
Qwen Image 2.0とは何か
Qwen Image 2.0はAlibabaの統合型テキスト画像生成AIで、ネイティブ2K出力と1,000トークンのプロンプト、英中バイリンガル描画を1つのモデルで実現します。
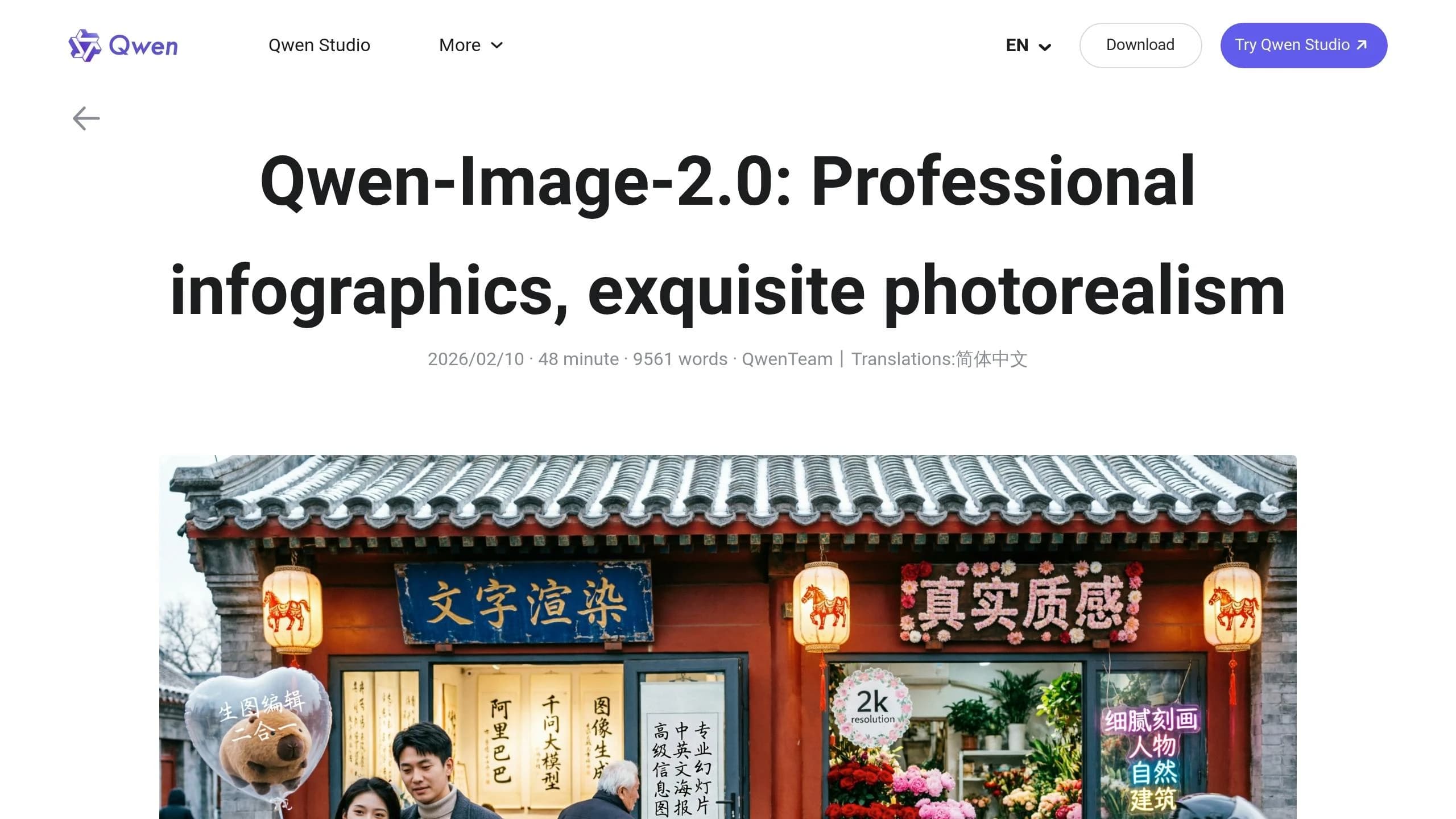
Qwen Image 2.0は、Alibabaが2026年2月10日に公開したテキスト画像生成AIモデルです。画像生成と編集を1つのシステムに統合し、ネイティブ2K解像度(2048×2048)、1,000トークンのプロンプトへの対応、そして英語と中国語での正確なバイリンガルテキスト描画を提供します。プロフェッショナルな用途向けに設計されており、高品質ですぐに使えるビジュアルを生成することで、マーケティング、Eコマース、メディアといった業界のワークフローを簡素化します。
主な特長
- 統合モデル:画像生成と編集を1つのツールに統合。
- バイリンガルテキスト:英語と中国語のテキストを正確に処理。
- 緻密な画像表現:後処理なしでシャープな画像を生成。
- オープンソース:Apache 2.0ライセンスにより商用利用とセルフホスティングが可能。
Qwen Image 2.0は、インフォグラフィック、製品ビジュアル、多言語デザインといったタスクに最適化されており、現代のクリエイティブニーズに対応する汎用性の高いソリューションとなっています。
Qwen Image 2.0の主要機能
テキストから画像への生成
Qwen Image 2.0は、アップスケーリングを必要とせずにネイティブ2K(2048×2048)画像を生成し、生地の質感、建築のエッジ、製品ラベルといった細部までシャープさを保ちます。これにより追加の後処理が不要になります。最大1,000トークンのプロンプトに対応しているため、ユーザーは照明、空間配置、色、質感の詳細を含む非常に緻密なシーン記述を、一度にまとめて作成できます。
このモデルは、フォトリアルな製品画像からアート寄りのイラストまで、さまざまなビジュアルスタイルに適応するため、商用プロジェクトとクリエイティブな取り組みの両方に適しています。
次に、統合編集がどのようにクリエイティブワークフローを簡素化するのかを見ていきましょう。
統合画像編集
Qwen Image 2.0は、画像生成と編集を単一の7Bパラメータモデル内に統合しているため、画像を外部ツールにエクスポートしたり、アプリケーションを切り替えたりする必要がありません。自然言語を使って、オブジェクトの追加、要素の削除、背景の変更、ポーズの調整、テキストの編集を直接かつ簡単に行えます。
そのデュアルエンコーディング機構により、編集中もセマンティックな細部が損なわれません。たとえば、Eコマースチームは、顔の特徴、アクセサリー、製品固有の属性といった重要なディテールを失うことなく、製品の背景を変更したり、バーチャル試着をシミュレートしたりできます。
"The unified architecture for editing and generation is a game changer for maintaining character consistency across different frames." - @DevLog_AI, Twitter [7]
ここでヒントを1つ。編集する際は、変更すべきでない部分を具体的に指定しましょう。たとえば「keep the jacket color and logo exactly the same」のような指示を含めることで、意図しない変更を避けられます [6]。
さらに、高度なテキスト描画機能がデザインワークフローを強化します。
画像内のテキスト描画
Qwen Image 2.0は、画像へのテキスト統合にも優れています。段落全体、複数列のレイアウト、そしてバイリンガルテキスト(英語と中国語)を、正確なタイポグラフィで描画できます。テキストは表面のジオメトリに沿って配置されるため、曲面上のロゴやガラスに書かれた手書きのメモといった要素も、適切な照明と遠近感を伴ってリアルに見えます。
この機能は、インフォグラフィック、ブランドポスター、プレゼンテーションスライドを手作業で組み立てる必要をなくし、1ステップで生成できるため、マーケティングおよびデザインチームにとって特に役立ちます。
この機能を最大限に活用するには、プロンプト内で表示したいテキストを二重引用符で囲みます。これによってモデルの専用タイポグラフィエンジンが起動します [7]。また、「three-column layout」や「bottom-right quadrant」といったレイアウト指定のフレーズを使って、テキストやグラフィックの配置を制御することもできます [1]。
🚀 次世代画像生成モデル、Qwen-Image-2.0のご紹介!
Qwen Image 2.0の業界別活用法
画像生成と編集の両方を1つのプラットフォームで処理できるQwen Image 2.0の能力は、クリエイティブなタスクを効率化し生産性を高めることで、さまざまな業界で定番のツールとなっています。
マーケティングと広告
マーケティングチームは、広告、ソーシャルメディア用グラフィック、バナーを作成するために複数のツールを使い分けることがよくあります。Qwen Image 2.0は、生成と編集を1つの一貫したモデルに統合することで、このプロセスを簡素化します。
その印象的な1,000トークンのプロンプト容量により、クリエイティブディレクターは、照明やムードからブランドカラー、フォント配置、キャッチコピーに至るまで、シーン全体を詳細に記述できます。これによりほぼ完成形のアセットが得られ、デザイナーとコピーライターの間で繰り返されるやり取りを削減できるため、時間に追われるキャンペーンにとって画期的な変化をもたらします。
Eコマース企業もこうした機能の恩恵を受けます。より速く正確なアセット制作は、売上やブランド認知に直接影響を与えるからです。
Eコマースと小売
米国のEコマースにおいて、高品質なビジュアルは顧客エンゲージメントとコンバージョンを高める鍵です。Qwen Image 2.0はネイティブ2K解像度の画像(2,048×2,048)を生成し、高DPIスクリーンやズーム対応ギャラリーでも美しく見える、シャープで緻密な製品ビジュアルを実現します。さらに、「Limited Time: $29.99」と表示するバナーのように、価格やプロモーションのテキストを画像に直接統合できるため、編集時にテキストレイヤーを追加する手間が不要になります。
このモデルの英語と中国語のバイリンガル対応は、ローカライズされたプロモーション素材を1ステップで作成できるようにし、効率をさらに高めます。この二言語対応機能は、国内と海外の両方のオーディエンスをターゲットとするブランドにとって特に価値があります。Atlas Cloudのブログでも次のように述べられています。
"Getting clear, readable text inside generated images has been a headache for a long time. Qwen Image 2.0 fixes a large chunk of that. The text is legible. It sits where it should. That alone saves hours of post‑editing." [8]
こうしたメリットは小売にとどまらず、メディアやエンターテインメントのプロフェッショナルにも、シームレスなビジュアルストーリーテリングのためのツールを提供します。静止画と動きの橋渡しをしたい方には、シネマティックなAI動画生成が、クリエイティブワークフローにおける強力な次のステップを提供します。
メディアとエンターテインメント
メディア制作では、ストーリーボード、コミックのコマ、複数エピソードのプロジェクトのいずれにおいても一貫性が鍵となります。Qwen Image 2.0の統合設計は、シーンをまたいでキャラクターやビジュアルの一貫性を保ち、まとまりのある物語を維持しやすくします。たとえばクリエイターは、ベースとなるシーンを生成してから、キャラクターのポーズなどの細部を調整したり、夜の街並みといった特定のムードに合わせて背景を変えたりできます。
このモデルは、12コマの編集グリッドや複数ページのストーリーボードといった複雑なレイアウトも、すべて1つのプロンプトで処理します。これにより、スピードと柔軟性が重要となるプリプロダクションのワークフローに最適なツールとなります。さらに、英語版と中国語版の両方が必要な映画ポスターのようなローカライズメディアのリリースでは、バイリンガルテキスト描画により両方のバージョンを一度に効率よく制作できます。
業界をまたぐQwen Image 2.0の汎用性は、多様なクリエイティブニーズに正確かつ容易に応える能力を際立たせています。
Qwen Image 2.0をマルチモーダルAIワークフローに統合する
マルチモーダルAIシステムにおけるQwen Image 2.0
Qwen Image 2.0の7Bパラメータアーキテクチャは、マルチモーダルAIワークフローを簡素化するように設計されています。画像生成と編集を1つのモデルに統合することで、複数のツールが不要になります。1回のAPI呼び出しでテキストプロンプトを受け取り、完成した編集可能な画像へと変換できるため、複雑さと処理時間の両方を削減できます。
このモデルのデュアルエンコーダ設計はここで重要な役割を果たし、正確なコンテキスト解釈と忠実なビジュアル再構築を保証します [3]。この機能は、同じキャラクターや製品を異なるフレームやシナリオで一貫して登場させる必要がある場合など、ビジュアルの一貫性を維持する必要のあるワークフローで特に役立ちます。
Qwen Image 2.0は、他のAIモダリティともシームレスに連携します。たとえば、大規模言語モデル(LLM)がユーザーの意図を解釈し、詳細なプロンプトをQwen Image 2.0に渡して画像を生成させ、その出力を動画モデルに転送してアニメーション化することができます。これらすべてが単一の統合APIを通じて行えるため、統合がシンプルで効率的になります。
APIMartを通じたQwen Image 2.0へのアクセス
Qwen Image 2.0へのアクセスは、効率的なプロセスを提供するAPIMartを通じて簡単に行えます。開発者は、複数の認証情報やインフラを管理する心配をすることなく、1つのエンドポイントですべてを管理できます。利用を開始するには、無料アカウントと従量課金プランがあれば十分です。設定が完了すれば、APIキーをダッシュボードから直接生成できます。
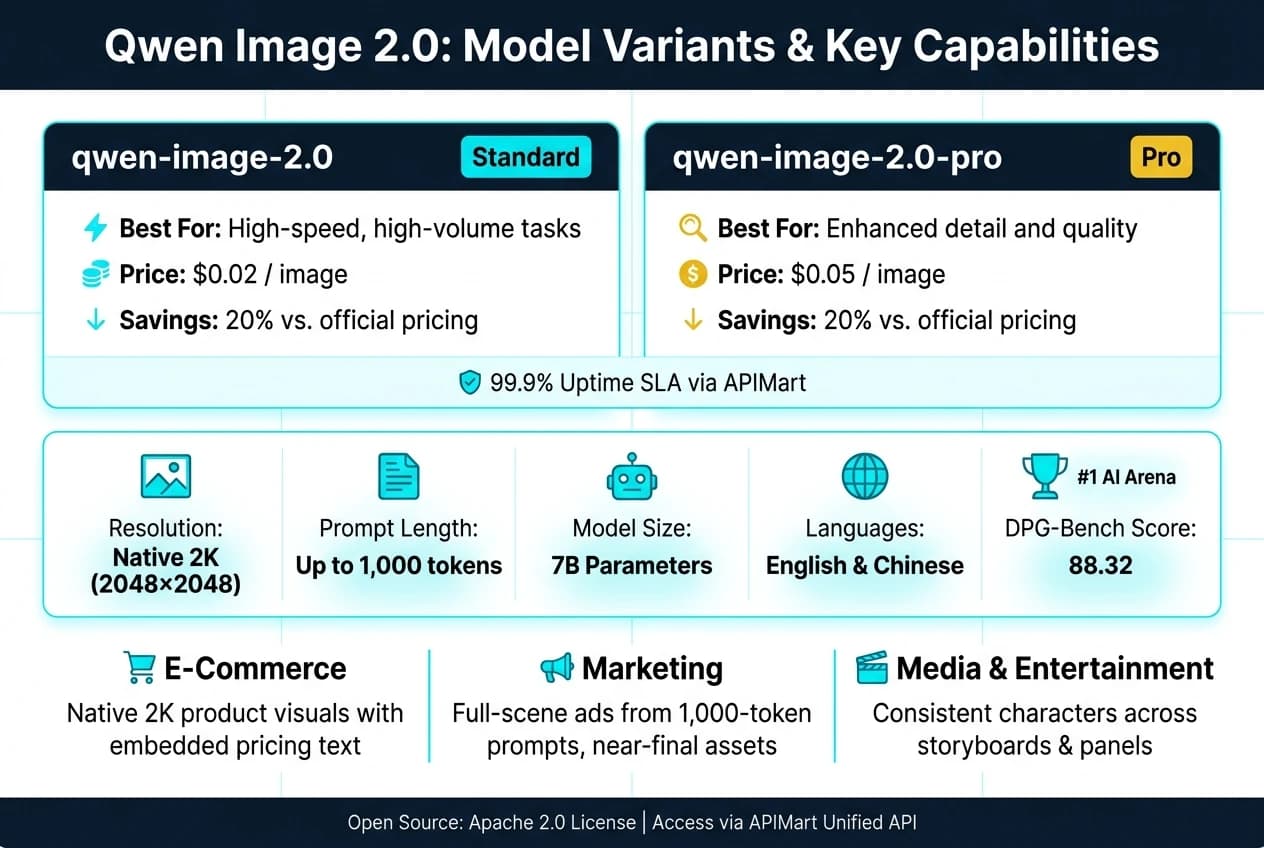
このAPIはOpenAI互換フォーマットを採用しているため、開発者は最小限のコード変更でQwen Image 2.0を既存のプロジェクトに統合できます。さまざまなニーズに合わせて2つのモデルバリアントが用意されています。
| モデルバリアント | 最適な用途 | APIMart価格 | 公式比の割引 |
|---|---|---|---|
qwen-image-2.0 | 高速・大量処理タスク | $0.02/image | 20% [9] |
qwen-image-2.0-pro | より高い精細さと品質 | $0.05/image | 20% [9] |
APIMartはまた、Qwen Image 2.0サービスに対して99.9%の稼働率SLAを保証しています [9]。ただし、API生成された画像URLは24時間しか有効でないため、画像を速やかに保存または転送することが重要です [9]。
ワークフローの活用例
Qwen Image 2.0は、他のモデルと組み合わせることでクリエイティブワークフローを一変させることができます。代表的なユースケースは、LLM(例:Qwen-Plus)と組み合わせてプロンプト生成を効率化することです。たとえば、LLMは「a product shot on a white background」のような基本的なプロンプトを、詳細な1,000トークンの記述へと拡張できます。この拡張されたプロンプトをQwen Image 2.0に入力すれば、手動調整を必要とせずに洗練された画像が生成されます。あるいは、組み込みのprompt_extendパラメータ(デフォルトで有効)が、この最適化を自動的に処理することもできます [4][10]。
製品カタログやストーリーボードのように、複数の関連画像を必要とするプロジェクトでは、参照画像入力機能がすべての出力でビジュアルの一貫性を保証します。大量処理のシナリオでは、タイムアウトを防ぐために非同期タスク処理も利用できます。タスクを送信してタスクIDを受け取り、後で完成結果を確認するだけです [9]。
Qwen Image 2.0を使うためのベストプラクティス
Qwen Image 2.0は、画像生成と編集を1つのツールに統合し、ビジュアルの作成と仕上げをより簡単にします。以下のヒントは、その機能を最大限に引き出すのに役立ちます。
効果的なプロンプトの書き方
結果の品質は、プロンプトをどのように構成するかに大きく左右されます。Qwen Image 2.0は最大1,000トークンに対応しており、非常に詳細な記述が可能です。
良い出発点となる公式は主題+設定+スタイルです。さらに洗練させるには、カメラの種類、雰囲気、ディテールのレベルといった修飾語を加えられます。たとえば「a coffee shop」のような曖昧なプロンプトの代わりに、次のように書いてみましょう。"a cozy corner coffee shop at dusk, shot with a wide-angle lens, warm amber lighting, shallow depth of field, photorealistic style."
さらに2つのヒントが結果の向上に役立ちます。
- 画像内に描画したいテキストには、二重引用符を使うこと。これによってタイポグラフィエンジンが起動します。
- 歪んだ手足、ぼやけたテキスト、過剰な彩度といった望ましくないアーティファクトを避けるために、ネガティブプロンプトを追加すること。
"The 1000 token context window finally allows for truly descriptive scene layouts that actually stick. It's the first model I've used that doesn't forget the second half of my prompt." - tech_lead_2025, Hacker News
マルチパネルデザインのような複雑なレイアウトでは、_"bottom-right quadrant"や"three-column layout"_といった空間的な用語を使って要素を正確に配置しましょう。
短いアイデアを扱っている場合、次のステップでは言語モデルを使ってそれらを拡張する方法を紹介します。
LLMを使ってプロンプトを拡張する
Qwen Image 2.0にはprompt_extendパラメータが備わっており、簡単なアイデアを詳細な1,000トークンの記述へと自動的に変換できます。これを有効にすると、言語モデルが拡張を代わりに処理します。より細かく制御したい場合は、この機能を無効にしてプロンプトを手動で調整できます。
高度なワークフローでは、テキスト画像生成タスクにはQwen-Plusを、編集にはQwen-VL-MaxをQwen Image 2.0と組み合わせることを検討してください。これらのツールはプログラム的にプロンプトを書き換えられるため、一貫性が鍵となる本番パイプラインで特に役立ちます。
Qwenチームは、安定性のためのプロンプト書き換えの重要性を強調しています。
"We have observed that editing results may become unstable if prompt rewriting is not used. Therefore, we strongly recommend applying prompt rewriting to improve the stability of editing tasks." - Qwen Team, GitHub README
詳細なプロンプトを作成したら、次のステップは反復的な編集を通じて結果を微調整しレビューすることです。
反復的な編集と品質レビュー
Qwen Image 2.0では、ベース画像を生成し、同じモデル内で編集コマンドを使ってそれを仕上げることができます。最良の結果を得るには、一度に1つの変数(例:照明、背景、特定のオブジェクト)を調整しましょう。このアプローチは変更を予測可能に保ち、各調整に対してモデルがどう反応するかを理解する助けになります。
人物やブランドキャラクターを含む画像を編集する際は、元の画像と望む変更との関係を明確に定義しましょう。たとえば_"Keep the person from image 1 but change their jacket to navy blue"_のようなプロンプトは、その人物のアイデンティティを保ちつつ特定のディテールを変更することを保証します。
特にマーケティングやEコマースのような用途では、人によるレビューが依然として不可欠です。よく構成されたプロンプトであっても、モデルがアイデンティティのずれやレイアウトの問題といった軽微な不整合を時折生じさせることがあります。ブランドとの整合性、テキストの正確さ、全体的なビジュアルの明瞭さを必ず再確認してください。
最後に、生成された画像URLは24時間後に期限切れになることを念頭に置いてください。作成後はすぐにアセットをダウンロードして保存し、失わないようにしましょう。
まとめ
Qwen Image 2.0は、本番作業に非常に実用的な機能を兼ね備えています。ネイティブ2K解像度、生成と編集の統合システム、英語と中国語の両方でのプロフェッショナルレベルのタイポグラフィ、そして最大1,000トークンのプロンプトを処理する能力です。これらすべてを7Bパラメータモデルで実現しており、これは20Bの前モデルの約3分の1のサイズでありながら、さらに優れた結果を出すことに成功しています。
マルチモーダルワークフローでこのモデルを際立たせるのは、精度と効率の両立です。このモデルはDPG-Benchで88.32のスコアを達成し、テキスト画像生成と画像編集の両タスクでAI Arenaリーダーボードの第1位を獲得しました [2][5]。これらは単なる抽象的な数字ではなく、インフォグラフィック作成、製品撮影、ブランドコンテンツといった分野での実用的なパフォーマンスを反映しています。
"It feels more like a tool for designers rather than just a random art generator." - Automatio.ai [7]
クリエイティブワークフローにAIを統合しようとするチームにとって、Qwen Image 2.0は複数の専用ツールへの依存を減らすことでプロセスを簡素化します。ベース画像の作成、自然言語による編集、正確なテキストオーバーレイの追加、そして印刷可能な品質でのエクスポートを、すべて1つのプラットフォーム内で行えます。さらに、他の500以上のAIモデルに接続するAPIMartの統合API経由でアクセスできるため、ワークフローを効率的かつスケーラブルに保てます。
バイリンガルコンテンツ、複雑なレイアウト、または大規模な画像制作を伴うプロジェクトであれば、Qwen Image 2.0はツールキットに加えることを検討すべき強力な選択肢です。
よくある質問
Qwen Image 2.0を自社のサーバーで実行できますか?
Qwen Image 2.0はローカルデプロイには対応していません。代わりに、モデルの重みは非公開のまま、API経由でアクセスするように設計されています。Alibaba CloudのModel Studioや、その他のマネージドAPIプロバイダーを通じて利用できます。アクセスはDashScopeのようなエンドポイントを介して行われ、これらが画像生成や編集といったタスクを処理します。
複数の画像でキャラクターや製品の一貫性を保つにはどうすればよいですか?
Qwen Image 2.0は統合アーキテクチャを採用しており、単一のモデル内で画像の作成と編集をシームレスに行えます。まず、ベース画像を生成し、その後シンプルな自然言語プロンプトを使って仕上げていきます。たとえば、_色の調整_や_背景の変更_といった変更を要求できます。
アイデンティティの一貫性を保つことが重要な場合は、一度に1つの変数を調整するのが最善です。さらに、編集を正確に制御するには、prompt_extend: falseを設定することでスマートなプロンプト書き換え機能を無効にできます。これにより、モデルが不要な調整を加えることなく、あなたの指示に忠実に従うようになります。
画像内に完璧な英語・中国語のテキストを入れる最良の方法は何ですか?
Qwen Image 2.0は、英語と中国語の両方で正確なテキストを作成するために設計された最先端のAIモデルです。バイリンガルコンテンツ、複雑なレイアウト、さらには中国語の書道の扱いにも優れています。
最良の結果を得るには、最大1,000トークンの詳細なプロンプトを提供してください。これらのプロンプトは、望むレイアウト、タイポグラフィ、テキストの階層を明確に示すべきです。このモデルはまた、遠近感や照明に合わせて調整しながら、さまざまな表面にテキストをシームレスに配置することを保証します。これにより追加の後処理の手間がなくなり、時間と労力を節約できます。
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。