
多模型 API 与单模型 API 成本分析对比
对比多模型与单模型 API 的成本——使用费率、集成与维护开销以及分层路由——找出总成本更低的方案。
如果只看 API 的标价,我很可能会忽略账单中最大的那部分。 在本次对比中,对于月支出低于 $5,000 的单一稳定任务,成本更低的方案往往是单模型;而当我面对混合型工作负载、多模态使用或高流量时,多模型通常更占优势。
简短版本如下:
- 单模型意味着一个供应商、一个 SDK、一套计费设置。
- 多模型 API 意味着一次集成即可向众多模型发送请求。
- API 直连价格只是成本的一部分。
- 隐性成本通常来自:
- 工程搭建
- 每月维护
- 安全与合规审查
- 计费与供应商管理
- 直连供应商的工作每月每个供应商可能耗费 3–8 小时,按 $100/hour 计算约为 $300–$800/month。
- 初始的直连集成可能需要 40–80 小时。
- 每增加一个供应商,每年可能多出约 4.2 个工程周。
- 使用多模型方案的团队将生产级 agent 上线的速度约快 3x:3.6 周 vs. 11.2 周。
- 按模型层级进行路由分配可以削减开支,例如:
- 55–70% 分配给低成本模型
- 20–30% 分配给中端模型
- 5–15% 分配给前沿模型
- 在使用计费方面,本文展示了统一接入成本更低的示例:
- GPT-5 Nano: $0.05 vs. $0.0625 per 1M input tokens
- Claude Sonnet 4.5: $1.80 vs. $3.00
- Imagen 4.0: $0.04 vs. $0.05 per call
如果要用一句话概括:在小规模、固定范围的场景下单模型往往更便宜;而一旦规模、路由和团队时间开始变得重要,多模型往往能削减总成本。
LLM 应用的成本优化技巧——更快、更省、可扩展的 AI | Uplatz
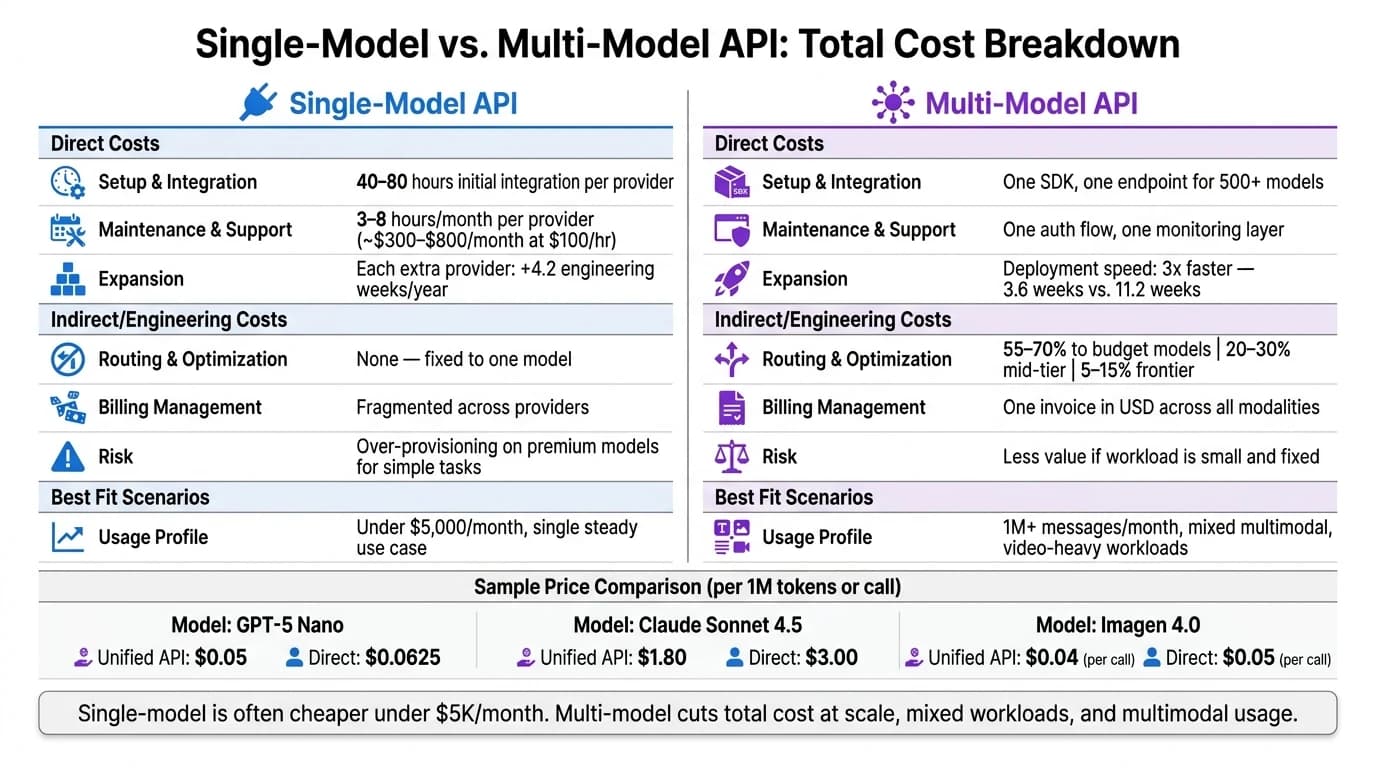
快速对比
| 评估标准 | 单模型集成 | 统一多模型 API |
|---|---|---|
| 搭建 | 一个直连供应商连接 | 一个连接接入众多模型 |
| 使用契合度 | 最适合单一稳定用例 | 最适合混合且不断增长的工作负载 |
| 计费 | 一份供应商账单 | 跨模型一份账单 |
| 按价格/质量路由 | 否 | 是 |
| 额外供应商工作 | 随每个供应商增长 | 保持在同一层内 |
| 工程开销 | 起初较低,随后攀升 | 范围扩大时更低 |
| 最佳成本场景 | 月支出低于 $5,000、固定任务 | 1M+ messages/month、多模态、视频密集 |
| 主要风险 | 为简单任务在单一高端模型上多付费 | 若工作负载小且固定,价值较低 |
我会用这篇文章来做一个基于全部成本的决策,而不仅仅是基于价目表的决策。
单模型集成的成本结构
直接成本:面向窄工作负载的使用费与计费
单模型集成让计费保持简单:一个供应商,一套定价设置。对于只有一个主要用例的早期产品来说,这种简单性很有帮助。你只有一份账单、一份价目表,需要打理的环节也更少。
话虽如此,简单并不总意味着便宜。如果使用量激增,超额费用可能随之而来。而在企业级层面,一些供应商会要求最低承诺量。这种设置在需求保持窄且易于预测时效果最好。
间接成本:集成、维护与合规工作
账单只是整体图景中的一部分。大量的开支其实在账单之外。
一支中型团队直接集成一个供应商,预计需要 40–80 小时的初始集成工作 [2]。这通常意味着编写适配器代码、处理诸如 429 和 5xx 响应之类的供应商错误、搭建重试逻辑,以及处理 API 密钥轮换。这就是所谓的集成税。
而且它不会在上线之后就停止。模型更新仍需关注。监控仍要占用工程时间。合规工作也可能带来更多投入。除此之外,单模型设置把数据暴露交到了一个供应商手中,这可能增加集中度风险。
单模型何时更便宜、何时变得昂贵
当工作负载稳定且窄时,单模型设置能保持成本高效。这就是它的甜蜜点。
麻烦始于团队把每个任务——即便是简单的任务——都跑在同一个高端模型上。这就是过度配置开始侵蚀开支的地方。而当产品范围扩大时,各自独立的供应商集成会迅速堆积。每新增一个直连供应商集成,在初始搭建和持续维护上估计要用掉 4.2 个工程周 [1]。这种开销累积得很快。
按工作负载来看,情况通常是这样的:
| 场景 | 单模型成本表现 |
|---|---|
| 稳定用例、低流量 | 成本低,易于预测 |
| 稳定用例、流量激增 | 面临超额费用和最低承诺量的风险 |
| 多个任务跑在单一高端模型上 | 过度配置推高开支 |
| 随时间增加更多集成 | 维护成本更高、计费更分散 |
单模型设置往往起步精简。但随着范围扩大,成本也会随之攀升。下一节将按工作负载类型对这些成本进行对比。
统一多模型 API 的成本结构
来自整合接入与灵活模型选择的直接节省
单模型设置往往比应有的成本更高,因为团队最终会过度购买。统一 API 改变了这一点。你不必把每个任务都发给同一个模型,而可以把简单的工作发给低成本模型,把更强的模型留给那些真正需要它们的任务。
这从两个明确的方向上转移了成本:常规任务交给更便宜的模型,而更难的任务仅在需要时才使用高端模型。在实践中,这种路由能以有意义的方式削减开支。
计费也变得更简单。文本、图像和视频的使用都汇总到一份以 USD 计价的账单上,这意味着财务的整理工作更少,跨供应商核对费用所花的时间也更少。
到 2026 年 4 月,企业级 token 成本同比下降了 67%,很大程度上是因为在低成本选项足以胜任时,团队把工作从昂贵的前沿模型上分流出去 [1]。一种常见的设置是分层堆栈:
- 将 55–70% 的流量路由到成本高效型模型
- 仅保留 5–15% 给前沿模型 [1]
来自跨众多模型的一次集成的间接节省
单模型系统的搭建负担并不会在团队增加更多供应商时消失。它会变得更糟。每个新供应商都可能意味着又一套认证流程、又一套监控设置、又一条治理路径,以及又一轮维护。
统一 API 能及早遏制这种滚雪球效应。你只需搭建一套认证流程、一层监控、一层治理。搭建一次,它便可在 API 背后的每个模型上生效。
这一点很重要,因为每当新增一个供应商,集成开销就会增长。有了统一层,这部分工作会被收拢到一个连接里,而不是散布在众多连接之中。
使用多模型基础设施的团队部署生产级 AI agent 的速度快 3x:3.6 周对比 11.2 周 [1]。在管道搭建上花的时间越少,用于交付的时间就越多。
以 APIMart 作为该模式的实践示例
一个平台示例能让定价差异更容易被看清。
APIMart 展示了统一接入在日常中的运作方式:一个 API、一套计费流程,以及跨文本、图像和视频的模型接入。
它的视频模型阵容也说明了为什么路由很重要。MiniMax Hailuo 2.3 Fast 定价为 $0.025/second,是一个快速、低成本的选项。Kling V3 Omni 定价为 $0.0672/second (720p),以中端价位契合电影级输出。Sora 2 Preview 定价为 $0.08/second,在质量与成本之间取得平衡。Vidu Q3 Pro 定价为 $0.12/second,适合要求更高、需要高性能的生成任务。
| 模型 | 价格 | 最适合 |
|---|---|---|
| MiniMax Hailuo 2.3 Fast | $0.025/sec | 高速、低成本的视频生成 |
| Kling V3 Omni (720p) | $0.0672/sec | 电影级画面与中端成本 |
| Sora 2 Preview | $0.08/sec | 质量与成本的平衡 |
| Vidu Q3 Pro | $0.12/sec | 最适合复杂、高性能的生成 |
| 统一多模型 API | 单模型集成 | |
|---|---|---|
| 计费 | 一份以 USD 计价的账单 | 跨供应商分散 |
| 集成工作 | 一个 SDK、一个端点 | 每个供应商独立搭建 |
| 路由灵活性 | 按成本或质量路由 | 固定于一个模型 |
| 更新 | 供应商更新集中处理 | 逐供应商手动更新 |
| 最佳契合 | 混合、增长中的工作负载 | 单任务、低流量应用 |
下一节将按工作负载类型对这些节省进行对比。
按工作负载类型的直接成本对比
本次对比使用的成本指标
只有把成本与你正在运行的工作类型挂钩,它才有意义。
需要对比的主要数字是 cost per 1M input tokens、cost per image call、cost per video second 以及每月 USD 支出。相比只看标价,这些数字能让你更好地读懂工作负载的总成本。
几个例子就能把差距说清楚。GPT-5 Nano 通过 APIMart 的成本为 $0.05 per 1M input tokens,而直连为 $0.0625。Claude Sonnet 4.5 为 $1.80 对比 $3.00。Imagen 4.0 为 $0.04 per call 对比 $0.05。在一个小项目上,这或许感觉不大。但在规模化时,累加起来很快。
单模型往往成本更低的工作负载
对于窄而可预测的工作负载,路由通常帮不上多少忙。
想想一条单一的内部摘要流水线,或另一种输入规模稳定的固定范围工作流。如果月支出保持在 $5,000 以下且任务始终如一,那么在多个模型间进行路由通常在日常中没有多少价值。在这种设置下,直连集成往往是成本更低的路径。
多模型往往降低总支出的工作负载
一旦流量上升、且不止一种模态进入画面,路由就开始变得重要。
混合型和高流量工作负载往往会改变账目。如果一支团队在生成文本、图像和视频——或者处理每月 1M+ 条聊天消息——随着任务分散到不同用例,成本会攀升。这正是多模型设置能省钱的地方:把简单请求发给低成本模型,把高端模型留给更难的任务。
| 工作负载类别 | 预计月支出 | 关键成本驱动因素 | 可能成本更低的方案 |
|---|---|---|---|
| 高流量聊天(1M+ messages/month) | $10,000–$25,000 | 输出 token 量;推理 token | 多模型(把简单任务路由到预算型模型) |
| 混合多模态(text + image + video) | $15,000+ | 多模态算力 | 多模型(整合计费、单一 SDK) |
| 视频密集型创意(100+ hrs/mo) | $25,000+ | 每秒渲染费率 | 多模型(高端视频模型最高可省 20%) |
| 稳定的内部工具(摘要) | 低于 $5,000 | 固定使用量;低复杂度 | 单模型(若不需要路由灵活性) |
预算框架与最终决策指南
面向美国团队的分步预算方法
用上面的工作负载模式把定价转化为预算决策。这个方法分三步。
先从基准成本开始。首先按所有流量都跑在一个高端模型上来定价。这给你一个上限,让你在测试其他路由设置之前,就能看到最可能出现的最高支出。
接着计算分层路由成本。把 55–70% 的流量发给成本高效型模型,20–30% 给中端模型,把前沿模型留给需要复杂推理的 5–15% 任务。然后按各层在总量中的占比及其每 token 费率进行加权,得出一个成本更低的组合。
然后计算总成本。给两种方案都加上工程开销。每增加一个供应商集成,每年约增加 4.2 个工程周 [1]。这些时间是有金钱成本的,而且它能很快改变决策。
一旦把使用量和开销都加进来,更好的方案就是全部月成本更低的那个。
何时选择单模型、何时选择多模型
当你只有一个稳定用例且复杂度低时,单模型设置效果最好。它更简单、更易管理,对于窄需求往往已经足够好。
当工作负载混合、使用量增长,或冗余性变得重要时,多模型设置更有意义。如果一些任务简单、另一些需要更深的推理,在模型层级间进行路由分配可以削减开支,同时不会把你锁死。
APIMart 提供一个 API 接入 500+ models,随着 AI 使用量的增长,削减重复的集成工作。
结论:最低的账单并不总是最低的总成本
某个模型上很低的每 token 费率,在电子表格里看起来可能很棒。但那个数字并不能展示整张账单。集成时间、维护周期和故障切换逻辑都会增加成本。统一多模型接入从设计上就有助于减少许多这类隐性成本。
关键要点:
- 使用价格只是总成本的一部分。
- 当工作负载混合或多模态时,分层路由能削减开支。
- 集成开销随每新增一个供应商而上升。
- 单模型契合稳定、窄的用例。
- 多模型契合增长中、多模态的工作负载。
常见问题
如何计算 API 定价之外的总成本?
先把目光从 token 定价上移开一会儿。更大的消耗往往来自日常中同时打理多个供应商的工作。
这不只是为 API 使用付费。还有额外的工程时间——用于构建适配器层、处理错误、编写自定义重试逻辑,以及管理一大堆各自独立的 API 密钥。这些工作累加得很快。在许多团队里,仅集成维护每月就要花 15–20 小时。
安全性又增添了一层成本。当访问令牌分散在不同供应商时,治理会变得更难。孤立的密钥更容易被遗留下来,这可能导致浪费性开支和没人能及时察觉的成本泄漏。
像 APIMart 这样的统一平台可以把这些分散的环节汇入一个仪表盘,让访问控制和支出跟踪更易于管理,同时减少手动开销。
多模型 API 什么时候会比单个模型更便宜?
当你使用智能的任务-模型路由而非一刀切的设置时,多模型 API 会变得更便宜。
基本思路是这样的:把分类、摘要和数据抽取等更简单的工作发给低成本模型。然后把高端模型留给更复杂或更高风险的工作。仅这一个转变就能把 AI 成本削减 30% 到 80%。
APIMart 让这件事更容易——它接入 500+ models,并提供统一计费、批量定价以及跨 AI 工作负载的聚合折扣。
哪些工作负载最能从模型路由中受益?
模型路由最适合高流量、成本敏感的工作负载,尤其是任务难度在不同请求之间变化的场景。基本思路很简单:把简单的工作发给低成本模型,把前沿模型留给难题。
这让路由非常契合分类、打标签、摘要和后台数据丰富等工作。在这些场景中,很大一部分请求并不需要最昂贵的模型就能完成任务。
它还能帮助:
- 高流量批处理
- 延迟敏感的面向用户应用
- 资源密集型任务,如视频生成
- 在推理、工具和检索之间切换的 agentic 工作流
去模型市场挑选你想要的模型
在 APIMart 模型市场尝试聊天、图像和视频模型,用统一 API 快速体验模型能力。