
GPT-Image-2 プロンプト完全ガイド · DALL·E 3 / SDXL 比較
GPT-Image-2 のマルチモーダルプロンプト設計を徹底解説。六ブロック構造、最大 16 枚の参照画像、99% 多言語テキスト精度を、DALL·E 3 と Stable Diffusion XL と比較しながら紹介します。
GPT-Image-2 は OpenAI が 2026 年 4 月 21 日にリリースした最新のマルチモーダルモデルです。DALL·E 3 のような従来モデルと違い、テキスト理解と画像生成を同一システム内で処理するため、多言語テキスト描画、空間レイアウト、複雑なプロンプトへの対応がいずれも高精度になっています。主な特徴は次のとおりです:
- テキスト描画: 50 以上の言語で 99% の精度、DALL·E 3 や Stable Diffusion XL を大きく上回ります。
- 空間制御: "top-center" や "bottom-right" などの位置指定語で、要素の配置を正確にコントロールできます。
- 編集機能: タクティカルなインペインティングで、全体に影響を与えず局所のみ編集可能。
- プロンプト柔軟性: 1 回あたり最大 32,000 トークン、参照画像 16 枚まで対応し、AI モデルマーケットプレイスから直接利用できます。
DALL·E 3 や Stable Diffusion XL より高コストですが、GPT-Image-2 は精度面で他に代えがたい強みを持ち、インフォグラフィック、多言語デザイン、緻密な構図といった本番運用に向いています。とはいえ生成速度の遅さと価格の高さは、案件によってはネックになります。
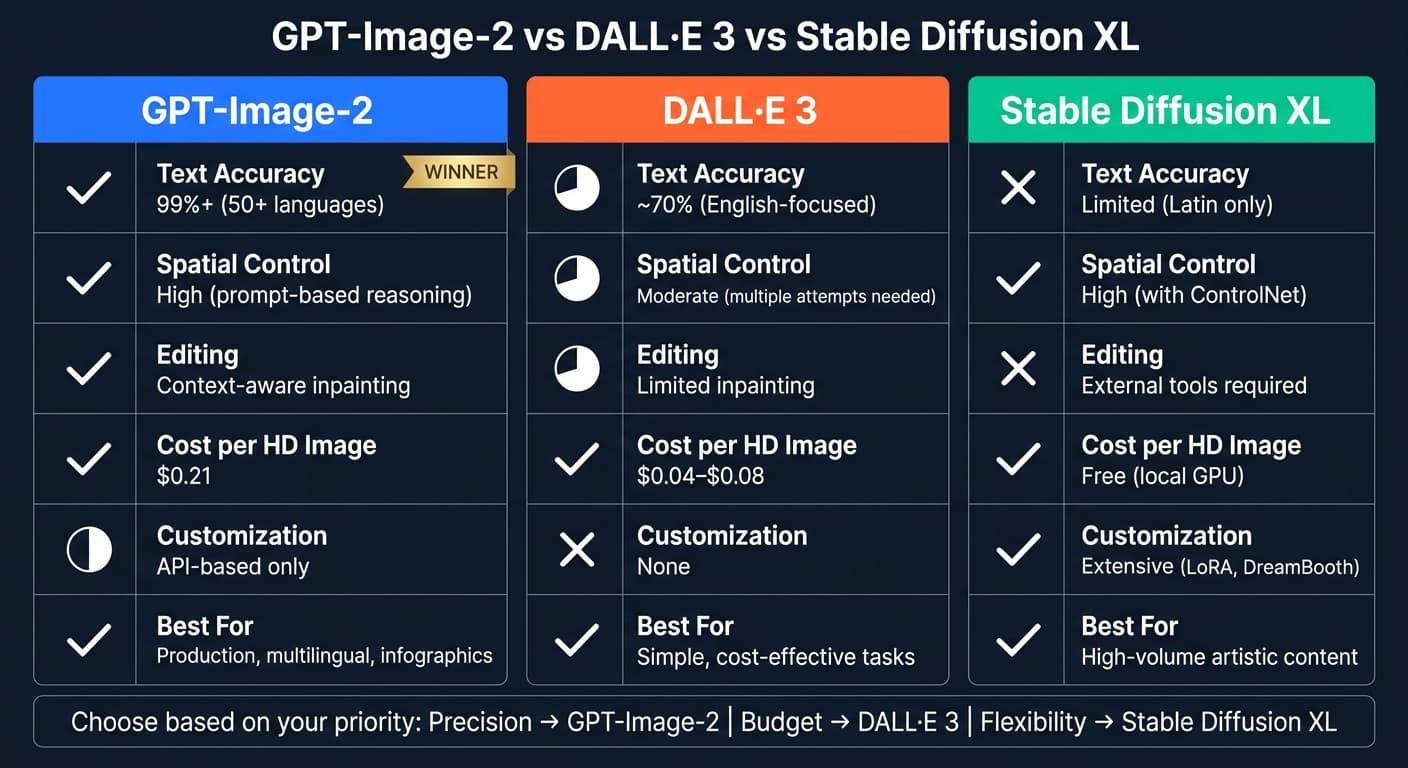
クイック比較:
| 項目 | GPT-Image-2 | DALL·E 3 | Stable Diffusion XL |
|---|---|---|---|
| テキスト精度 | 99%+(多言語) | 約 70%(英語寄り) | 限定的(ラテン文字のみ) |
| 空間制御 | 高(プロンプト経由) | 中程度 | 高(ControlNet 併用時) |
| 編集 | コンテキスト対応の編集 | 限定的なインペインティング | 外部ツールが必要 |
| コスト | $0.21(HD 画像) | $0.04–$0.08 | ローカルなら無料 |
| カスタマイズ性 | API 経由のみ | なし | 高(ローカルでファインチューニング可) |
精度を最優先するなら GPT-Image-2 が筆頭。DALL·E 3 はシンプル・低コスト用途に、Stable Diffusion XL は技術力のあるチーム向けです。
GPT Image 2 登場 — 押さえておくべきポイント
1. GPT-Image-2
GPT-Image-2 は「描く前に考える」自然言語モデルとして設計されており、生成前に構図を計画し、空間的な矛盾を整理します。Pixo Blog はこう説明しています:
「GPT-Image-2 はキーワード一致のエンジンではない。O シリーズの推論能力を載せた自然言語モデルだ。」 [7]
この独自の能力こそが、プロンプト設計を特に重要にしています。
プロンプト構造
このモデルの推論力を最大限に引き出すのが、よく設計されたプロンプト構造です。最も効果的なプロンプトは「六ブロック」フレームワークに従います:Subject(主体)、Action(動作)、Scene(場面)、Composition(構図)、Lighting(光)、Style(スタイル)。プロンプトはクリエイティブブリーフとして書きましょう。統合 LLM API は最大 32,000 トークンを扱えますが、実際は 100–300 語に収めると最も良い結果が出ます。[7]
複数画像を扱う案件では、GPT-Image-2 は 1 回のプロンプトで最大 16 枚の参照画像 を受け付けます。各画像にインデックスで明確な役割を割り当てましょう。例えば 「Image 1: subject identity, Image 2: color style」 のように指定すれば、モデルはそれぞれの素材から要素を適切に取り込みます。[7][9]
テキスト描画
GPT-Image-2 は 英語、スペイン語、ドイツ語、フランス語、日本語、簡体字・繁体字中国語、韓国語 など多くの言語のテキスト描画に強いのが特徴です。[9] テキストを入れたいときはダブルクォートで囲みます(例:"30% OFF")。英語以外の単語は "ZEITGEIST (Z-E-I-T-G-E-I-S-T)" のように一文字ずつ綴ると、精度は約 99% まで上がります。[7]
ただし、文字を入れたくない指示を含めないと、約 60% の画像 に意図しない文字が混入します。これを防ぐにはプロンプトの末尾に必ず 「No extra text, no additional words, no watermarks.」 のような指示を入れましょう。[7]
空間制御
GPT-Image-2 はレイアウトの空間制御も精密です。要素が 3 つを超えるシーンでは Thinking Mode をオンにしましょう。レンダリング前に 10–30 秒の計画時間を与えることで、レイアウト精度が大きく向上します。[7] 「top-center」「bottom-right」「along the left margin」 といった明示的な位置指定語を使えば、要素や文字を狙った場所に配置できます。CreateVision AI の AI モデルリサーチリード Marcus Rivera 氏は、このモデルは 「タイトル無しの 4 列という残念な結果ではなく、競合する制約を最初の試行で合理的に解決してくる」 と述べています。[9]
編集機能
出力を仕上げるため、GPT-Image-2 は Edits API エンドポイント(v1/images/edits)経由で タクティカルなインペインティング をサポートします。特定領域を選んで 「fix a typo」 や 「swap a product」 のような指示を渡せます。[7][8] 最良の結果を得るには、変えてはいけない部分を明確に指定しましょう。例:「change only the background, keep the subject and lighting the same.」 編集を 3 ラウンド以内に抑えることで、ノイズの蓄積や画質劣化を防げます。[7]
2. DALL·E 3

DALL·E 3 は GPT-4 を使ってプロンプトを処理し、拡張・書き換えた上で画像を生成します。Enter Pro はこう解説しています:
「DALL·E 3 自体は独立した拡散モデルだった。OpenAI はそれを外部ツールとして ChatGPT に接続した形で、GPT-4 が拡張プロンプトを書き、DALL·E 3 が別途レンダリングする構成だ。」 [4]
この 2 段階の処理は「インテントドリフト」を引き起こしがちで、最終的な画像が元のリクエストと完全に一致しないことがあります。拡張されたプロンプトでは細部のニュアンスが落ちることがあり、制御性と精度の両方に影響します。
プロンプト構造
GPT-4 が自動でプロンプトを拡張してくれるため、DALL·E 3 はより短く会話的な入力でも動きます。ただしその代償として創作の制御性は下がります。たとえば複数画像のコンポジションには非対応で、これは GPT-Image-2 が備える機能です [10]。
テキスト描画
DALL·E 3 で目立つ弱点はテキスト描画で、精度は約 70% に留まります。長文や非ラテン文字では特に苦戦します。Lensgo チームはこう指摘しています:
「DALL·E 3 の最大の弱点は読めるテキストだった。『Summer Sale 50% Off』と書いたポスターを依頼すると、『Sumnner Sal 50% Of』のような結果が返ってきた。」 [10]
このため、ポスター、商品ラベル、多言語デザインなど精密なテキストを必要とする案件には不向きです。
空間制御
DALL·E 3 はプロンプト内の描写的な言葉で空間配置をコントロールします。中程度の性能は出ますが、精密な配置を狙うと再生成を何度も行う必要があり、時間とコストがかさみます [5]。GPT-Image-2 の優れたレイアウト能力とは差が開きます。
編集機能
DALL·E 3 の編集はインペインティングの実装に縛られています。選択範囲を再生成する際、周辺部分も意図せず変わってしまうことがあります。例えば:
「写真をアップロードして『帽子を赤いベルベットに変えて』と頼むと、DALL·E 3 は画像全体を再生成しがちで、戻ってきた顔は別人になっていたりする。」 [10]
被写体ロック、input_fidelity の調整、透明背景の標準対応といった機能がなく、手作業での修正が前提になります。価格は標準 1024×1024 画像が $0.04、ハイレゾが $0.08 と GPT-Image-2 より安いものの、これらの制約により反復型の本番タスクには向きません [4]。
2026 年 4 月時点で、DALL·E 3 は ChatGPT のインターフェースから削除され、GPT-Image-2 に置き換わりました。レガシー API エンドポイントも 2026 年内に廃止予定です [2]。
3. Stable Diffusion XL
SDXL は、GPT-Image-2 や DALL·E 3 のような API 型ツールとは別路線の、ユーザー主導の選択肢です。ローカル GPU やクラウド経由で運用できる オープンソース基盤モデル で、マネージド API を呼ぶだけのアプローチより遥かに高いコントロール性があります [11]。
プロンプト構造
組み込みの推論層を持つモデルと違い、SDXL は明示的なトークンとウェイト調整に完全依存して結果を出します。そのためプロンプトの正確さが求められます。特定のスタイルやキャラクターを再現するには、LoRA や DreamBooth などでファインチューニングできます [12]。
テキスト描画
テキスト描画には明確な制約があります。短いラテン文字なら対応できますが、長い文字列、非ラテン文字、正確なタイポグラフィでは苦戦します。GPT-Image-2 の多言語テキストはほぼ完璧な精度なので、SDXL でそのレベルを目指すには外部のファインチューニングが必要です [11]。
空間制御
SDXL は特に ControlNet と組み合わせると強力な空間制御を発揮し、深度マップ、ポーズスケルトン、エッジ検出データを入力して構図を精密に組めます [11]。ただし ControlNet なしでは、複雑なレイアウトでは苦しくなります。
「5 つの見出しが入った雑誌の表紙や、矢印付きラベルのある 4 コマインフォグラフィックを描かせてみると、途端に崩れる。文字が乱れ、ラベルが消え、レイアウトが破綻する。」 - BestPhoto チーム [3]
編集機能
SDXL での編集はインペインティング、アウトペインティング、LoRA スワップ、ControlNet オーバーレイなど外部ツールに完全依存します [12]。強力な結果を出せますが、Python 環境、GPU ドライバ、モデルウェイトを自前で管理する必要があり、学習コストは高めです。一方で、プライバシーやブランド独自性 を重視するチームには、SDXL のローカル処理は大きなアドバンテージになります。それ以外のチームには技術的な負担が利点を上回ることもあります [11]。
| 項目 | Stable Diffusion XL | GPT-Image-2 |
|---|---|---|
| 空間制御 | 高(ControlNet、深度マップ)[11] | 中(プロンプトベース)[11] |
| カスタマイズ性 | 高(LoRA、DreamBooth)[11] | 低(API のみ、ファインチューニング不可)[11] |
| テキスト描画 | 普通(ラテン文字寄り)[3] | 99%+ 精度、多言語 [3] |
| 編集方式 | インペインティング、マスク、ControlNet [12] | 自然言語指示 [12]、Flux 2 API と同様 |
| プライバシー | 高(ローカル処理)[11] | 中(OpenAI サーバー)[11] |
| コスト | ローカル無料(GPU 必要)[11] | 約 $0.04–$0.35 / 枚 [11] |
長所と短所
各 AI モデルには独自の強みと弱みがあり、適したタスクも変わります。
| モデル | 強み | 弱み |
|---|---|---|
| GPT-Image-2 | 50 以上の言語でテキスト描画に強い;推論でレイアウトを計画;コンテキスト対応の編集、最大 16 枚の参照画像 [9] | 生成が遅め(標準 30–60 秒、Thinking モード時最大 149 秒);コスト高(HD 画像 約 $0.21);精密な商標ロゴの再現が苦手 [1] |
| DALL·E 3 | 使いやすい;シンプルなシーンではプロンプトに忠実;価格が安い($0.04–$0.08 / 枚)[4] | 長文テキストでの描画にムラ;プロンプトから外れやすい;複数画像での一貫性に欠ける [4] |
| Stable Diffusion XL | ローカルなら無料;LoRA や ControlNet で深くカスタマイズ可能;アート系の大量生成向き [12] | ファインチューニングなしではテキスト描画が弱い;複雑なレイアウトに苦戦;技術的なセットアップ負荷が高い(Python、GPU ドライバ、モデルウェイト)[12] |
この表は、コスト・精度・柔軟性のトレードオフを端的に示しています。
コスト面では GPT-Image-2 は DALL·E 3 の約 5 倍、クラウド経由の Stable Diffusion XL に比べても 4 倍以上の価格です。しかしこの上乗せ分で、高度な推論能力、ほぼ完璧な多言語テキスト精度、AI Canvas を使った編集での最上級のパフォーマンスを手に入れられます。
「GPT-Image-2 は、密で情報量の多い構図を安定してこなせる初の広く利用可能なモデルだ。そして推論ステップを取り入れた初のモデルでもある。」 - BestPhoto チーム [3]
インフォグラフィックや多言語プロジェクトに取り組むチームにとっては、GPT-Image-2 の精度は追加コストや処理時間の遅さを十分埋め合わせます。Stable Diffusion XL はローカル処理と画像あたり実質ゼロコストの強みから、アート系のクリエイティブには現実的な選択肢。DALL·E 3 はバランス型で、安価かつスピーディだが精度が問われるタスクでは信頼性に欠けます。コストと品質の両立を狙うなら、GPT-4o Image API もマルチモーダル生成向けの高性能な代替として有力です。
まとめ
最適なモデルは、プロジェクトの要件次第で決まります。GPT-Image-2 は精度が求められる本番ワークフローで頭ひとつ抜けています。商品ラベル、UI モックアップ、多言語ポスター、フレーム間でキャラクターの一貫性が求められるキャンペーンなど、優れた多言語テキスト精度と一貫した推論を提供します。精度に妥協できないプロジェクトでは有力候補です。
一方で DALL·E 3 は、テキスト精度が重要でない一回限りのアートイラストに向いています。Stable Diffusion XL は、大量・スタイル特化型の出力を扱うチームで、技術力を活かして機能を最大限に引き出せる体制なら最適です。高機能な分、複雑で要求の厳しい案件には投資する価値があります。
判断する際には、運用面の現実も忘れないでください。複数の API キーと請求アカウントを抱えると、本番ワークフローは複雑化します。APIMart のようなツールを使えば、GPT-Image-2 を含む 500 以上の AI モデルを単一の統合 API で利用でき、管理コストを抑えて成果に集中できます。
「(GPT-Image-2 への)アップグレードは、GPT-3 から GPT-5 への飛躍に匹敵する。」 - Sam Altman、OpenAI CEO [6]
GPT-Image-2 を重要なワークフローに組み込むことで、アウトプットの品質と一貫性を大きく高められます。
よくある質問
強い GPT-Image-2 プロンプトを書くには?
良い GPT-Image-2 プロンプトの肝は、明確さと構造です。モデルへの詳細なクリエイティブブリーフだと考えましょう。まず希望する ビジュアルスタイル を指定します — 「cinematic」「watercolor」など、トーンを定めます。
次に光、環境、レイアウトを 具体的に 描写します。例えば「部屋」ではなく「大きな出窓から暖かな自然光が差し込む居心地の良いリビング」と書きます。具体的なほど、モデルは意図を読み取れます。
ラベルや UI 要素のテキストを含める場合は、正確な文言をクォートで囲んで 書きます。たとえば「ボタンのラベル」ではなく "Press Start" と書きます。
最後に、曖昧なフレーズや無関係なキーワードの羅列は避けましょう。明確で描写性のある言葉でモデルを導けば、品質の高い結果につながります。
画像内の意図しないテキストを防ぐには?
GPT-Image-2 が生成する画像で不要な文字を抑えるには、明確で精密なプロンプト を使うことが重要です。指示は具体的かつ詳細にし、曖昧な表現は避けましょう。整理されたプロンプトは視覚的なノイズを減らし、必要なテキストを読みやすく保ちます。プロンプトエンジニアリングのベストプラクティスを徹底すれば、結果の品質は大きく向上します。
Thinking Mode はレイアウトでいつ使うべき?
レイアウト時に Thinking Mode を有効にすると、モデルは構図、階層、制約を計画してから画像を生成します。このアプローチによってデザインとレイアウトを丁寧に推論でき、最終的なレンダリングはより構造的で整理されたものになります。
関連記事
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。