
AI API 定价、性能与可扩展性
一份 2026 年的 AI API 成本指南:token、按图和按秒计费到底如何累加,以及决定你最终付多少钱的延迟、速率限制和重试。
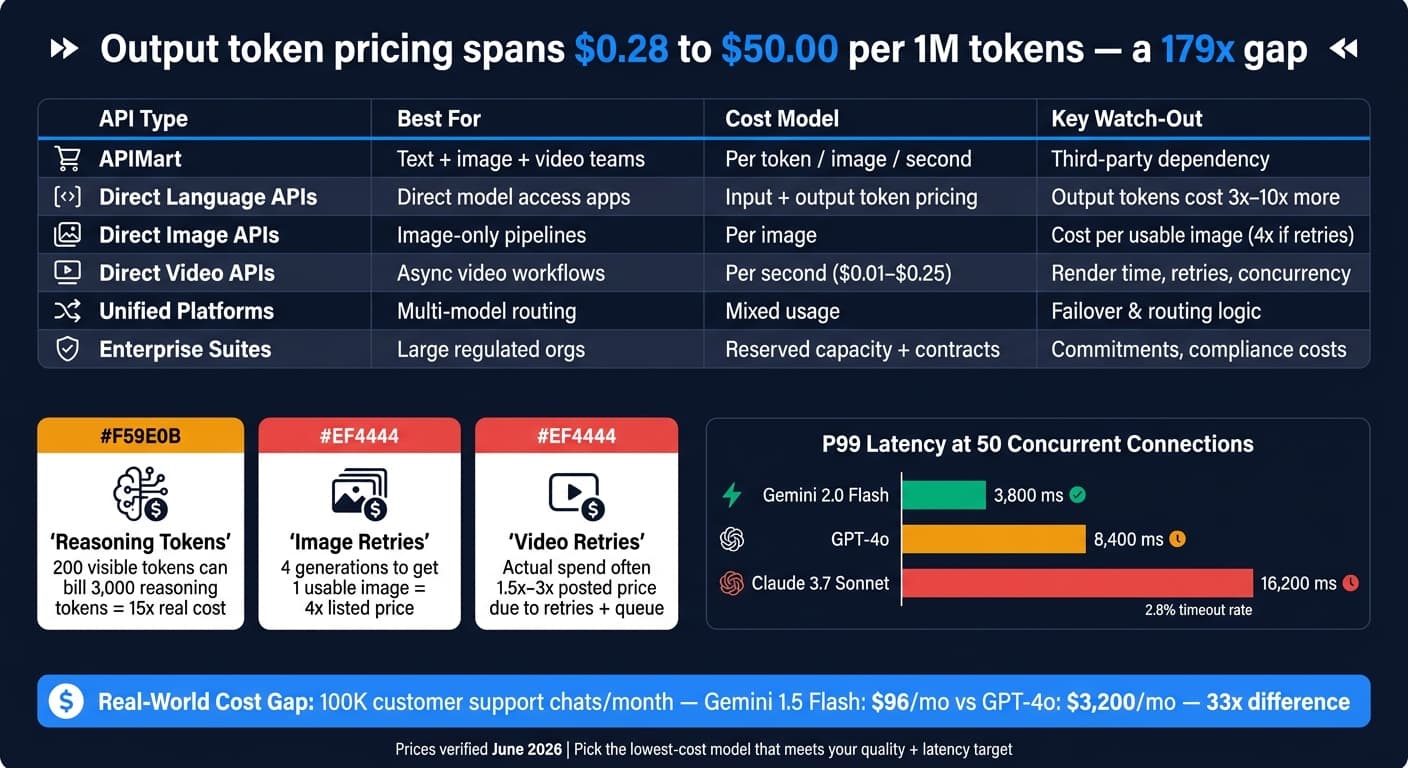
2026 年的 AI API 成本五花八门:仅输出定价就从 每 100 万 token $0.28 到 $50.00 不等,相差 179 倍。 如果今天让我挑一个 API,我会在做任何决定之前先看成本、延迟、速率限制,以及流量攀升时系统如何撑住。
下面是精简版:
- APIMart 为想用一个 API 调用文本、图像和视频模型的团队而建,并附带路由、异步任务和开销控制。
- 直连语言模型 API 给你直接访问,但输出 token 的成本往往是输入 token 的 3 到 10 倍,而推理 token 还能把账单推得更高。
- 直连图像 API 通常按图计费,但你的_真实_成本取决于重试、拒绝率、放大,以及你需要生成多少次才能得到一张能用的图。
- 直连视频 API 通常按秒计费,伴随长等待时间、异步交付、重试成本和很紧的并发上限。
- 统一 AI API 平台 在你需要跨多个厂商做模型路由、故障转移和一个计费层时帮得上忙。
- 企业套件 适合需要预留容量、合规条款、私有网络和基于合同的支持的团队。
如果你想要简单规则,就是这条:挑那个仍能满足你质量和延迟目标的最低成本模型,然后用你自己的提示词、在你自己的流量水平上测试它。 价目表有帮助,但 p95 延迟、重试率、排队时间和重输出用量才决定你最终要付多少。
快速对比
| 选项 | 最适合 | 主要成本模型 | 需留意什么 |
|---|---|---|---|
| APIMart | 同时使用文本、图像和视频的团队 | 按 token、按图、按秒 | 第三方依赖、套餐契合度 |
| 直连语言 API | 需要直接访问模型的应用 | 输入/输出 token 定价 | 输出 token 成本、推理 token、速率限制 |
| 直连图像 API | 纯图像产品和流水线 | 按图 | 每张可用图成本、排队时间、URL 过期 |
| 直连视频 API | 异步视频工作流 | 按秒 | 渲染时间、重试、并发上限 |
| 统一 AI 平台 | 跨厂商的多模型路由 | 混合用量定价 | 路由逻辑、重试处理、故障转移行为 |
| 企业套件 | 有严格法律或基础设施需求的大型组织 | 预留容量和定制合同 | 承诺量、区域定价、支持条款 |
这就是我会用来看待这个主题其余部分的视角:不只是标价,而是大规模拿到一个可用结果的完整成本。
APIMart
APIMart 给你一个调用 500+ 语言、图像和视频模型的单一 API。对大多数团队来说,那意味着更少的集成工作、更简单的定价,以及内建的扩展控制。当你跨文本、图像和视频用例比较成本时,这套配置变得更有用。
它使用按用量付费定价,没有月度最低消费,也没有隐藏费用。计费取决于你使用的模型类型:文本按每 100 万输入 token 计费,图像按调用计费,视频按秒计费。在下面列出的模型上,APIMart 比官方价更低。而随着用量增长,批量折扣和套餐定价还能把单价进一步压低。
| 模态 | 模型 | APIMart 价 | 官方价 | 单位 |
|---|---|---|---|---|
| 文本 | GPT-5 Nano | $0.05 | $0.0625 | 每 1M 输入 token |
| 文本 | Claude Sonnet 4.5 | $1.80 | $3.00 | 每 1M 输入 token |
| 图像 | Imagen 4.0 | $0.04 | $0.05 | 每次调用 |
| 视频 | Sora 2 | $0.08 | $0.10 | 每秒 |
| 视频 | Hailuo 2.3 Fast | $0.025 | $0.031 | 每秒 |
当然,价格只是拼图的一块。一旦用量开始攀升,吞吐和可靠性同样重要。
APIMart 跨厂商路由流量以减少流量峰值期间的限流,支持带 task ID 和 webhook 的异步任务以处理较大的工作,并使用边缘交付来降低全球延迟 [6][7]。它还为生产工作负载提供 99.9% 的正常运行时间 SLA。当流量开始爬升时,监控和预算控制与响应时间一样重要。
对于早期使用,仪表盘帮团队盯住开销。在更高用量时,上限和告警有助于阻止由峰值或重复重试引起的意外扣费。仪表盘实时显示开销、配额和用量,而 APIMart 博客提供更多省钱技巧。对于不需要即时响应的工作,Batch API 把输入和输出 token 成本都降低 50%。
直连语言模型 API
直连语言模型 API 通常把输入和输出 token 分开计费。而输出 token 往往比输入 token 贵 3 到 10 倍,因为生成需要更多算力 [4][8]。那个差距对你月账单的冲击,可能比标价里的每 token 价格看起来要大。
下面是截至 2026 年 6 月、跨常见模型档位的代表性定价快照:
| 模型 | 输入(每 1M token) | 输出(每 1M token) | 上下文窗口 |
|---|---|---|---|
| GPT-5.5 (Flagship) | $5.00 | $30.00 | 1M |
| Claude Opus 4.8 | $5.00 | $25.00 | 1M |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M |
| Gemini 3.1 Pro | $2.00 | $12.00 | 1M |
| GPT-5.4-mini | $0.75 | $4.50 | 400K |
| DeepSeek V4 Flash | $0.14 | $0.28 | 1M |
| Gemini 1.5 Flash | $0.075 | $0.30 | 1M |
在生产中,这些费率会因工作负载不同而表现得非常不一样。档位之间的价格差距会很快变成巨大的开销差距。例如,一个每月处理 100,000 次对话的客服聊天机器人,在 Gemini 1.5 Flash 上约 $96 每月,而在 GPT-4o 上约 $3,200 每月——相差 33 倍 [4]。如果你在跑高量聊天或摘要,重输出的提示词会吃掉大部分预算。
当模型烧掉你根本看不见的 token 时,成本还会再涨。推理模型在这里又加了一层。OpenAI 的 o 系列会生成按输出费率计费的内部推理 token,即便可见答案很短。所以一个 200 token 可见答案的回复,仍可能为 3,000 个推理 token 计费,把真实成本推高 15 倍 [10]。理论上修复很简单:设 max_completion_tokens 或 thinking_budget 给它封顶 [2]。
一旦开销看起来稳定了,下一个问题通常是容量。在规模化时,速率限制往往成为第一个瓶颈。档位升级不会一夜之间完成,所以团队需要在高流量发布提前数周做规划。在 Anthropic,Tier 1 从 $5 付款起步,而 Tier 4 在累计花费 $400 之后解锁 4,000 RPM 和每分钟 400 万输入 token [9]。
而一旦流量到来,延迟可能比标价更重要。在负载下,P99 延迟攀升很快:在 50 个并发连接时,Gemini 2.0 Flash 录得 3,800 ms P99 延迟、0.05% 超时率,GPT-4o 达到 8,400 ms,而 Claude 3.7 Sonnet 触及 16,200 ms、2.8% 超时率 [11]。
直连图像生成 API
直连图像生成 API 通常按图计费,不过有些厂商改用算力时间或按额度定价 [12][14][16]。在实践中,价格主要由分辨率和质量档位驱动。所以如果你既做缩略图又做主视觉图,除非你想花冤枉钱,否则别让它们走同一条路径。
| 模型 | 厂商 | 每张成本(1024px) | 高级档 |
|---|---|---|---|
| Flux.1 Schnell | fal.ai / Replicate | $0.003 | N/A |
| Imagen 4 Fast | $0.010 | N/A | |
| Flux 2 Pro | BFL / fal.ai | $0.030 | $0.060 |
| Imagen 4 Standard | $0.040 | $0.120 | |
| Stable Image Ultra | Stability AI | $0.080 | N/A |
| GPT Image 1.5 | OpenAI | $0.100 | $0.180 (HD) |
有代表性的标准 1024px 定价;在可用处展示高级档 [13][15][16]。
有一件事老让团队栽跟头:追踪每张可用图的成本,而不是每个提示词的成本。如果你的工作流需要四次生成才能得到一张能发布的图,你的实际单位成本就是标价的 4 倍。失败请求、内容审核拒绝、局部重绘和放大都会加进这个总数 [14]。
价格只是故事的一半。速度的摆幅同样剧烈。对于交互式图像应用,追踪 p50、p95、TTFB 和排队等待时间 [17]。一个模型在纸面上可能看起来便宜,但在产品里仍感觉慢。Flux.1 Schnell 对 1024×1024 图像录得 1.2 秒 p50 延迟,而 DALL-E 3 HD 为 11.9 秒 p50 和 21.4 秒 p95 [17]。
规模取决于 API 背后的限制。而这里人们常常搞混:并发上限和速率限制不是一回事。Black Forest Labs 在标准端点上强制 24 个并发请求,而 Stability AI 使用每 10 秒 150 个请求的突发限制,超过后会触发 60 秒超时 [16]。一旦量开始攀升,那个差别就很要紧。
高量流水线通常需要几块无聊但重要的拼图:
- 异步轮询
- 临时资产存储
- 短时效 URL 处理
最后那一块,如果你忽视它,会咬到你。比如 BFL 的 URL 在 10 分钟后过期,所以你需要在链接失效前把图像挪进你自己的系统 [16]。
对大多数生产团队来说,混合技术栈最有道理。把缩略图和其他高量资产发往快速档位。把高级档位留给主视觉图和最终资产——在那里图像质量比纯吞吐更重要。
视频生成 遵循同样的基本模式,但成本和延迟从按图输出转向按秒渲染。
直连视频生成 API
视频对定价和队列施加了更大的压力。算术很简单:你按秒付费,交付通常是异步的。在 2026 年,视频 API 按 $0.01 到 $0.25 每秒计费,取决于模型和档位 [19][20]。在低端,Vidu Q3 Turbo 为 $0.03/秒。在高端,Seedance 2.0 Pro 达到 $0.247/秒。对同样的片长,那差不多是 8 倍的差距 [20]。
而标价只是起点。1080p 是正常的生产基线。升到 4K 或电影级档位,每秒成本可能翻倍甚至翻两番。重试也累加得很快,这意味着实际开销往往落在标价的 1.5 到 2 倍,在来回往复的工作流里可达 3 倍 [20][22]。
不过,价格只是故事的一部分。渲染时间和成功率同样塑造单位经济。一个 10 秒 1080p 的片段在 Seedance 2.0 上可能花 60 到 180 秒,在 Sora 上花 120 到 600 秒 [22]。这就是为什么生产系统应该提交任务、返回一个 job ID,并通过 webhook 或轮询完成交付 [22]。如果你试图把视频当作普通的同步 API 调用,事情很快会变得一团糟。
Sora 2 在标准提示词上平均有 85% 到 90% 的成功率,所以重试和被拒输出从第一天起就要纳入成本模型 [25]。对于视频,追踪的不只是每秒价格。你还需要盯:
- 队列深度
- 并发
- 成功率
这些数字会咬人。在 10 个并发请求时,队列峰值可能超过 7 秒,而大多数账户把并发限制在 3 到 10 个活动生成 [22][23][24][26]。这让 Redis 或 BullMQ 这类工具成为上线前的实用配置,而不是什么锦上添花的东西 [22]。
一种草稿/终稿的工作流通常最有道理。团队可以用 Wan 2.6 或 Seedance 2.0 Fast 这类更快的模型来测试提示词,然后切换到高级模型做最终渲染 [18][20]。这让迭代保持便宜,并把昂贵的运行留给你要发布的那个版本。
一些模型特性还能削减附带成本。带原生音频生成的模型,比如 Veo 3.1 和 Kling 3.0,可以省掉每个视频 $0.50 到 $2.00 的单独音频或授权开销 [20]。原生 9:16 输出(在 Kling 2.6 和 Seedance 2.0 上可用)还避免了为短视频社交片段重新编码 [21]。
那套配置对营销团队尤其管用。他们可以以低成本测试广告变体,然后只把胜出的概念以高级质量渲染。一旦文本、图像和视频都需要在一条流水线里协同工作,统一访问就开始显得有用得多。
统一 AI API 平台
统一 AI API 平台让团队通过一个 API 密钥发送文本、图像和视频请求。当一个产品需要支持不止一种模态时,这削减了集成工作。例如,APIMart 把文本、图像和视频模型放在一个密钥之后。当一个产品需要兼顾便宜的日常调用和更昂贵、高风险的输出时,这套配置最为重要。
定价往往用分层模型路由效果更好。说白了,把简单任务发往低成本模型,把顶级模型留给更难的推理工作。这种方法可以大幅削减开销,尤其因为把每个请求都推给一个高级模型的公司,可能多付 60% 到 80% [27]。提示词缓存也有帮助。当你复用系统提示词或 RAG 文档时,它可以把输入成本削减 50% 到 90% [5]。而当你估算成本时,别停在标价的 token 价格上。你还需要算上推理 token,它们按输出费率计费,并能把总开销推高很多 [5]。
对于交互式功能,两个指标很快变得重要:首 token 时间和重试率。更低的重试率可以意味着每个有用输出的成本更低,即便每 token 价格乍看更高 [28][29][4]。对于实时聊天、流式和交互式助手等对延迟敏感的用例,吞吐也很重要。专用硬件可以达到大约每秒 750 token,相比之下标准 H100 端点约为每秒 100 到 150 token [29]。一旦用量开始攀升,光靠路由解决不了问题。速率限制、故障转移和备用容量开始变得同样重要。
可扩展性正是统一平台开始体现价值的地方。自动故障转移路由把服务中断减少 65% [27]。随着流量增长,团队应该实时监控速率限制余量,并在约 80% 容量处在客户端预先限流。越过那个点,P95 延迟可能跳升 2 到 5 倍 [30][31]。在更高用量时,关键问题不只是模型访问。而是平台给了你多少对路由、限制和故障转移的控制。
企业级 AI API 套件
当路由和批处理不再够用时,企业套件带着预留容量、合规控制和有合同背书的支持登场。统一平台帮你做路由。企业套件处理治理、采购和有保证的容量。
定价模型也变了。企业级 AI API 套件往往不是纯按用量计费,而是把团队转向预留容量和定制合同。这给组织更可预测的吞吐,这对受监管的工作负载或承受不起延迟峰值的应用很重要。大公司常常通过 Azure Provisioned Throughput Units 或 AWS Bedrock Provisioned Capacity 这类选项协商预留吞吐。权衡很简单:更少的灵活性,但更稳的开销。固定的小时或月度费率买来预留容量 [33][28][34]。
还有些额外费用要留意。数据驻留保证,比如仅限美国推理,可能给基础 token 成本加上 1.1 倍乘数 [32][1]。长上下文提示词又能把成本推高。一些厂商在提示词超过 200,000 token 后收双倍费 [32][1]。
服务承诺因合同而异。公开 SLA 通常落在 99.5% 到 99.9% 正常运行时间之间,而一些 MSA 附录会上到 99.99% [35][36]。P95 或 P99 延迟目标通常不是开箱即有的标配。团队一般得按模型和区域去协商它们。
支持条款也各不相同:
- Google 的 Premium Support 档位对严重等级 1 的问题承诺 15 分钟
- OpenAI Enterprise 目标是 1 小时
- Anthropic Enterprise 允许在工作时间内最多 4 小时 [35][36]
在受监管的配置里,控制栈通常包括 VPC 服务控制、VNET 隔离、Private Link、CMEK 加密和**零数据留存(ZDR)**合同。Anthropic 的 ZDR 通过 AWS Bedrock 和 Google Vertex AI 提供,而 Azure OpenAI 需要一份特定的企业协议 [37][38][39]。
成本控制和访问控制一样重要。在企业规模上,基于 token 的限流往往是最强的杠杆。单个 100,000 token 的 RAG 查询,成本可能高达 1,000 次短聊天请求 [40]。那种差距能很快把预算炸开。管理它的常见做法,是在请求前预留一个估算的 token 预算,然后在完成后对照实际总数核对。
各类 API 的优缺点
下面是一种简单方式,看 APIMart 在不同增长阶段如何在成本、速度和日常管理上对比。下表给你一个快速的并排视图。
| 规模阶段 | 优点 | 缺点 | 预算影响 | 速度影响 | 运营影响 |
|---|---|---|---|---|---|
| 早期 / 低量 | 规模化时单位成本更低;统一计费 | 受限于可用套餐;第三方依赖 | 按用量付费,无最低消费 | 中性;取决于厂商基础设施 | 低;单一 API 密钥和计费关系 |
| 成长 / 中量 | 分层模型路由削减开销;提示词缓存降低输入成本 | 批量折扣需要用量门槛 | 通过路由和缓存显著省钱 | 微小路由延迟;在大多数工作负载里可忽略 | 低;故障转移和路由由平台处理 |
| 高量 / 生产 | 异步批处理把 token 成本削减 50%;边缘交付降低全球延迟 | 批量任务比同步调用增加交付延迟 | 通过 Batch API 和批量定价获得最低单位成本 | 稳定吞吐;异步任务避开速率限制瓶颈 | 低;仪表盘、上限和告警集中管理成本 |
用这些权衡来收窄你的选项,然后再把 API 匹配到你的用例。
如何为你的用例选择合适的 AI API
用上面的对比来挑那个仍能达到你质量和延迟目标的最低成本模型。最简单的方式是从你的主要约束开始。
如果预算是最大因素,从那个能越过你最低质量线的最便宜模型开始。然后只在它没达标时才往上提。如果速度最重要,倾向于为快速响应而建的模型,并在上线前用你实际的提示词模板测试 p50 和 p95 延迟。这部分比许多团队预想的更重要。跨区域调用可能增加数百毫秒 [3][42]。
如果输出质量不能打折扣,前沿模型通常最有道理。但模型档位之间有一道很大的价格鸿沟 [1]。
在你锁定任何东西之前,用 30–50 个来自你实际用例的真实提示词跑一个试点,而不是通用的基准提示词 [42]。那能让你对自己在买什么有更清楚的判断。衡量:
- 质量
- 成本
- 原始延迟
那样,你就能看出你的工作负载_实际_需要哪个模型档位。
试点之后,转向负载测试和预算控制。在现实的并发水平下做负载测试,在厂商层面设硬性每日消费上限,并为每个功能的成本异常加告警 [44][43]。当一切看起来还小的时候,这一步很容易被跳过。它也正是成本能悄悄逼近你的地方。
随着提示词变长、边缘情况堆积,生产 token 用量从原型到上线常常增长 5–15 倍 [41]。从第一天起就把那个缓冲建进你的成本模型。
另外,在 APIMart 里记录每个请求——模型版本、token 数、功能名和延迟——这样随着流量增长,路由、成本和延迟都保持可见 [42][43]。
常见问题
我该如何估算我真实的 AI API 成本?
越过基础的每 token 费率,去估算完整的请求生命周期。从这个公式开始:
Monthly cost = (requests_per_day × 30) × ((input_tokens × input_price) + (output_tokens × output_price)) ÷ 1,000,000
从那里出发,把实践中会冒出来的额外成本驱动因素纳入考量。
输出 token 往往比输入 token 贵 3 到 10 倍,所以长答案能很快改变算式。多轮聊天也会推高成本,因为每条新消息都往运行中的上下文里加更多 token。在此之上,重试通常再加 5% 到 15%,尤其当请求失败或超时时。
如果你在用智能体工作流或工具调用,跳升可能大得多。那些配置可以增加 1.5 到 10 倍,因为一个用户动作可能触发好几次模型调用,而不只是一次。
有一个杠杆能削减开销:提示词缓存。如果你的配置支持它,缓存的输入 token 成本可以降低 50% 到 90%。当相同的系统提示词或重复的上下文出现在许多请求中时,这能省下一大块。
上线前最重要的指标是哪些?
上线前,聚焦于那些兼顾稳定性和成本预测的指标:
- p50 和 p95 延迟
- 任务成功率,包括重试和故障转移
- 基于有代表性的提示词形态、输入/输出 token 数和预计月度用量的有效定价
- 对照公布的速率限制的吞吐和并发
在类生产环境中测试,以避免上线后的意外。
我什么时候该用批处理或异步任务?
当你不需要即时回复时,使用批处理或异步任务。那种权衡可以把成本削减多达 50%,这让这种方法很适合不紧急的工作。
好的例子包括:
- 大规模文档摘要
- 视频分析
- 隔夜数据处理
当等待最多 24 小时没问题时,这些任务就说得通。
反过来,别把它们用于依赖快速反馈的面向用户的功能。那包括聊天、自动补全和实时推荐。如果有人坐在那儿等,异步任务通常是错误的工具。
这里还涉及一些额外的管道。任务完成后,你需要逻辑来排队、轮询和核对结果。