
无需重写代码即可切换AI模型
了解统一AI API如何通过一个端点连接500+模型,借助配置驱动路由、适配器层和A/B测试,在APIMart上轻松切换模型。
在不同AI模型之间切换可能令人头痛——不同的提供商意味着不同的配置、SDK和响应格式。但有更好的方法。统一AI API让你通过单一接口连接多个模型,切换模型就像更新一个配置项一样简单。这种方式节省时间、减少错误,并确保你的应用不依赖于单一提供商。
以下是你将学到的内容:
- 统一AI API通过标准化端点、认证和参数来简化集成。
- 像APIMart这样的工具,只需一个API密钥和端点即可连接500+模型。
- 集中管理配置、构建路由层等设计技巧,让模型切换更加轻松。
- A/B测试和监控确保在尝试新模型时平稳过渡。
统一API消除了大规模重写的需求,让你专注于为当前任务选择合适的模型。
理解统一AI API
什么是统一AI API?
统一AI API就像是连接多个AI模型的一站式服务。你不需要为每个提供商——无论是OpenAI、Anthropic、Google还是其他——管理不同的配置,而是获得一个统一的接口来处理幕后的一切。无需深入了解每个提供商的集成细节。
采用这种方式,切换模型变得轻而易举。只需更新一个字符串值,而不是重构认证或核心逻辑。这使得统一API成为想要简化多模型集成、无需大规模重写的理想选择。
| 概念 | 统一AI API | 单一提供商API |
|---|---|---|
| 端点 | 单一基础URL(如 https://api.apimart.ai/v1) | 每个提供商有独立URL |
| 认证 | Authorization: Bearer KEY | 每个提供商方式各异 |
| 模型选择 | "model": "string-id" | 因SDK或URL路径而异 |
| 供应商锁定 | 低——通过配置更改切换 [5] | 高——迁移困难 |
统一API集成的核心组件
统一API集成依赖四个主要元素:基础URL、模型标识符、API密钥和环境变量。
- 基础URL用一个通用地址替换所有提供商特定的端点,从而简化配置 [1]。
- 模型标识符(如
"gpt-4o"或"claude-opus-4")告诉网关使用哪个AI模型。 - API密钥确保通过统一网关的安全访问。
- 环境变量让配置更改无需触及生产代码即可完成。
使用统一网关的优势之一是每个请求仅增加约3ms到50ms的额外延迟 [4]。与模型本身处理请求所需时间相比,这几乎可以忽略不计。此外,这些网关通常还处理一个棘手问题:参数归一化。不同提供商对相同功能使用不同术语。例如,控制模型严格遵守提示的参数,在Flux和Google中称为guidance_scale,在Stability中称为cfg_scale,在OpenAI中称为quality [3]。统一API消除这些差异,让你无论使用哪个提供商都能使用一致的参数。
OpenRouter:支持300+AI模型的单一API
如何构建易于切换模型的应用架构
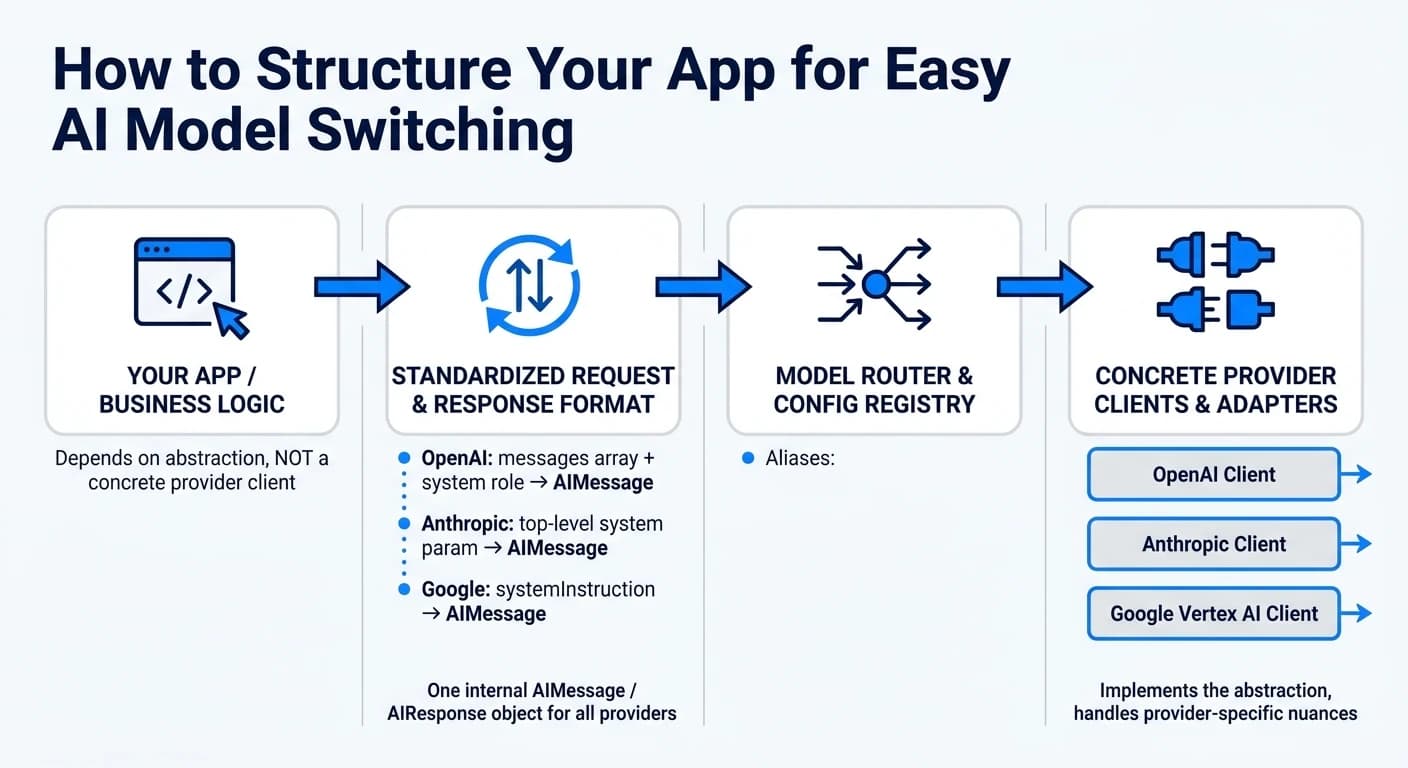
要充分发挥统一API集成的价值,关键是将应用设计成在不同模型之间灵活切换的架构。核心原则是将业务逻辑与API特定逻辑分离。工程师兼创始人Tian Pan解释道:
"你的业务逻辑应该依赖于语言模型的抽象,而不是OpenAI或Anthropic的具体客户端。" [6]
这种方式不仅仅是为了写出更整洁的代码——它也是避免高昂代价的明智之举。迁移一个与单一提供商紧密绑定的中型生产系统,工程时间成本可能高达5万到10万美元 [6]。以下策略可以帮助你构建规避这些问题的应用架构。
标准化请求和响应格式
创建单一的内部格式,如AIMessage接口或AIResponse对象,无论使用哪个模型都保持一致 [2]。适配器层可以将每个提供商的独特特性转换为这种标准格式,无需在代码中进行大范围修改。
例如,各提供商处理请求和响应的方式各不相同:OpenAI使用带有system角色的messages数组,Anthropic需要顶级system参数,Google则选择systemInstruction [2][9]。在响应方面,OpenAI将内容放在choices[0]中,而Anthropic使用content[0]。通过实现适配器层,你可以消除这些不一致,节省切换模型时的时间和精力。
集中管理模型配置
在中央配置文件中使用"text-fast"或"reasoning-premium"等描述性别名来表示特定的模型ID [7]。这种方法利用统一API隔离提供商特定细节的能力,确保业务逻辑不受影响。当新模型版本发布或你想测试更经济的选项时,只需更新一行代码,而不必在整个应用中搜索。
你还可以更进一步,使用提供商注册表,将每个别名链接到在运行时动态创建正确客户端的工厂函数 [6][7]。这样,应用的其余部分无需知道也无需关心使用的是哪个提供商。
构建模型路由层
路由层作为应用与提供商之间的中间人,决定哪个模型处理每个请求。例如,你可以设置基于规则的路由器,将复杂查询发送到高级模型,将简单任务发送到更快、更低成本的选项 [10]。该层与统一API协同工作,降低管理多个提供商的复杂性。
一个真实案例:2026年4月,一家SaaS公司通过路由层将简单任务分配给廉价模型,将高要求查询保留给高级模型,将每日LLM成本削减了58%,从1,420美元降至594美元 [8]。路由层还管理429或5xx等错误的自动回退,确保运营顺畅 [2][8]。
如何使用APIMart切换模型
将APIMart用作中央模型枢纽
APIMart通过单一端点https://api.apimart.ai/v1提供对500多个文本、图像、视频和音频任务模型的集中访问,简化AI模型管理。只需一个API密钥、统一的请求格式和集中化设置,模型间的切换即可无缝进行。
例如,如果你在使用Python或Node.js的OpenAI SDK,只需将base_url指向APIMart的端点即可。从GPT-5切换到Claude 4.6 Sonnet?只需更新model字符串——无需接触新的SDK或认证流程。
这种设置对需要快速实验的团队特别有用。无需为每个AI提供商创建单独的集成,你可以依靠一个简化的集成,并根据需要调整配置。
根据项目需求切换视频模型
在视频生成方面,选择正确的模型至关重要。每个模型在成本、质量和速度方面都有其权衡,具体取决于任务需求。APIMart通过同一API提供多个视频模型选项,简化了这一流程,让你无需更改工作流即可选择最适合项目的模型。
以下是一些热门选项的快速比较:
| 模型 | 价格 | 最适合 |
|---|---|---|
| MiniMax Hailuo 2.3 | $0.025/秒 | 快速、经济的草稿 |
| Kling V3 Omni(720P) | $0.0672/秒 | 多模态输入和通用性 |
| Sora 2 Preview | $0.08/秒 | 高质量创意输出 |
例如,MiniMax Hailuo 2.3非常适合速度和成本优先的早期草稿或内部头脑风暴会议。如果需要同时使用文本和图像输入来创建短视频,Kling V3 Omni是可靠的选择。对于质量至关重要的面向客户的营销活动,选择Sora 2 Preview。由于这些模型共享相同的请求结构,切换只需更新一个配置值。
这种灵活性也让在项目中集成多模态工作流变得更加容易。
使用单一API运行多模态工作流
APIMart的统一API旨在以最小的工作量处理多模态工作流。通过在单一流水线中串联不同类型的模型,你可以在各个步骤调整模型标识符,无需担心认证、计费或变更跟踪。
以下是内容生产流水线的示例:
| 步骤 | 模型示例 | 任务 |
|---|---|---|
| 1. 脚本创作 | GPT-5 | 创建创意简报和视频提示词 |
| 2. 分镜设计 | Flux Pro | 根据脚本生成参考图像 |
| 3. 视频合成 | Kling V3 Omni | 将图像转化为电影感片段 |
| 4. 最终精修 | Sora 2 Preview | 输出高质量最终场景 |
保持此流水线易于管理的秘诀在于配置驱动方式。将模型标识符、输入格式和参数(如resolution、duration、aspect_ratio)等细节集中到一个配置对象中。这样,如果需要替换步骤3中的视频模型,可以在不影响前面脚本创作或图像生成步骤的情况下进行更改。
对于视频和图像任务,APIMart以异步方式处理它们,提供task_id供你使用指数退避(从10–20秒开始)轮询结果,直到任务完成。
安全高效切换模型的最佳实践
要充分利用APIMart的统一API集成,在配置管理、监控和安全方面遵循关键实践,对于顺畅安全的模型过渡至关重要。
模型配置的版本控制与测试
管理模型配置时,像对待代码一样对待它。使用版本控制跟踪模型标识符、参数和路由规则的更改。这样,如果出现问题,可以快速回滚到以前的版本。保留详细的变更历史有助于在切换模型时排查问题。
在生产环境中部署新模型之前,进行A/B测试。将一小部分实时流量路由到新模型,并将其性能与现有模型进行比较。这种方式基于真实使用情况而非仅仅测试数据提供洞察。对于额外的质量检查,使用LLM-as-judge设置。例如,GPT-5或Claude 4.5等模型可以评估新模型输出的1–5%样本,在影响用户之前识别细微的质量问题 [8]。
自动化健康检查是另一个关键工具。设置周期性测试请求(例如轻量级的5-token补全),每60到120秒执行一次。这有助于及早检测提供商的中断,降低等到用户投诉才发现问题的风险 [2]。
监控和记录模型性能
模型上线后,密切关注延迟、成本和错误率等指标。延迟,尤其是P95响应时间(第95百分位),是关键指标。例如,如果一个模型需要30秒才能响应,即使技术上以HTTP 200成功响应,对面向用户的应用来说也几乎无法使用 [2][8]。
"一个模型包打天下的时代已经结束。为每个请求选择合适的工具,你的AI账单将下降40–70%。" - Akshay Ghalme,AWS DevOps工程师,BytePhase Technologies [8]
你的日志还应捕获已解析的模型元数据,详细记录哪个模型处理了每个请求。这在回退场景中尤为重要。如果经济型模型频繁升级到高级模型(比如超过30%的时间),这就是路由逻辑需要调整的信号 [8]。
除性能监控外,保护API凭证对于不间断运营至关重要。
保护API密钥安全并保持合规
强大的安全措施对于维护稳定的多模型环境、确保模型无缝过渡而不暴露漏洞至关重要。使用APIMart的单一API密钥来限制攻击面。将密钥安全存储在环境变量或密钥管理器中,避免硬编码或提交到版本控制系统。
对于在受监管行业运营的团队,合规是必须的。正如Akshay Ghalme所指出的:
"路由必须遵守合同/法规约束——某些数据绝不能离开特定地区或供应商。" [8]
确保你的路由逻辑遵守数据驻留规则。使用支持SOC 2合规、单点登录(SSO)和集中审计日志的网关。此外,实施每个租户的支出上限以防止意外费用,特别是在客户可能有不同使用层级或数据要求的多租户设置中 [8]。
最后,将自动回退保留给特定错误类型。例如,对429(超出速率限制)和5xx(服务器错误)响应使用回退,因为切换模型可以解决这些问题。避免对400 Bad Request之类的4xx错误使用回退,这些通常表示模型切换无法修复的格式错误输入 [2]。
结论:借助统一AI API获得灵活性
统一AI API让AI模型之间的切换简单到只需调整配置——无需大量编码或系统重构。
通过标准化请求和响应格式、集中管理模型配置,以及通过单一接口路由所有内容,你消除了切换模型时复杂工程工作的需要。无论你选择哪个模型,应用逻辑都保持不变。
以APIMart为例。其连接500多个模型(涵盖文本、图像和视频生成)的单一端点,让团队可以轻松切换模型。想象一个美国电商团队对两个语言模型进行A/B测试,用于产品描述。他们可以在APIMart中调整路由规则,以美元跟踪结果,比较转化率——所有这些都无需部署新代码。这种简化的流程帮助团队快速适应不断变化的项目需求。
这种设置也能随你扩展。无论是为增加的流量扩展规模,还是集成高级视频生成器或特定领域模型等尖端工具,这种统一方式都能保持简洁。开发者的入职更快,系统可以在不中断核心应用的情况下应对新技术。
统一AI API的强大之处在于将灵活性直接嵌入到你的架构中。模型过渡成为常规调整,而非重大工程任务。这种适应性确保你随时准备好应对未来的变化。
常见问题
如何在不重构所有内容的情况下向现有应用添加模型切换功能?
要实现无需重写代码的无缝模型切换,考虑使用统一API网关。将SDK的基础URL指向像APIMart这样的网关,你就能轻松管理模型选择、路由和故障转移。这种设置允许你调整配置——例如在代码中动态更新模型参数——而无需触及认证、SDK逻辑或错误处理。网关负责标准化这些流程,为你节省时间和精力。
模型路由层应该包含什么(何时应该避免回退)?
模型路由层作为连接应用与不同AI模型的枢纽。其职责是管理请求映射、基于成本效益选择模型、实施故障转移策略和监控性能。为保持稳定性,使用依赖特定任务基准的配置驱动路由图。
对于需要精确单一模型执行的特殊任务,避免针对语义或质量问题的回退机制。这种方式确保严格的质量控制,避免结果妥协。
如何在不影响生产环境的情况下安全地A/B测试新模型?
要在不影响生产的情况下测试新AI模型,首先以_影子模式_运行该模型。在这种设置下,生产流量同时发送到现有模型和新模型。当前模型继续为用户提供服务,而新模型在后台处理输入,让你能在不影响实时运营的情况下比较结果。
一旦验证了新模型的性能,可以使用统一API网关或功能标志等工具进行渐进式推出。这些工具允许你仔细监控性能指标,并设置回滚触发器,以在出现任何问题时保持系统稳定性。
去模型市场挑选你想要的模型
在 APIMart 模型市场尝试聊天、图像和视频模型,用统一 API 快速体验模型能力。