
AI API 在云原生应用中的未来
AI API 在 2026 年如何重塑云原生应用:更慢的模型调用、按请求计费、多厂商路由,以及对开销、安全和延迟更严的把控。
AI API 如今是应用技术栈的一部分,而不只是附加工具。 如果你在 2026 年构建云原生应用,你需要为缓慢的模型调用、可变的按请求成本、多厂商路由,以及对开销、安全和延迟更严的把控做规划。
下面是精简版:
- 一个普通的应用请求可能在 50–200 毫秒内完成,而一次 AI 调用可能要花 2–30 秒
- AI 请求成本可以从 $0.01 到超过 $1.00 每次调用不等
- 使用多模型基础设施的团队平均 3.6 周就能发布,而单厂商配置要 11.2 周
- 好的生产配置会把工作拆到微服务、无服务器函数和事件驱动队列上
- 对于长 AI 任务,webhook、流式、并行步骤和兜底输出比原始模型质量更重要
- 大部分流量应该走低成本模型,只有 5%–15% 发往前沿模型
- AI 开销只是账单的一部分;API 费用往往只占总拥有成本的 30%–50%
如果让我把这篇文章浓缩成一点,那就是:AI API 的未来关乎控制层。不只是模型访问。你需要一个层来跨文本、图像、音频和视频处理路由、故障转移、策略、日志和预算上限。
这也改变了我对架构的思考方式:
- 用微服务处理基于智能体或检索密集的流程
- 用队列和异步流水线处理媒体生成
- 用无服务器处理突发的用户动作
- 用 AI 感知的网关处理 token 限制、缓存和熔断
- 用模型版本固定和带硬上限的子密钥来控制输出漂移和开销
有几个数字很突出。并行的多步流程可以把端到端延迟从 11–23 秒降到 5–9 秒。一条 15 秒的生成媒体流水线大约花 $0.425 每片。专用 GPU 托管在约 12,500 次月请求时开始变得划算,H200 定价接近 $2.60 每 GPU 小时,约 $1,872 每月。
这对你意味着什么很简单:如果你的应用使用 AI,主要工作不再只是「挑一个模型」。而是构建一个系统,能在合适的成本下、带着合适的保障,把合适的请求路由到合适的模型。

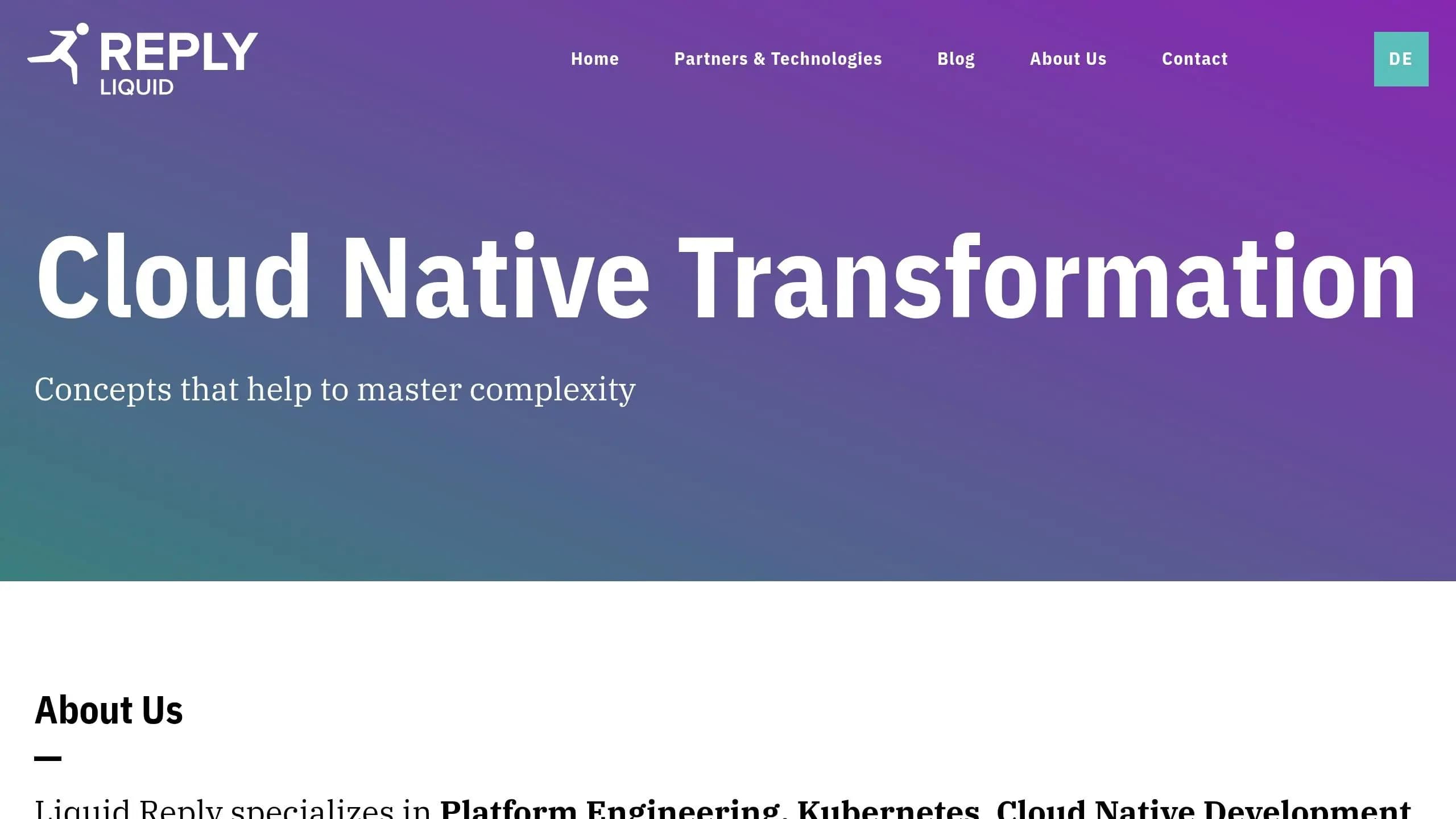
快速对比
| 领域 | AI API 带来的变化 |
|---|---|
| 延迟 | 请求常常从毫秒级变为秒级 |
| 成本 | 开销从固定基础设施转向按调用用量加上重试和审核 |
| 架构 | 同步 CRUD 模式让位给异步队列、流式和工作流引擎 |
| 扩展 | GPU、队列深度和 KV-cache 比单纯的 CPU 更重要 |
| 可靠性 | 故障转移、降级响应和厂商路由成为标配 |
| 治理 | PII 脱敏、审计日志、子密钥和预算上限移入网关层 |
| 产品速度 | 统一的多模型访问削减集成开销和发布时间 |
所以当我看 AI API 在云原生应用中走向何方时,我看到的不是「又一类 API」。我看到的是塑造应用速度、成本和正常运行时间的核心平台管道。
将塑造下一波 AI API 的云原生基础
面向 AI 工作负载的容器、Kubernetes、无服务器和 API 网关
这种转变改变了模型调用周围的基础设施层。AI 推理需要 GPU 感知的扩缩信号,而不只是 CPU 和内存。团队需要监控 KV-cache 利用率、请求队列和延迟。[6] 对于视频生成和图像理解,缓存压力会直接影响响应时间。
在 vLLM 部署中,应把 KV-cache 利用率用作 HPA 信号,并在超过 90% 时设告警。[6] GPU 调度也需要匹配手头的任务:
- 独占 GPU 分配最适合大模型推理
- MIG 分区为较小的模型提供硬件隔离
- 时间切片适合优先级较低的后台任务[6]
老式网关不擅长处理这类流量。AI 原生网关增加了 token 感知的速率限制、来自嵌入的语义缓存,以及基于延迟的熔断器。一个实用的熔断阈值约为 20 秒。[7][4]
多云、混合云和统一 API 层
企业级 AI 技术栈如今横跨云、边缘、本地数据和第三方模型厂商。当每个厂商都自带 SDK 时,集成很快就会变脆。这就是为什么许多团队正转向一个统一的 AI 网关,把厂商调用规整到一个抽象层之后。[7][1]
当一个应用通过同一个工作流路由文本、图像、音频和视频时,那个单一抽象就更加重要。控制层处理策略、路由和可移植性,让应用代码与下游模型细节解耦。简单说,应用可以专注于用户体验,而不必应付厂商特定的管道。
边缘执行也在提速。Cloudflare Workers 等平台上的 V8 Isolates 可以消除冷启动,并通过 TransformStream API 流式传输 token。[7] 正是这同一个控制层,让多模态路由和策略执行在日常系统中变得可行。
安全、治理与美国合规要求
美国企业买家如今把零数据留存(ZDR)、PII 脱敏和签署的数据处理协议当作标准的采购要求。[1] 这些不再是锦上添花的检查项。它们是底线诉求。
技术负责人应该为每个团队设置带硬性预算上限和模型范围权限的 API 子密钥,这样一个工作流就不会意外推高开销或制造治理问题。[9] 治理也应该延伸到网关层,通过 PII 脱敏和提示词注入检测,并辅以对答案忠实度、幻觉和漂移的实时监控。[7][5]
这些控制有助于让多模态工作流在团队和厂商之间保持可预测。它们也为接下来的多模态编排层做了铺垫。
AI API 如何从单模态工具转向统一的多模态服务
从文本生成到图像理解和实时视频
一旦网关层标准化了,下一个转变发生在模型层:单个请求现在可以覆盖文本、图像、音频和视频。
早期的 LLM API 只支持文本。团队不得不在代码里把视觉、语音和语言服务拼在一起。那种分离模型的流水线增加了延迟、额外的活动部件,以及更多可能出错的地方。语音转文本还可能在推理模型看到输入之前就抹掉语气、迟疑和情绪。[10]
现代的早期融合模型用另一种方式处理这件事。它们从一开始就把文本、音频、图像和视频映射到一个共享表示里。[10] 这让模型可以同时跨模态推理,而不是把数据沿一条链往下传——在那条链上上下文常常丢失。更少的模型交接通常意味着更低的延迟、更干净的重试和更简单的可观测性。
影响相当直接。一个对话式助手可以在聊天中途检查一张产品图,而无需单独发起视觉调用。一个教育应用可以在一次会话内把一份大纲变成带旁白的课程视频。到那个程度,难的部分不再只是把工具连起来。而是编排整个流程如何运作。
面向现代应用的统一多模态 API 模式
当模型共享一个接口时,团队可以让输入、输出、策略和成本走同一个控制层。
这改变了应用的构建方式。一次调用可以接受混合输入并返回混合输出。例如,一个应用可能发送文本加一张图,拿回一张修改后的图、一段视频片段或一段大白话解释。对内容团队来说,这意味着更少的认证开销,以及从创意简报到成品资产之间更少的活动部件。这些功能不再像一堆服务拼凑的补丁,而开始感觉像一个系统。
通过一个集成路由多模态请求
即使有了统一模型,单个模型仍然不会对每个任务都最合适。生产应用需要路由逻辑,把输入类型、任务复杂度、延迟目标和成本画像匹配到合适的模型。这就是为什么模态路由正在变成一种核心架构模式。
日常的收益是在模型、成本和模态之间更简单地路由。团队可以为高量视觉工作使用低成本模型,把高端模型留给更难的推理任务。[11] 如果你必须跨独立的 SDK、速率限制和重试系统来管理这些选择,事情很快会变得一团糟。统一的基础设施去掉了其中大量摩擦。
面向 AI API 驱动应用的架构、性能和定价
可扩展 AI 功能的参考架构
一旦路由设定好,下一步就是为每种工作负载挑选运行时模式。在实践中,三种模式覆盖了大多数生产用例,每一种适配不同类型的任务。
面向 AI 的微服务架构很适合隔离的智能体和检索流水线。每个服务都可以独立部署,使用定义好的 JSON 输入/输出 schema,遵循自己的扩缩策略,并跨服务通过智能体到智能体的消息通信 [2]。
事件驱动流水线很适合批量媒体生成。任务进入异步队列,而小于 10 毫秒的对象存储在步骤之间保留中间媒体资产。然后 OpenTelemetry 追踪整条流水线,并记录模型版本加推理步骤以用于审计追踪 [14][15]。
无服务器函数很适合突发的、用户触发的媒体任务。它们随流量峰值扩缩,并在模型调用不频繁或难以预测时很合理。
最佳选择归结于工作的形态:交互式、异步,还是媒体密集型。
工作流编排、流式和性能调优
这正是生产系统要么感觉顺滑、要么崩塌的地方。编排、流式和缓存是让这些模式在流量到来后仍可用的几块拼图。
长时间运行的视频任务需要 Argo Workflows 5.0、Prefect Orion 或 Temporal 2.x 这样的编排引擎来处理复杂的 DAG、重试和有状态的进度跟踪 [12]。没有那一层,一个失败的步骤可能把整条流水线打回起点。
像 文本 → 图像 → 视频 → 音频 这样的顺序链会把每一步的延迟累加起来。那会把总响应时间推到 11–23 秒。如果你切换到并行分支——例如同时生成图像和音频,再把它们合并——你可以把它降到 5–9 秒,这是 50–60% 的下降 [15]。对于面向用户的目标,争取聊天低于 200 毫秒、预览几秒 [12][15]。
协议选择也很重要,尤其对感知速度而言。
- 服务器发送事件(SSE) 适合聊天 UI 中逐 token 的文本生成。
- WebSocket 适合双向、实时的语音或共享的 AI 会话 [2]。
对于长时间运行的视频或转写任务,使用 webhook 而不是轮询。它们减少不必要的 API 流量,并在厂商变慢时帮助保持你的后端稳定 [17]。
还有几个小选择在生产中也有大影响。对嵌入这类被复用的资产做中间缓存,能在重复请求上同时降低成本和延迟 [13]。固定明确的模型版本有助于避免随时间产生无声的输出漂移 [17]。而且如果你的主模型没达到它的延迟目标,返回一个降级模式的结果——比如一个低分辨率的占位图——往往比彻底阻塞用户流程更好 [17]。
按用例做成本规划和模型选择
架构应该驱动模型档位、托管选择和预算规则。在系统设计定下来之后,定价应该跟随工作负载量和延迟需求。
一种常见的路由分配看起来是这样:把 55–70% 的流量发往低成本模型处理分类等简单任务,20–30% 发往中档模型处理中等工作,只有 5–15% 发往前沿模型处理高风险推理 [3]。
有代表性的视频定价档位 [13]:
| 模型 | 价格 | 最适合 |
|---|---|---|
| MiniMax Hailuo 2.3 | $0.025/sec | 高量、短篇草稿 |
| Kling V3 | $0.0672/sec (720P) | 电影级质量、动态场景 |
| Kling V3 Omni | $0.0672/sec (720P) | 多模态输入、多语言 |
| Sora 2 Preview | $0.08/sec | 质量与成本平衡 |
| Vidu Q3 Pro | $0.12/sec | 复杂场景、高端输出 |
一条产出 15 秒生成媒体片段的链式流水线——包括文生图、图生视频、配音和可选编辑——大约花 $0.425 每片 [13]:
| 流水线阶段 | 模型示例 | 估算成本(美元) |
|---|---|---|
| 文生图 | Seedream-5.0-Lite | $0.035 |
| 图生视频 | Kling-Image2Video-V2.1-Pro | $0.150 |
| 音频 / TTS | ElevenLabs TTS v3 | $0.100 |
| 可选编辑 | Bria Video Eraser | $0.140 |
| 总估算成本 | 链式流水线 | ~$0.425 每片 |
对于流量很大的团队,专用 GPU 容量可能开始比按请求定价更划算。H200 实例约为 $2.60 每 GPU 小时,或约 $1,872/月,并在大约 12,500 次月请求时成为成本更低的选项 [16]。低于那个点,按请求付费通常是更好的路径。
在治理一侧,在子密钥级别设置硬性预算上限,这样递归的智能体循环或流量峰值就不会把账单推高 [9]。另外,用重试和审核之后的总成本来追踪成功,而不只是每次 API 调用的原始成本 [17]。
业务影响及团队接下来该做什么
多模态 AI API 在哪里创造可衡量的价值
一旦架构和定价定下来,下一步很简单:找出多模态 API 能产生明确回报的地方。
| 行业 | 主要用例 | 关键可衡量价值 | 关键 KPI |
|---|---|---|---|
| 营销 | 个性化的 15 秒视频广告 | 广告制作成本降低 60% | 转化率、单广告成本、延迟 |
| 电商 | 图像感知助手 | 通过产品置信度检查提升买家信任 | 会话到成交、幻觉率 |
| 教育 | 自适应 AI 辅导 | 全天候个性化辅导流程 | 学生参与度、忠实度评分 |
| 娱乐 | 预可视化 | 以独立预算实现电影级预可视化 | 时间稳定性、角色一致性 |
这里的规律容易被忽略。模型名字得到了大部分关注,但业务结果往往归结于路由和治理。如果你的技术栈把合适的任务发往合适的模型,并配上合适的检查,你就走得更快。而那种速度优势把 API 选择变成了产品周期上的优势。
未来 12 到 24 个月的技能、治理与运营模式
如今的转变正在离开单体式的 AI 功能,转向分布式、可组合的服务。
在实践中,运营模式正分裂成四个核心职能:
- 平台工程运行网关和路由
- 应用团队构建工作流
- AI ops 负责提示词、评估和成本控制
- 治理处理审计和合规
对于国际团队,及早建好合规很值得。EU AI Act 的 GPAI 义务于 2026 年 8 月 2 日生效,包括审计日志、训练数据摘要和版权检查 [8]。
规划未来 24 个月的一个有用方式,是把 API 费用只当作账单的一部分。它们通常只占总拥有成本的 30–50%。其余应该留给提示词工程(20–30%)、评估(10–20%)和可观测性(10–20%)[1]。只盯着每次调用开销的团队几乎总会低估把生产级 AI 运营好所需要的投入。
结论:AI API 在云原生应用中的未来
「2026 年 AI API 基础设施的选择不是一个供应商采购决策——它是一个战略性的架构决策,将在你的组织的 AI 能力上产生复利式的影响。」 - AI.cc Report [3]
那句话切中要害。集成层和模型本身一样重要。
APIMart 的统一 API 通过一个集成点让团队访问 500+ 模型。这包括视频、图像和语言工作流,定价选项既覆盖低成本的短视频生成,也覆盖更高端的电影级工作负载。
常见问题
我该如何在无服务器、微服务和队列之间为 AI 功能做选择?
这归结于你的工作流在延迟、状态和持久性上的需求。
- 微服务 在你需要独立部署、单独扩缩和清晰的服务契约时很合适。
- 无服务器 在你想保持对话上下文又不想管理虚拟机时很合理,尤其在对延迟敏感的应用里。
- 队列 很适合长时间运行、需持久的工作流,或超出你实时预算的任务。
我什么时候该把请求路由到低成本模型而不是前沿模型?
对例行工作使用低成本模型,比如分类、简短聊天回复、摘要和结构化数据抽取。把前沿模型留给更难的任务,比如多步智能体任务、高级调试,以及需要更多深度的推理。
一种简单的处理方式是用静态规则。例如,基于用户档位或输入长度等清晰信号来路由。另一个选项是先用更便宜的模型,只在它未通过质量检查或 schema 校验时才升级。
我需要哪些控制来管理 AI 的成本、延迟和合规?
在你的应用和模型厂商之间使用一个 AI 网关或统一 API 平台。
那一额外层给你一个统一的地方来控制成本、速度和策略,而不必逐个厂商各管各的。
- 对于成本: 追踪 token 用量、设硬性预算上限、使用语义缓存,并把更简单的任务发往低成本模型。
- 对于延迟: 使用流式和智能路由,并在模型变慢或不可用时兜底。
- 对于合规: 要求区域内数据驻留、脱敏输入,并保留审计日志。