
Z-Image Turboとは?高速AI画像生成を解説
Z-Image TurboはAlibabaが開発した60億パラメータのAIモデルで、数秒で写実的な画像を生成します。その速度、機能、価格、最適な用途を詳しく解説します。
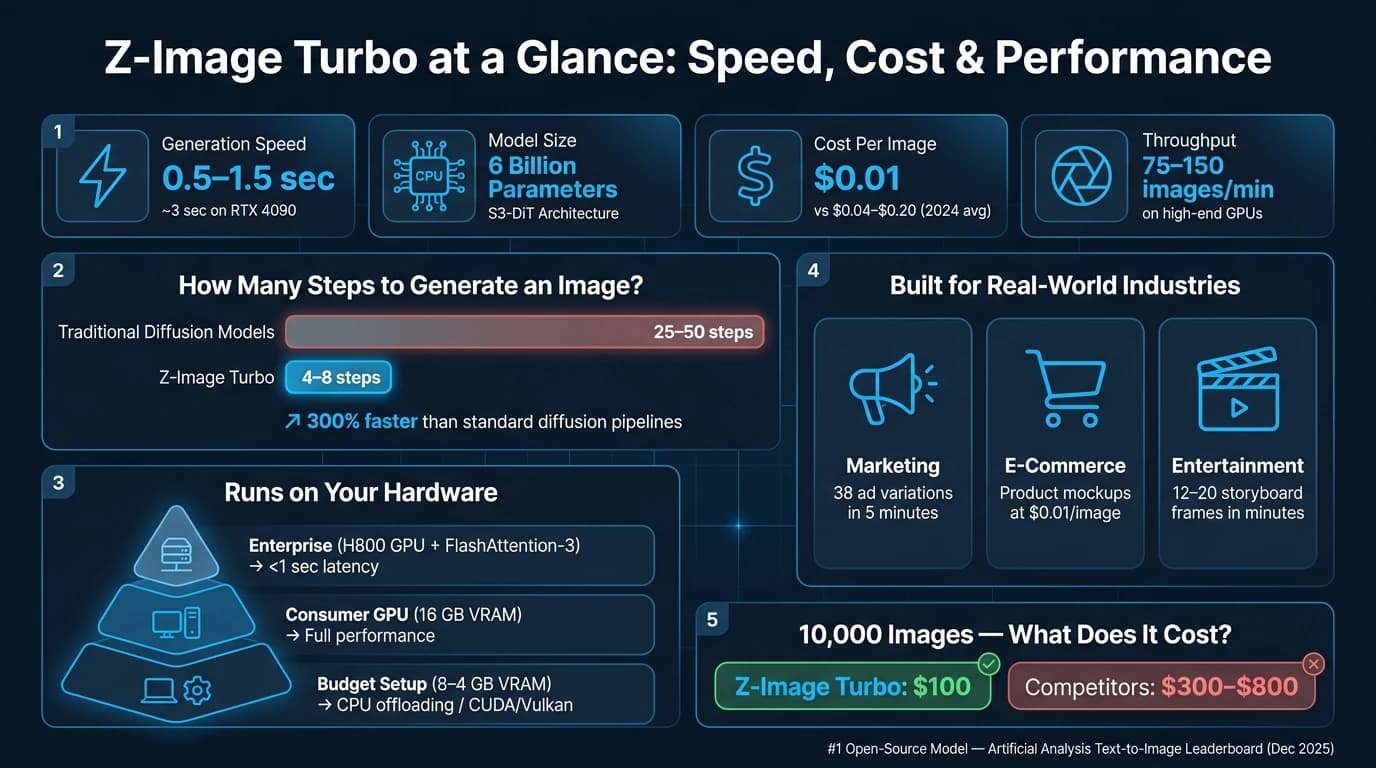
Z-Image Turboは、記録的な速さで高品質な画像を生成する次世代AIモデルです。AlibabaのTongyi-MAIチームによって開発され、60億パラメータのアーキテクチャを使用し、エンタープライズ向けハードウェアでわずか0.5〜1.5秒でビジュアルを生成します。独自のScalable Single-Stream Diffusion Transformer(S3-DiT)設計はテキストと画像のトークンを統合し、従来モデルよりも高速かつ効率的にします。
主なハイライト
- 速度: ハイエンドGPUで毎分75〜150枚の画像を生成します。
- 品質: 高度な拡散技術を用い、わずか4〜8ステップで写実的な結果を実現します。
- 使いやすさ: 英語と中国語のプロンプト、複数の解像度、シードロックやマスクベースの編集などの機能をサポートします。
- ハードウェア互換性: わずか8 GB VRAMのコンシューマー向けGPUで動作し、CPUオフロードのオプションもあります。
Z-Image Turboは、マーケティング、eコマース、メディアなどの業界に最適で、1枚あたり$0.01という低コストで広告制作、商品画像、ストーリーボード作成などのタスクを可能にします。速度、コスト効率、ビジュアルの精度のバランスを取り、迅速な画像生成を必要とするプロフェッショナルにとって実用的な選択肢となっています。
Z-Image Turboの仕組み
蒸留拡散技術
Z-Image Turboの驚異的な速度の秘密は、蒸留拡散アプローチにあります。従来の拡散モデルがノイズを鮮明な画像に洗練するのに25〜50ステップを必要とするのに対し、Z-Image Turboはこのプロセスをわずか4〜8ステップまで削減します。これは、CFG Augmentation(速度向上)とDistribution Matching(画像品質の維持)を分離するDecoupled-DMDによって実現されています [1]。このモデルはまた、DMDと強化学習を組み合わせた_DMDR_を取り入れ、意味的な整合性を向上させ、美的品質を高め、複雑なディテールを洗練します。その結果は?標準的な拡散パイプラインよりも最大300%高速な画像生成を、ビジュアル品質を損なうことなく実現します [2]。
この技術は、直感的で使いやすいワークフローにシームレスに統合されています。
ユーザーワークフローの例
Z-Image Turboを使った典型的なセッションは次のように進行します:
| ステップ | 操作 | 設定 |
|---|---|---|
| 1 | プロンプトを書く | 英語または中国語で説明的なテキストを入力(最大約1,000文字)[1] |
| 2 | 解像度を選ぶ | 1:1、16:9、9:16などのアスペクト比を選択 [2] |
| 3 | サンプリングステップを設定 | Turboの最適なパフォーマンスには4〜8ステップを使用 [7] |
| 4 | CFGスケールを設定 | 0.0に保つ(推奨)。値が高いと過飽和を引き起こす可能性があります [1] |
| 5 | シードを設定 | ランダムな結果には-1を使用、再現性のためには固定値を選択 [2] |
| 6 | 生成 | NVIDIA RTX 4090で約3秒で出力を取得 [7] |
プロのヒント:サンプリングステップを12以上に設定すると過飽和を招く可能性があるため、避けてください [5]。
このシンプルなプロセスにより、ユーザーは最小限の労力で高品質な結果を得ることができます。
互換性とパフォーマンス
Z-Image Turboは速度だけではありません。ハードウェア互換性にも優れています。わずか16 GBのVRAMでコンシューマー向けハードウェア上で効率的に動作するよう設計されており、高価なデータセンターのリソースを必要とせず、より幅広いユーザーに高速な画像生成をもたらします。FlashAttention-3とモデルコンパイルを備えたH800 GPUのようなエンタープライズ構成では、推論レイテンシは1秒未満まで低下します [1][8]。
ハードウェアが限られているユーザーは、Hugging Face Diffusersライブラリ(pipe.enable_model_cpu_offload())を通じてCPUオフロードを有効にすることで、わずか8 GBのVRAMでモデルを動作させることができます [1]。stable-diffusion.cppを使用するものなど、一部のコミュニティ実装では、CUDAやVulkanバックエンドを活用して、この要件を約4 GBのVRAMまで削減しています [1]。
Z-Image Turboは、PyTorch、vLLM-omni、SGLang-Diffusion、RustベースのCandleフレームワークなど、さまざまな開発環境をサポートします。これにより、異なるプラットフォームの開発者にとってスムーズな統合と柔軟性が確保されます [1]。
Z-Image Turboの主な機能
写実的で正確な出力
Z-Image Turboの60億パラメータアーキテクチャは、シャープでリアルなビジュアルを生成します [1]。そのS3-DiTアーキテクチャは、最も複雑な説明でさえ曖昧な近似を避けて正確なビジュアルに変換することを保証する上で重要な役割を果たします。
際立った機能の1つは、バイリンガルテキストレンダリングです。Z-Image Turboは、英語と中国語のテキストを生成画像にシームレスに統合し、適切なタイポグラフィ、スペーシング、可読性を維持できます。これを使用するには、プロンプト内に希望のテキストを引用符で囲んで含めるだけです。例:the sign reads "夜市 / NIGHT MARKET" [9]。この機能は、グローバルなマーケティングキャンペーンやバイリンガルの商品ビジュアル作成に特に便利です。
2025年12月時点で、Z-Image TurboはArtificial Analysis Text-to-Image Leaderboardにおいてオープンソースモデル中第1位を達成し、総合で8位にランクインしました [1]。
これらのビジュアル能力は、さまざまなカスタマイズオプションによって補完されています。
カスタマイズと柔軟性
Z-Image Turboは、特定のニーズに合わせて出力を調整するさまざまな方法を提供します。ユーザーは複数のアスペクト比と解像度から選択でき、最高解像度は2048 × 2048ピクセルに達します [6]。
このモデルはまた、オブジェクトの置換や背景の変更を可能にするマスクベースの編集や、調整可能なstrengthパラメータを使用して元の入力が最終出力にどれだけ影響するかを制御できる画像から画像への生成などの高度な編集ツールもサポートします。さらに、出力はJPG、PNG、WEBPなどさまざまな形式で保存でき、圧縮品質は20〜99の間で調整可能です。一貫したビジュアルを重視するチームには、API経由でLoRAサポートとControlNetガイダンスが利用できます。
「当社のeコマース商品画像にZ Image Turboへ切り替えました。コスト削減と速度向上は、当社のビジネスにとって大きな効果がありました。」 - James Liu、eコマースマネージャー [3]
もう1つの便利な機能はシードパラメータで、生成画像の一貫性を確保します。-1の代わりに固定の整数を設定することで、ユーザーは同一の画像を再現したり、コア要素をそのまま保ちながら小さな調整を加えたりできます [2]。
指示への忠実性
Z-Image Turboは画像を迅速に生成するだけでなく、詳細な指示に従うことにも優れています。自然言語のキャプションでのトレーニングと組み込みのPrompt Enhancerのおかげで、このモデルは構造的な整合性を維持しながら複雑なプロンプトを解釈します [9]。
DMDR後トレーニングプロセス(Distribution Matching DistillationとReinforcement Learningの組み合わせ)は、意味的な正確性を向上させ、複雑なプロンプトでさえ精密にレンダリングされることを保証します [1]。
「細かいスタイリングのプロンプトでも構造は安定したままでした。」 - Emma L.、ビジュアルデザイナー [12]
「各プロンプトは構図を保ちながらディテールを追加し、ショット全体で手動修正を削減しました。」 - Daniel M.、コンテンツクリエイター [12]
最良の結果を得るには、ネガティブプロンプトを簡潔に保ってください。このモデルは指示によく従うため、「blurry, overexposed」のような短い除外リストで通常は十分です [9]。
Z-Image Turboの実用的な応用
マーケティングと広告
マーケティングでは、速度が状況を一変させることがあります。Z-Image Turboの1秒未満での画像生成能力により、クリエイティブチームはわずか5分で38種類の広告バリエーションを制作でき、標準的な生成モードと比較して出力を3倍にできます [13]。これにより、これまで現実的ではなかったビジュアルコンセプトの迅速なA/Bテストが可能になります。
仕組みは次のとおりです:Turboモードを使ってさまざまなクリエイティブの方向性を素早く探求します。勝てるコンセプトを特定したら、Normalモードに切り替えて、洗練された印刷可能な仕上がりに磨きをかけます [13][4]。広告バナーの場合、画像上のテキストは短く太字に保ってください。「SALE」や「NEW」のような1〜3語が目安です。そして、より詳細なテキストを背景にオーバーレイすると、クリーンでプロフェッショナルな見た目になります [13]。
この迅速な反復プロセスは広告に限定されず、商品ショーケースも強化し、ビジュアルのテストと洗練をより簡単にします。
eコマースと小売
小売業者はZ-Image Turboで商品画像のワークフローを革新できます。その速度と精度により、チームは1枚あたり1秒未満で商品モックアップ、ライフスタイル画像、背景の置き換えを作成できます [3][10]。シードロック機能により、色や素材のバリエーションが一貫した構図と照明を維持し、コストのかかる手動の再撮影が不要になります [15]。
もう1つの際立った機能はバイリンガルレンダリングで、別途ローカライズ手順を必要とせずに、英語と中国語の市場向けのラベル付けを簡素化します [11][14]。APIMartで1枚あたりわずか$0.01 [3]という価格で、このツールは大規模なカタログ更新にも予算に優しいものです。
エンターテインメントとメディア
Z-Image Turboは、エンターテインメントのようなクリエイティブ業界でも同様に価値があります。ビジュアルストーリーテリングに取り組むチームにとって、それはビジュアルスケッチパッドとして機能し、コンセプトアーティストが数分で12〜20枚の素早いフレームを生成できるようにします。つまり、通常1枚の高精細レンダリングを制作するのにかかる時間で、6〜10種類のプロンプトバリエーションを探求できるのです [13]。
「Z-Image Turboの画像品質は、高速な生成時間を考えると印象的です。素早いプロトタイピングとコンセプトの視覚化のための定番モデルになりました。」 - David Kim、プロダクトデザイナー [3]
このツールの汎用性は、ストーリーボードシーケンス(一貫性のためにシードロックを使用)から映画のティーザーポスター、アニメビジュアル、YouTubeサムネイルまで、さまざまなクリエイティブプロジェクトをサポートします。アートディレクターのAlex Parkは、このモデルが複雑なプロンプトをプロレベルの結果で処理する方法を強調しました [3]。最良の出力を得るには、「realistic」のような一般的な記述子(これはダイナミックさに欠ける画像になる可能性があります)の代わりに、_「35mm prime」や「Kodak Portra 400」_のような具体的なカメラやフィルムの用語を使用してください [16]。
| 業界 | 一般的なユースケース | Turboの利点 |
|---|---|---|
| マーケティング | 広告クリエイティブ、ソーシャルメディア投稿、メールバナー | 迅速なA/Bテストのために5分で38バリエーション [13] |
| eコマース | 商品モックアップ、ライフスタイルショット、バリアントビジュアル | カタログ全体のビジュアル一貫性のためのシードロック [15] |
| エンターテインメント | ストーリーボード、コンセプトアート、ポスター、サムネイル | ライブのクリエイティブセッション中のほぼ即時のフィードバック [13] |
Z-Image Turboの使い方
ステップバイステップのワークフロー
Z-Image Turboは、特にAPIMart APIと組み合わせると、優れた速度と柔軟性を提供します。始め方は次のとおりです:
- 認証: APIMart API Key Management ダッシュボードのBearer Tokenを使用します。
https://api.apimart.ai/v1/images/generationsにPOSTリクエストを送信し、プロンプトとパラメータを含め、モデルをz-image-turboに設定します。 - 結果のポーリング: リクエストを送信すると、APIは
task_idを返します。このIDを使用して、タスクが完了とマークされるまで定期的に/v1/tasks/{task_id}エンドポイントにクエリを送ります。完了すると、最終的な画像URLを受け取ります [6]。
ワークフローを設定したら、さまざまなパラメータを調整して結果を洗練できます。
主要な設定オプション
最良の結果を得るには、これら5つの重要な設定に注目してください:
prompt: 詳細な説明を提供します(最大1,000文字)。このモデルは英語と中国語の両方をサポートするため、より高い精度のために照明、スタイル、構図などの要素を具体的に指定してください。size: プラットフォームに合ったアスペクト比を選択します。例えば、TikTokやReelsには9:16、YouTubeサムネイルには16:9、ソーシャルメディアフィードには1:1を使用します。resolution: より速い結果が必要な場合は1K、より高品質な画像には2Kを選択します。良い方法は、直接2Kで生成するのではなく、1Kから始めて必要に応じて後でアップスケールすることです。ネイティブの高解像度出力を必要とするプロジェクトには、4Kレンダリングのためにdoubao-seedream-5-0-liteを検討してください。seed: ランダムな結果には-1に設定し、繰り返しの反復のためにデザインをロックするには特定の整数を使用します。prompt_extend: これをオンにすると、曖昧なプロンプトを自動的に強化します。この機能は1枚あたり$0.02のコストがかかることに注意してください。
速度と品質の最良のバランスのために、推論ステップを8〜10の間に保ってください。12ステップを超えると品質が低下し、過飽和を招く可能性があります [5]。
これらのオプションにより、最適な結果を得るために画像生成プロセスを微調整できます。以下は、主要な設定とその効果をまとめたクイックテーブルです:
設定と効果:クイックリファレンステーブル
| 設定 | 推奨値 | 出力への影響 |
|---|---|---|
| prompt | 具体的で詳細なテキスト(最大1,000文字) | より多くのディテールが正確で写実的な画像を生み出します |
| size | アスペクト比を設定(例:16:9、9:16) | 構図を表示形式に合わせ、意図しないトリミングを回避します |
| resolution | 速度には1K、高精細には2K | 1Kは高速生成を確保し、2Kは品質を向上させますが時間とコストが増加します |
| seed | 一貫した結果には固定整数、ランダムには-1 | 固定シードは複数の生成にわたって再現性を確保します |
| prompt_extend | シンプルなプロンプトにはtrue、詳細なプロンプトにはfalse | 曖昧なプロンプトに深みを加えます(1枚あたり$0.02のコスト) |
| guidance_scale | 0.0(Turboには必須) | 値が高いと(3.0以上)過飽和のリスクがあります |
| num_inference_steps | 8〜9 | 品質と速度を維持します。12ステップを超えると結果が劣化する可能性があります |
Z-Image Turboオールインワンワークフロー:低VRAM向けのComfyUIでシンプルなAI画像生成!
まとめ
Z-Image Turboは、高速で手頃な価格、かつ高品質な画像生成を必要とするチームにとって実用的なソリューションです。1秒未満の生成速度と1枚あたりわずか$0.01のコストで、2024年初頭に見られた$0.04〜$0.20の料金を大幅に下回ります [17]。
60億パラメータのアーキテクチャ上に構築され、Decoupled-DMD蒸留を活用することで、このモデルはわずか8推論ステップで写実的な画像を生成します。クリエイティブディレクターのSarah Chenは、その速度がデザインの反復に必要な時間を劇的に削減する様子を強調しています。
この効率性は生産性を高めるだけでなく、柔軟なワークフローの選択肢も開きます。マーケティング、eコマース、エンターテインメントなどの業界では、ハイブリッドワークフローが特に効果的です。チームはプロトタイピング、A/Bテスト、大量画像生成などのタスクにZ-Image Turboを使用し、最終的な制作アセットにはgpt-image-2のようなプレミアムモデルを残しておくことができます。例えば、10,000枚の画像を生成する場合、Z-Image Turboではわずか$100で済むのに対し、より高価な代替手段では$300〜$800かかります [17]。
商品カタログの構築、広告コンセプトの洗練、ストーリーボードの締め切りに向けた競争のいずれであっても、APIMart API経由でアクセスできるZ-Image Turboは、アイデアを素早く画像に変える信頼性が高くコスト効率の良い方法を提供します。
よくある質問
自分のGPUでZ-Image Turboを実行するには何が必要ですか?
Z-Image TurboをGPUでスムーズに実行するには、グラフィックスカードに少なくとも16 GBのVRAMがあることを確認してください。これにより最適なパフォーマンスが確保されます。デバイスのメモリが少ない場合でも、解像度を下げ(例:640x768)、CPUオフロードを有効にすることで使用できます。ただし、これにより生成プロセスが遅くなることに注意してください。
また、Python 3.9+、CUDA、互換性のあるGPU対応のPyTorchビルドも必要です。モデルを実装するには、diffusersライブラリのZImagePipelineを使用してください。
なぜZ-Image Turboはガイダンススケール0.0を推奨するのですか?
Z-Image Turboがガイダンススケール0.0の使用を推奨するのは、そのDecoupled-DMD蒸留プロセスがガイダンスを直接モデルの重みに組み込んでいるためです。これは、モデルが画像生成のガイドにプロンプトのみに依存することを意味します。組み込みのステアリングメカニズムがモデルを設計どおりに動作させるため、ガイダンススケールへの外部からの調整は必要ありません。
固定シードと-1はいつ使い分けるべきですか?
固定シードの使用は、一貫した結果を確保したり、ブランドの整合性を維持しながら以前の画像にわずかな調整を加えたりするのに最適な方法です。特定の整数をシードとして設定することで、同じプロンプトを使用したときに同じ出力を確実に再現できます。
より多くのバリエーションを求め、新しいアイデアを試したい場合は、シードとして-1を使用してください。これによりランダムな出力が生成され、新しいクリエイティブの方向性を探求したり、以前の結果を複製せずに唯一無二のアセットを制作したりするのに最適です。
関連ブログ記事
モデルマーケットで使いたいモデルを選ぶ
APIMart のモデルマーケットでチャット、画像、動画モデルを試し、統一 API でモデルの能力をすばやく体験できます。