
Оптимизация промптов для видео: текст vs изображения
Сравнение text-to-video, image-to-video и гибридного промптинга для генерации AI-видео с рекомендациями по консистентности бренда, творческому контролю, стоимости и качеству.
В генерации AI-видео ваш выбор промпта - text-to-video (T2V) или image-to-video (I2V) - существенно влияет на результат. Вот краткий разбор:
- Text-to-Video: идеально подходит для создания совершенно новых визуалов. Лучше всего годится для мозгового штурма, тестирования концепций или генерации абстрактных сцен. Требует подробных промптов для качественных результатов, но предлагает гибкость.
- Image-to-Video: идеально для сохранения точности. Загрузите статичное изображение, и AI его анимирует. Лучше всего подходит для демонстрации продуктов, брендинга или когда консистентность критична. Ограничено контекстом загруженного изображения.
- Гибридный подход: сочетает оба метода для точности и контроля. Используйте изображение для визуальной консистентности и текст для управления движением или стилем.
Ключевые соображения:
- T2V предлагает свободу, но требует точного prompt engineering.
- I2V обеспечивает точность, но ограничивает творчество исходным изображением.
- Эффективность по времени и стоимости различается: T2V требует больше итераций, тогда как I2V достигает результатов быстрее с меньшим числом попыток.
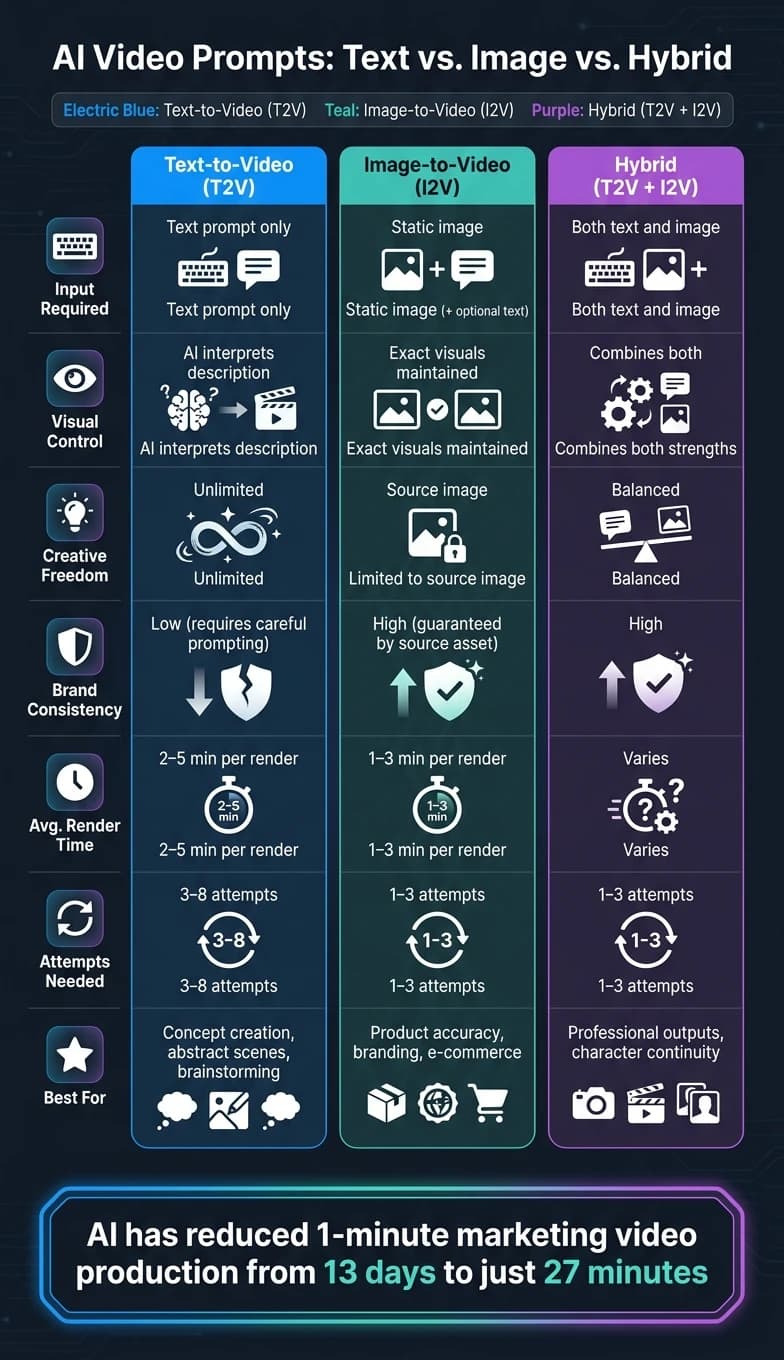
Быстрое сравнение:
| Характеристика | Text-to-Video | Image-to-Video | Гибрид |
|---|---|---|---|
| Требуемый ввод | Только текст | Статичное изображение (+ текст) | Оба |
| Визуальный контроль | AI интерпретирует текст | Сохраняет исходное изображение | Объединяет сильные стороны |
| Творческий диапазон | Неограниченный | Ограничен изображением | Сбалансированный |
| Консистентность бренда | Требует усилий | Высокая | Высокая |
| Идеальный сценарий | Создание концепций | Точность продукта | Профессиональный результат |
Итог: используйте T2V для новых идей, I2V для точности и оба варианта для кинематографичной генерации AI-видео и отточенных результатов.
Текстовые и графические промпты: ключевые различия
Что такое текстовые промпты?
Текстовый промпт - это, по сути, письменная инструкция, которая говорит AI, что создать. Вы начинаете с нуля, выстраивая всё - от сцены и освещения до настроения и движения камеры. Поскольку визуальной опоры нет, модель полностью опирается на свои обучающие данные, предлагая множество творческих возможностей. Например, вы можете описать нечто совершенно фантастическое, вроде дрона, летящего сквозь светящийся каньон на Марсе, и AI попытается воплотить ваше видение.
Но со всей этой свободой приходит и вызов: расплывчатые промпты могут привести к невыразительным результатам. Чтобы получить наилучший вывод, нужно включить детали по 10 конкретным категориям: субъект, стиль, освещение, окружение, настроение, композиция, движение, камера, длительность и звук. Большинство пользователей пропускают несколько из них, что часто приводит к шаблонным результатам - представьте статичные кадры с плоским освещением.
«Text-to-video и image-to-video не взаимозаменяемы. Они работают в разных ограничениях латентного пространства, и понимание того, когда использовать каждый из них, - это разница между кинематографичным выводом и непригодными генерациями.» - Sarah Iruoje [1]
В отличие от этого, графические промпты дают визуальную отправную точку, которая заземляет творческий процесс.
Что такое графические промпты?
Графический промпт начинается со статичного изображения в качестве основы. Вместо генерации всего с нуля AI анимирует изображение, добавляя движение и другие элементы. Этот подход даёт модели чёткое понимание внешнего вида субъекта.
Это особенно полезно для проектов, где визуальная точность критична, например в работе с брендом или продуктом. Скажем, если вы загрузите изображение продукта, AI сохранит его форму, цвет и компоновку. Персонажи остаются консистентными, а логотипы не искажаются. Это делает image-to-video предпочтительным выбором для электронной коммерции, маркетинга продуктов и любого сценария, где сохранение оригинального вида критично. Однако компромисс в том, что ваш творческий диапазон ограничен тем, что уже есть на изображении - вы не сможете создать нечто совершенно новое.
«Как у режиссёра, ваш злейший враг - случайность. Вы не хотите, чтобы AI „угадывал“, как выглядит ваш главный герой; вы хотите, чтобы он анимировал персонажа, которого вы уже разработали.» - AIAI.com [10]
Мультимодальный промптинг
Объединяя сильные стороны текстовых и графических промптов, мультимодальный ввод предлагает мощный способ создавать контент. Эти рабочие процессы, становящиеся стандартом к 2026 году, сочетают визуальную опору с описательными текстовыми инструкциями. Изображение фиксирует визуальные детали субъекта, а текст задаёт движение или поведение камеры. Например, вы можете загрузить фото продукта и добавить текстовую инструкцию вроде «медленный наезд dolly-in с мягким студийным освещением», чтобы управлять тем, как разворачивается сцена.
Платформы вроде APIMart делают этот процесс бесшовным. Они позволяют пользователям задействовать инструменты вроде Kling V3 и Sora в рамках единого API, устраняя необходимость переключаться между разными инструментами или рабочими процессами при сочетании текстового и графического ввода.
| Фактор | Text-to-Video | Image-to-Video |
|---|---|---|
| Требуемый ввод | Только текстовый промпт | Статичное изображение (+ опциональный текст) |
| Визуальный контроль | Модель интерпретирует описание | Точные визуалы сохраняются |
| Творческая свобода | Неограниченная | Ограничена контекстом исходного изображения |
| Консистентность бренда | Низкая (требует тщательного промптинга) | Высокая (гарантируется исходным ассетом) |
| Кривая обучения | Выше (prompt engineering) | Ниже (загрузить и сгенерировать) |
Текстовые промпты: сильные стороны и ограничения
Сильные стороны текстовых промптов
Текстовые промпты блистают, когда речь идёт о пробуждении творчества. Всего несколькими описательными словами вы можете сформировать целые сцены. Они позволяют быстро экспериментировать - тестируете ли вы разные настроения, стили или идеи сцен среди сотен AI-моделей. Хотите сменить мрачный городской фон на залитую солнцем прибрежную обстановку? Просто подправьте несколько слов и сгенерируйте заново. Модели text-to-video также прекрасно черпают из своих обучающих данных, что может приводить к воображаемым результатам, особенно с абстрактными визуалами вроде городских пейзажей, природных последовательностей или фантастических сред, которые можно сгенерировать с помощью моделей вроде Grok Imagine Video.
Но, как и у любого инструмента, здесь есть свои компромиссы.
Ограничения текстовых промптов
Самая большая сложность с текстовыми промптами - недостаток точности. Без визуальной опоры модель часто принимает непредсказуемые решения. Это может приводить к несоответствиям в персонажах, фирменных цветах, расположении логотипа или деталях продукта в нескольких клипах. Ещё одно препятствие? Модели часто испытывают трудности со сложными физическими взаимодействиями - вроде реалистичного хвата рук, синхронизированных движений или стабильного отображения текста. [9][4]
Чтобы справиться с этими сложностями, необходимо использовать ряд проверенных стратегий.
Лучшие практики для текстовых промптов
Один из самых эффективных способов улучшить результаты - использовать структурированный формат из 10 слотов: Субъект + Действие + Окружение + Стиль + Камера + Освещение + Движение + Настроение + Длительность + Звук. [9][4] Пропуск любого из этих элементов может привести к выводу более низкого качества. Например, хорошо составленный промпт для недвижимости может выглядеть так: «Медленный наезд краном вниз, экстерьер современного дома, широкий установочный план, освещение золотого часа, кинематографичный стиль.»
Вот несколько дополнительных техник для отточки ваших результатов:
- Блоки действий с временными метками: внедряйте действия с временными метками для лучшего контроля, особенно в моделях вроде Sora 2. Например: «0–3 с: субъект входит в кадр; 3–6 с: поднимает конверт.» Этот подход помогает управлять темпом и снижает хаотичные или непредсказуемые движения. [4]
- Негативные промпты: используйте поле негативного промпта, чтобы избежать распространённых проблем вроде «размытость, низкое качество, искажения, водяной знак.» Эти исключения помогают обеспечить более чистые результаты. [11]
- Согласованные значения seed: придерживайтесь одного и того же значения seed между генерациями. Это позволяет дорабатывать детали без необходимости начинать заново, экономя время и усилия. [1][4]
Графические промпты: сильные стороны и ограничения
Сильные стороны графических промптов
Когда нужны точные визуалы, графические промпты - это то, к чему обращаются. Вместо опоры исключительно на текст вы загружаете изображение, и AI использует его как точку отсчёта. Этот подход особенно эффективен для сценариев вроде демонстрации продуктов, туров по недвижимости или брендированного контента. Почему? Потому что картинка может мгновенно передать конкретику вроде точного оттенка упаковки продукта, расположения логотипа или текстуры материала - детали, которые трудно зафиксировать одними словами [2][7].
Ещё одно большое преимущество - эффективность. С рабочими процессами image-to-video (I2V) обычно нужно всего 1–3 генерации, чтобы получить желаемый результат, по сравнению с 3–8 попытками при текстовых промптах. Это потому, что основополагающие элементы - композиция, освещение и цвет - уже заданы с первого кадра [6][7].
Ограничения графических промптов
Минус? Страдает гибкость. Поскольку видео привязано к вашему референсному изображению, создание совершенно новых сцен с нуля невозможно. Кроме того, качество вашего входного изображения имеет значение - плохо освещённое, низкого разрешения или неудачно скомпонованное изображение напрямую повлияет на конечный результат [2].
Движение тоже может быть коварным. Тонкие изменения мимики, искажённые руки или исчезающие детали вроде украшений или текста на одежде могут нарушить плавность клипа. В таблице ниже обозначены разные типы кадров и связанные с ними риски:
| Тип кадра | Риск | Лучше всего для |
|---|---|---|
| Тонкое движение | Низкий | Чистые лица, целостность продукта, стабильные фоны |
| Медленный наезд/панорама | Низкий | Кинематографичное настроение, профессиональный маркетинг |
| Агрессивное движение | Высокий | Сцены действия (могут потребоваться повторы) |
| Быстрый облёт/зум | Высокий | Динамичные переходы (склонны к артефактам) |
Большинство моделей по состоянию на 2026 год лучше всего работают с клипами длиной от 5 до 15 секунд. Для более длинных видео безопаснее сшивать вместе короткие сегменты на этапе постпродакшена, чтобы сохранить консистентность деталей между кадрами [6][9].
Опции контроля для графических промптов
Чтобы справиться с этими сложностями, вы можете подстроить несколько настроек контроля. Платформы вроде APIMart с моделями вроде Kling V3 позволяют регулировать параметры вроде интенсивности движения, длительности клипа и веса промпта. Эти настройки помогают сбалансировать, насколько сильно текстовые инструкции влияют по сравнению с референсным изображением [12].
Использование фиксированного значения seed - ещё один разумный шаг. Оно позволяет дорабатывать направление и интенсивность движения между несколькими генерациями, не теряя визуальной консистентности вашего исходного изображения [12]. Для наилучших результатов сочетайте высококачественное референсное изображение с тонкими настройками движения и зафиксированным seed. Этот подход часто выдаёт чистые, отточенные клипы всего за одну-две попытки.
Когда использовать текст, изображение или оба варианта
Сравнение сценариев использования
Решение между text-to-video и image-to-video сводится к тому, какие ассеты у вас уже есть под рукой.
«Выбор между AI-моделями text to video и image to video на самом деле не техническое решение. Дело в том, с чем вы приходите.» - Eachlabs Team [2]
Если вы работаете с концепцией или продуктом, у которого пока нет визуалов - вроде идеи на стадии до запуска - text-to-video ваш лучший выбор. Он позволяет создавать визуалы с нуля без необходимости в фотосъёмке. С другой стороны, если у вас уже есть профессиональные фотографии продукта или фирменные изображения, image-to-video обычно тот самый путь. Это гарантирует, что визуалы в вашем видео идеально совпадают с реальным продуктом, что особенно важно для электронной коммерции, чтобы снизить возвраты [3][7].
| Сценарий | Рекомендуемый ввод | Почему |
|---|---|---|
| Новый бренд, нет существующих ассетов | Text-to-Video | Создаёт визуалы с нуля без необходимости в фотосъёмке [3] |
| Демонстрация или демо продукта | Image-to-Video | Гарантирует, что видео точно совпадает с реальным продуктом [7] |
| Абстрактная или сюрреалистичная рекламная концепция | Text-to-Video | Передаёт метафорические идеи, которые невозможно снять [3] |
| Непрерывность персонажа между клипами | Гибрид (Изображение + Текст) | Референсные изображения фиксируют идентичность; текст управляет действиями [10] |
| Профессиональный брендированный контент | Гибрид (Изображение + Текст) | Сочетает визуальные опоры с движением для отточенных результатов [1] |
Эти решения также зависят от практических факторов вроде стоимости и времени рендеринга.
Практические факторы для команд в США
Бюджет и сроки часто играют не меньшую роль, чем творческие цели. Text-to-video обычно занимает 2–5 минут на рендер и может потребовать 3–8 попыток, чтобы получить нужное, тогда как image-to-video быстрее, в среднем 1–3 минуты и 1–3 попытки [7][8]. Эти различия во времени могут накапливаться в более крупных продакшенах.
Стоимость - ещё одно ключевое соображение. Ценообразование APIMart наглядно показывает, как эти выборы могут влиять на ваш рабочий процесс. Например, Wan 2.5 (Image-to-Video) стоит всего 5 кредитов (около $0.39) за генерацию, что делает её идеальной для высокообъёмной электронной коммерции, где точность критична [3]. Если вы стремитесь к кинематографичному качеству, Sora 2 Pro по 60 кредитов за генерацию - премиальный вариант. Для нужд стандартного качества Veo 3.1 Fast по 8 кредитов находит баланс [3]. Общий подход: начинайте с более дешёвых моделей text-to-video для идей на ранней стадии, затем переходите к image-to-video или гибридным рабочим процессам для финального продукта.
Сочетание текстовых и графических промптов
Использование текстовых и графических промптов вместе может помочь вам получить лучшее из обоих миров, объединяя творчество с точностью.
«Text-to-video = воображение и исследование; Image-to-video = консистентность и контроль; Гибрид = вывод профессионального уровня.» - Sarah Iruoje, VidAU.ai [1]
Один из эффективных методов - техника «Сначала генерируй стоп-кадры». Начните с использования модели text-to-image, чтобы создать стоп-кадр, который передаёт нужную вам композицию. Затем используйте модель image-to-video, чтобы добавить движение этому стоп-кадру [2][7]. Ещё один многообещающий рабочий процесс, известный как Кирпичная система, разбивает видеорекламу на отдельные секции. Например, вы можете использовать модель text-to-video, чтобы создать привлекающее внимание кинематографичное вступление, продолжить его сегментами image-to-video для точных деталей продукта и завершить брендированным оверлеем для призыва к действию [3]. Каждая секция - или «кирпич» - использует тип ввода, наиболее подходящий для её роли, создавая целостное и эффективное финальное видео.
Image-to-Video vs Text-to-Video: почему стартовый кадр выигрывает в контроле
Заключение: выбор правильного типа промпта под ваши цели
Процесс принятия решения здесь сводится к одной простой отправной точке: работайте с тем, что у вас уже есть. Если у вас нет визуалов для начала, text-to-video - отличный способ быстро поэкспериментировать с идеями. С другой стороны, если у вас уже есть утверждённые изображения, image-to-video - ваш выбор для сохранения консистентности бренда. Для наилучших результатов сочетание обоих методов может стать переломным моментом.
Вот статистика, чтобы взглянуть на вещи в перспективе: AI сократил время производства минутного маркетингового видео с 13 дней до всего 27 минут [5]. Тип промпта, который вы выбираете, определяет, какую часть этой эффективности вы реально сможете задействовать. Text-to-video превосходит на этапе мозгового штурма, image-to-video обеспечивает точность для финальных результатов, а гибридные рабочие процессы приносят профессиональным командам отточенные результаты, которые им нужны.
Полезная техника, которую стоит взять на вооружение, - стратегия «Универсального ядра». Она предполагает составление модульного промпта, сфокусированного на консистентном субъекте и сцене, с добавлением параметров, специфичных для модели. Использование паритета seed для стабилизации визуалов также может сократить число генераций, необходимых для получения пригодного клипа.
Платформы вроде APIMart делают мультимодальные рабочие процессы более бесшовными. Система автоматически выбирает подходящий режим генерации на основе вашего ввода: отсутствие изображения по умолчанию задаёт text-to-video, одно изображение запускает image-to-video, а два изображения активируют режим первого-последнего кадра [12]. С доступом к более чем 500 моделям - включая Sora 2, Veo 3.1 и Kling V3 - через единый API вы можете легко переключаться между стратегиями, не жонглируя несколькими платформами или биллинговыми системами. Такой оптимизированный рабочий процесс упрощает творческий процесс.
В конечном счёте универсального решения не существует. Лучший тип промпта зависит от доступных вам ассетов, ваших дедлайнов и уровня визуальной консистентности, которого требует ваш проект. Освоив каждый подход, вы сможете сократить циклы проб и ошибок и выдавать результаты быстрее.
Часто задаваемые вопросы
Как выбрать между text-to-video и image-to-video для моего проекта?
Выбор между text-to-video и image-to-video зависит от того, чего вы стремитесь достичь с точки зрения творчества и консистентности.
- Text-to-video хорошо работает, когда вы фокусируетесь на сторителлинге, генерации абстрактных визуалов или экспериментах со свежими идеями с самого начала.
- Image-to-video лучше для сценариев, где сохранение консистентного визуального стиля критично, вроде брендированного контента или проектов с повторяющимися персонажами.
Чтобы упростить дело, APIMart берёт это решение на себя. Он автоматически выбирает наиболее подходящий режим на основе ваших вводных, обеспечивая плавную интеграцию.
Что делает текстовый промпт «достаточно подробным» для хороших результатов видео?
Сильный текстовый промпт переходит от общего к чётко определённому, обозначая субъект, действие, окружение, движение камеры и стиль. Включение точных деталей - вроде отличительных характеристик или конкретного освещения - помогает устранить неоднозначность и обеспечивает более консистентный результат. С APIMart вы можете пойти ещё дальше, добавив визуальные референсы в качестве опор. Этот подход гарантирует, что ключевые детали, вроде брендинга или дизайна персонажа, остаются консистентными по всему вашему видеоконтенту.
Как мне сохранить консистентность персонажей или продуктов в нескольких AI-видеоклипах?
Чтобы создавать консистентные AI-сгенерированные видеоклипы, лучше опираться на мультимодальный ввод, а не только на текстовые промпты. Текстовые промпты могут вызывать несоответствия, поскольку модели приходится заполнять все детали самостоятельно. Сочетая ваши текстовые промпты с референсными изображениями с помощью инструментов вроде APIMart, вы даёте AI чёткий визуальный ориентир для элементов вроде персонажей, логотипов и продуктов. Для оптимальных результатов убедитесь, что ваши референсные изображения высокого разрешения, хорошо освещены и показывают субъект с нескольких ракурсов.
Выберите нужную модель в маркетплейсе моделей
Попробуйте чат, изображения и видео в маркетплейсе APIMart и быстро оцените возможности моделей через единый API.