
GPT-Image-2 프롬프트 완벽 가이드 · DALL·E 3, SDXL 비교
GPT-Image-2 멀티모달 프롬프트의 6블록 구조, 최대 16개 참조 이미지, 99% 다국어 텍스트 렌더링 정확도를 DALL·E 3, Stable Diffusion XL과 비교해 자세히 정리했습니다.
GPT-Image-2는 OpenAI가 2026년 4월 21일 공개한 최신 멀티모달 모델입니다. DALL·E 3 같은 기존 도구와 달리, 텍스트 이해와 이미지 생성을 한 시스템 안에서 함께 처리하기 때문에 다국어 텍스트 렌더링, 공간 레이아웃, 복잡한 프롬프트 처리 등 작업에서 정확도가 더 높습니다. 핵심 특징은 다음과 같습니다:
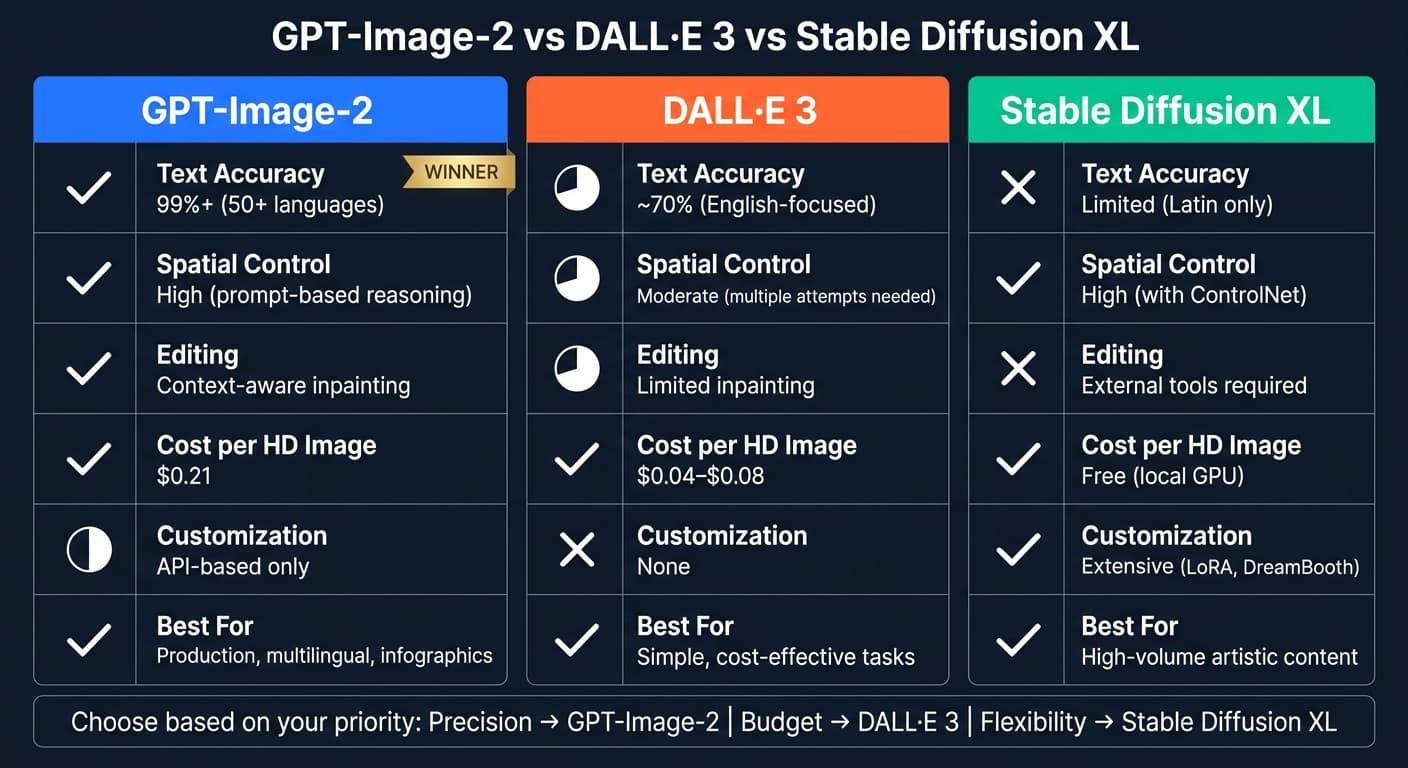
- 텍스트 렌더링: 50개 이상 언어에서 99% 정확도, DALL·E 3와 Stable Diffusion XL을 크게 앞섭니다.
- 공간 제어: "top-center", "bottom-right" 같은 명확한 위치 표현으로 요소 배치를 정밀하게 제어합니다.
- 편집 도구: 타깃 인페인팅으로 전체 이미지를 흔들지 않고 국소 영역만 수정할 수 있습니다.
- 프롬프트 유연성: 한 번에 최대 32,000 토큰과 16장의 참조 이미지를 처리하며, AI 모델 마켓플레이스에서 바로 사용할 수 있습니다.
DALL·E 3나 Stable Diffusion XL보다 비싸지만, GPT-Image-2는 정밀도에서 대체 불가의 강점을 갖춰 인포그래픽, 다국어 디자인, 복잡한 구도 같은 프로덕션 작업에 특히 잘 맞습니다. 다만 생성 속도가 느리고 가격이 높다는 점은 모든 프로젝트에 적합하지는 않습니다.
빠른 비교:
| 항목 | GPT-Image-2 | DALL·E 3 | Stable Diffusion XL |
|---|---|---|---|
| 텍스트 정확도 | 99%+ (다국어) | ~70% (영어 중심) | 제한적 (라틴 문자만) |
| 공간 제어 | 높음 (프롬프트 기반) | 중간 | 높음 (ControlNet 결합 시) |
| 편집 | 컨텍스트 인식 편집 | 제한된 인페인팅 | 외부 도구 필요 |
| 비용 | $0.21 (HD 이미지) | $0.04–$0.08 | 로컬은 무료 |
| 커스터마이즈 | API 전용 | 없음 | 매우 높음 (로컬 파인튜닝) |
정밀도가 중요한 작업에는 GPT-Image-2가 최선입니다. DALL·E 3는 단순하고 비용에 민감한 용도에, Stable Diffusion XL은 기술력을 갖춘 사용자에게 적합합니다.
GPT Image 2 출시 — 꼭 알아야 할 것들
1. GPT-Image-2
GPT-Image-2는 그리기 전에 먼저 사고하도록 설계된 자연어 모델입니다. 이미지를 만들기 전에 구도를 계획하고 공간적 충돌을 해결합니다. Pixo Blog는 이렇게 설명합니다:
"GPT-Image-2는 키워드 매칭 엔진이 아니다. O 시리즈 추론이 얹힌 자연어 모델이다." [7]
바로 이 특별한 능력 덕분에 프롬프트 설계가 특히 중요한 모델입니다.
프롬프트 구조
모델의 추론력을 뒷받침하는 것이 잘 설계된 프롬프트 구조입니다. 가장 효과적인 프롬프트는 6블록 프레임워크를 따릅니다: Subject(주체), Action(동작), Scene(장면), Composition(구도), Lighting(조명), Style(스타일). 프롬프트를 한 편의 크리에이티브 브리프라고 생각해야 합니다. 통합 LLM API는 한 번에 최대 32,000 토큰을 처리할 수 있지만, 실제로는 100–300 단어 범위가 가장 좋은 결과를 냅니다. [7]
다중 이미지 작업에서는 한 프롬프트에 최대 16장의 참조 이미지 를 사용할 수 있습니다. 각 이미지에 인덱스로 명확한 역할을 지정하세요. 예를 들어 "Image 1: subject identity, Image 2: color style" 처럼 적으면, 모델이 각 소스의 요소를 제대로 통합합니다. [7][9]
텍스트 렌더링
GPT-Image-2는 영어, 스페인어, 독일어, 프랑스어, 일본어, 간체 및 번체 중국어, 한국어 등 여러 언어의 텍스트 렌더링에 강합니다. [9] 텍스트를 넣을 때는 큰따옴표로 감쌉니다(예: "30% OFF"). 영어가 아닌 단어는 "ZEITGEIST (Z-E-I-T-G-E-I-S-T)" 처럼 한 글자씩 풀어 적으면, 정확도가 약 99% 까지 올라갑니다. [7]
다만 '텍스트 금지' 같은 지시가 없으면 약 60%의 이미지 에 의도하지 않은 글자가 섞입니다. 이를 막으려면 프롬프트 끝에 "No extra text, no additional words, no watermarks." 같은 지시를 꼭 넣어야 합니다. [7]
공간 제어
레이아웃 측면의 공간 제어도 정밀합니다. 요소가 셋을 넘는 장면에서는 Thinking Mode 를 켜는 것이 좋습니다. 렌더링 전에 10–30초 계획 시간이 주어지면서 레이아웃 정확도가 크게 향상됩니다. [7] "top-center", "bottom-right," "along the left margin" 처럼 명시적인 위치 표현을 쓰면, 대상과 텍스트를 정확한 자리에 배치할 수 있습니다. CreateVision AI의 AI 모델 리서치 리드 Marcus Rivera는 이 모델이 "제목 없는 4열 결과 대신, 충돌하는 제약을 첫 시도에서 합리적으로 해결한다" 고 평가합니다. [9]
편집 능력
결과물을 다듬기 위해, GPT-Image-2는 Edits API 엔드포인트(v1/images/edits)를 통해 타깃 인페인팅 을 지원합니다. 특정 영역을 선택해 "fix a typo" 또는 "swap a product." 같은 지시를 보낼 수 있습니다. [7][8] 최상의 결과를 얻으려면 바뀌면 안 되는 부분을 명시적으로 지정하세요. 예: "change only the background, keep the subject and lighting the same." 편집 회차를 3회 이내로 제한하면 노이즈 누적과 이미지 품질 저하를 막을 수 있습니다. [7]
2. DALL·E 3

DALL·E 3는 GPT-4를 활용해 프롬프트를 확장·재작성한 뒤 이미지를 생성합니다. Enter Pro의 설명은 이렇습니다:
"DALL·E 3 자체는 독립된 확산 모델이었다. OpenAI가 그것을 외부 도구로 ChatGPT에 연결했고, GPT-4가 확장 프롬프트를 작성하면 DALL·E 3가 별도로 렌더링하는 구조였다." [4]
이 두 단계 처리는 종종 '의도 표류(intent drift)'를 일으켜, 최종 이미지가 원래 요청과 완전히 일치하지 않을 수 있습니다. 확장된 프롬프트가 사용자 의도의 미묘한 부분을 놓치면, 제어성과 정확도 모두에 영향이 갑니다.
프롬프트 구조
GPT-4가 프롬프트를 자동 확장해 주므로 DALL·E 3는 더 짧고 대화적인 입력으로도 동작합니다. 다만 그 대가로 창작 제어성이 떨어집니다. 예를 들어 멀티이미지 조합은 지원하지 않으며, 이는 GPT-Image-2가 제공하는 기능입니다 [10].
텍스트 렌더링
DALL·E 3의 두드러진 약점이 텍스트 렌더링으로, 정확도는 약 70%에 그칩니다. 긴 문자열이나 비라틴 문자에서 자주 실패합니다. Lensgo 팀은 이렇게 지적합니다:
"DALL·E 3의 가장 큰 약점은 읽을 수 있는 텍스트였다. 'Summer Sale 50% Off' 가 적힌 포스터를 요청하면, 'Sumnner Sal 50% Of' 같은 결과를 돌려주곤 했다." [10]
이 때문에 포스터, 제품 라벨, 다국어 디자인 등 정밀한 텍스트가 필요한 작업에는 신뢰하기 어렵습니다.
공간 제어
DALL·E 3는 프롬프트의 서술적 표현으로 공간 배치를 제어합니다. 어느 정도는 잘 동작하지만, 정밀한 배치를 노리면 재생성을 여러 번 거쳐야 하고, 시간과 비용이 늘어납니다 [5]. GPT-Image-2의 더 정확한 레이아웃 능력과는 차이가 큽니다.
편집 능력
DALL·E 3의 편집은 인페인팅 구현 방식에 묶여 있습니다. 선택 영역을 재생성할 때 주변 부위가 의도치 않게 함께 바뀌는 일이 잦습니다. 예를 들면:
"사진을 올리고 '모자를 레드 벨벳으로 바꿔달라' 고 하면, DALL·E 3는 이미지 전체를 다시 생성하곤 하고 얼굴이 달라져 돌아온다." [10]
피사체 잠금, input_fidelity 조정, 투명 배경 기본 지원 같은 기능이 없어 수동 보정이 필수입니다. 가격은 표준 1024×1024 이미지 $0.04, 고해상도 $0.08로 GPT-Image-2보다 저렴하지만, 이런 한계 때문에 반복 작업이 필요한 프로덕션 태스크에는 적합도가 떨어집니다 [4].
2026년 4월부터 DALL·E 3는 ChatGPT 인터페이스에서 제거되고 GPT-Image-2로 교체되었습니다. 레거시 API 엔드포인트도 2026년 하반기에 단종될 예정입니다 [2].
3. Stable Diffusion XL
SDXL은 GPT-Image-2 와 DALL·E 3 같은 API 기반 도구의 사용자 주도형 대안입니다. 로컬 GPU나 클라우드 서비스에서 운용할 수 있는 오픈소스 파운데이션 모델 로, 매니지드 API에 프롬프트만 넘기는 방식에 비해 훨씬 큰 제어권을 제공합니다 [11].
프롬프트 구조
내장 추론 레이어가 있는 모델과 달리, SDXL은 명시적 토큰과 가중치 조정에 전적으로 의존해 결과를 만듭니다. 따라서 프롬프트 정확도가 매우 중요합니다. 특정 스타일이나 캐릭터를 재현하려면 LoRA 나 DreamBooth 같은 도구로 파인튜닝할 수 있습니다 [12].
텍스트 렌더링
텍스트 렌더링에서는 분명한 한계가 있습니다. 짧은 라틴 문자는 처리할 수 있지만, 긴 문자열, 비라틴 문자, 정확한 타이포그래피에서는 약합니다. GPT-Image-2의 다국어 텍스트는 거의 완벽한 정확도라, SDXL이 그 수준에 도달하려면 외부 파인튜닝이 필수입니다 [11].
공간 제어
SDXL은 특히 ControlNet 과 결합하면 강력한 공간 제어를 보여줍니다. 깊이 맵, 포즈 스켈레톤, 에지 검출 데이터를 입력해 구도를 정밀하게 설계할 수 있습니다 [11]. 다만 ControlNet 없이는 복잡한 레이아웃에서 흔들립니다.
"헤드라인 다섯 줄이 들어간 잡지 표지나, 라벨 달린 화살표가 있는 4컷 인포그래픽을 그려보라고 하면 무너진다. 텍스트가 깨지고 라벨이 사라지고 레이아웃이 붕괴한다." - BestPhoto 팀 [3]
편집 능력
SDXL의 편집은 인페인팅, 아웃페인팅, LoRA 스왑, ControlNet 오버레이 같은 외부 도구에 전적으로 의존합니다 [12]. 강력한 결과를 얻을 수 있지만 학습 곡선이 가파릅니다 — Python 환경, GPU 드라이버, 모델 가중치를 직접 관리해야 해 진입 장벽이 높습니다. 한편 프라이버시 민감 또는 브랜드 전용 출력 을 중시하는 팀에게는 SDXL의 로컬 처리가 큰 장점입니다. 그 외 팀에는 기술적 부담이 이점을 압도할 수 있습니다 [11].
| 항목 | Stable Diffusion XL | GPT-Image-2 |
|---|---|---|
| 공간 제어 | 높음 (ControlNet, 깊이 맵) [11] | 중간 (프롬프트 기반) [11] |
| 커스터마이즈 | 높음 (LoRA, DreamBooth) [11] | 낮음 (API 전용, 파인튜닝 불가) [11] |
| 텍스트 렌더링 | 평균 (라틴 문자 중심) [3] | 99%+ 정확도, 다국어 [3] |
| 편집 방식 | 인페인팅, 마스크, ControlNet [12] | 자연어 지시 [12], Flux 2 API 와 유사 |
| 프라이버시 | 높음 (로컬 처리) [11] | 중간 (OpenAI 서버) [11] |
| 비용 | 로컬은 무료 (GPU 필요) [11] | 이미지당 약 $0.04–$0.35 [11] |
장단점
각 AI 모델은 고유한 강점과 약점을 가지며, 잘 맞는 작업도 다릅니다.
| 모델 | 강점 | 약점 |
|---|---|---|
| GPT-Image-2 | 50개 이상 언어 텍스트 렌더링이 탁월; 추론으로 레이아웃 설계; 최대 16장 참조 이미지로 컨텍스트 인식 편집 [9] | 생성 속도가 느림(표준 30–60초, Thinking 모드는 최대 149초); 비용이 높음(HD 이미지 약 $0.21); 정밀한 상표 로고 재현에 약함 [1] |
| DALL·E 3 | 사용하기 쉬움; 단순한 장면에서는 프롬프트를 잘 따름; 저렴한 가격($0.04–$0.08/장) [4] | 긴 문자열의 텍스트 렌더링이 불안정; 프롬프트에서 벗어나기 쉬움; 여러 이미지에서 일관성이 떨어짐 [4] |
| Stable Diffusion XL | 로컬은 무료; LoRA와 ControlNet으로 깊은 커스터마이즈 가능; 아트 스타일 대량 생산에 적합 [12] | 파인튜닝 없이는 텍스트 렌더링 약함; 복잡한 레이아웃에 약함; 기술적 셋업 부담이 큼(Python, GPU 드라이버, 모델 가중치) [12] |
이 표는 비용, 정확도, 유연성 사이의 트레이드오프를 잘 보여줍니다.
비용을 비교하면, GPT-Image-2 는 DALL·E 3 보다 약 5배, 클라우드에서 돌리는 Stable Diffusion XL 보다도 4배 이상 비쌉니다. 그러나 이 가격에는 고도화된 추론, 거의 완벽한 다국어 텍스트 정확도, AI Canvas 를 활용한 편집의 최상위 퍼포먼스가 포함돼 있습니다.
"GPT-Image-2는 정보 밀도 높은 구성을 안정적으로 처리하는 최초의 광범위 사용 가능한 모델이다. 그리고 추론 단계를 도입한 첫 모델이기도 하다." - BestPhoto 팀 [3]
인포그래픽이나 다국어 프로젝트를 진행하는 팀이라면, GPT-Image-2 의 정밀도가 더 높은 비용과 다소 느린 처리 시간을 충분히 상쇄합니다. Stable Diffusion XL 은 로컬 처리와 이미지당 사실상 0원이라는 강점으로 아트 스타일 중심의 창작 프로젝트에 합리적인 선택입니다. DALL·E 3 는 균형형 옵션 — 저렴하고 빠르지만 정밀도가 필요한 태스크에는 덜 안정적입니다. 비용과 품질의 균형을 원한다면 GPT-4o Image API 도 멀티모달 생성을 위한 고성능 대안으로 검토할 만합니다.
결론
올바른 모델은 결국 프로젝트의 구체적 요구에 따라 결정됩니다. GPT-Image-2 는 정밀도가 요구되는 프로덕션 워크플로에서 두각을 나타냅니다. 제품 라벨, UI 목업, 다국어 포스터, 또는 프레임 전반에 걸쳐 캐릭터 일관성이 필요한 캠페인 등 어떤 작업이든 뛰어난 다국어 텍스트 정확도와 일관된 추론을 제공합니다. 정밀도가 협상 불가능한 프로젝트라면 유력한 후보입니다.
반면 DALL·E 3 는 텍스트 정확도가 핵심이 아닌, 일회성 아트 일러스트 제작에 잘 어울립니다. Stable Diffusion XL 은 대량의 스타일 위주 출력을 다루며 그 기능을 최대로 끌어낼 기술력이 있는 팀에 이상적입니다. 고급 기능 덕분에 복잡하고 까다로운 프로젝트에서는 투자할 가치가 충분합니다.
결정을 내릴 때는 실무 배포 요인도 놓치지 마세요. 여러 API 키와 결제 계정을 관리하면 프로덕션 워크플로가 복잡해집니다. APIMart 같은 도구는 단일 통합 API로 GPT-Image-2를 포함한 500개 이상의 AI 모델을 제공해, 관리 부담을 줄여 결과 전달에 집중할 수 있게 해 줍니다.
"(GPT-Image-2로의) 업그레이드는 GPT-3에서 GPT-5로의 도약에 견줄 만하다." - Sam Altman, OpenAI CEO [6]
GPT-Image-2를 핵심 워크플로에 도입하면, 산출물의 품질과 일관성을 크게 끌어올릴 수 있습니다.
자주 묻는 질문
좋은 GPT-Image-2 프롬프트를 어떻게 작성하나요?
좋은 GPT-Image-2 프롬프트의 핵심은 명확성과 구조입니다. 모델에 전달하는 상세한 크리에이티브 브리프라고 생각하세요. 먼저 원하는 비주얼 스타일 을 지정합니다 — "cinematic", "watercolor" 같은 식으로 톤을 잡습니다.
다음으로 조명, 환경, 레이아웃에 대해 구체적으로 묘사합니다. 예를 들어 "방"이라고 쓰는 대신, "큰 베이 윈도우로 따뜻한 자연광이 들어오는 아늑한 거실"이라고 쓰세요. 구체적일수록 모델이 의도를 더 잘 해석합니다.
라벨이나 UI 요소처럼 텍스트를 포함한다면, 정확한 문구를 따옴표로 감싸서 지정합니다. 예를 들어 "버튼 라벨"이라고만 쓰지 말고 "Press Start"라고 적습니다.
마지막으로 모호한 문구나 서로 관련 없는 키워드를 늘어놓는 것을 피하세요. 명확하고 묘사력 있는 언어로 모델을 이끌어야 고품질 결과가 나옵니다.
이미지에 의도치 않은 텍스트가 나오지 않게 하려면?
GPT-Image-2가 생성한 이미지에서 원치 않는 글자를 줄이려면 명확하고 정밀한 프롬프트 가 중요합니다. 지시는 구체적이고 자세하게, 모호하거나 단순한 표현은 피하세요. 잘 구성된 프롬프트는 시각적 잡티를 크게 줄이고 필요한 텍스트의 가독성을 유지합니다. 프롬프트 엔지니어링 모범 사례를 지킨다면 결과 품질이 눈에 띄게 향상됩니다.
레이아웃에서 Thinking Mode는 언제 사용해야 하나요?
레이아웃에 Thinking Mode 를 켜면, 모델은 이미지를 생성하기 전에 구도, 계층, 제약을 먼저 계획합니다. 이 방식은 모델에 디자인과 레이아웃을 충분히 추론할 시간을 주어, 최종 렌더링이 더 구조적이고 정돈된 형태로 나오게 합니다.
관련 글
모델 마켓에서 원하는 모델을 선택하세요
APIMart 모델 마켓에서 채팅, 이미지, 비디오 모델을 사용해 보고 하나의 통합 API로 모델 기능을 빠르게 경험하세요.