
优化视频提示词:文本 vs 图像
对比文本生视频、图像生视频和混合提示词在 AI 视频生成中的应用,并就品牌一致性、创意控制、成本和质量提供指导。
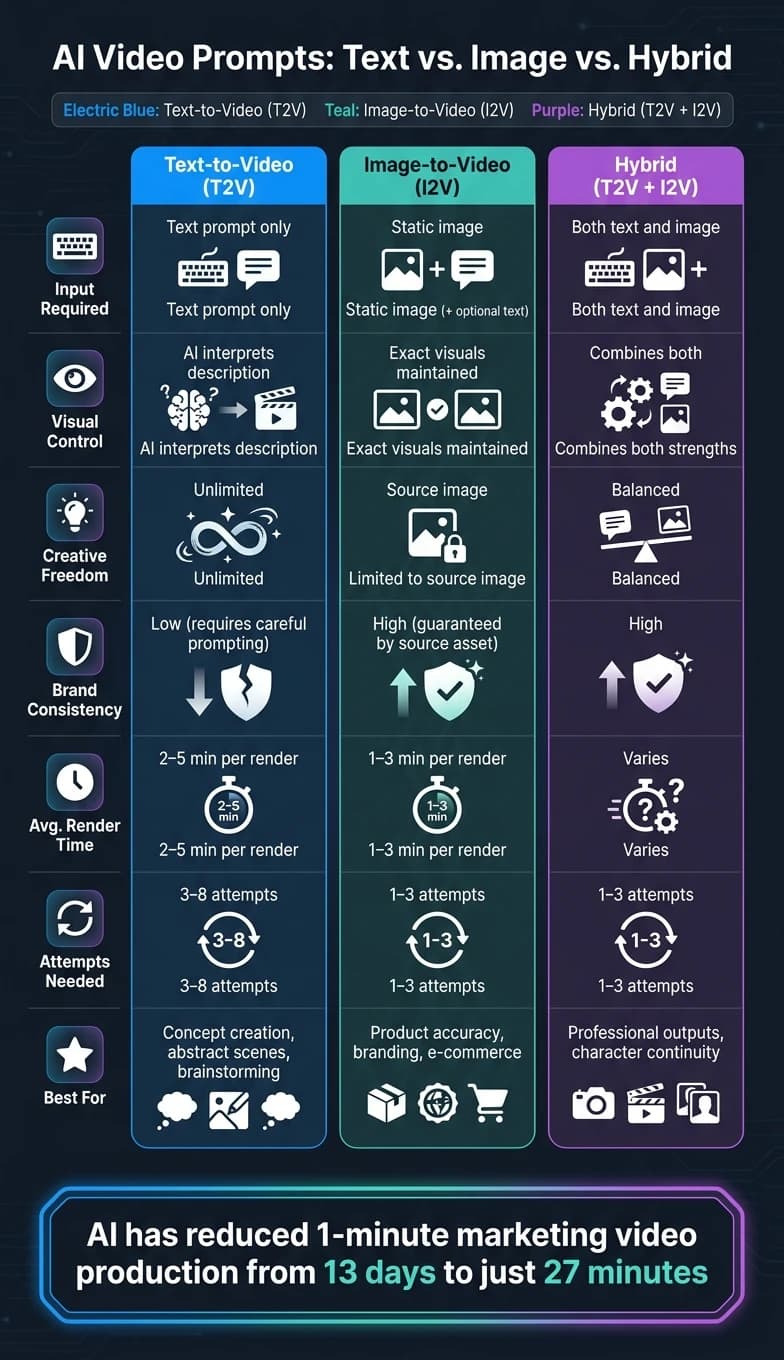
在 AI 视频生成中,你对提示词的选择——文本生视频(T2V) 还是 图像生视频(I2V)——会显著影响结果。以下是快速概览:
- 文本生视频:适合创造全新的视觉效果。最适合头脑风暴、测试概念或生成抽象场景。要获得高质量结果需要详细的提示词,但提供了灵活性。
- 图像生视频:完美适合保持准确性。上传一张静态图像,AI 会让它动起来。最适合产品展示、品牌塑造,或当一致性至关重要时。受限于所上传图像的语境。
- 混合方法:结合两种方法以实现精确度和控制力。用图像保证视觉一致性,用文本引导运动或风格。
关键考量:
- T2V 提供自由度,但需要精确的提示词工程。
- I2V 确保准确性,但将创意限制在输入图像之内。
- 时间和成本效率各不相同:T2V 需要更多迭代,而 I2V 用更少的尝试就能更快地得到结果。
快速对比:
| 特性 | 文本生视频 | 图像生视频 | 混合 |
|---|---|---|---|
| 所需输入 | 仅文本 | 静态图像(+文本) | 两者皆需 |
| 视觉控制 | AI 解读文本 | 保持输入图像 | 结合两者优势 |
| 创意范围 | 无限 | 受限于图像 | 平衡 |
| 品牌一致性 | 需要努力 | 高 | 高 |
| 理想用例 | 概念创作 | 产品准确性 | 专业级输出 |
结论:用 T2V 来构思新想法,用 I2V 来保证精确度,二者结合则用于电影级 AI 视频生成和精致的成果。
文本提示词与图像提示词:关键差异
什么是文本提示词?
文本提示词本质上是一条书面指令,告诉 AI 要创造什么。你从零开始,构建从场景、灯光到氛围、镜头运动的一切。由于没有视觉参照,模型完全依赖其训练数据,从而提供大量创意可能性。例如,你可以描述一些完全天马行空的内容,比如一架无人机飞越火星上发光的峡谷,而 AI 会努力将你的设想变为现实。
但随着这一切自由而来的是一个挑战:含糊的提示词可能导致平淡的结果。要获得最佳输出,你需要在 10 个特定类别 中加入细节:主体、风格、灯光、环境、氛围、构图、运动、镜头、时长和音频。大多数用户会跳过其中几个,这往往导致泛泛的输出——想想那些灯光平淡的静态镜头吧。
“文本生视频和图像生视频并不能互换。它们在潜在空间中以不同的约束条件运作,知道何时使用哪一个,正是电影级输出与无法使用的生成结果之间的区别。”——Sarah Iruoje [1]
相比之下,图像提示词提供了一个视觉起点,为创作过程奠定基础。
什么是图像提示词?
图像提示词以一张静态图像作为基础开始。AI 不再从零生成一切,而是让图像动起来,添加运动和其他元素。这种方法让模型对主体的外观有了清晰的理解。
这对于 视觉准确性至关重要 的项目尤其有用,比如品牌或产品方面的工作。例如,如果你上传一张产品图像,AI 会保留它的形状、颜色和布局。角色保持一致,标志不会变形。这使得图像生视频成为电子商务、产品营销以及任何需要保持原始外观的场景的首选。不过,代价是你的创意范围被限制在图像中已有的内容之内——你无法创造出全新的东西。
“作为一名电影制作人,你最大的敌人是随机性。你不希望 AI 去‘猜测’你的主角长什么样;你希望它为你已经设计好的角色赋予动态。”——AIAI.com [10]
多模态提示
通过结合文本提示词和图像提示词的优势,多模态输入提供了一种强大的创作方式。这些工作流到 2026 年正成为标准,它们将视觉参照与描述性的文本指令配对。图像锁定主体的视觉细节,而文本规定运动或镜头行为。例如,你可以上传一张产品照片,并加上一条文本指令,比如“柔和影棚灯光下缓慢推近(dolly-in)”,以控制场景如何展开。
像 APIMart 这样的平台让这一过程变得无缝。它们允许用户在单一 API 内利用 Kling V3 和 Sora 等工具,在融合文本和图像输入时无需在不同工具或工作流之间切换。
| 因素 | 文本生视频 | 图像生视频 |
|---|---|---|
| 所需输入 | 仅文本提示词 | 静态图像(+可选文本) |
| 视觉控制 | 模型解读描述 | 保持精确的视觉效果 |
| 创意自由度 | 无限 | 受限于源图像语境 |
| 品牌一致性 | 低(需谨慎的提示词) | 高(由源素材保证) |
| 学习曲线 | 较高(提示词工程) | 较低(上传并生成) |
文本提示词:优势与局限
文本提示词的优势
文本提示词在激发创意方面大放异彩。仅用几个描述性的词语,你就能塑造出整个场景。它们支持快速实验——无论你是在数百个 AI 模型中测试不同的氛围、风格还是场景创意。想从粗粝的都市背景切换到阳光普照的海岸场景?只需调整几个词再重新生成即可。文本生视频模型还擅长从其训练数据中提取内容,这可能带来富有想象力的结果,尤其是在城市景观、自然序列或奇幻环境等抽象视觉效果上,这些可以用 Grok Imagine Video 等模型来生成。
但是,正如任何工具一样,也存在一些取舍。
文本提示词的局限
文本提示词最大的挑战在于缺乏精确度。没有视觉参照,模型常常做出不可预测的决定。这可能导致角色、品牌颜色、标志位置或产品细节在多个片段之间出现不一致。另一个障碍呢?模型往往难以处理复杂的物理交互——比如逼真的手部抓握、同步动作或稳定的文字渲染。 [9][4]
要应对这些挑战,使用一些经过验证的策略至关重要。
文本提示词的最佳实践
改善结果最有效的方法之一是使用 结构化的 10 槽位格式:主体 + 动作 + 环境 + 风格 + 镜头 + 灯光 + 运动 + 氛围 + 时长 + 音频。 [9][4] 跳过其中任何一个元素都可能导致质量较低的输出。例如,一条精心制作的房地产提示词可能是这样的:“缓慢摇臂下移,现代住宅外观,宽广的定场镜头,黄金时刻灯光,电影级风格。”
以下是一些进一步打磨输出的额外技巧:
- 带时间戳的动作块:加入带时间戳的动作以获得更好的控制,尤其是在 Sora 2 等模型中。例如:“0–3 秒:主体进入画面;3–6 秒:拿起信封。” 这种方法有助于管理节奏,并减少不规律或不可预测的运动。 [4]
- 负面提示词:使用负面提示词字段来避免常见问题,比如 “模糊、低质量、扭曲、水印。” 这些排除项有助于确保更干净的结果。 [11]
- 一致的种子值:在多次生成中坚持使用相同的种子值。这让你能够微调细节而无需从头开始,节省时间和精力。 [1][4]
图像提示词:优势与局限
图像提示词的优势
当你需要精确的视觉效果时,图像提示词是首选。你不再仅仅依赖文本,而是上传一张图像,AI 将其用作参照点。这种方法对于产品演示、房地产导览或品牌内容等场景尤其有效。为什么?因为一张图片可以即刻传达诸如产品包装的确切色调、标志的位置或材料的质感等细节——这些是仅凭文字难以精准把握的 [2][7]。
另一个巨大的优势是效率。使用图像生视频(I2V)工作流,通常只需 1–3 次生成就能得到想要的结果,而文本提示词则需要 3–8 次尝试。这是因为构图、灯光和颜色等基础元素从第一帧起就已设定好 [6][7]。
图像提示词的局限
缺点呢?灵活性受到了影响。由于视频锚定于你的参照图像,从零开始创造全新的场景便不在选项之内。此外,输入图像的质量很重要——一张光线不佳、分辨率低或构图别扭的图像会直接影响最终输出 [2]。
运动也可能很棘手。微妙的面部变化、扭曲的手部,或像珠宝、衣物上的文字等消失的细节,都可能扰乱片段的流畅度。下表概述了不同的镜头类型及其相关风险:
| 镜头类型 | 风险 | 最适合 |
|---|---|---|
| 微妙运动 | 低 | 干净的面部、产品完整性、稳定的背景 |
| 缓慢推近/平移 | 低 | 电影氛围、专业营销 |
| 激烈运动 | 高 | 动作场景(可能需要重试) |
| 快速环绕/变焦 | 高 | 动态转场(容易产生伪影) |
截至 2026 年,大多数模型在 5 到 15 秒之间的片段上效果最佳。对于更长的视频,更稳妥的做法是在后期制作中将较短的片段拼接在一起,以保持各帧之间细节的一致性 [6][9]。
图像提示词的控制选项
为应对这些挑战,你可以调整若干控制设置。像 APIMart 这样的平台,搭配 Kling V3 等模型,让你能够调节运动强度、片段时长和提示词权重等参数。这些设置有助于平衡文本指令相对于参照图像的影响程度 [12]。
使用固定的种子值是另一个明智之举。它让你能够在多次生成中微调运动方向和强度,而不会丢失原始图像的视觉一致性 [12]。为获得最佳效果,请将高质量的参照图像与微妙的运动设置以及锁定的种子搭配使用。这种方法往往只需一到两次尝试就能交付干净、精致的片段。
何时使用文本、图像或两者兼用
用例对比
在文本生视频和图像生视频之间做选择,归根结底取决于你手头已有哪些素材。
“在文本生视频和图像生视频 AI 模型之间的选择,其实并不是一个技术决策。它关乎你带着什么走进来。”——Eachlabs Team [2]
如果你正在处理一个尚无任何视觉素材的概念或产品——比如一个未上市的创意——文本生视频是你的最佳选择。它让你无需任何摄影就能从零创造视觉效果。另一方面,如果你已经拥有专业的产品照片或品牌图像,图像生视频通常是更好的方式。这能确保视频中的视觉效果与实际产品完美契合,这对于减少退货的电子商务来说尤为重要 [3][7]。
| 场景 | 推荐输入 | 原因 |
|---|---|---|
| 新品牌,无现有素材 | 文本生视频 | 无需摄影即可从零创造视觉效果 [3] |
| 产品展示或演示 | 图像生视频 | 确保视频与真实产品精确匹配 [7] |
| 抽象或超现实的广告概念 | 文本生视频 | 捕捉无法拍摄的隐喻性创意 [3] |
| 跨片段的角色连贯性 | 混合(图像 + 文本) | 参照图像锁定身份;文本引导动作 [10] |
| 专业品牌内容 | 混合(图像 + 文本) | 将视觉锚点与运动结合以获得精致的结果 [1] |
这些选择还取决于成本和渲染时间等实际因素。
美国团队的实际考量
预算和时间安排所起的作用往往不亚于创意目标。文本生视频通常每次渲染需要 2–5 分钟,并可能需要 3–8 次尝试才能做对,而图像生视频更快,平均 1–3 分钟、1–3 次尝试 [7][8]。在更大规模的制作中,这些时间差异会不断累积。
成本是另一个关键考量。APIMart 的定价凸显了这些选择会如何影响你的工作流。例如,Wan 2.5 (图像生视频) 每次生成仅需 5 个积分(约 $0.39),非常适合对准确性要求高的大批量电子商务 [3]。如果你追求电影级质量,每次生成 60 个积分的 Sora 2 Pro 是高端选择。对于标准质量需求,8 个积分的 Veo 3.1 Fast 则取得了平衡 [3]。总体思路是:在早期阶段的创意上,先从成本较低的文本生视频模型起步,然后在最终成品上过渡到图像生视频或混合工作流。
结合文本提示词和图像提示词
将文本提示词和图像提示词一起使用,可以帮助你将创意与精确度相结合,从而两全其美。
“文本生视频 = 想象与探索;图像生视频 = 一致性与控制;混合 = 专业级输出。”——Sarah Iruoje,VidAU.ai [1]
一种有效的方法是 “先生成静帧” 技巧。先使用文本生图模型创建一张能捕捉到你想要的构图的静态图像。然后,使用图像生视频模型为那张静帧添加运动 [2][7]。另一种颇具前景的工作流被称为 积木系统,它将一则视频广告拆分成不同的部分。例如,你可以用文本生视频模型创作一个引人注目的电影级开场,接着用图像生视频片段呈现准确的产品细节,最后以一个品牌叠加层来收尾,作为行动号召 [3]。每个部分——或者说“积木”——都使用最适合其角色的输入类型,从而打造出一个连贯而有效的最终视频。
图像生视频 vs 文本生视频:为何起始帧在控制力上胜出
结论:为你的目标选择正确的提示词类型
这里的决策过程归结为一个简单的起点:用你已经拥有的东西来工作。 如果你一开始没有视觉素材,文本生视频是快速试验各种想法的好办法。另一方面,如果你已经有了获批的图像,图像生视频则是保持品牌一致性的首选。为获得最佳效果,结合两种方法可能会带来质的飞跃。
这里有一个数据可以帮你看清形势:AI 已将一分钟营销视频的制作时间从 13 天压缩到仅仅 27 分钟 [5]。你所选择的提示词类型决定了你实际能挖掘出多少这样的效率。文本生视频在头脑风暴阶段表现出色,图像生视频确保最终输出的精确度,而混合工作流则为专业团队带来他们所需的精致成果。
一种值得采用的实用技巧是 “通用核心”策略。这涉及制作一个聚焦于一致主体和场景的模块化提示词,同时添加针对特定模型的参数。使用种子一致性来稳定视觉效果,也能减少为得到一个可用片段所需的生成次数。
像 APIMart 这样的平台让多模态工作流更加无缝。系统会根据你的输入自动选择合适的生成模式:没有图像默认为文本生视频,一张图像触发图像生视频,两张图像则激活首尾帧模式 [12]。通过单一 API 即可访问超过 500 个模型——包括 Sora 2、Veo 3.1 和 Kling V3——你可以轻松地在各种策略之间切换,而无需在多个平台或计费系统之间周旋。这种精简的工作流简化了创作过程。
归根结底,并不存在放之四海而皆准的解决方案。最佳的提示词类型取决于你可用的素材、你的截止日期,以及你的项目所需的视觉一致性程度。通过精通每一种方法,你可以减少反复试错的循环,更快地交付成果。
常见问题
我该如何为我的项目在文本生视频和图像生视频之间做选择?
在 文本生视频 和 图像生视频 之间的选择,取决于你在创意和一致性方面想要实现什么。
- 文本生视频 在你专注于叙事、生成抽象视觉效果,或从头开始试验全新想法时效果很好。
- 图像生视频 更适合那些保持一致视觉风格至关重要的场景,比如品牌内容或涉及反复出现角色的项目。
为了让事情更简单,APIMart 会替你处理这一决策。它会根据你的输入自动选择最合适的模式,确保流畅的集成。
怎样的文本提示词才算“足够详细”以获得好的视频结果?
一条强有力的文本提示词会从笼统走向明确,勾勒出 主体、动作、环境、镜头运动和风格。加入精确的细节——比如独特的特征或特定的灯光——有助于消除歧义,并确保更一致的结果。借助 APIMart,你可以更进一步,将视觉参照作为锚点纳入其中。这种方法可确保品牌标识或角色设计等关键细节在你的整个视频内容中保持一致。
我如何在多个 AI 视频片段中保持角色或产品的一致性?
要创作出一致的 AI 生成视频片段,依靠多模态输入而非仅仅依靠文本提示词会更好。纯文本提示词可能导致不一致,因为模型必须自行填补所有细节。通过使用 APIMart 等工具将你的文本提示词与参照图像配对,你便为 AI 在角色、标志和产品等元素上提供了清晰的视觉指引。为获得最佳效果,请确保你的参照图像分辨率高、光线充足,并能从多个角度展示主体。
去模型市场挑选你想要的模型
在 APIMart 模型市场尝试聊天、图像和视频模型,用统一 API 快速体验模型能力。