
GPT-Image-2 · промпты, сравнение с DALL·E 3 и SDXL
Разбираем мультимодальные промпты GPT-Image-2 — шестиблочную структуру, до 16 референсов и 99% точность многоязычного текста. Сравнение с DALL·E 3 и SDXL.
GPT-Image-2 — это новейшая мультимодальная модель от OpenAI, выпущенная 21 апреля 2026 года. В отличие от предыдущих инструментов вроде DALL·E 3, она объединяет понимание текста и генерацию изображений в одной системе. Это даёт более высокую точность в многоязычном рендеринге текста, пространственных раскладках и обработке сложных промптов. Ключевые особенности:
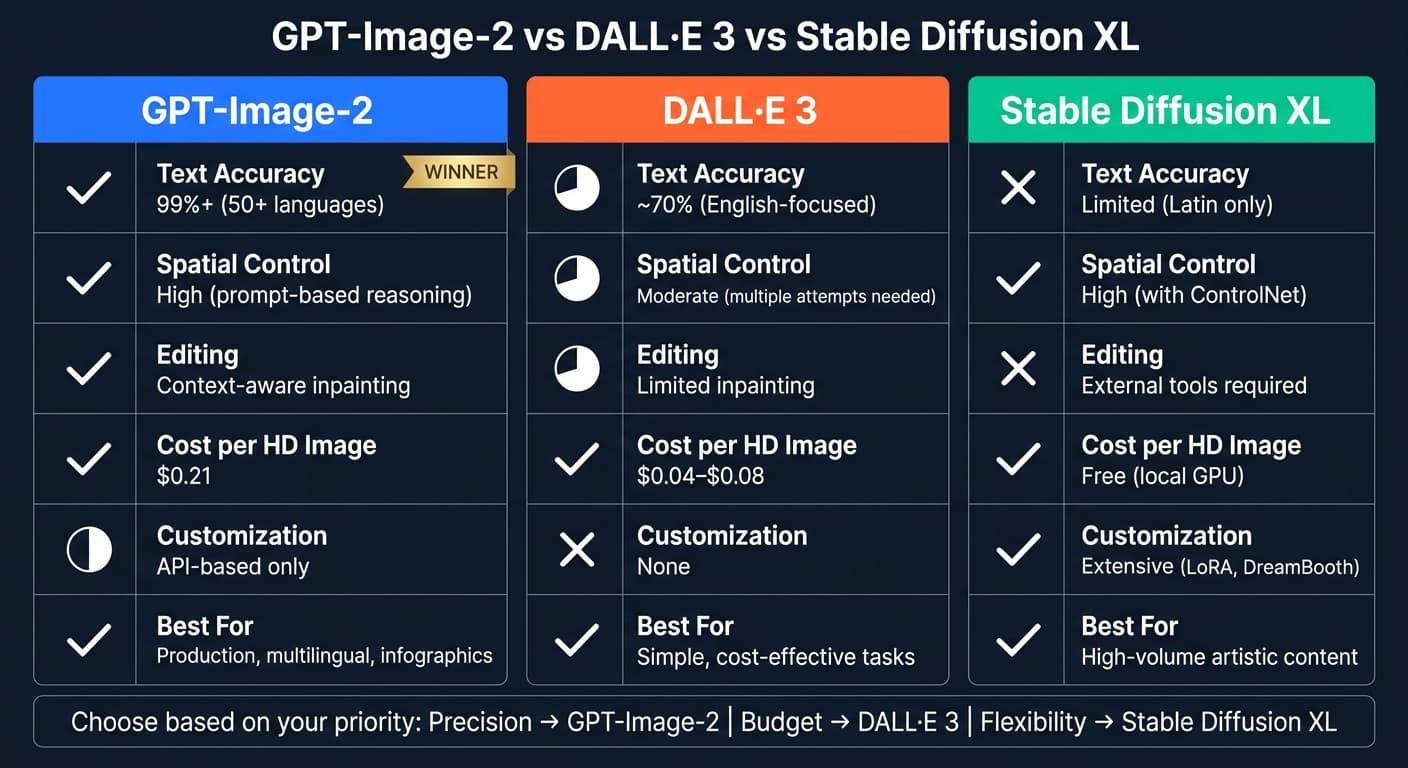
- Рендеринг текста: 99% точности на 50+ языках, заметно опережает DALL·E 3 и Stable Diffusion XL.
- Пространственный контроль: Точное размещение объектов через выражения вроде "top-center" или "bottom-right".
- Инструменты редактирования: Тактическая инпейнтинг-правка для точечных изменений без перерисовки всей картинки.
- Гибкость промптов: До 32 000 токенов и до 16 референсных изображений за один запрос, доступно через маркетплейс AI-моделей.
Хотя цена выше, чем у DALL·E 3 и Stable Diffusion XL, GPT-Image-2 даёт несравнимую точность для продакшен-задач: инфографики, многоязычные дизайны, сложные композиции. С другой стороны, более медленная генерация и более высокая стоимость подходят не каждому проекту.
Быстрое сравнение:
| Параметр | GPT-Image-2 | DALL·E 3 | Stable Diffusion XL |
|---|---|---|---|
| Точность текста | 99%+ (многоязычно) | ~70% (упор на английский) | Ограниченно (только латиница) |
| Пространственный контроль | Высокий (через промпт) | Средний | Высокий (с ControlNet) |
| Редактирование | С учётом контекста | Ограниченный inpainting | Нужны внешние инструменты |
| Стоимость | $0.21 (HD-изображение) | $0.04–$0.08 | Бесплатно локально |
| Кастомизация | Только через API | Нет | Высокая (локальный fine-tuning) |
Для задач, где важна точность, GPT-Image-2 — лучший выбор. DALL·E 3 подходит для простых и экономичных задач, а Stable Diffusion XL — для технически подкованных пользователей.
GPT Image 2 уже здесь — всё, что нужно знать
1. GPT-Image-2
GPT-Image-2 — это языковая модель, спроектированная думать критически: до создания изображения она планирует композицию и разрешает пространственные конфликты. Pixo Blog объясняет так:
«GPT-Image-2 — это не движок сопоставления ключевых слов. Это языковая модель с надстроенным сверху reasoning серии O.» [7]
Именно эта способность делает её промпт-архитектуру особенно интересной.
Структура промпта
Способности модели к рассуждению дополняются хорошо продуманной структурой промпта. Самые эффективные промпты строятся по «шестиблочному» каркасу: Subject (объект), Action (действие), Scene (сцена), Composition (композиция), Lighting (свет), Style (стиль). Воспринимайте промпт как творческий бриф. Unified LLM API поддерживает до 32 000 токенов, но лучшие результаты дают промпты длиной 100–300 слов. [7]
Для мультиграфических задач GPT-Image-2 принимает до 16 референсных изображений в одном промпте. Назначайте каждому изображению чёткую роль через индекс — например, «Image 1: subject identity, Image 2: color style» — чтобы модель корректно сочетала элементы из разных источников. [7][9]
Рендеринг текста
GPT-Image-2 силён в рендеринге текста на множестве языков: английский, испанский, немецкий, французский, японский, упрощённый и традиционный китайский, корейский. [9] Чтобы добавить текст, заключайте его в двойные кавычки (например, "30% OFF"). Неанглийские слова лучше прописывать побуквенно, как "ZEITGEIST (Z-E-I-T-G-E-I-S-T)" — это поднимает точность примерно до 99%. [7]
Однако без явной инструкции «без текста» примерно на 60% изображений появляются непредусмотренные надписи. Чтобы этого избежать, всегда заканчивайте промпт указанием вроде «No extra text, no additional words, no watermarks.» [7]
Пространственный контроль
GPT-Image-2 также обеспечивает точный пространственный контроль раскладки. Включение Thinking Mode для сцен с более чем тремя элементами улучшает точность за счёт того, что модель тратит 10–30 секунд на планирование перед рендерингом. [7] Явные позиционные термины — «top-center», «bottom-right», «along the left margin» — гарантируют правильное размещение объектов и текста. Marcus Rivera, AI Model Research Lead в CreateVision AI, отмечает, что модель «разумно разрешает противоречивые ограничения с первой попытки, вместо того чтобы выдать четыре колонки без заголовка». [9]
Возможности редактирования
Для доводки результата GPT-Image-2 поддерживает тактический inpainting через эндпоинт Edits API (v1/images/edits). Можно выделить конкретную область и дать инструкцию вроде «fix a typo» или «swap a product». [7][8] Для лучших результатов чётко прописывайте, что должно остаться без изменений, например: «change only the background, keep the subject and lighting the same.» Не более трёх раундов правок — так удаётся избежать накопления шума и деградации качества. [7]
2. DALL·E 3

DALL·E 3 использует GPT-4 для обработки промптов: сначала расширяет и переписывает их, и только затем генерирует изображение. Enter Pro объясняет так:
«DALL·E 3 сама по себе была отдельной диффузионной моделью. OpenAI подключила её к ChatGPT как внешний инструмент: GPT-4 пишет расширенный промпт, а DALL·E 3 рендерит его отдельно.» [4]
Такой двухступенчатый процесс приводит к «дрейфу намерения»: итоговое изображение не всегда точно соответствует исходному запросу. Расширенный промпт иногда теряет тонкости задумки пользователя, что бьёт и по контролю, и по точности.
Структура промпта
Поскольку GPT-4 автоматически расширяет промпты, DALL·E 3 справляется с короткими, разговорными вводами. Но это стоит контроля над творческим процессом. Например, она не поддерживает мульти-изображение в одной композиции — функция, которая есть у GPT-Image-2 [10].
Рендеринг текста
Заметная слабость DALL·E 3 — рендеринг текста с точностью около 70%. С длинными строками и нелатинскими шрифтами она часто буксует. Команда Lensgo отмечает:
«Главной слабостью DALL·E 3 был читаемый текст. Попросите постер с надписью ‘Summer Sale 50% Off’ — и DALL·E 3 вернёт что-то вроде ‘Sumnner Sal 50% Of’.» [10]
Из-за этого она ненадёжна для задач с точным текстом — постеров, этикеток, многоязычных макетов.
Пространственный контроль
DALL·E 3 опирается на описательный язык в промпте для управления размещением. Получается неплохо, но точное позиционирование объекта требует нескольких регенераций — это и долго, и дорого [5]. По сравнению с более аккуратной раскладкой GPT-Image-2 разница ощутима.
Возможности редактирования
Редактирование в DALL·E 3 ограничено самим подходом к inpainting. При регенерации выбранной области соседние части часто меняются непреднамеренно. Пример:
«Если загрузить фото и сказать ‘поменяй шляпу на красный бархат’, DALL·E 3 чаще всего перерисовывает всё изображение, и лицо возвращается уже другим.» [10]
Нет таких функций, как subject-lock, настройка input_fidelity и нативная поддержка прозрачного фона — ручные правки неизбежны. Цена ниже — $0.04 за стандартное изображение 1024×1024 и $0.08 за HD — но из-за этих ограничений модель плохо подходит для итеративных продакшен-задач [4].
С апреля 2026 года DALL·E 3 удалена из интерфейса ChatGPT и заменена на GPT-Image-2. Унаследованный API-эндпоинт также будет отключён позднее в 2026 году [2].
3. Stable Diffusion XL
SDXL выделяется как user-driven альтернатива API-инструментам вроде GPT-Image-2 и DALL·E 3. Это open-source базовая модель, которую можно запускать локально на GPU или через облако — это даёт больше контроля, чем простой вызов managed API с промптом [11].
Структура промпта
В отличие от моделей со встроенным слоем рассуждения, SDXL полностью полагается на явные токены и настройку весов. Поэтому требования к точности промпта высокие. Для воспроизведения конкретного стиля или персонажа SDXL можно дообучить с помощью LoRA или DreamBooth [12].
Рендеринг текста
В рендеринге текста у SDXL есть свои ограничения. С короткими латинскими словами она справится, а вот длинные строки, нелатинские шрифты и аккуратная типографика даются с трудом. GPT-Image-2 даёт почти идеальную точность для многоязычного текста — чтобы SDXL дотянулась до такого уровня, без внешнего fine-tuning не обойтись [11].
Пространственный контроль
SDXL сильна в пространственном контроле, особенно с ControlNet — можно подавать карты глубины, скелеты поз и данные edge detection для точной структуры композиции [11]. Без ControlNet SDXL спотыкается на сложных раскладках.
«Попросите их отрендерить обложку журнала с пятью заголовками или инфографику на четыре панели с подписанными стрелками — и они разваливаются. Текст превращается в кашу. Подписи пропадают. Раскладка рушится.» — команда BestPhoto [3]
Возможности редактирования
Редактирование в SDXL полностью завязано на внешние инструменты: inpainting, outpainting, переключение LoRA, ControlNet-наложения [12]. С их помощью можно добиться впечатляющих результатов, но кривая обучения крутая — придётся самостоятельно следить за окружением Python, драйверами GPU и весами моделей. Однако для команд, которым важна приватность или брендовая уникальность, локальная обработка SDXL — серьёзное преимущество. Для остальных техническая нагрузка может перевесить пользу [11].
| Параметр | Stable Diffusion XL | GPT-Image-2 |
|---|---|---|
| Пространственный контроль | Высокий (ControlNet, карты глубины) [11] | Средний (через промпт) [11] |
| Кастомизация | Высокая (LoRA, DreamBooth) [11] | Низкая (только API, без fine-tuning) [11] |
| Рендеринг текста | Средний (упор на латиницу) [3] | 99%+ точность, многоязычный [3] |
| Метод редактирования | Inpainting, маски, ControlNet [12] | Инструкции на естественном языке [12], как у Flux 2 API |
| Приватность | Высокая (локальная обработка) [11] | Средняя (серверы OpenAI) [11] |
| Стоимость | Бесплатно локально (нужен GPU) [11] | ~$0.04–$0.35 за изображение [11] |
Плюсы и минусы
У каждой AI-модели свой набор сильных и слабых сторон — и под разные задачи подходят разные.
| Модель | Сильные стороны | Слабые стороны |
|---|---|---|
| GPT-Image-2 | Отличный рендеринг текста на 50+ языках; reasoning для планирования раскладки; редактирование с учётом контекста и поддержка до 16 референсов [9] | Медленная генерация (30–60 секунд в стандарте, до 149 секунд в Thinking-режиме); высокая цена (~$0.21 за HD); сложности с точным воспроизведением фирменных логотипов [1] |
| DALL·E 3 | Дружелюбна к пользователю; хорошо следует промптам в простых сценах; ниже по цене ($0.04–$0.08 за изображение) [4] | Непоследовательный рендеринг длинных строк; склонна отклоняться от промпта; страдает консистентность между несколькими изображениями [4] |
| Stable Diffusion XL | Бесплатна локально; гибкая кастомизация через LoRA и ControlNet; подходит для массовой генерации арт-контента [12] | Слабый рендеринг текста без fine-tuning; сложно с замысловатой раскладкой; высокий порог входа (Python, драйверы GPU, веса моделей) [12] |
Таблица наглядно показывает компромиссы между стоимостью, точностью и гибкостью.
По стоимости GPT-Image-2 примерно в пять раз дороже DALL·E 3 и более чем в четыре раза дороже Stable Diffusion XL при облачном запуске. Зато эта цена даёт продвинутый reasoning, почти идеальную точность многоязычного текста и топовую производительность в связке с AI Canvas при редактировании.
«GPT-Image-2 — первая широкодоступная модель, надёжно справляющаяся с насыщенными, информативными композициями. И первая, в которой появилось reasoning-звено.» — команда BestPhoto [3]
Командам, работающим над инфографикой или многоязычными проектами, GPT-Image-2 окупает свою цену и более медленную обработку. Stable Diffusion XL разумен для творческих проектов с упором на художественный стиль благодаря локальной обработке и нулевой стоимости за изображение. DALL·E 3 остаётся сбалансированным вариантом — доступным и быстрым, но менее надёжным там, где важна точность. Если хочется баланса между ценой и качеством, рассмотрите GPT-4o Image API — мощную альтернативу для мультимодальной генерации.
Заключение
Выбор подходящей модели полностью зависит от задач проекта. GPT-Image-2 выделяется в продакшен-процессах, где требуется точность. Будь то этикетки, UI-мокапы, многоязычные постеры или кампании с консистентными персонажами в разных кадрах — модель даёт исключительную точность многоязычного текста и связное reasoning. Это сильный кандидат там, где точностью нельзя жертвовать.
DALL·E 3 хорошо подходит для художественных, разовых иллюстраций, где точность текста не приоритет. Stable Diffusion XL — идеальный выбор для команд, генерирующих большие объёмы стилизованного контента и обладающих экспертизой для раскрытия её возможностей. Её продвинутый инструментарий оправдывает инвестиции для сложных и требовательных проектов.
При принятии решения не забывайте про реалии деплоя. Управление несколькими API-ключами и биллинг-аккаунтами усложняет продакшен. Инструменты вроде APIMart решают это за счёт единого API к 500+ AI-моделям, включая GPT-Image-2 — административной возни меньше, можно сосредоточиться на результате.
«Апгрейд [до GPT-Image-2] сопоставим с переходом от GPT-3 к GPT-5.» — Сэм Альтман, CEO OpenAI [6]
Внедрение GPT-Image-2 в ключевые процессы заметно повышает и качество, и стабильность результата.
Часто задаваемые вопросы
Как написать сильный промпт для GPT-Image-2?
Сильный промпт для GPT-Image-2 начинается с ясности и структуры. Воспринимайте его как развёрнутый творческий бриф для модели. Сначала укажите желаемый визуальный стиль — "cinematic", "watercolor" или иной — это задаёт тон результата.
Затем дайте точные детали про свет, окружение и раскладку. Например, вместо «комната» напишите «уютная гостиная с тёплым естественным светом, проникающим через большие эркерные окна». Чем конкретнее, тем лучше модель считывает замысел.
Если включаете текст — например, подписи или элементы UI — указывайте точные формулировки в кавычках. Лучше "Press Start", чем расплывчатое «надпись на кнопке».
Наконец, избегайте размытых фраз и нагромождения несвязанных ключевых слов. Чёткий описательный язык даёт модели опору и качественный результат.
Как избежать лишнего текста на изображениях?
Чтобы свести непреднамеренные надписи к минимуму, важны чёткие и точные промпты. Инструкции должны быть конкретными и подробными, без размытых или упрощённых формулировок. Хорошо структурированные промпты заметно снижают визуальные артефакты и сохраняют читаемость нужного текста. Следование лучшим практикам prompt engineering ощутимо повышает качество результата.
Когда использовать Thinking Mode для раскладки?
Когда включаете Thinking Mode для раскладки, модель сначала планирует композицию, иерархию и ограничения, и только затем генерирует изображение. Такой подход даёт модели время аккуратно проработать дизайн и раскладку, поэтому итоговый рендер выходит более структурированным и упорядоченным.
Похожие статьи
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.