
AI API 成本对比:按量付费模型完整指南
对比 2026 年 APIMart、OpenAI、Google Cloud、Amazon Bedrock 的按量付费 AI API 价格、token 费率、批量折扣与成本优化策略。
想找到 2026 年最划算的 AI API 定价方案?以下是你需要了解的内容。
按量付费(PAYG)模式根据 token 使用量计费,适合不同规模的企业灵活使用。过去两年里 token 价格下降了 80%,APIMart、OpenAI、Google Cloud AI、Amazon AI Services 等厂商都给出了颇具竞争力的方案。不过同一类任务的成本差异可能高达 625 倍。
核心要点:
- APIMart:一站式接入 500+ 模型,相比官方价直降 20%。适合需求多样、希望统一计费的团队。
- OpenAI:工具链成熟,支持 prompt caching 等高级特性,但旗舰模型价格偏高。
- Google Cloud AI:上下文窗口最大可达 200 万 token,多模态能力强。
- Amazon AI Services:入门价格极低,与 AWS 深度集成,但 Bedrock 的统一 API 会带来一定加价。
小贴士:高频任务用低价模型,关键场景再上旗舰模型;配合批量处理和 prompt caching,可省下 50%–90% 的开支。
下面逐一拆解各家厂商的价格、特性和折扣策略。
AI 模型 API 价格对比:Claude、Kimi、GPT-4o 及其他
1. APIMart
APIMart 让你用一把 API key、一份账单、一块控制台就能调用 500+ AI 模型。
单次调用成本
APIMart 采用按量付费模式,没有月度最低消费,也没有隐藏费用。下表展示的样本费率相比官方价稳定节省 20% [7]:
| 模型 | APIMart 价格 | 官方价格 | 节省 |
|---|---|---|---|
| Wan 2.7 Image | $0.0216/call | $0.027/call | 20% |
| GPT Image 2 | $0.006/call | $0.0075/call | 20% |
| Imagen 4.0 | $0.04/call | $0.05/call | 20% |
| Qwen Image 2.0 | $0.02/1K tokens | $0.025/1K tokens | 20% |
| Z Image Turbo | $0.01/call | $0.0125/call | 20% |
除了价格优势,APIMart 还提供覆盖各类 AI 能力的丰富模型选择。
模型种类与多模态能力
APIMart 的模型库覆盖聊天、图像生成、视频生成与编辑,全部通过同一个端点调用。视频方向有 Sora 2($0.08/秒)、Veo 3、Kling V3(720p 售价 $0.0672/秒)等选项;图像与语言方向则包含 Flux.1、Imagen 4.0、GPT-5、Claude Sonnet 4.5 等。如此丰富的组合让你能为每个任务挑选最合适的模型,轻松搭建跨文本、图像和视频的工作流,无需同时管理多家供应商。
批量折扣与可扩展性
随着用量增长,系统会自动套用批量折扣。APIMart 还推出了"Discount Bundles",对在同一账户下混用多类模型的团队给予奖励。例如,把 GPT-5 用于推理任务、Flux.1 用于图像生成,就能解锁更高的折扣档位。统一的控制台实时展示各模型族的用量与配额,方便企业级团队管理与预测开支 [7]。
成本优势之外,APIMart 在接入与服务支持上同样出色。
接入与支持
APIMart 的接入过程非常简单,3 分钟即可完成:生成 API key、替换 base URL,就能开始调用 [7]。已经在用 OpenAI SDK 的开发者只需改一行代码。平台完全兼容 OpenAI,支持 Python 与 JavaScript SDK,可处理流式输出、function calling、视觉与多模态输入。在 GPT-5、Claude Sonnet 4.5 等模型间切换无需修改代码 [8]。
技术支持由真人工程师通过聊天提供,平台目前在 320 条评价中获得 4.6/5 的评分。用户普遍称赞其"单 key 接入"和低延迟两大亮点 [9]。
2. OpenAI API
OpenAI 采用按 token 计费的按量付费模式,以处理的每 100 万(1M)token 作为计价单位。不同模型之间的价格差距很大:GPT-5 nano 的输入价低至 $0.05 per 1M tokens,而 GPT-5.5 Pro 可高达 $30.00 per 1M tokens——相差整整 600 倍 [11]。下面按模型分档梳理。
单次调用成本
费用主要取决于你选择的模型档位。完整价格如下:
| 模型 | 输入(per 1M tokens) | 缓存输入 | 输出(per 1M tokens) |
|---|---|---|---|
| GPT-5.5 Pro(Reasoning) | $30.00 | – | $180.00 |
| GPT-5.5(Standard Edition) | $5.00 | $0.50 | $30.00 |
| GPT-5.4 | $2.50 | $0.25 | $15.00 |
| GPT-5.4 mini | $0.75 | $0.075 | $4.50 |
| GPT-5.4 nano | $0.20 | $0.02 | $1.25 |
| GPT-5 nano | $0.05 | $0.005 | $0.40 |
非文本任务单独计费。例如 Sora-2 视频处理 720p 售价 $0.10/秒,1080p 售价 $0.70/秒。Realtime API 的音频输入费用为 $32.00 per 1M tokens,输出为 $64.00 per 1M tokens [10]。
模型种类与多模态能力
OpenAI 支持文本、视觉、音频、视频、网页搜索、代码执行等广泛任务。Realtime API 提供实时语音转语音和翻译服务,翻译收费 $0.034/分钟,转录收费 $0.017/分钟。网页搜索按 $10.00/1,000 次调用计费,托管式代码执行("Containers")则根据内存使用情况,每 20 分钟会话从 $0.03 到 $1.92 不等 [10]。
批量折扣与可扩展性
为了帮助用户控制成本,OpenAI 提供多种省钱选项:
- Batch API:可异步处理且能在 24 小时内完成的任务,输入和输出成本均减半,非常适合批量作业。
- Flex Tier:对响应时延要求不高的实时请求提供 50% 折扣。
- Priority Processing:价格是标准档的 150%,但能换来更快、更稳定的吞吐。例如 GPT-5.5 的优先档输入价为 $12.50 per 1M tokens,标准档为 $5.00。
优先处理档相比标准处理服务能更快地生成 token,并且在高峰期速度也更稳定。 - OpenAI [14]
自动 prompt caching 还能将输入成本进一步降低多达 90%,非常适合重复或长上下文任务 [14]。
接入与支持
OpenAI 提供丰富的工具链,方便无缝接入,包括标准 SDK、Agents SDK 与 CLI,并支持 WebRTC、WebSocket、SIP 等实时连接方式 [12]。开发者可在 Chat Completions API 中将 service_tier 参数设为 "priority"、"auto" 或 "default" 来调整处理速度 [15]。
为方便团队跟踪和管理成本,Usage Dashboard 会按服务档位或单项条目给出详细的支出洞察。对于有数据驻留需求的用户,OpenAI 还提供区域处理端点,但会加价 10% [13]。
3. Google Cloud AI APIs
Google Cloud 的 AI 定价采用与 OpenAI 类似的按 token 计费方式,但模型阵容和价格结构各有特点。Google 将 Gemini 模型 分为两档:"Flash" 主打速度与性价比,"Pro" 面向更复杂的推理任务。这种划分方便开发者在能力与预算之间做平衡。
单次调用成本
不同模型间价格差距明显。Gemini 3 4B 是最便宜的档位,输入仅 $0.04 per 1M tokens;Gemini 3.1 Pro 在提示词不超过 20 万 token 时为 $2.00 per 1M tokens,超出后翻倍至 $4.00 [17]。输出 token 的价格通常是输入的 4 至 10 倍 [17]。
| 模型 | 输入(per 1M tokens) | 输出(per 1M tokens) | 上下文窗口 |
|---|---|---|---|
| Gemini 3.1 Pro(Preview) | $2.00 | $12.00 | 1M–2M tokens |
| Gemini 2.5 Pro | $1.25 | $10.00 | 2M tokens |
| Gemini 3 Flash(Preview) | $0.50 | $3.00 | 1M tokens |
| Gemini 2.5 Flash | $0.30 | $2.50 | 1M tokens |
| Gemini 3.1 Flash-Lite | $0.25 | $1.50 | 1M tokens |
| Gemini 2.5 Flash-Lite / 2.0 Flash | $0.10 | $0.40 | 1M tokens |
| Gemini 3 4B | $0.04 | $0.08 | 131K tokens |
图像和视频生成方面,Imagen 4.0 按质量不同每张图售价 $0.02–$0.06,Veo 3.1 视频生成标准模式为 $0.40/秒,preview 模式为 $0.15/秒 [16]。
模型种类与多模态能力
Google 的模型可处理文本、图像、视频、音频、代码等多种任务,省去了外接转录等工具的麻烦 [20]。最大亮点是 Gemini 2.5 Pro 和 Gemini 3.1 Pro 上的 200 万 token 上下文窗口,在业界几乎无人能敌 [16][3]。需要注意的是,音频输入价格高于文本:Gemini 3.1 Flash-Lite 的文本输入为 $0.25 per 1M tokens,音频则为 $0.50 per 1M tokens [17]。此外,新一代推理模型引入了"thinking tokens",会显著推高复杂输出的成本 [17][19]。
批量折扣与可扩展性
Google Cloud 为企业提供多种省钱选项。Batch API 对能在 24 小时内异步处理的任务给予输入输出五折优惠 [17][19]。例如 Gemini 3.1 Pro 的批量输入价从 $2.00 降至 $1.00 per 1M tokens。另一项 context caching 会以 $1.00 per 1M tokens/小时 缓存高频提示词或文档,非常适合 RAG 管线或长会话场景 [17]。开发者还可以通过在多家厂商之间智能路由进一步 优化成本。
Google 还实施 按消费额提速 策略:30 天内消费超过 $2,000 的组织会自动解锁更高的速率上限 [18]。面向超大规模业务的 Enterprise tier 则提供容量保障与定制价格 [17]。
接入与支持
Google Cloud 的工具链原生支持 Google Workspace、Drive 和移动平台,通过 Vertex AI 一站接入 [20][19]。Grounding with Google Search 功能可用实时数据增强模型回答,在 Gemini 3 模型上每月前 5,000 次提示免费,超出部分按 $14/1,000 次查询 计费 [17]。
其他内置工具还包括 Function Calling、Streaming 和 Code Execution。隐私策略则因档位而异:免费档(Google AI Studio)提交的数据可能被用于产品研发;付费档与 Enterprise 档则承诺不会将数据用于此类用途——这对处理敏感数据的团队是关键考量 [17][3]。
4. Amazon AI Services
Amazon 的 AI 产品主要分为两条线:Amazon Bedrock 通过托管 API 提供基础模型访问,Amazon SageMaker 则用于训练和部署自定义模型。两个平台都采用按量付费模式,但具体结构遵循各自的服务条款。和大多数竞品一样,Amazon 提供灵活的用量定价以及面向不同业务需求的分档方案。
单次调用成本
Amazon Bedrock 的价格分四档:Standard(按需)、Flex(更便宜但响应慢)、Priority(更快但更贵)和 Batch(异步处理)。以 Amazon Nova 2 Lite 为例:
| 档位 | 输入(per 1M tokens) | 输出(per 1M tokens) |
|---|---|---|
| Standard | $0.30 | $2.50 |
| Priority | $0.525 | $4.375 |
| Flex | $0.15 | $1.25 |
| Batch | $0.15 | $1.25 |
Nova 家族价格跨度很大:Nova Micro 起步仅 $0.035 per 1M input tokens,Nova Premier 则达到 $2.50 per 1M input tokens。第三方模型价格更高,比如 Claude 4.7 Opus 的输入为 $5.00 per 1M tokens,输出为 $25.00 per 1M tokens [22]。
模型种类与多模态能力
Amazon Nova 系列覆盖图像、视频、语音和 embedding 等多种内容类型:
- Nova Canvas:图像生成 $0.04–$0.06/张。
- Nova Reel:视频生成 $0.08/秒(720p/24fps)。
- Nova Sonic:语音处理 $3.00–$3.40 per 1M input tokens [22]。
此外,Nova 模型的 web grounding 统一按 $30.00/1,000 次请求 计费 [22]。
批量折扣与可扩展性
对用量稳定或体量大的企业,Amazon 提供丰厚的折扣选项:
- Batch inference 相比按需价节省 50% [22]。
- Machine Learning Savings Plans 让 SageMaker 用户在签订 1 年或 3 年合约后可省下高达 64% [23]。
- Managed Spot Training 利用 AWS 闲置容量训练,最高可降低 90% 的算力成本 [23]。
AWS 这样解释:
按量付费模式让你能基于真实需求而不是预测来调整业务,降低过度配置或容量不足的风险。 [21]
接入与支持
Amazon Bedrock 让用户能便捷地调用来自 Anthropic、Meta、Cohere、AI21 Labs、DeepSeek 以及 Amazon Nova 等家族的基础模型。统一 API 让模型间切换或能力组合不再需要大改现有集成 [24][25]。Bedrock 原生对接 Amazon S3、AWS Lambda 和 SageMaker,还内置了 Amazon Bedrock Guardrails(安全护栏)和 Amazon Augmented AI (A2I)(人工审核工作流)等能力 [26]。
为提升可靠性,AWS 会自动把推理请求路由至最合适的区域,确保数据不经过公网传输 [25]。
各家厂商的优缺点
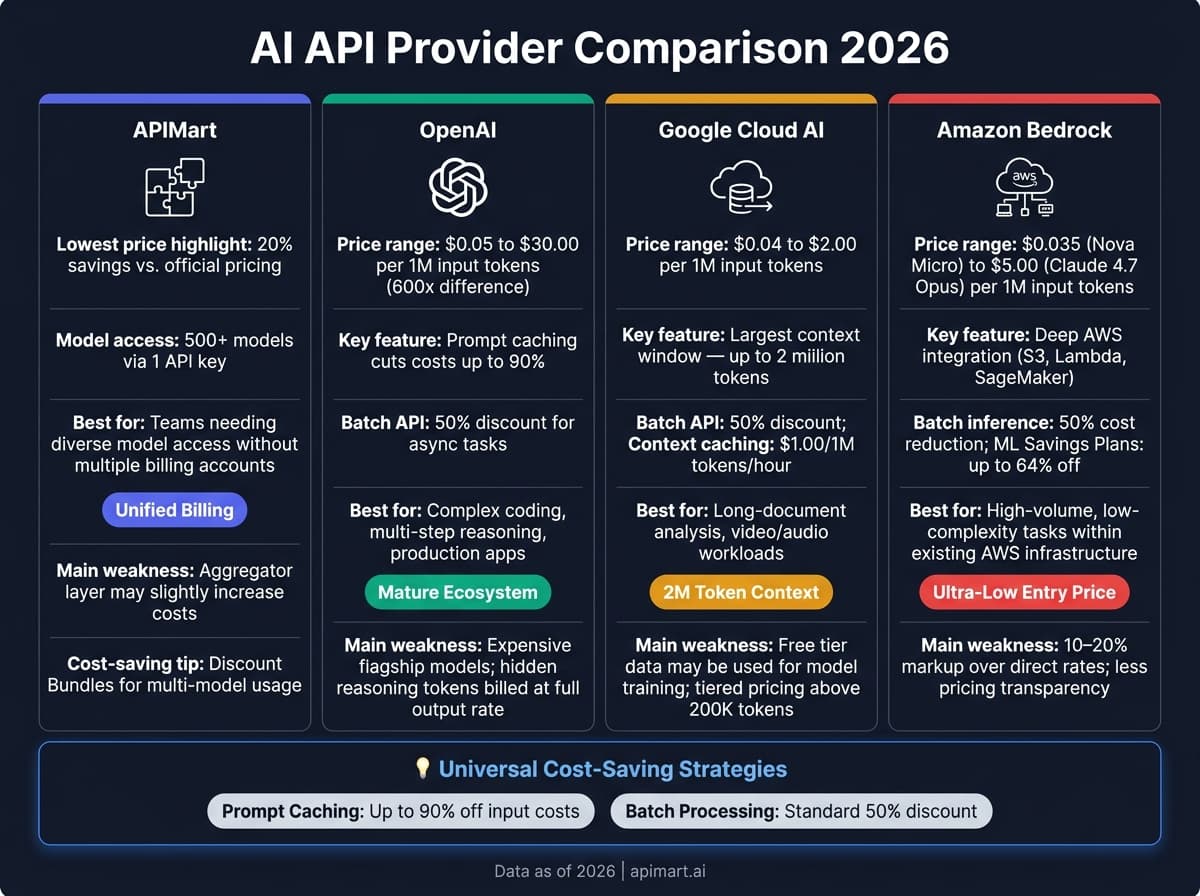
各家厂商的定价和功能都针对不同的工作负载与技术需求量身打造。下面快速看看主要玩家的强项与短板。
APIMart 通过一个统一的 API 把 500+ 模型聚合在一起,免去了管理多个账单的麻烦。代价是聚合层会让价格略高于直连模型方的方案。但对大规模项目来说,这种简化的成本管理方式收益显著。
OpenAI 凭借成熟的开发者生态和强大的 prompt caching 系统脱颖而出,缓存输入能带来最高 50% 的成本下降。但旗舰模型价格高昂,推理类模型(如 o 系列)还有一个隐藏成本:reasoning token 按完整输出价计费,即便它们并不会出现在最终输出中 [1][5]。
提示词设计、模型选择或上下文长度上的小调整,就可能让月度账单浮动 10 倍。 - Lyne Carolyne, CloudZero [5]
Google Cloud AI 提供业界最大的上下文窗口——最高 200 万 token,多模态能力也很强。免费档具备吸引力,但需要注意:提交的数据可能被用于模型训练,对隐私敏感的用户来说是一个隐患 [3]。此外 Gemini 3.1 Pro 等模型采用阶梯定价,提示词超过 20 万 token 后输入价翻倍 [5]。
Amazon AI Services (Bedrock) 非常适合已经在用 AWS 的团队。Nova Micro 把入门价做到了 $0.035 per 1M input tokens,是市面最低之一;批量推理还能为非紧急任务节省 50% [2]。不过通过 Bedrock 的统一 API 调用,通常会比直接走原厂 API 贵 10%–20% [5]。
下面这张表快速总结主要权衡:
| 厂商 | 主要优势 | 主要劣势 | 最佳定位 |
|---|---|---|---|
| APIMart | 一个 API 接入 500+ 模型、多模态支持 | 聚合层可能略增成本 | 需要多模型而又不想折腾多家账单的团队 |
| OpenAI | 生态成熟、prompt caching、Batch API | 旗舰/推理模型偏贵,thinking token 隐藏成本 | 复杂编码、多步推理、生产级应用 |
| Google Cloud AI | 最大上下文(2M token)、多模态 | 免费档数据可能被用于训练,超 20 万 token 阶梯加价 | 长文档分析、视频/音频负载 |
| Amazon Bedrock | AWS 深度集成、入门价极低 | 比原厂直连贵 10%–20%,定价透明度较低 | AWS 体系内的大批量、低复杂度任务 |
这些权衡说明每家厂商都对应着特定的技术需求和预算结构。对于输出量大的应用而言,输出 token 比输入 token 贵 3–10 倍的特性让批量处理和 prompt caching 等策略尤为划算 [4][6]。
结语
选对 AI API 厂商,本质上就是把需求和工具精准匹配。虽然过去两年 AI API 价格大约下降了 10 倍(截至 2026 年初)[2],但同一任务在最便宜和最贵的方案之间仍可能相差 625 倍 [4]。对任何开发团队来说,挑对厂商都至关重要。
务实的做法是:分类、抽取等高频且简单的任务用廉价模型,把昂贵的旗舰模型留给真正关键的场景。采用这种智能模型路由,团队能在不牺牲质量的前提下降低 60%–80% 的成本 [28]。除省钱外,借助聚合平台还能减少多账户管理带来的运维负担。
运营效率同样关键。多厂商管理常带来沉重的开销。APIMart 这类平台通过单一 API 和统一计费接入 500+ 模型,正好解决了这个痛点。这种方式牺牲了一点直连厂商的极致单价优势,换来的是更快的交付和更简单的流程。
整合的价值不仅在于成本,更在于把工程师的时间从基础设施上省下来,用到产品本身。 - Louis Amira, ATXP 联合创始人 [28]
最后,无论选哪家厂商,都建议落地两项省钱策略:prompt caching 和 批量处理。前者对重复上下文的输入成本最多可降低 90% [27],后者对不要求实时结果的任务直接打 5 折 [2]。它们既省钱又能让工作流更清晰,是每个团队都该上的"标配"。
常见问题
上线前如何估算工作负载的 token 用量?
token 本质上是文本的小片段,平均约 0.75 个英文单词。它同时用于衡量你提供的输入和模型返回的输出。要看清自己的 token 用量,先借助 token 计数工具分析样本提示词和回答,估算出每次请求大约消耗多少 token。
拿到数据后,按业务场景估算输入与输出所需的 token 总量,再乘上厂商的单价(通常按每百万 token 计费),就能算出大致成本。这一步是规划预算、决定是否上线的关键前置工作。
如何在不牺牲质量的前提下降低 PAYG 成本?
降低按量付费(PAYG)的 AI API 成本,并不一定意味着要牺牲性能。可以参考以下做法:
- 合并请求:把多个小请求合并成大批量调用,能减少调用次数、降低费用。
- 精简提示词:避免冗长或复杂的提示。简洁清晰的指令既能省 token,也能保证输出质量。
- 挑对模型:简单或非关键任务用小而便宜的模型,旗舰模型只在真正需要时才上。
- 跟踪 token 用量:持续监控 token 消耗,发现浪费时及时调整方案或切换模型。
如果业务负载波动大或体量较小,重点放在 token 效率和批量请求上;如果业务量大且稳定,订阅式套餐通常更划算,价格更可预期、单价也更低。
在什么情况下使用 APIMart 这样的统一 AI API 更划算?
如果你的团队同时依赖多家厂商的多种模型,那么像 APIMart 这种统一 AI API 就能带来明显的成本和管理收益。所有模型集中在同一平台上,运维更简单、开销也更可控。
对于跨度较大的任务——例如多媒体项目或语言处理——APIMart 提供多模态输入、进阶编辑能力 和 统一计费,即便业务用量波动较大,也能帮你稳住成本曲线。
相关阅读
去模型市场挑选你想要的模型
在 APIMart 模型市场尝试聊天、图像和视频模型,用统一 API 快速体验模型能力。