
Cultural Adaptation Best Practices for Video AI
How to adapt AI video for global markets — cultural cues, language and voice, bias, a transcreation pipeline, governance, and per-market performance metrics.
If I want video AI to work in more than one market, I can’t just translate the script. I need to check speech, gestures, colors, clothes, humor, on-screen text, units, and review rules. That matters because video models still miss the mark often: one cited benchmark puts faithfulness at 56.8% and behavior below 52.1%.
Here’s the short version:
- Translation is not enough. Word swaps miss tone, jokes, symbols, and social behavior.
- Video adds risk. A good voice track can still fail if the gesture, color, or spacing feels wrong. Advanced models like Google Veo 3.1 offer synced audio and cinematic control to help mitigate these risks.
- Data shape outputs. Many models lean toward Western defaults in looks, accents, and behavior.
- Prompting helps, but people still matter. One 2026 test showed a 14.3% lift from a multi-agent prompt setup.
- A repeatable pipeline beats one-off fixes. Script changes, text expansion, dubbing, lip-sync, subtitles, legal review, and final QA all need a set flow.
- Governance is part of the job. Consent for voice clones, likeness use, and symbol use should be documented before release.
- Market-level metrics tell me what worked. I should track watch time, CTR, CPA, comments, sentiment, complaints, and revision rates by locale.
A few details stand out. German copy can run 20%–30% longer than English, so pacing and sync need adjustment. Design also needs room for text growth, often around 15%–30%. And for U.S. viewers, I should use formats like 06/26/2026, $, miles, and °F.
What this comes down to is simple: I should treat this as a release process, not a last-minute edit. That means clear tags for identity, behavior, and context, prompt guardrails, native-speaker review, policy checks, and post-launch tracking.
Core Cultural Factors Video AI Systems Must Address
Visual Cues, Symbols, and Social Norms
Visual choices - clothing, gestures, colors, food, and spacing - carry meaning right away.
Color is a simple example. White often signals purity in many Western settings, but in some Asian cultures it can signal mourning [8][9]. Clothing matters just as much. A video aimed at more conservative markets may call for modest attire, while a Japanese business setting usually points to formal suits [9]. Even the distance between people on screen can send a message, since personal space norms change from one market to another.
Gestures and everyday interactions are often the toughest part to localize. A model trained mostly on Western media may default to a handshake for a greeting. But gestures that seem harmless in the U.S. can offend in other places - the thumbs-up in parts of the Middle East, the "OK" sign in Brazil, or pointing feet toward someone in Thailand [9]. That means gesture choice can't be treated as a neutral default. It has to be handled as a market-specific output constraint.
Language, Voice, and On-Screen Text Details
Language adaptation goes far beyond word replacement. Tone and formality shift by market. U.S. copy often sounds direct and upbeat, while Japanese copy often comes across as more polite and indirect [9]. Humor is even trickier. A joke that works in one place may fall flat - or land badly - in another. So the target is the same feeling, not a literal translation.
Voice pacing is also a technical issue, not just a writing one. German text runs about 20–30% longer than English, which means audio timing has to change [3]. If pacing stays the same, dubbed audio starts drifting away from graphics and subtitles.
For U.S. audiences, formatting details matter too:
- Dates should use month/day/year, such as 06/26/2026
- Prices should appear in U.S. dollars
- Distances should use miles
- Temperatures should use Fahrenheit [1]
Spoken audio is only part of the job. On-screen text - titles, lower thirds, and calls to action - needs the same market-by-market treatment. In AI-generated video, such as content created with MiniMax-Hailuo-02, burned-in text should be regenerated for each market. In live-action video, motion-tracked localized overlays help handle text expansion [3].
Bias, Representation, and Fairness in Generated Media
Many video AI models were trained on datasets that lean heavily toward Western, English-language media. The result is pretty direct: outputs often default to Western aesthetics, accents, and social norms, even when the prompt never asks for them [5][8]. Researchers call this the "WEIRD" problem - training data shaped by Western, Educated, Industrialized, Rich, and Democratic contexts, while other groups get less representation [8].
You can see this in the outputs. Characters from minority communities may be pushed into background roles without agency, which turns into tokenism. Non-Western accents may get flattened or neutralized. The same visual style may keep showing up, making other markets feel like an afterthought. In some cases, the models that look best score worst on cultural faithfulness [5].
"Cultural sensitivity is easiest to build in before the first frame is shot." - Sarah Miller, Author, Vozo [8]
A useful way to review outputs is across three dimensions: identity, behavior, and context. Use identity, behavior, and context as the checklist for dataset curation and output review. For large-scale projects, you can access 500+ AI models through a unified gateway to test these dimensions across different systems.
How to Build and Tune Video AI for Cultural Accuracy
Curate Datasets and Metadata for Cultural Coverage
Start with tagging. Before training, define cultural tags and metadata in a way that goes past broad labels. Each clip should be tagged across Identity, Behavior, and Context. A workplace greeting in Tokyo, for instance, should note the formality level, social hierarchy, and the setting itself - not just a country tag [6].
Interaction labels help a lot here because social meaning often lives in small moments. Useful categories include Expressives like Thanks, Apology, Greeting, and Farewell, along with Directives like Requesting/Rejecting Information [6]. That gives the model more than a map pin. It gives the model a social scene.
Geographic tokens on their own aren't enough. Instead, use prompts or metadata with specific visual details. One example is using multimodal vision analysis to describe a kimono by its left-over-right lapels instead of calling it "traditional Japanese clothing" [5]. That kind of detail helps the model stop guessing from broad cues and start matching what people would actually expect to see.
Once the data is tagged, use prompt-time controls to guide generation.
Combine Prompting, Guardrails, and Human Review
Data helps, but it doesn't solve output on its own. Prompts and guardrails need to back it up. A flat, one-line prompt often misses too much nuance. A stronger setup is multi-agent prompting, where separate agents handle the person, action, and location before merging the result [7].
In May 2026, researchers at Santa Clara University tested this through the MAVEN framework. Using the prompt "a Chinese person playing guzheng at the Potala Palace", the multi-agent pipeline reached a Cultural Relevance Score of 0.271. That was a 14.3% lift over the base model's 0.237. The output also picked up details like a qipao-inspired updo and specific hand techniques for the instrument [7].
Prompting is only part of the job. You also need policy guardrails for sensitive material and human review for cases where meaning can slip through the cracks. Set aside native-speaker review time for each language. AI still has trouble with nuanced non-verbal signals like gaze direction, interpersonal distance, and emotional tone [6][3].
Run Structured Cultural Quality Checks on Outputs
After generation, review each clip using the same cultural tags used during training. A simple approval pass won't hold up at scale. If you're making video for many markets, you need a checklist, not a gut feeling [5].
That checklist should cover a few plain questions:
- Do the gestures fit the market?
- Are symbols and color meanings used in the right way?
- Do the visuals avoid clichés or stereotyped depictions?
Behavior is usually the hardest part to nail. That's where human reviewers tend to matter most. A structured checklist makes review more consistent and keeps the bar the same across teams and markets.
Why Localization Still Needs Humans Even with AI
Workflows for Multilingual and Cross-Cultural Video at Scale
Once cultural checks are done, the next job is keeping that same bar across every market.
Build an End-to-End Transcreation Pipeline
After quality checks, scale with a repeatable transcreation pipeline. That means clear owners, smart automation, and human sign-off where it matters.
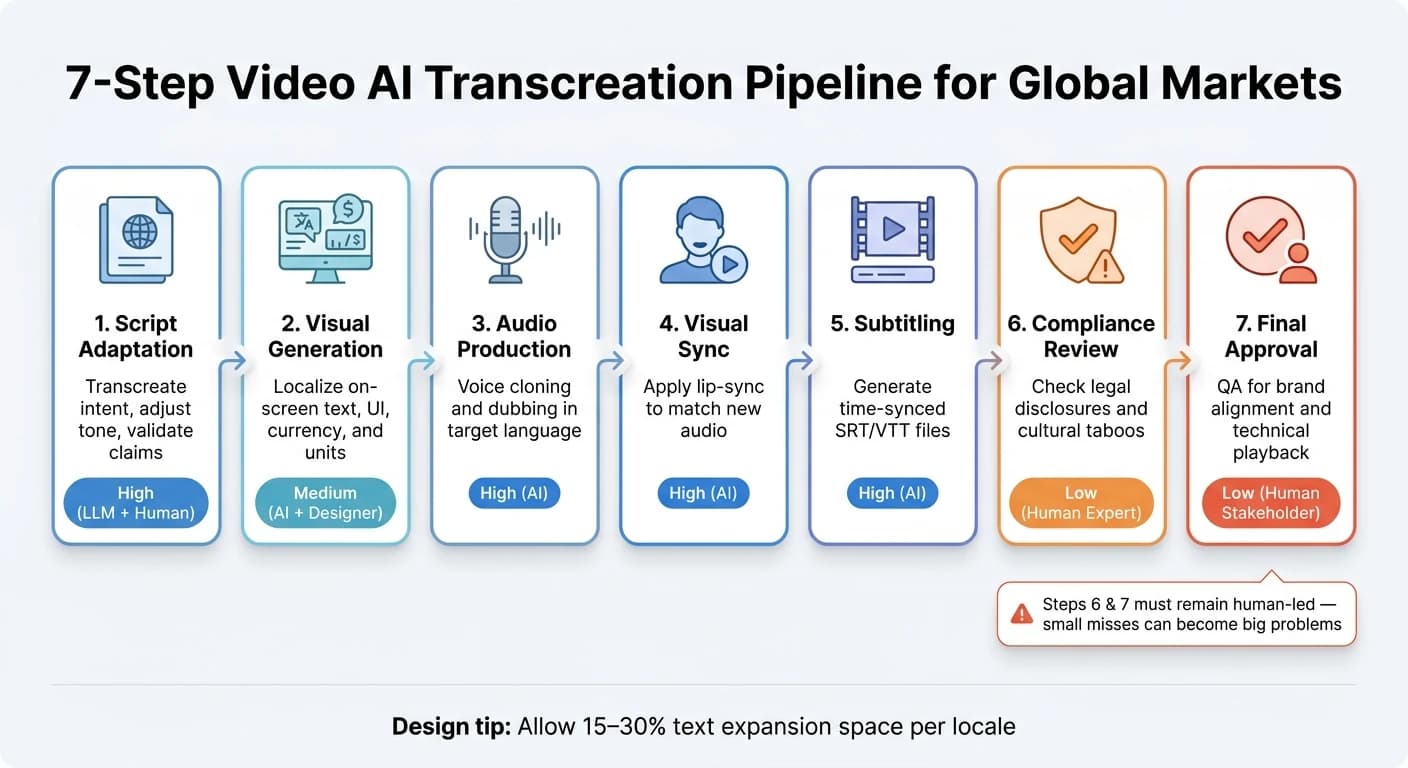
Here’s the seven-step flow:
| Step | Action | Automation Level |
|---|---|---|
| 1. Script Adaptation | Transcreate intent, adjust tone, validate claims | High (LLM) + Human Review |
| 2. Visual Generation | Localize on-screen text, UI, currency, and units | Medium (AI + Designer) |
| 3. Audio Production | Voice cloning and dubbing in target language | High (AI) |
| 4. Visual Sync | Apply lip-sync to match new audio | High (AI) |
| 5. Subtitling | Generate time-synced SRT/VTT files | High (AI) |
| 6. Compliance Review | Check legal disclosures and cultural taboos | Low (Human Expert) |
| 7. Final Approval | QA for brand alignment and technical playback | Low (Human Stakeholder) |
Two parts should stay human-led: compliance review and final approval. Those are the places where small misses can turn into big problems.
It also helps to lock the master script before localization begins. If the source script changes late, every language version needs rework. That slows the whole pipeline and adds cost fast. On the design side, leave room for text expansion - about 15% to 30% - and keep key product details above subtitle and UI zones [10].
The point isn’t only speed. It’s making sure meaning, tone, and trust hold up in each market.
Track Performance by Market and Audience Response
Once the videos are live, the next step is simple: check whether each locale is reacting the way you hoped.
Publishing localized video is only half the work. Without market-level data, it’s hard to spot a mismatch until it starts hurting the campaign - or the brand. A video can look fine on paper, hit the right specs, and still feel off to the people watching it.
Track these metrics by locale on a steady basis:
- Engagement: view rates, completion rates, watch time, and click-through rates (CTR)
- Conversion: leads, sales, revenue, and cost per acquisition (CPA) by language
- Audience response: comments in the target language, shares, sentiment, and complaint or revision rates
- Creative performance: top-performing languages, best video length by market, and top posting times
Complaint and revision rates deserve extra attention. A spike in either one for a specific locale is often the first sign that something missed the mark. Catching that early is much cheaper than dealing with a full recall or a public response later.
Use APIMart to Centralize Model Orchestration and Cost Control
To keep the pipeline steady, it helps to run orchestration through one API layer.
A multi-market video workflow usually means juggling script models, voice models, image models, and video generation models like Veo 3.1 - sometimes all in the same run. APIMart links those steps through a single API and carries context metadata across the workflow, including social norms, currency formats, and dialect flags. You can route both draft and final passes through one API to keep context, logging, and cost control lined up across markets.
Governance, Risk Management, and Key Takeaways
Set Policies for Sensitive Content and Consent
Once localization is live, governance is what keeps quality, consent, and approvals steady across markets.
Start with representation policies. These should ban stereotyping, cultural appropriation, and minority erasure [11]. They should also spell out how teams handle sacred symbols, flags, and colors. A small detail can change the meaning of a scene. For instance, white can signal mourning in some Asian cultures, while in many Western settings it points to purity [8][11].
Representation rules cover what shows up on screen. Consent rules cover who can appear and how they can appear. Consent for likeness and voice needs to be explicit and specific. Talent releases should cover AI dubs, voice clones, and lip-sync edits for new markets [2]. And if you're dealing with community-owned symbols, ceremonies, or imagery, policy should require consultation with community representatives before anything is used [11].
On the documentation side, use Model Cards and datasheets to record dataset provenance, licensing terms, collection methods, and known cultural biases [11]. Set up a Cultural Safety Board to review risk assessments and approve high-impact releases. It also helps to run quarterly red-teaming so teams can spot failure modes before launch [11].
| Policy Area | What to Document |
|---|---|
| Likeness & Voice | Talent releases covering AI dubs, voice cloning, and lip-sync edits |
| Cultural Symbols | Approved/restricted symbols, colors, and gestures by market |
| Model Versions | Model Cards with training data, known biases, and licensing |
| Approvals | Cross-functional review and release sign-offs |
Key Takeaways for Teams Deploying Cultural Adaptation in Video AI
With policy set, the next step is steady review and release control.
Cultural adaptation in video AI is not a one-time checklist. It's a system that needs repeatable workflow, clear policy, review, and monitoring at each stage. The teams that handle this well don't treat it like a last-minute edit. They build it into the release process from the start.
Define culture broadly. It includes identity, behavior, and context in every frame, not just the words on screen [5]. Pair prompt guardrails with human review, especially for gestures, greetings, and other non-verbal cues, where current models still miss things [6]. Before each release, audit policy breaches, reviewer escalations, and market complaints.
After launch, track performance by market using KPIs like view-through rate, sentiment, and engagement. That helps teams spot where the localized experience isn't landing as intended [2][4]. Release approval should stay tied to policy review, red-team findings, and market-level feedback.
Treat cultural adaptation as a monitored release process, not a one-time launch task.
FAQs
How do I audit cultural accuracy before launch?
Use both automated checks and human review. Go frame by frame with in-market stakeholders to review language, tone, brand fit, and playback. Then test with native focus groups to catch misreadings or unintended offense before anything goes live.
Tools such as CultureScore can help flag mismatches across identity, behavior, and context. If it fits your process, APIMart can help make localization work easier. But don’t stop there - always confirm the final output with local experts.
When should human reviewers step in?
Human reviewers matter at a few key points if you want the work to feel right and stay on-brand.
In pre-production, they should review cultural concepts and scripts so bias gets caught early, not after the work is already far along. After translation, native speakers should check tone, intent, and local relevance.
A two-stage approval process also makes sense: sign off on translated audio before lip-sync rendering, then complete native-speaker QA to confirm cultural fit, compliance, and messaging.
Which metrics best show if localization worked?
Track both business results and audience feedback.
The main signals to watch are:
- higher conversion rates
- more watch time
- stronger engagement
- better local search performance from multilingual SEO
If you want a deeper read on what’s working, don’t stop at surface-level analytics. Pair those numbers with internal data and social media sentiment.
And if you’re reviewing AI-generated content, use the CultureScore framework to check cultural faithfulness across identity, behavior, and context.
Choose the model you want in the model marketplace
Try chat, image and video models in the APIMart model marketplace, and experience model capabilities quickly with one unified API.