
面向角色故事工作流的多模态 AI
了解多模态 AI 如何结合文本、图像和视频模型,打造一致的角色、规划分镜卡片,并生产个性化的故事内容。
多模态 AI 正在通过结合文本、视觉、音频和视频,打造栩栩如生的角色和连贯的叙事,从而变革故事创作。它简化了内容创作、降低了成本,并确保跨格式的一致性。以下是你需要了解的内容:
- 它能做什么:多模态 AI 可处理多种内容类型(如文本转视频),塑造出在视觉、声音和行为上保持一致的角色。
- 为什么重要:与传统方法(每集成本可高达 500,000 美元)相比,它大幅削减了制作成本(每个故事低至 5 美元)和时间(不到一小时)。
- 它如何运作:像 APIMart 这样的工具统一了 500+ AI 模型,为创建和管理角色故事提供无缝的工作流。
- 关键技巧:使用「角色 DNA 文档」来构建详尽的角色档案,用锚定视觉素材保持一致性,并借助 LoRA 和 IP-Adapter 等高级工具来维持准确度。
本指南将讲解如何有效运用多模态 AI——从撰写叙事到生产视频——同时让角色对不同受众都保持一致且引人入胜。
AI 驱动角色开发的核心概念
构建一致的角色档案
在使用多模态 AI 进行故事创作时,为角色打下坚实的基础至关重要。在生成视觉素材或对话之前,先从一份 「角色 DNA 文档」 开始——这是一份定义角色方方面面的详尽参考。该文档应包含外貌细节(例如 「略微上扬的杏仁形翠绿色眼睛」,而不只是「绿色眼睛」)、性格特质、行为边界,以及 AI 必须在所有输出中始终遵循的叙事规则 [3]。
这份文档中所包含的细节程度至关重要。模糊的描述会导致结果不一致,让你的角色变得难以辨认。精确的档案给 AI 提供了清晰的边界,确保角色在整个故事中的外貌、语气和行为上保持一致。
「AI 内容中的角色一致性意味着角色在每一次输出中都保持不变。他们的性格、语气、行为、外貌和背景故事不会改变,也不会与先前的细节相矛盾。」——Aisha Imtiaz,AllAboutAI 编辑 [3]
保持视觉一致性的一个有效方法是保存成功角色生成时的种子编号。在后续场景中复用这个种子,能确保角色的视觉身份保持锚定,避免随时间推移出现细微变化 [3]。
多模态模型如何协同工作
专注于文本、图像和视频的 AI 模型各自应对角色创作的不同方面。当它们协同使用时,就能以连贯的方式让角色栩栩如生。例如:
- 像 GPT-5 这样的语言模型塑造角色的声音、背景故事和情感深度。
- 像 Flux Kontext 这样的图像模型将文字描述转化为一致的视觉设计。
- 像 Kling V3 这样的视频模型为角色注入动画,在动态场景中保持其外观。
LoRA 等高级工具会微调特定的模型层,以锁定关键细节——如面部结构、服装纹理或肤色——相比单纯依赖提示词,其准确率可达 85–92% [3]。与此同时,IP-Adapter 支持「零样本」身份注入。这意味着你可以上传一张参考肖像,模型无需额外训练即可提取面部特征 [6]。运用这些方法,现代 AI 视频 API 可实现高达 95% 的视觉连贯性,将角色漂移控制在跨场景 5% 的偏差以内 [6]。
从早期的「提示并祈祷」方式转向结构化的生产工作流,这一转变彻底改变了整个行业。正如 Atlas Cloud Blog 所解释的:
「行业已经从『提示并祈祷』过渡到了结构化生产。」 [6]
这种结构化的方法确保角色即使在不同 AI 工具之间切换时也能保持一致。
APIMart 在角色叙事中的作用
以往管理多个 AI 模型需要复杂的配置,但像 APIMart 这样的平台简化了这一流程。APIMart 通过单一的 OpenAI 兼容 API 连接了 500 多个 AI 模型——包括 GPT-5、Claude、Flux Kontext、Kling V3 和 Sora——简化了整个角色创作流水线。
在角色开发方面,APIMart 为 Kling V3 Omni 等模型提供了 <<<image_N>>> 参考语法等特性。该语法明确告诉模型应遵循哪张参考图像,从而确保视觉一致性 [4]。此外,其 create-character 端点允许你从现有视频的特定时间戳提取角色身份,并在新场景中复用该身份 [5]。这些工具提供了精确的控制,确保你的角色在整个叙事过程中在视觉和叙事上都保持一致。
创建一致的多角色 AI 故事
规划多模态角色故事工作流
界定故事范围并选择模态
在深入使用 AI 工具之前,先规划好项目的结构和时长至关重要。例如,一段 30 秒的短小情感弧线可能会拆分成 6–8 个微片段,每段约 5 秒;而一段 2 分钟的讲解视频则可能包含更长的分段,其间穿插标题卡片。提前打好这个基础有助于避免后续额外的返工。
将你的脚本拆分成分镜卡片,详细描述主体、动作、环境、镜头运动和基调。可以把这些卡片当作你的故事板,无论你是用纯文本编写,还是使用 JSON 格式。这个规划阶段能确保与你已经确立的角色身份保持一致。
对于抽象或氛围性的时刻,如果精确的视觉效果并非必需,纯文本场景就很合适。然而,当引入一个反复出现的角色时,将文本与图像结合有助于锁定其视觉身份,防止场景之间出现不一致。对于需要紧密同步的时刻——比如对话搭配音效——文本、视觉和音频的组合是最佳方案。
一旦你的场景规划完毕,下一步就是为每种模态选择合适的模型。
借助 APIMart 选择合适的模型
每张分镜卡片的模态都应与最合适的 AI 模型相匹配。APIMart 通过单一 API 提供对 500 多个 AI 模型的访问,免去了同时管理多个账户或集成的麻烦,从而简化了这一流程。
在文本生成方面,GPT-5 是塑造角色深度和背景的可靠选择。在 APIMart 上,GPT-5 配备了 Web Search 和 File Search 等工具,可将角色扎根于真实世界的细节之中 [7]。
在图像生成方面,APIMart 提供了能将文字角色描述转化为一致视觉效果的高级模型。
至于视频,你的选择将取决于预算和质量需求。以下是一些选项的快速概览:
| 模型 | 最适合 | APIMart 价格 |
|---|---|---|
| Kling V3 Omni | 采用多模态输入的电影级角色场景 | $0.0672/秒(720p) |
| MiniMax Hailuo 2.3 | 快速、低成本的短片段 | $0.025/秒 |
| Sora 2 Preview | 适用于大多数创意场景的均衡质量 | $0.08/秒 |
| Vidu Q3 Pro | 复杂、高性能的场景 | $0.12/秒 |
这里有个小技巧:先用 GPT-5 等语言模型做一次初步处理,将角色的外貌特征提取成结构化的 JSON 格式(例如姓名、年龄、发色、服装、声音描述)。将这份身份表附加到每个场景提示词上,能确保你的角色在所有模型输出中都保持一致 [1]。
得益于 APIMart 的统一 API,选择和管理模型的过程变得简单得多。
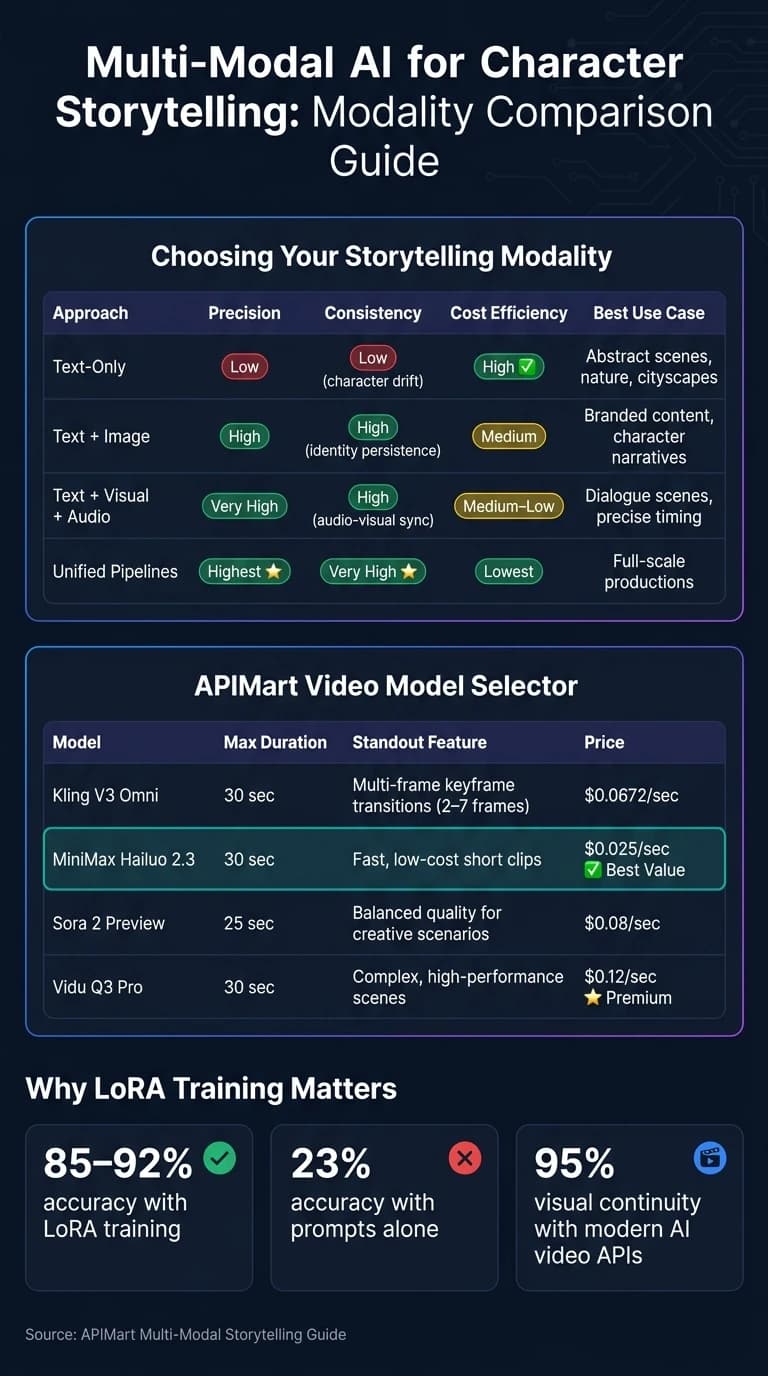
面向故事创作的模态对比
每种模态方案都各有其优势和取舍。以下是一份快速对比,帮助你决定哪种最适合你的需求:
| 方案 | 精确度 | 一致性 | 成本效率 | 最佳使用场景 |
|---|---|---|---|---|
| 纯文本 | 低 | 低(角色漂移) | 高 | 抽象场景、自然风光、城市景观 |
| 文本 + 图像 | 高 | 高(身份持续性) | 中 | 品牌内容、角色叙事 |
| 文本 + 视觉 + 音频 | 极高 | 高(音画同步) | 中–低 | 对话场景、精确计时 |
| 统一流水线 | 最高 | 极高 | 最低 | 全规模制作 |
在早期投入更高的精确度,能在后续为你节省时间和精力。虽然纯文本工作流前期看似更便宜,但跨场景的角色漂移会导致额外的修订,从而抵消这些初期的节省。
创建并优化多模态角色故事
撰写基于文本的叙事
多模态故事创作的核心在于一个坚实的叙事框架。为此,可分两个不同的步骤来运用 GPT-5。首先,将角色的视觉身份提取为结构化的 JSON 文件,详述发色、面部结构、服装和声音等特征。其次,将故事拆分成 分镜卡片,每张卡片聚焦于单一的主要动词(例如 奔跑、躲藏、大笑)[1]。这种方法确保叙事与后续描述的视觉和视频元素连贯地对齐,让角色的 JSON 身份表在所有模态中都保持一致。
在创建分镜卡片时,每张卡片坚持只用一个主要动词。在提示词中塞入多个动作会让模型困惑,往往导致不一致或混乱的输出 [8]。
将角色描述转化为视觉素材
一旦你的角色叙事基础确立,下一步就是在视觉上让他们栩栩如生。首先将 JSON 身份表转化为一组参考图像。争取至少三个锚定视角:正面、侧面和四分之三角度。这些锚定图像充当角色的视觉指南,确保其外观在整个故事中保持一致 [9]。
为了避免「身份漂移」,请维护一份 角色圣经,其中包含脸型、配色方案、服装、光照偏好和默认表情等关键细节。每个图像提示词都应纳入这个身份模块,只改变场景特定的动作或环境 [9]。APIMart 上的 Grok Imagine 的 Subject 特性 等工具允许你直接上传参考图像,确保你的角色在各种不同的设定中都能保持一致的外观 [10]。
生产以角色为核心的视频场景
有了锚定视觉素材,你就可以着手生成视频了。将这些参考图像用作基础,而不是仅仅依赖文本提示词,从而确保得到精致的效果。
APIMart 上提供的不同模型可满足独特的视频制作需求。以下是一份快速对比:
| 模型 | 最长时长 | 突出特性 |
|---|---|---|
| Sora 2 Pro | 25 秒 | 扩展的电影级控制与同步音频 |
| Hailuo 03 | 30 秒 | 导演模式与全局身份 VAE |
| Kling V3 | 30 秒 | 多帧关键帧过渡(2–7 帧) |
| Google Veo 3 | 8 秒 | 原生环境音、拟音和对话音频 |
为确保片段之间的平滑过渡,可使用 「末帧」方法:取一段视频的最后一帧,将其用作下一场景的起始图像 [10]。这种方法在角色的位置、光照和表情上保持连续性,无需从头开始。Kling V3 Omni 通过其 <<<image_N>>> 语法简化了这一过程,允许你在提示词数组中直接引用特定的帧 [4]。
保持角色一致并让故事个性化
维持角色一致性的方法
多模态故事创作中最大的挑战之一是避免「角色漂移」。当跨场景出现细小的、无意的变化,让角色显得不一致或难以辨认时,就会发生这种情况。防止这种情况的关键,是在生成任何内容之前为你的角色打好坚实的基础。
首先创建一份 角色圣经。它应包含脸型、眼睛颜色、发质、肤色、特征性标记和默认服装等基本细节。可以把它当作 AI 模型的外部记忆工具,因为这些模型缺乏跨会话保留上下文的能力 [3][11]。同时,汇编一个 参考包,包含 8–10 张锚定图像,在中性光照条件下从多个角度(正面、侧面、四分之三和全身)展示角色 [9][11]。
在技术层面,LoRA 训练 可以将特定元素——如面部结构或服装图案——直接嵌入模型的参数中,实现 85–92% 的角色准确率,相比之下单纯依赖提示词仅有 23% [3]。对于更精细的细节,IP-Adapter 等工具可确保精确的面部特征控制,而 ControlNet 有助于维持一致的姿态和空间定位 [6][13]。LoRA 训练也很经济实惠,每个角色模型通常成本在 5 到 15 美元之间 [13]。像 APIMart 这样的平台通过 Hailuo 03 的 全局身份 VAE 和 Sora 2 的 character_url 参数等工具进一步简化了这一流程,免去了自定义训练的需要。
有两个工作流习惯能在维持一致性方面产生巨大影响:
- 将角色描述符放在每个提示词的开头。 AI 模型会根据 token 的顺序对其优先排序,因此把身份细节埋在提示词靠后的位置会削弱其影响力 [11]。
- 每 5–8 个场景检查一次连贯性。 这有助于及早发现并纠正漂移,防止其演变成更大的问题 [12]。
「『AI 生成内容』与『AI 电影』之间的差距在于一致性。弥合这一差距,你就不只是在生成图像——你是在讲故事。」——Sofia Chen,CinemaDrop 增长与市场负责人 [11]
遵循这些步骤,你就能确保视觉和叙事上的双重一致性,让你的角色为面向不同受众的无缝改编做好准备。
为不同受众改编故事
一旦你的角色身份被锁定,你就可以为各种受众改编他们的叙事,同时保持其核心特质不变。一致性并不意味着刻板——你的角色可以在多种情境下都保持亲和力,无论是面向课堂还是在董事会上做汇报。秘诀在于保留角色的视觉和行为内核,同时调整语言、语气、场景和文化参照等元素。
像 APIMart 这样的平台让这一过程可规模化。集中式的角色嵌入让一个虚拟代言人在跨市场时保持相同的外观,同时适应不同的语言或本地化环境 [6]。这与虚拟网红的运作方式类似。到 2026 年初,这些网红占据了 4.2% 的市场份额,并实现了 5.67% 的互动率——几乎是其真人对手的三倍 [6]。
| 方案 | 一致性 | 受众灵活性 | 最适合 |
|---|---|---|---|
| 纯文本 | 低 | 高 | 抽象或通用场景 |
| 文本 + 图像 | 高 | 中 | 品牌内容、角色叙事 |
| 统一流水线 | 极高 | 高 | 剧集系列、多市场活动 |
对于教育内容,可将语气调整得更平易近人、简化词汇,并让场景与主题相匹配——同时保持核心角色身份不变。对于娱乐内容,只需改变场景的情境,同一个角色就能扮演高风险的电影级角色。角色圣经 保持不变,只有周围的元素在变化。
结论与关键要点
多模态 AI 对故事创作的关键益处
多模态 AI 重新定义了创作者所能达成的目标。过去需要大型团队、高昂预算和数月努力才能完成的任务,如今可以在不到一小时内完成——而且成本只是零头 [2]。这一转变对以角色为驱动的故事创作而言是颠覆性的,在保持叙事流畅的同时大幅缩短了制作时间。
但这不仅仅关乎速度和成本。多模态 AI 为故事创作带来了全新层次的深度和连贯性。它能无缝管理角色弧线、因果动态和主题一致性等元素——而这些正是各自为政的工具常常难以应付的任务。例如,2026 年的一项调查显示,当依赖碎片化工具时,63% 的写作者花在编辑 AI 生成内容上的时间比创作原创素材还多 [14]。统一的多模态方法消除了这种低效中的大部分。
「简单的聊天机器人用来写邮件没问题,但当你需要连贯的叙事时它们就不行了。」——SidekickWriter [14]
通过简化创作流程,多模态 AI 不仅让故事创作更加便捷,也提升了质量和一致性的标准。这些工具赋能创作者以更少的阻力,打造出更丰富、更引人入胜的叙事。
使用 APIMart 的下一步
如果你已准备好将这些进展付诸实践,APIMart 提供了一个简单直接的解决方案。它通过单一的 OpenAI 兼容 API 端点(api.apimart.ai/v1)提供对 500 多个 AI 模型的访问——涵盖文本、图像和视频。这个统一的系统免去了管理多个 API 密钥、计费账户或在不同提供商之间切换的麻烦。
要入门,可以考虑先用一个经济实惠的模型进行草稿和内部审阅。一旦你完善了叙事,再切换到高端模型来获得最终的精致输出。为了保持角色外观的一致,请复用 seed 参数。而为了控制成本,先在 720p 下验证你的输出,再扩展到 1080p 或 4K 分辨率。这种方法能让你有效地在质量和预算之间取得平衡。
常见问题
阻止跨场景角色漂移最快的方法是什么?
避免角色漂移最快的方法是使用一张 参考图像 作为视觉指南。一张展示多个角度的角色设定图可以帮助模型保持面部几何结构、比例和服装的一致。像 APIMart 这样的工具让你能轻松地将这些多模态输入集成到工作流中。将视觉锚点与一致的提示词模板和固定种子结合,能确保稳定性,减少不断手动微调的需要。
我需要 LoRA 训练,还是参考图像就够了?
在决定是否使用 LoRA 训练时,一切都取决于你的角色外观需要多高的一致性。对于短片段或单个场景,参考图像通常就能奏效。你只需上传一张图像,或依赖之前的帧来保持角色身份的完整。
然而,如果你的项目跨越多个场景——比如一部网络剧集——那么 LoRA 训练就成了更好的选择。它能提供更高的保真度,但也需要额外的付出。你需要 15–30 张高质量图像,以及多一些技术上的专业知识才能做好。
我该如何将脚本拆分成用于 AI 视频的分镜卡片?
Subject(主体):Alex,一位二十五六岁的年轻艺术家,头发凌乱,身穿溅满颜料的工装裤,坐在一间小公寓的杂乱木桌前。
Action(动作):Alex 正专注地在一本大笔记本上素描,偶尔停下来瞥一眼钉在墙上的参考照片。他咬着铅笔末端,陷入沉思。
Environment(环境):房间被一盏台灯昏暗地照亮,四周散落着装满美术用品的架子和未完成的画布。背景中的一扇窗户展现出暮色中熙熙攘攘的城市景观。
Camera Direction(镜头指引):镜头以 Alex 专注表情的特写开始,然后缓缓拉远,展现这个凌乱却充满创意的空间。
Tone(基调):氛围亲密而内省,强调 Alex 的专注以及其工作空间中安静的能量。
Audio(音频):背景中播放着一段柔和的器乐钢琴曲,混合着微弱的城市声响,如远处的汽车喇叭声和模糊的人声。
Scene 2
Subject(主体):Alex 走出公寓楼,此时身穿深色连帽衫和牛仔裤,一本速写本夹在腋下。
Action(动作):他快步走在拥挤的人行道上,躲避行人,偶尔抬头望向头顶高耸的摩天大楼。
Environment(环境):街道充满生机——霓虹灯闪烁,街头小贩向路人叫卖,汽车愤怒地鸣笛。
Camera Direction(镜头指引):镜头从后方以中景距离跟随 Alex,捕捉他穿过熙攘人群的动作。镜头偶尔切换到高耸建筑的低角度镜头,强调城市令人震撼的规模。
Tone(基调):这一场景显得充满活力与生机,用城市的喧嚣与上一场景的孤独形成对比。
Audio(音频):声景中充满了层叠交织的城市噪音——脚步声、闲谈声、汽车鸣笛声——营造出一种紧迫感和能量感。
Scene 3
Subject(主体):Alex 抵达一座宁静的公园,在小池塘边找到一条僻静的长椅。他坐下,打开速写本,开始作画。
Action(动作):Alex 在素描时,偶尔抬头望向平静的水面,鸭子从那里滑过。一阵微风拂乱了他的头发。
Environment(环境):公园安宁祥和,高大的树木在午后渐晚的光线中投下长长的影子。池塘倒映着落日的金色光辉。
Camera Direction(镜头指引):镜头以公园的全景开始,然后过渡到 Alex 素描的中景。它停留在他的手在纸页上移动的细节上,捕捉其画艺的流畅。
Tone(基调):氛围平静而沉思,与先前的喧嚣形成对比,提供了片刻的宁静。
Audio(音频):树叶沙沙作响和鸟儿啁啾的轻柔声响伴随着这一场景,还有附近喷泉传来微弱的潺潺流水声。
Scene 4
Subject(主体):一位陌生人,一位身穿粗花呢夹克、戴着帽子的年长男士,走近 Alex,好奇地端详他的速写本。
Action(动作):这位男士对 Alex 的画作发表了评论,引发了一段简短的对话。Alex 羞涩地微笑,显然对这番赞美感到受宠若惊。
Environment(环境):场景保持不变,公园沐浴在落日的温暖光辉中。
Camera Direction(镜头指引):镜头在 Alex 和男士的中景之间交替,捕捉他们的表情和肢体语言。一个特写突出了 Alex 转动速写本展示更多作品时的微笑。
Tone(基调):这次互动显得温暖而振奋人心,暗示了两位因艺术而相遇的陌生人之间的一种连接。
Audio(音频):公园的环境声持续着,其上层叠着他们对话的微弱低语。
Scene 5
Subject(主体):夜幕降临,Alex 走在回家的路上,城市此刻被路灯和明亮的窗户照亮。
Action(动作):他在一个小吃摊前停下,买了一个热狗,坐在附近的长椅上吃了起来。在两口之间,他翻看着速写本,为自己的进步而微笑。
Environment(环境):街道此刻更安静了,人更少,氛围更凉爽、更放松。小吃摊上蒸汽升腾,空气感觉清冽。
Camera Direction(镜头指引):镜头以中景捕捉 Alex,由小吃摊温暖的灯光衬托。一个特写展现他的手翻动速写本的书页,露出精细的画作。
Tone(基调):氛围满足而内省,以一种成就感为这一天的旅程画上句号。
Audio(音频):背景中轻柔地播放着一段舒缓的爵士乐曲,与偶尔驶过的汽车嗡鸣声以及小吃摊传来的滋滋声交融在一起。
Related Blog Posts
去模型市场挑选你想要的模型
在 APIMart 模型市场尝试聊天、图像和视频模型,用统一 API 快速体验模型能力。