
Multi-Model API vs. Single Model Cost Analysis
Compare multi-model and single-model API costs — usage rates, integration and maintenance overhead, and tiered routing — to find the lower total cost.
If I only look at API list prices, I can miss the biggest part of the bill. In this comparison, the lower-cost path is often single-model for one steady task under $5,000/month, while multi-model often wins when I have mixed workloads, multimodal usage, or high volume.
Here’s the short version:
- Single-model means one provider, one SDK, and one billing setup.
- Multi-model API means one integration that can send requests across many models.
- Direct API price is only part of cost.
- Hidden cost often comes from:
- Engineering setup
- Monthly maintenance
- Security and compliance review
- Billing and vendor admin
- Direct provider work can take 3–8 hours per month per provider, or about $300–$800/month at $100/hour.
- Initial direct integration can take 40–80 hours.
- Each extra provider can add about 4.2 engineering weeks per year.
- Teams using multi-model setups shipped production agents about 3x faster: 3.6 weeks vs. 11.2 weeks.
- Routing work by model tier can cut spend, such as:
- 55–70% to lower-cost models
- 20–30% to mid-tier models
- 5–15% to frontier models
- For usage pricing, the article shows examples where unified access was lower:
- GPT-5 Nano: $0.05 vs. $0.0625 per 1M input tokens
- Claude Sonnet 4.5: $1.80 vs. $3.00
- Imagen 4.0: $0.04 vs. $0.05 per call
If I had to put it in one line: single-model is often cheaper at small, fixed scope; multi-model often cuts total cost once scale, routing, and team time start to matter.
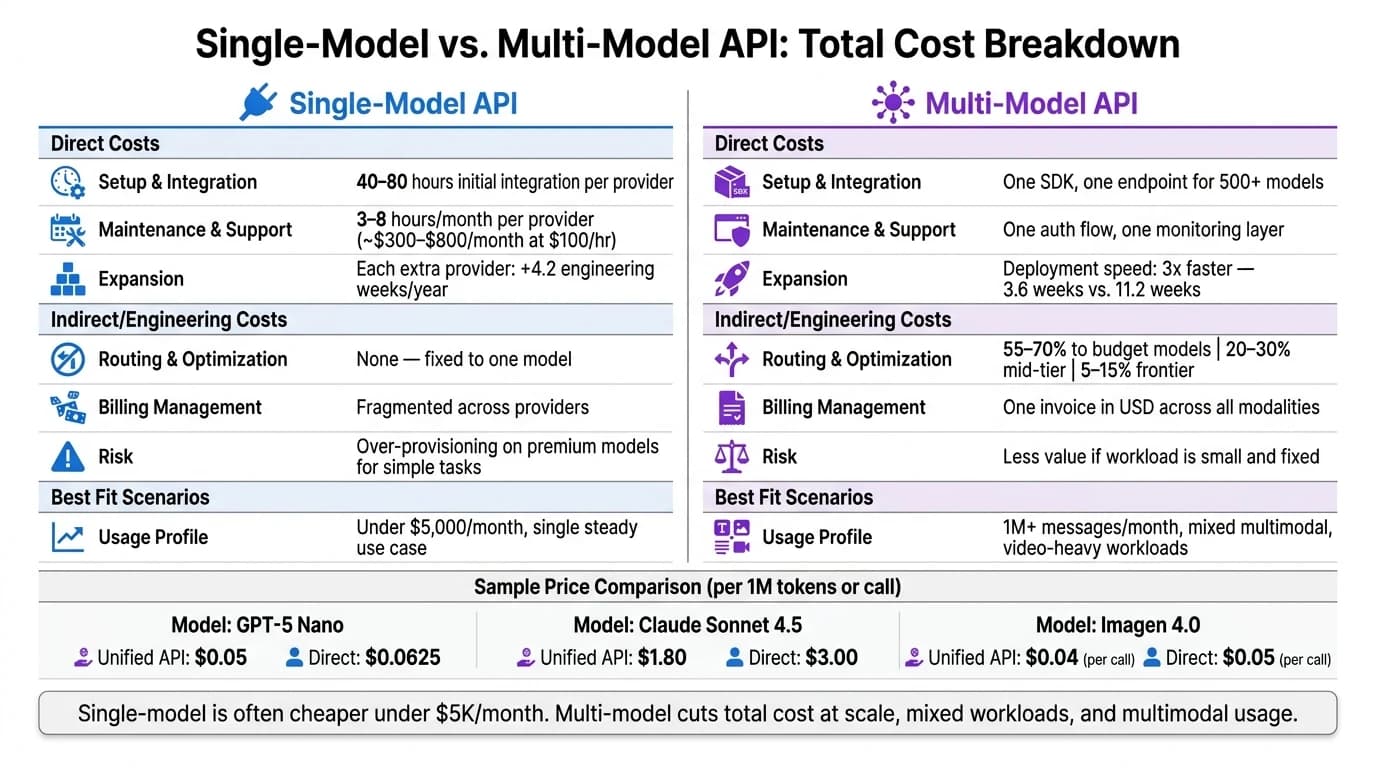
Cost Optimization Techniques for LLM Applications - Faster, Cheaper & Scalable AI | Uplatz
Quick Comparison
| Criteria | Single-Model Integration | Unified Multi-Model API |
|---|---|---|
| Setup | One direct provider connection | One connection for many models |
| Usage fit | Best for one steady use case | Best for mixed and growing workloads |
| Billing | One provider invoice | One invoice across models |
| Routing by price/quality | No | Yes |
| Extra provider work | Grows with each provider | Stays in one layer |
| Engineering overhead | Lower at first, then climbs | Lower when scope expands |
| Best cost case | Under $5,000/month, fixed task | 1M+ messages/month, multimodal, video-heavy |
| Main risk | Overpaying for simple tasks on one premium model | Less value if workload is small and fixed |
I’d use this article to make a full-cost decision, not just a rate-card decision.
Cost Structure of a Single-Model Integration
Direct costs: usage fees and billing for narrow workloads
A single-model integration keeps billing simple: one provider, one pricing setup. For an early-stage product with one main use case, that kind of simplicity helps. You have one invoice, one rate card, and fewer moving parts.
That said, simple doesn't always mean cheap. If usage jumps, overage charges can follow. And at the enterprise level, some providers ask for minimum commitments. This setup works best when demand stays narrow and easy to predict.
Indirect costs: integration, maintenance, and compliance work
The invoice is only one piece of the picture. A lot of the spend sits outside it.
A mid-sized team integrating a provider directly can expect 40–80 hours of initial integration work [2]. That usually means writing adapter code, dealing with provider errors like 429 and 5xx responses, setting up retry logic, and handling API key rotation. That's the integration tax.
And it doesn't stop after launch. Model updates still need attention. Monitoring still takes engineering time. Compliance work can add more effort, too. On top of that, a single-model setup puts data exposure in one vendor's hands, which can increase concentration risk.
When single-model is cheaper and when it gets expensive
Single-model setups stay cost-efficient when the workload is stable and narrow. That's the sweet spot.
The trouble starts when teams run every task through one premium model, even the simple stuff. That's where over-provisioning starts to eat into spend. And when product scope grows, separate provider integrations can pile up fast. Each added direct provider integration uses an estimated 4.2 engineering weeks in initial setup and ongoing maintenance [1]. That overhead adds up in a hurry.
Here’s how that tends to look by workload:
| Scenario | Single-Model Cost Behavior |
|---|---|
| Stable use case, low volume | Low cost, easy to forecast |
| Stable use case, traffic spikes | Risk of overage charges and minimum commitments |
| Multiple tasks on one premium model | Over-provisioning drives up spend |
| More integrations over time | Higher maintenance and more fragmented billing |
Single-model setups often start lean. But as scope grows, costs can climb with them. The next section compares these costs by workload type.
Cost Structure of a Unified Multi-Model API
Direct savings from consolidated access and flexible model selection
Single-model setups often cost more than they should because teams end up overbuying. A unified API changes that. Instead of sending every task to the same model, you can send simple work to lower-cost models and keep stronger models for the jobs that actually need them.
That shifts cost in two clear ways: routine tasks go to cheaper models, and harder tasks use premium models only when needed. In practice, that kind of routing can cut spend in a meaningful way.
Billing gets simpler too. Text, image, and video usage all show up on one invoice in USD, which means less cleanup for finance and less time spent matching charges across vendors.
Enterprise token costs fell 67% year-over-year by April 2026, driven in large part by teams routing work away from expensive frontier models when lower-cost options could do the job [1]. One common setup is a tiered stack:
- Route 55–70% of traffic to cost-efficiency models
- Reserve only 5–15% for frontier models [1]
Indirect savings from one integration across many models
The setup burden from single-model systems doesn't disappear when teams add more providers. It gets worse. Every new provider can mean another auth flow, another monitoring setup, another governance path, and another round of maintenance.
A unified API stops that snowball effect early. You set up one auth flow, one monitoring layer, and one governance layer. Build it once, and it works across every model behind the API.
That matters because integration overhead grows every time a new provider is added. With a unified layer, that work gets pulled into one connection instead of being spread across many.
Teams using multi-model infrastructure deploy production AI agents 3x faster: 3.6 weeks versus 11.2 weeks [1]. Less time spent on plumbing means more time shipping.
APIMart as a practical example of this model
A platform example makes the pricing difference easier to spot.
APIMart shows how unified access works day to day: one API, one billing flow, and access to models across text, image, and video.
Its video model lineup also shows why routing matters. MiniMax Hailuo 2.3 Fast costs $0.025/second, which makes it a fast, lower-cost option. Kling V3 Omni costs $0.0672/second (720p) and fits cinematic output at a mid-tier price. Sora 2 Preview comes in at $0.08/second for a balance between quality and cost. Vidu Q3 Pro costs $0.12/second and fits more demanding, high-performance generation.
| Model | Price | Best For |
|---|---|---|
| MiniMax Hailuo 2.3 Fast | $0.025/sec | High-speed, low-cost video generation |
| Kling V3 Omni (720p) | $0.0672/sec | Cinematic visuals and mid-tier cost |
| Sora 2 Preview | $0.08/sec | Quality-cost balance |
| Vidu Q3 Pro | $0.12/sec | Best for complex, high-performance generation |
| Unified Multi-Model API | Single-Model Integration | |
|---|---|---|
| Billing | One invoice in USD | Fragmented across providers |
| Integration work | One SDK, one endpoint | Unique setup per provider |
| Routing flexibility | Route by cost or quality | Fixed to one model |
| Updates | Provider updates handled centrally | Manual per-provider updates |
| Best fit | Mixed, growing workloads | Single-task, low-volume apps |
The next section compares these savings by workload type.
Direct Cost Comparison by Workload Type
Cost metrics used in this comparison
Cost only means something when you tie it to the kind of work you're running.
The main numbers to compare are cost per 1M input tokens, cost per image call, cost per video second, and monthly USD spend. That gives you a much better read on total workload cost than looking at list price alone.
A few examples make the gap plain. GPT-5 Nano costs $0.05 per 1M input tokens through APIMart versus $0.0625 direct. Claude Sonnet 4.5 comes in at $1.80 versus $3.00. Imagen 4.0 costs $0.04 per call versus $0.05. On a small project, that may not feel huge. At scale, it adds up fast.
Workloads where single-model often costs less
For narrow, predictable workloads, routing often doesn't do much for you.
Think of a single internal summarization pipeline or another fixed-scope workflow with steady input sizes. If monthly spend stays below $5,000 and the task stays the same, there usually isn't much day-to-day value in routing across several models. In that setup, direct integration is often the lower-cost path.
Workloads where multi-model often lowers total spend
Once volume goes up and more than one modality enters the picture, routing starts to matter.
Mixed and high-volume workloads tend to change the math. If a team is generating text, images, and video - or handling 1M+ chat messages per month - costs climb as tasks spread across different use cases. That's where a multi-model setup can save money: send simple requests to lower-cost models, and keep premium models for the harder jobs.
| Workload Category | Est. Monthly Spend | Key Cost Drivers | Likely Lower-Cost Approach |
|---|---|---|---|
| High-Volume Chat (1M+ messages/month) | $10,000–$25,000 | Output token volume; reasoning tokens | Multi-Model (route simple tasks to budget models) |
| Mixed Multimodal (text + image + video) | $15,000+ | Multimodal compute | Multi-Model (consolidated billing, single SDK) |
| Video-Heavy Creative (100+ hrs/mo) | $25,000+ | Per-second render rates | Multi-Model (up to 20% savings on premium video models) |
| Stable Internal Tool (summarization) | Under $5,000 | Fixed usage; low complexity | Single-Model (if routing flexibility isn't needed) |
Budget Framework and Final Decision Guide
A step-by-step budgeting method for U.S. teams
Use the workload patterns above to turn pricing into a budget call. This method has three steps.
Start with a baseline cost. Price all traffic through one premium model first. That gives you a ceiling, so you can see the highest likely spend before you test other routing setups.
Next, calculate the tiered routing cost. Send 55–70% of traffic to cost-efficiency models, 20–30% to mid-tier models, and keep frontier models for the 5–15% of tasks that need complex reasoning. Then weight each tier by its share of total volume and its per-token rate to get a lower-cost mix.
Then calculate the total cost. Add engineering overhead to both options. Each extra provider integration adds about 4.2 engineering weeks per year [1]. That time has a dollar cost, and it can change the decision fast.
Once you’ve added usage and overhead, the better option is the one with the lower full monthly cost.
When to choose single-model and when to choose multi-model
A single-model setup works best when you have one steady use case and low complexity. It’s simpler, easier to manage, and often good enough for narrow needs.
A multi-model setup makes more sense when workloads are mixed, usage is growing, or redundancy matters. If some tasks are simple and others need deeper reasoning, routing work across model tiers can cut spend without boxing you in.
APIMart offers one API across 500+ models, which cuts duplicate integration work as AI usage grows.
Conclusion: the lowest invoice is not always the lowest total cost
A low per-token rate on one model can look great in a spreadsheet. But that number doesn’t show the whole bill. Integration time, maintenance cycles, and failover logic all add cost. Unified multi-model access helps reduce many of those hidden costs by design.
Key takeaways:
- Usage price is only one part of total cost.
- Tiered routing cuts spend when workloads are mixed or multimodal.
- Integration overhead goes up with each added provider.
- Single-model fits steady, narrow use cases.
- Multi-model fits growing, multimodal workloads.
FAQs
How do I calculate total cost beyond API pricing?
Look past token pricing for a minute. The bigger drain often comes from the day-to-day work of juggling multiple providers.
It’s not just about paying for API usage. It’s the extra engineering time spent building adapter layers, dealing with error handling, writing custom retry logic, and managing a mess of separate API keys. That work adds up fast. In many teams, integration maintenance alone takes 15–20 hours per month.
Security adds another layer of cost too. When access tokens are spread across different vendors, governance gets harder. It becomes easier for orphaned keys to stick around, which can lead to wasted spend and cost leakage that no one spots right away.
A unified platform like APIMart can bring those moving parts into one dashboard, making access control and spend tracking much easier to manage while cutting down on manual overhead.
When does a multi-model API become cheaper than one model?
A multi-model API gets cheaper when you use intelligent task-model routing instead of a one-size-fits-all setup.
Here’s the basic idea: send simpler jobs like classification, summarization, and data extraction to lower-cost models. Then save premium models for more complex or high-stakes work. That one shift can cut AI costs by 30% to 80%.
APIMart makes this easier with access to 500+ models, along with unified billing, volume pricing, and aggregated discounts across AI workloads.
What workloads benefit most from model routing?
Model routing works best for high-volume, cost-sensitive workloads where task difficulty changes from one request to the next. The basic idea is simple: send easy work to lower-cost models, and save frontier models for the hard stuff.
That makes routing a strong fit for work like classification, tagging, summarization, and background enrichment. In these cases, a large share of requests don't need the most expensive model to get the job done.
It can also help with:
- high-volume batch processing
- latency-sensitive user-facing apps
- resource-heavy tasks like video generation
- agentic workflows that switch between reasoning, tools, and retrieval
Choose the model you want in the model marketplace
Try chat, image and video models in the APIMart model marketplace, and experience model capabilities quickly with one unified API.