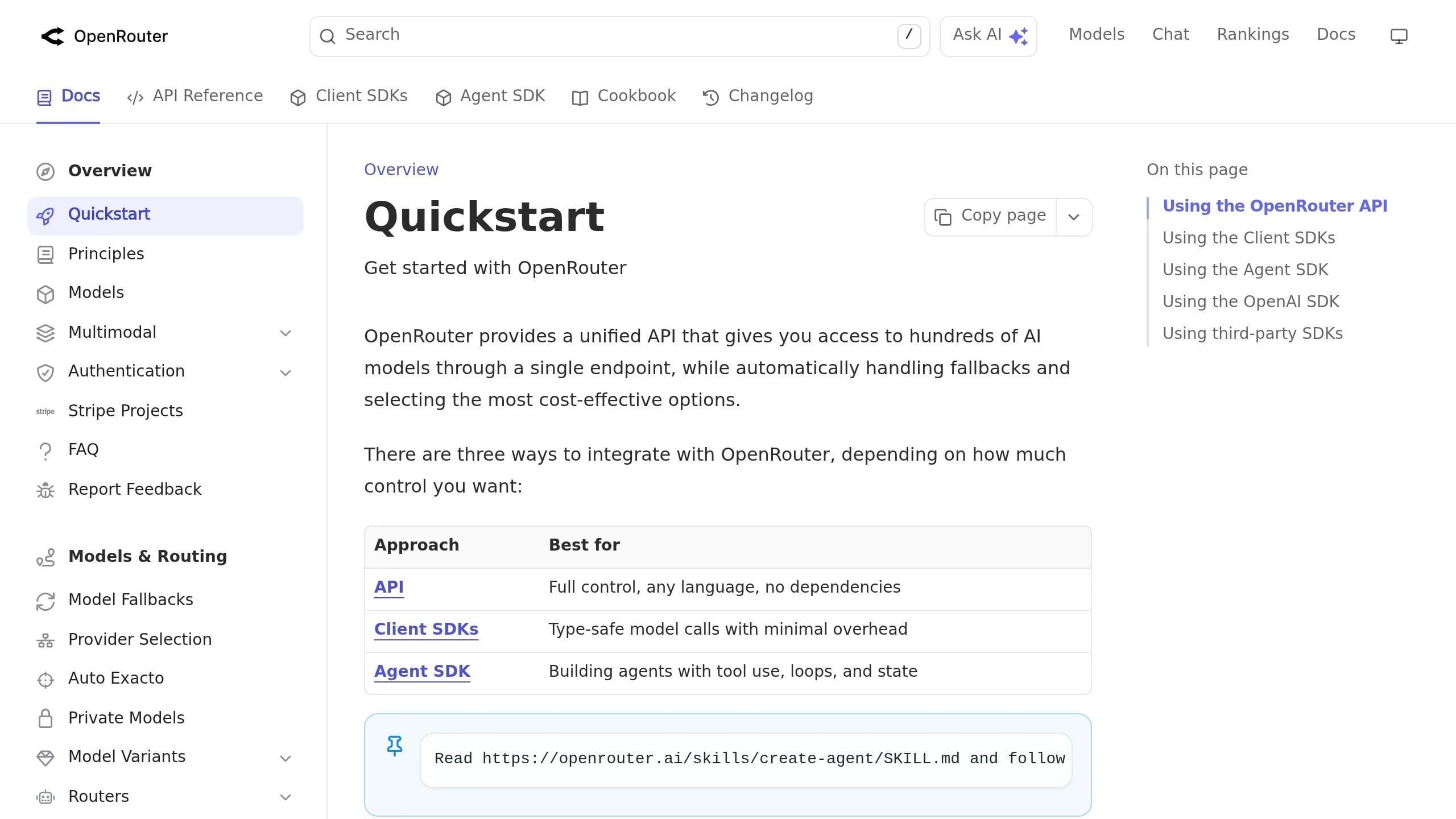
How to Structure Your App for Easy Model Switching
To make the most of unified API integration, it's crucial to design your app in a way that keeps it flexible across different models. A key principle is separating your business logic from API-specific logic. As engineer-founder Tian Pan explains:
"Your business logic should depend on an abstraction of a language model, not a concrete client from OpenAI or Anthropic." [6]
This approach isn't just about writing cleaner code - it’s a smart way to avoid expensive headaches. Migrating a mid-size production system that's tightly tied to one provider can rack up costs of $50,000 to $100,000 in engineering time [6]. The strategies below can help you structure your app to sidestep these challenges.
Standardizing Request and Response Formats
Create a single internal format, such as an AIMessage interface or AIResponse object, that stays consistent no matter which model you're using [2]. An adapter layer can translate the unique quirks of each provider into this standard format, so you don’t have to make sweeping changes throughout your code.
For instance, providers handle requests and responses differently: OpenAI uses a messages array with a system role, Anthropic requires a top-level system parameter, and Google opts for systemInstruction [2][9]. On the response side, OpenAI places content in choices[0], while Anthropic uses content[0]. By implementing an adapter layer, you can smooth out these inconsistencies, saving time and effort when switching models.
Centralizing Model Configuration
Use descriptive aliases like "text-fast" or "reasoning-premium" to represent specific model IDs in a central configuration file [7]. This method leverages the unified API's ability to isolate provider-specific details, ensuring your business logic remains untouched. When a new model version is released or you want to test a more cost-effective option, you only need to update one line of code instead of hunting through your entire app.
You can take this a step further with a provider registry, which links each alias to a factory function that dynamically creates the correct client at runtime [6][7]. This way, the rest of your app doesn’t need to know - or care - which provider is in use.
Building a Model Routing Layer
A routing layer acts as a middleman between your app and the providers, deciding which model should handle each request. For example, you can set up a rule-based router that sends complex queries to premium models and simpler tasks to faster, lower-cost options [10]. This layer works hand-in-hand with the unified API, reducing the complexity of managing multiple providers.
Here’s a real-world example: In April 2026, a SaaS company cut its daily LLM costs by 58%, dropping from $1,420 to $594. They achieved this by using a routing layer to direct simple tasks to cheaper models while reserving premium ones for more demanding queries [8]. The routing layer also managed automatic fallbacks for errors like 429 or 5xx, ensuring smooth operations [2][8].
How to Switch Models Using APIMart
Using APIMart as a Central Model Hub
APIMart makes managing AI models easier by offering centralized access to over 500 models for text, image, video, and audio tasks - all through a single endpoint: https://api.apimart.ai/v1. With just one API key, a unified request format, and centralized settings, switching between models is seamless.
For example, if you're using the OpenAI SDK for Python or Node.js, all you need to do is point the base_url to APIMart's endpoint. Changing from GPT-5 to Claude 4.6 Sonnet? It's as simple as updating the model string - no need to mess with new SDKs or authentication processes.
This setup is especially handy for teams that need to experiment quickly. Instead of creating separate integrations for each AI provider, you can rely on one streamlined integration and adjust configurations as needed.
Switching Between Video Models Based on Project Needs
When it comes to video generation, picking the right model is crucial. Each model comes with its own trade-offs in terms of cost, quality, and speed, depending on the task at hand. APIMart simplifies this process by offering multiple video model options through the same API, so you can choose the best fit for your project without changing your workflow.
Here’s a quick comparison of some popular options:
| Model | Price | Best For |
|---|---|---|
| MiniMax Hailuo 2.3 | $0.025/sec | Quick, cost-effective drafts |
| Kling V3 Omni (720P) | $0.0672/sec | Multi-modal inputs and versatility |
| Sora 2 Preview | $0.08/sec | High-quality creative outputs |
For example, MiniMax Hailuo 2.3 is perfect for early-stage drafts or internal brainstorming sessions where speed and cost are priorities. If you need to work with both text and image inputs to create short clips, Kling V3 Omni is a solid choice. For customer-facing campaigns where quality is paramount, go with Sora 2 Preview. Since all these models share the same request structure, you can switch between them by updating one configuration value.
This flexibility also makes it easier to integrate multi-modal workflows into your projects.
Running Multi-Modal Workflows With a Single API
APIMart’s unified API is designed to handle multi-modal workflows with minimal effort. By chaining different model types in a single pipeline, you can adjust model identifiers at various steps without worrying about authentication, billing, or tracking changes.
Here’s an example of how a content production pipeline might look:
| Step | Model Example | Task |
|---|---|---|
| 1. Scripting | GPT-5 | Create a creative brief and video prompts |
| 2. Storyboarding | Flux Pro | Generate reference images based on the script |
| 3. Video Synthesis | Kling V3 Omni | Turn images into cinematic clips |
| 4. Final Polish | Sora 2 Preview | Deliver high-quality final scenes |
The secret to keeping this pipeline manageable lies in a configuration-driven approach. Centralize details like model identifiers, input formats, and parameters (e.g., resolution, duration, aspect_ratio) into one configuration object. This way, if you need to replace the video model in step 3, you can do so without affecting the earlier scripting or image-generation steps.
For video and image tasks, APIMart processes them asynchronously. It provides a task_id that you can use to poll for results with exponential backoff (starting at 10–20 seconds) until the task is complete.
Best Practices for Switching Models Safely and Efficiently
To make the most of APIMart's unified API integration, following key practices in configuration management, monitoring, and security is essential for smooth and secure model transitions.
Versioning and Testing Model Configurations
When managing model configurations, treat them like you would code. Use version control to track changes to model identifiers, parameters, and routing rules. This way, if something goes wrong, you can quickly roll back to a previous version. Keeping a detailed history of changes helps troubleshoot issues when switching models.
Before deploying a new model in production, conduct A/B testing. Route a small percentage of live traffic to the new model and compare its performance against the existing one. This approach provides insights based on real-world usage rather than just test data. For additional quality checks, use an LLM-as-judge setup. For example, models like GPT-5 or Claude 4.5 can evaluate a sample of 1–5% of the new model's outputs, helping identify subtle quality issues before they impact users [8].
Automated health checks are another critical tool. Set up periodic test requests - such as a lightweight 5-token completion - every 60 to 120 seconds. This helps you detect outages from providers early, reducing the risk of waiting for user complaints to uncover problems [2].
Monitoring and Logging Model Performance
Once a model is live, keep a close eye on metrics like latency, cost, and error rates. Latency, particularly the P95 response time (the 95th percentile), is a key indicator. For instance, if a model takes 30 seconds to respond, it’s practically unusable for user-facing applications, even if it technically succeeds with an HTTP 200 response [2][8].
"One model for everything is dead. Pick the right tool for each request, and your AI bill drops 40–70%." - Akshay Ghalme, AWS DevOps Engineer, BytePhase Technologies [8]
Your logs should also capture resolved model metadata, detailing which model handled each request. This is especially important in fallback scenarios. If a budget-friendly model frequently escalates to a premium one - say, more than 30% of the time - it’s a sign that your routing logic needs adjustment [8].
In addition to performance monitoring, securing your API credentials is crucial for uninterrupted operations.
Keeping API Keys Secure and Staying Compliant
Strong security measures are essential to maintaining a stable multi-model environment and ensuring seamless model transitions without exposing vulnerabilities. Use a single API key with APIMart to limit your attack surface. Store this key securely in environment variables or a secrets manager, and avoid hardcoding it or committing it to version control.
For teams operating in regulated industries, compliance is a must. As Akshay Ghalme notes:
"Routing must respect contractual / regulatory constraints - some data should never leave a specific region or vendor." [8]
Ensure your routing logic adheres to data residency rules. Use gateways that support SOC 2 compliance, single sign-on (SSO), and centralized audit logs. Additionally, implement per-tenant spending caps to prevent unexpected costs, particularly in multi-tenant setups where clients may have varying usage tiers or data requirements [8].
Lastly, reserve automatic fallbacks for specific error types. For example, use fallbacks for 429 (rate limit exceeded) and 5xx (server error) responses, where switching models can resolve the issue. Avoid fallbacks for 4xx errors like a 400 Bad Request, as these typically indicate malformed inputs that a model switch won’t fix [2].
Conclusion: Gaining Flexibility With Unified AI APIs
Unified AI APIs make switching between AI models as simple as tweaking a configuration setting - no heavy coding or system overhauls required.
By standardizing request and response formats, centralizing model configurations, and routing everything through a single interface, you eliminate the need for complex engineering work when changing models. Your application logic stays intact, no matter which model you choose to use.
Take APIMart as an example. With its single endpoint that connects to over 500 models - spanning text, image, and video generation - teams can switch models effortlessly. Imagine a U.S.-based e-commerce team A/B testing two language models for product descriptions. They can adjust a routing rule in APIMart, track the results in USD, and compare conversion rates - all without deploying new code. This streamlined process helps teams adapt quickly to changing project needs.
This setup also grows with you. Whether you're scaling for increased traffic or integrating cutting-edge tools like advanced video generators or domain-specific models, this unified approach keeps things simple. Developers can onboard faster, and your system can handle new technologies without disrupting your core application.
What makes unified AI APIs so powerful is their ability to embed flexibility directly into your architecture. Model transitions become routine adjustments, not massive undertakings. This adaptability ensures you’re ready for whatever comes next.
FAQs
How do I add model switching to an existing app without refactoring everything?
To make switching models seamless without rewriting your code, consider using a unified API gateway. By directing your SDK's base URL to a gateway like APIMart, you can manage model selection, routing, and failover effortlessly. This setup allows you to adjust configurations - like dynamically updating a model parameter in your code - without touching authentication, SDK logic, or error handling. The gateway takes care of standardizing these processes, saving you time and effort.
What should go into a model routing layer (and when should I avoid fallbacks)?
A model routing layer serves as the hub that links your application to different AI models. Its job is to manage request mapping, choose models based on cost-efficiency, implement failover strategies, and monitor performance. To maintain stability, use config-driven routing maps that rely on task-specific benchmarks.
When it comes to specialized tasks that demand precise, single-model execution, avoid fallback mechanisms for semantic or quality issues. This approach ensures strict quality control and avoids compromising outcomes.
How can I A/B test a new model safely without breaking production?
To test a new AI model without risking disruptions in production, begin by running the model in shadow mode. In this setup, production traffic is sent to both the existing model and the new one. The current model continues serving users, while the new model processes inputs in the background, allowing you to compare results without affecting live operations.
Once the new model's performance is validated, you can use tools like a unified API gateway or feature flags for a gradual rollout. These allow you to carefully monitor performance metrics and set up rollback triggers to maintain system stability if any issues arise.
Choose the model you want in the model marketplace
Try chat, image and video models in the APIMart model marketplace, and experience model capabilities quickly with one unified API.