
GPT-Image-2 提示词指南 · 对比 DALL·E 3 与 SDXL
详解 GPT-Image-2 多模态提示词的六块结构、16 张参考图与 99% 多语言文字渲染精度,并与 DALL·E 3、Stable Diffusion XL 全面对比,帮你选对 AI 图像模型。
GPT-Image-2 是 OpenAI 于 2026 年 4 月 21 日发布的最新多模态模型。和早期的 DALL·E 3 等工具不同,它把文字理解和图像生成放到同一个系统里完成,因此在多语言文字渲染、空间布局、复杂提示词处理等任务上都更准确。核心亮点包括:
- 文字渲染: 50+ 种语言下保持 99% 准确率,明显领先 DALL·E 3 与 Stable Diffusion XL。
- 空间控制: 支持"top-center"、"bottom-right"等明确位置词,对元素摆放精准可控。
- 编辑工具: 战术级 inpainting,只修改局部,不会牵动整张图。
- 提示词弹性: 单次最多支持 32,000 tokens 和 16 张参考图,可通过 AI 模型市场直接调用。
虽然价格高于 DALL·E 3 和 Stable Diffusion XL,但 GPT-Image-2 在精度上具备不可替代的优势,特别适合信息图、多语言海报、复杂构图等生产级任务。不过生成速度偏慢、定价偏高,并不是所有项目都合适。
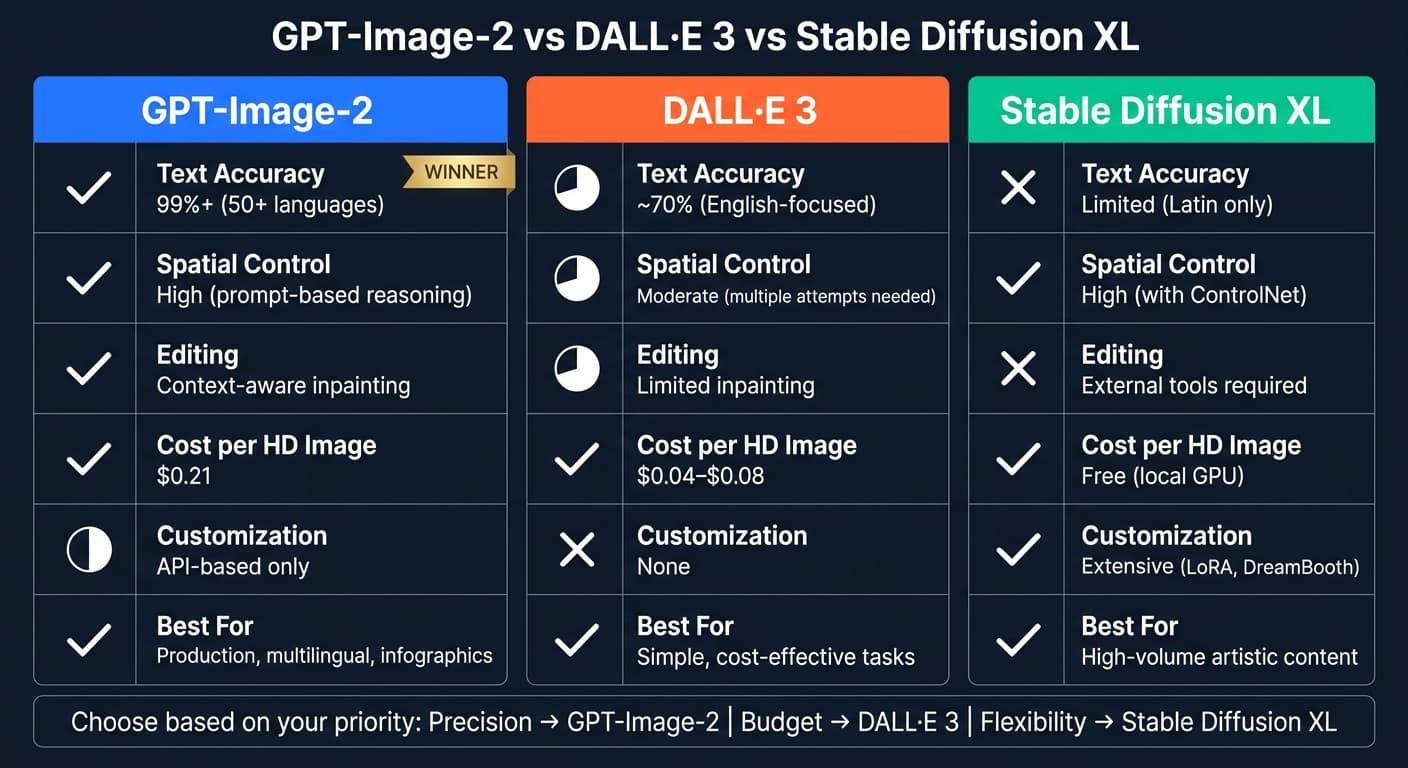
快速对比:
| 特性 | GPT-Image-2 | DALL·E 3 | Stable Diffusion XL |
|---|---|---|---|
| 文字准确率 | 99%+(多语言) | ~70%(偏英文) | 有限(仅拉丁字符) |
| 空间控制 | 高(通过提示词) | 中等 | 高(配合 ControlNet) |
| 编辑能力 | 上下文感知编辑 | 有限的 inpainting | 需要外部工具 |
| 成本 | $0.21(HD 图) | $0.04–$0.08 | 本地免费 |
| 可定制性 | 仅 API | 无 | 高(本地可微调) |
精度优先的任务选 GPT-Image-2;DALL·E 3 适合简单、成本敏感的需求;Stable Diffusion XL 则面向技术能力较强的用户。
GPT Image 2 来了 — 你必须知道的一切
1. GPT-Image-2
GPT-Image-2 是一个会"先想再画"的自然语言模型——动笔生成图像前,它会先规划构图、化解空间冲突。Pixo Blog 这样描述:
"GPT-Image-2 不是一个关键词匹配引擎,而是一个上面叠加了 O 系列推理能力的自然语言模型。" [7]
正是这种独到能力,让它的提示词架构格外值得研究。
提示词结构
模型的推理能力背后,是一套经过精心设计的提示词结构。最有效的提示词遵循"六块"框架:主体(Subject)、动作(Action)、场景(Scene)、构图(Composition)、灯光(Lighting)、风格(Style)。可以把提示词当作一份创意 brief 来写。虽然 统一 LLM API 单次能容纳 32,000 tokens,但把提示词控制在 100–300 字时效果最好。[7]
多图项目里,GPT-Image-2 单次最多支持 16 张参考图。给每张图都用索引指定明确角色——例如 "图 1:主体身份,图 2:色彩风格"——这样模型才能正确融合各来源中的元素。[7][9]
文字渲染
GPT-Image-2 在多语言文字渲染上表现突出,覆盖 英语、西班牙语、德语、法语、日语、简体与繁体中文、韩语。[9] 要插入文字时,用双引号包起来(如 "30% OFF")。对于非英文术语,建议逐字母拼出,例如 "ZEITGEIST (Z-E-I-T-G-E-I-S-T)",准确率可提升到约 99%。[7]
但如果不显式声明"不要文字",大约 60% 的图片 会出现意料之外的字符。为避免这一点,请在提示词末尾加上类似 "No extra text, no additional words, no watermarks." 的指令。[7]
空间控制
GPT-Image-2 在版面方面也有精准的空间控制能力。当场景元素超过三个时,建议启用 Thinking Mode——它会给模型 10–30 秒的规划时间,从而显著提升布局准确度。[7] 使用明确的位置词,如 "top-center"、"bottom-right," 或 "along the left margin",能确保对象和文字落到正确位置。CreateVision AI 的 AI 模型研究负责人 Marcus Rivera 指出,该模型 "能在第一次尝试时就合理化解相互冲突的约束,而不是输出四列没有标题的结果。" [9]
编辑能力
要进一步优化输出,GPT-Image-2 通过 Edits API 接口(v1/images/edits)提供 战术级 inpainting。用户可以选定区域并下发指令,如 "fix a typo" 或 "swap a product." [7][8] 想得到最佳结果,最好明确写出"哪些保持不变",例如 "change only the background, keep the subject and lighting the same." 把编辑轮次控制在三轮以内,可以避免噪点积累和画质下降。[7]
2. DALL·E 3

DALL·E 3 借助 GPT-4 处理提示词,先做扩写和改写,再交给图像模型生成。Enter Pro 这样解释:
"DALL·E 3 本身是一个独立的扩散模型。OpenAI 把它作为外部工具挂到 ChatGPT 上——GPT-4 先写出扩展提示词,再由 DALL·E 3 单独渲染。" [4]
这种两步走的流程容易产生"意图漂移":最终图像未必能完整对应原始诉求,扩写后的提示词有时会丢掉用户的关键意图,导致控制力和准确度都打折。
提示词结构
由于 GPT-4 会自动扩写,DALL·E 3 可以接受更短、更口语化的输入。但代价是创作控制力下降。比如它不支持多图组合,而 GPT-Image-2 是支持的 [10]。
文字渲染
DALL·E 3 一个突出短板就是文字渲染,准确率只有约 70%。长文字和非拉丁字符往往是重灾区。Lensgo 团队指出:
"DALL·E 3 最大的弱点就是清晰可读的文字。让它出一张写着 'Summer Sale 50% Off' 的海报,结果常常变成 'Sumnner Sal 50% Of'。" [10]
这让它在需要精确文字的场景里很难用——比如海报、产品标签、多语言设计等。
空间控制
DALL·E 3 主要靠描述性语言来控制空间位置。它表现尚可,但要想精准定位对象,往往需要多次重生成,时间和成本都会上去 [5]。和 GPT-Image-2 更精准的版面能力相比,差距明显。
编辑能力
DALL·E 3 的编辑受限于 inpainting 实现方式。重新生成所选区域时,相邻部分经常会被无意改动。举个例子:
"当你上传一张照片并说'把帽子改成红色天鹅绒'时,DALL·E 3 倾向于重新生成整张图,连脸都会变样。" [10]
它没有 subject-lock、input_fidelity 调节以及透明背景原生支持等能力,手工修正不可避免。虽然价格——标准 1024×1024 图 $0.04,高清 $0.08——比 GPT-Image-2 便宜,但这些短板让它不适合迭代型的生产任务 [4]。
2026 年 4 月起,DALL·E 3 已从 ChatGPT 界面中下线,由 GPT-Image-2 接替;其旧版 API 接口也将在 2026 年晚些时候停止服务 [2]。
3. Stable Diffusion XL
SDXL 是面向用户的开源替代方案,与 GPT-Image-2 和 DALL·E 3 这类托管 API 模型不同。它是一款 开源基础模型,可在本地 GPU 或云服务上运行,相比单纯调用托管 API 更具掌控力 [11]。
提示词结构
和带有内置推理层的模型不同,SDXL 完全依赖显式 token 和权重调节产出结果,因此对提示词精度的要求更高。要复现特定风格或角色,可借助 LoRA 或 DreamBooth 等工具进行微调 [12]。
文字渲染
文字渲染上 SDXL 有明显局限。短的拉丁字符还能应付,但长字符串、非拉丁字符以及精准排版都比较吃力。相比之下,GPT-Image-2 的多语言文字渲染几乎接近完美。SDXL 想达到同样水平,少不了额外的微调 [11]。
空间控制
SDXL 的空间控制能力很强,特别是配合 ControlNet——可以输入深度图、姿态骨架和边缘检测数据来精确构图 [11]。一旦脱离 ControlNet,SDXL 在复杂版面上就会吃力。
"要它们画一张带五条标题的杂志封面,或者一张带标注箭头的四宫格信息图,结果就全乱了——文字糊掉、标签丢失、版面塌陷。" - BestPhoto 团队 [3]
编辑能力
SDXL 的编辑能力完全依赖外部工具,比如 inpainting、outpainting、LoRA 切换、ControlNet 叠加等 [12]。这些工具能产出强大的效果,但学习曲线相当陡——你得自己管理 Python 环境、GPU 驱动和模型权重,门槛不低。不过对于看重 隐私和品牌独占性 的团队来说,SDXL 的本地化处理是个明显加分项。对其他团队而言,技术成本可能要盖过收益 [11]。
| 特性 | Stable Diffusion XL | GPT-Image-2 |
|---|---|---|
| 空间控制 | 高(ControlNet、深度图)[11] | 中(提示词驱动)[11] |
| 可定制性 | 高(LoRA、DreamBooth)[11] | 低(仅 API,不可微调)[11] |
| 文字渲染 | 一般(偏拉丁字符)[3] | 99%+ 准确率,多语言 [3] |
| 编辑方式 | inpainting、蒙版、ControlNet [12] | 自然语言指令 [12],与 Flux 2 API 类似 |
| 隐私 | 高(本地处理)[11] | 中(OpenAI 服务器)[11] |
| 成本 | 本地免费(需 GPU)[11] | ~$0.04–$0.35 每张 [11] |
优缺点
每个 AI 模型都有自身的长处和短板,适用场景因此各异。
| 模型 | 优势 | 短板 |
|---|---|---|
| GPT-Image-2 | 50+ 语言文字渲染出众;用推理规划版面;上下文感知编辑,最多支持 16 张参考图 [9] | 生成偏慢(标准 30–60 秒,Thinking 模式下可达 149 秒);成本较高(HD 图约 $0.21);复刻精确商标时仍有困难 [1] |
| DALL·E 3 | 易上手;简单场景下能很好地跟随提示词;价格更低($0.04–$0.08 每张)[4] | 长字符串文字渲染不稳定;偏离提示词的概率高;多图一致性差 [4] |
| Stable Diffusion XL | 本地免费;通过 LoRA、ControlNet 可深度定制;适合艺术风内容批量产出 [12] | 不微调时文字渲染较差;复杂版面吃力;部署门槛高(Python、GPU 驱动、模型权重)[12] |
这张表清晰呈现了三者在成本、精度和灵活性之间的取舍。
成本上看,GPT-Image-2 大约比 DALL·E 3 贵五倍,比云上跑的 Stable Diffusion XL 贵四倍以上。但这个溢价换来的是先进的推理能力、近乎完美的多语言文字精度,以及配合 AI Canvas 进行编辑时的顶级表现。
"GPT-Image-2 是第一个能够稳定处理那些信息密度高、内容丰富构图的广泛可用模型,也是第一个引入推理步骤的模型。" - BestPhoto 团队 [3]
对于做信息图或多语言项目的团队,GPT-Image-2 的精度足以抵掉更高的成本和略慢的速度。Stable Diffusion XL 因其本地化处理和单图零成本,对偏艺术风格的创意项目更划算。DALL·E 3 则是中庸选项——便宜、迅速,但精度敏感的任务靠不住。想兼顾成本和质量,可以考虑 GPT-4o Image API,在多模态生成方面是个高性价比的替代方案。
结论
到底选哪一款,完全要看项目的具体需求。GPT-Image-2 在追求精度的生产工作流里表现拔尖——无论是产品标签、UI 稿、多语言海报,还是跨帧需要角色一致性的活动设计,它都能交付出色的多语言文字精度和连贯的推理结果。对那些精度不可妥协的项目,它是有力候选。
DALL·E 3 则更适合一次性、文字精度不那么关键的艺术插画。Stable Diffusion XL 适用于追求批量、风格化输出且具备技术能力深挖工具的团队,它的高级能力能为复杂高需求的项目带来回报。
做决策时,别忽视部署层面的现实因素。多套 API Key 和账单管理会让生产工作流更复杂。像 APIMart 这样的工具通过统一 API 一次性提供 500+ 个 AI 模型(包括 GPT-Image-2),能简化这些行政成本,让你专注在交付结果上。
"这次(升级到 GPT-Image-2)的提升,可以类比从 GPT-3 到 GPT-5 的跨越。" - Sam Altman,OpenAI CEO [6]
把 GPT-Image-2 接入关键工作流,能明显提升产出质量和一致性。
常见问题
怎么写一份好的 GPT-Image-2 提示词?
写好 GPT-Image-2 提示词的关键在于清晰和结构。把它当作给模型的一份详尽创意 brief。先确定你想要的 视觉风格——是"电影感"、"水彩"还是别的什么,定下整体基调。
接着用 具体细节 描述灯光、环境和版面。例如,不要写"一间房间",而是写"一间温馨的客厅,温暖的自然阳光从大型凸窗洒入"。越具体,模型越能准确还原你的想法。
如果要加文字(比如标签或 UI 元素),用引号写出精确措辞,避免歧义。比如写 "Press Start",而不是只说"一个按钮上的字"。
最后,避免堆砌模糊词或塞一堆无关关键词。要的是清晰、有描述力的语言,模型才能把它落到高质量结果上。
怎么避免图里出现意外文字?
要降低 GPT-Image-2 生成图里冒出意外文字的概率,关键是用 清晰精确的提示词。指令要具体、详细,避开模糊或简化的措辞。结构良好的提示词能明显减少视觉杂质,并让必要的文字保持清晰可读。坚持提示词工程的最佳实践,结果质量会有明显提升。
什么时候用 Thinking Mode 处理版面?
启用 Thinking Mode 后,模型会先规划构图、层级与约束,再开始生成图像。这种方式让模型有时间认真推理设计和布局,最终渲染结果会更结构化、更井然有序。
相关博客
去模型市场挑选你想要的模型
在 APIMart 模型市场尝试聊天、图像和视频模型,用统一 API 快速体验模型能力。