
AI Compression for Faster Media Pipelines
Explore AI compression techniques for video, image, texture, and 3D pipelines, with workflow patterns for faster delivery and lower storage costs.
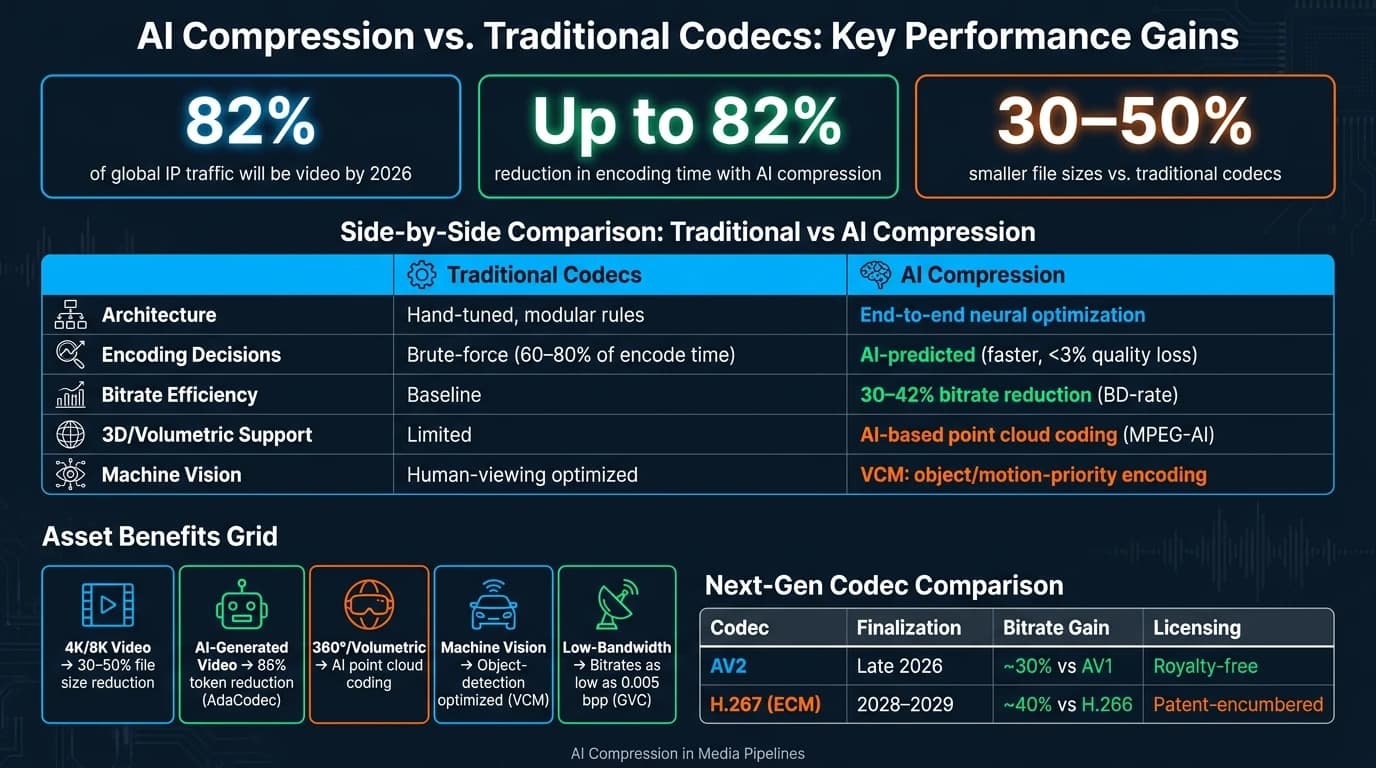
AI compression is transforming how media is processed, stored, and delivered by using machine learning to reduce file sizes, speed up encoding, and maintain visual quality. With video making up 82% of global IP traffic by 2026, traditional codecs like H.264 and HEVC struggle to meet the demands of 4K/8K content, real-time workflows, and bandwidth constraints. AI-driven methods, such as neural codecs and generative compression, tackle these challenges by optimizing decisions and reducing processing times by up to 82% while cutting file sizes by 30–50%.
Key highlights:
- AI Compression Types: AI-enhanced (improves traditional codecs) and AI-native (fully replaces traditional pipelines).
- Efficiency Gains: Encoding time reduced by up to 82%, file sizes shrunk by 30–50%.
- Generative Models: Advanced methods like Generative Video Compression (GVC) achieve ultra-low bitrates for satellite and low-bandwidth applications.
- Applications: Benefits 4K/8K video, volumetric video, AI-generated content, and machine vision data.
- Future Trends: New codecs (AV2, H.267) and AI tools like pre-encoders and autoencoders will further improve efficiency and reduce costs.
AI compression is not just about better codecs - it integrates throughout the entire media pipeline, from ingest to delivery, offering faster processing, lower costs, and compatibility with existing systems.
AI Compression in Media Pipelines
What Is AI Compression?
AI compression, also known as neural compression, uses machine learning techniques - like transformers, convolutional neural networks (CNNs), and generative models - to compress media. Unlike traditional codecs such as H.264, which rely on predefined, manually designed rules, AI compression adapts by learning from data. It optimizes frame partitioning, motion prediction, and data encoding all at once, striving to deliver the best quality while keeping file sizes as small as possible.
"The AI never touches the bitstream; it only touches the decision-making logic that the encoder uses to produce the bitstream." - Nikolay Sapunov, Forasoft [3]
Currently, there are two primary approaches to AI compression:
- AI-enhanced compression: This method integrates smaller, faster models like LightGBM or SVMs into traditional encoders. These models make specific decisions - such as how to divide a frame into blocks - more efficiently.
- AI-native (end-to-end) compression: Here, deep learning networks completely replace traditional pipelines. They map media into a compact "latent space" and use generative models to reconstruct the content on the receiving end.
By relying on a data-driven process, AI compression not only improves coding efficiency but also reduces processing delays, making it a game-changer for media workflows.
Why AI Compression Matters in Media Pipelines
To understand the importance of AI compression, consider the challenge of compute time in media processing. Encoding decisions for codecs like HEVC, AV1, and VVC can take up 60–80% of the total encoding time [3]. These decisions, such as how to divide each frame into coding units, are typically made using time-consuming brute-force methods. With AI models, these decisions can be predicted much faster, cutting encoding time by 30% to 82% while maintaining quality losses under 3% [3].
For workflows handling 4K and 8K content, these time savings are massive. Tasks that used to take hours can now be completed significantly faster, all without requiring changes to existing delivery systems. AI-enhanced models work within current encoders and remain fully compatible with standard decoders like H.264 or AV1.
"The standards-compliance property is what makes a pre-encoder a deployable product instead of a research paper. The integration cost is 'add a step to your existing transcode pipeline,' not 'convince the client side of the world to ship a new decoder.'" - Marco Graziano, EncodeIQ [8]
Pushing the boundaries even further, Generative Video Compression (GVC), introduced by TeleAI (China Telecom) in March 2026, demonstrated the ability to transmit video at bitrates as low as 0.005 bpp (bits per pixel). This breakthrough allows high-quality video delivery over satellite connections, where traditional codecs struggle. Instead of transmitting a compressed video file, GVC sends a description of the content, enabling an AI model at the receiving end to reconstruct it [6].
Media Assets That Benefit Most from AI Compression
The benefits of AI compression are most noticeable for media assets that are large, complex, or expensive to transmit. Here's how the technology impacts specific asset categories:
| Asset Type | Primary Benefit | Key Gain |
|---|---|---|
| 4K/8K Video | Reduces storage and CDN costs | 30–50% file size reduction [11] |
| AI-Generated Video | Lowers inference and token costs | ~86% token reduction [5] |
| Volumetric/360° Video | Handles massive data volumes | AI-based point cloud coding [9] |
| Machine Vision Data | Optimized for object detection | Machine-analysis priority [9] |
| Low-Bandwidth Video | Enables satellite/narrowband use | Bitrates as low as 0.005 bpp [6] |
AI-generated content, in particular, stands to gain significantly. For example, in June 2026, researchers from Shanghai Jiao Tong University and JD.com introduced AdaCodec, which reduces video token usage by 86% by inserting full reference frames only at scene changes. This approach matches benchmarks like LongVideoBench while slashing computational costs [5].
For machine vision applications, such as those used in autonomous vehicles or industrial robotics, a specialized approach called Video Coding for Machines (VCM) is emerging. Unlike traditional codecs, VCM prioritizes features like object boundaries and motion vectors over fine textures, optimizing the video for machine interpretation rather than human viewing.
Core AI Techniques for Media Compression
Neural Video and Image Codecs
Speeding up media processing starts with rethinking how codecs are designed. Traditional codecs like H.264 and HEVC rely on separate, hand-tuned components for tasks like motion estimation, transforms, and entropy coding. Neural codecs, on the other hand, optimize all these components together under a single rate-distortion framework, leading to more efficient compression.
"The hand-engineered, modular architecture of [traditional] codecs imposes inherent limitations: each component... is designed and optimised in relative isolation, which prevents joint global optimisation." - Reka Sandaruwan Gallena Watthage, University of Strathclyde [2]
Take the DCVC-UF (Ultra-Fast) system, for example. Developed by Microsoft Research Asia in June 2026, it encodes multiple video frames into a single latent representation. This approach achieved an impressive 1,415.1 FPS for 1080p video on an NVIDIA B200, while also saving 42.2% bitrate compared to VTM (Low-Delay) [13]. Even with a consumer-grade RTX 4090, it hit 371.1 FPS, making real-time deployment feasible.
Another standout is STAC (Spatio-Temporal Adaptive Context), introduced by the University of Strathclyde in May 2026. Using transformer-based self-attention, STAC models dependencies across both space and time, achieving an average 32.20% BD-rate saving over the VTM-17.0 anchor. This means it can deliver the same visual quality while using about a third less data [2].
These neural advancements also extend to autoencoders, which further improve efficiency by directly optimizing textures and data representation.
Autoencoders for Texture and Image Optimization
AI autoencoders bring a fresh approach to media compression by mapping raw pixels into a compact latent space that retains critical textures and details. A decoder then reconstructs the original content from this compressed form. Unlike traditional codecs, autoencoders can be trained on perceptual quality metrics like MS-SSIM or VMAF, ensuring that fine details and textures remain intact.
One innovation in this space is Latent Transformation Engines (LTE), which project high-dimensional features into smaller, optimized representations using learnable Feature Distribution Matrices. This reduces memory usage and computational demands without sacrificing context. Meanwhile, the Efficient Dual-path Parallel Compression (EDPC) framework splits tasks between the GPU (for probability prediction) and the CPU (for encoding), allowing both to work simultaneously. This setup delivers 2.7x faster compression speeds while cutting GPU memory usage by nearly 50% compared to traditional sequential processing [10].
For AI pipelines where the goal is machine-readability rather than human viewing, autoencoders can be fine-tuned to prioritize features that models need. The AdaCodec system, developed by Shanghai Jiao Tong University and JD.com in June 2026, uses predictive coding to reduce video token usage for multimodal models. By inserting full reference frames only at scene changes, AdaCodec achieved an 86% reduction in video token usage while maintaining the performance of Qwen3-VL-8B [5].
Beyond 2D media, these techniques are also being adapted for the unique challenges of 3D asset compression.
Geometry Compression for 3D Assets
Compressing 3D assets like point clouds and meshes is a whole different ballgame. These assets are massive and unstructured, making real-time applications like gaming or AR/VR particularly challenging.
Implicit Neural Representations (INRs) offer a clever solution by encoding 3D geometry as the weights of a neural network instead of explicit coordinate data. This means that instead of storing millions of vertices, the network learns a continuous function that can reconstruct geometry at any resolution on demand. This drastically reduces the memory footprint for even the most complex assets [14]. For large-scale scenes, techniques like geometry patching - which splits assets into smaller, manageable chunks - make it possible to handle high-resolution 3D data in resource-limited environments [14].
On the standards front, MPEG-AI (ISO/IEC 23888) has incorporated AI-based point cloud coding into its scope, highlighting the growing importance of geometry compression in the industry [9]. As real-time 3D content becomes more prevalent in areas like gaming, simulation, and spatial computing, these techniques are poised to play a central role in production workflows.
How to Integrate AI Compression into Media Pipelines
AI Compression Across Pipeline Stages
AI compression works best when applied throughout the media pipeline, not just at the final stages. The table below highlights how different AI techniques align with specific pipeline stages and the benefits they bring:
| Pipeline Stage | AI Technique | Primary Benefit |
|---|---|---|
| Ingest | Scene & quality analysis | Identifies optimal encoding paths early [11] |
| Asset Creation | Incremental rendering | Reduces re-render times by 75–85% [12] |
| Rendering | ROI bitrate allocation | Maintains quality on faces and on-screen text [11] |
| Delivery | Adaptive Bitrate (ABR) streaming | Eliminates buffering on unstable connections [1] |
At the ingest stage, neural encoders analyze factors like codec, resolution, and frame rate to determine the best encoding path for the content.
During asset creation, incremental rendering focuses on updating only the parts of the timeline that have changed, saving significant time - up to 75–85% - in rendering tasks.
In the rendering phase, content-aware encoding ensures that critical areas, such as faces and on-screen text, receive higher bitrate allocation. This approach balances quality and compression by focusing on regions of interest (ROIs).
Finally, at the delivery stage, Adaptive Bitrate (ABR) streaming adjusts quality dynamically based on network conditions. It also formats content for specific platforms, like vertical videos for TikTok or multi-bitrate ladders for YouTube [12].
These techniques lay the groundwork for modern media pipelines to operate more efficiently and effectively.
Architecture Patterns for AI Compression
Successfully integrating AI compression into your infrastructure requires thoughtful architectural planning. Here are three common patterns that address most production needs:
- Centralized API Integration: This approach simplifies codec management by abstracting complexity and handling global distribution. It reduces infrastructure costs by up to 40% and provides scalability that on-premise systems often lack [15].
- Event-Driven Workflows and Hybrid Setups: Event-driven workflows use webhooks to trigger post-processing tasks, eliminating the need for polling or manual intervention. For teams not fully cloud-based, hybrid setups split tasks between on-premise systems and cloud nodes. This allows sensitive master files to remain local while leveraging cloud resources for parallel rendering of long videos [12].
- Hardware-Accelerated Encoding: Hardware encoders like NVIDIA NVENC or Intel Quick Sync boost real-time processing speeds by 10–50×, making them ideal for live streaming. For video-on-demand (VOD) libraries, software encoders such as SVT-AV1 provide better quality per bit and offer extensive tuning options [7].
By aligning your architecture with these patterns, you can optimize both performance and cost efficiency in your media pipeline.
Storage and Caching Strategies with AI Compression
When paired with AI compression, smart storage strategies can significantly cut costs and reduce latency in media pipelines. A tiered storage approach works well: high-quality mezzanine files are archived for long-term needs, while AI-compressed renditions are used for active delivery, minimizing CDN expenses [15].
For VOD archives, leveraging aggressive AI compression techniques, such as SVT-AV1 at preset levels 4–6, can further reduce storage costs. For near-real-time caching, hardware-based encoding ensures low latency without compromising quality [7].
Neural denoising filters can also play a role by removing random noise, which reduces file sizes by 12–15% [4]. Combining this with edge caching - distributing compressed assets via CDN edge servers - helps lower latency and reduces the load on origin servers [15].
These strategies, when used together, create a streamlined and cost-effective solution for managing media assets in modern pipelines.
Best Practices for Running AI Compression at Scale
Quality Control and Perceptual Metrics
When working at scale, even a single flawed encoding preset can impact thousands of assets. To prevent this, implement automated quality gates that reject encoding jobs falling below a defined VMAF threshold before they reach your CDN. A VMAF score below 80 is a common cutoff, as artifacts become noticeable on most screens at this level [16].
VMAF should be your main quality metric, but it’s wise to add PSNR, SSIM, and VMAF-NEG to spot sharpening artifacts introduced by AI [8].
| VMAF Score | Quality Level |
|---|---|
| 93+ | Excellent (Reference Quality) |
| 80–93 | Good (Broadcast Quality) |
| 70–80 | Fair (Acceptable Mobile) |
| < 70 | Poor (Visible Artifacts) |
For teams handling massive volumes of assets, CPU-based quality checks can quickly become a bottleneck. Switching to NVIDIA VMAF-CUDA increases throughput by 2.5–2.8× compared to CPU validation [16]. This makes it feasible to run quality checks on every asset, eliminating the need for sampling.
Once quality controls are in place, managing assets effectively becomes the next priority.
Versioning and Asset Management
Never overwrite your master files. Store uncompressed originals in permanent cold storage and treat compressed versions as temporary, disposable derivatives. A three-tier storage structure often works best:
- Tier 1: Full-quality masters
- Tier 2: Compressed delivery files (e.g., AV1 or HEVC)
- Tier 3: Temporary working files, which auto-delete after 60–90 days [17][19]
Proper metadata management is just as critical. Attach structured metadata fields - such as Series ID, production batch, language, and resolution - during ingest, and ensure these fields persist through all downstream transformations via webhooks. For example, a production_batch identifier can be a lifesaver. If an encoding preset fails, you can isolate and address the affected assets in that batch without combing through your entire library [18].
"Scaling post-production for 1-minute episodes is not an encoding problem. It is an orchestration problem." - FastPix [18]
For workflows that involve re-editing, maintain two versions of each file: a high-quality master at CRF 18 for future edits and a compressed distribution copy at CRF 28 for delivery. Avoid re-encoding from compressed files, as this introduces generation loss - each pass slightly degrades quality. Always return to the master for any changes [19].
Cost and Resource Optimization
Once you’ve secured asset quality and version control, the next step is reducing delivery costs. While encoding costs are relatively minor, delivery costs dominate. Sujeet Jaiswal, Principal Software Engineer, explains:
"Egress dominates. A 10% compression improvement saves $350,000/month - far exceeding any encoding cost increase from using slower presets or better codecs." [16]
This underscores the value of using slower, higher-quality encoding presets for video-on-demand (VOD). For example, SVT-AV1 at preset 4 or 6 requires more compute time upfront but generates smaller files, significantly reducing long-term CDN expenses. For live or high-volume encoding, where speed is critical, consider NVIDIA NVENC or VPU instances, which can cut per-hour encoding costs from ~$0.68 to ~$0.08 [16].
To further optimize costs, use cloud spot instances, which can reduce compute expenses by up to 70% [12]. Combine this with per-title encoding, where each asset gets a custom bitrate ladder based on its complexity. Simple content like talking-head videos uses fewer bits, while complex scenes (e.g., sports or action) receive the bitrate they need.
Here’s a real-world example: An OTT platform with 8,000 hours of VOD re-encoded its top 1,500 most-watched titles using SVT-AV1 on Intel Arc QuickSync hardware over 14 weeks. This effort cut their CDN bill from $145,000 to $103,000 per month - a $42,000 monthly savings with a payback period of just four months [20]. As AI compression continues to advance, the potential for further cost and performance improvements will only grow.
What's Next for AI-Driven Media Compression
Next-Generation Neural Codecs and Adaptive Compression
The landscape of video compression is evolving rapidly, with next-generation codecs pushing the boundaries of efficiency. Take DCVC-UF, for instance - this cutting-edge system encodes frame chunks into compact latent representations, achieving an impressive 371.1 encoding FPS for 1080p video when run on a 4090 GPU. Even more striking, it delivers a 42.2% bitrate reduction compared to VTM [13].
On the standards front, two codecs stand out:
| Codec | Expected Finalization | Bitrate Gain | Licensing |
|---|---|---|---|
| AV2 | Late 2026 | ~30% vs. AV1 | Royalty-free |
| H.267 (ECM) | 2028–2029 | ~40% vs. H.266 | Patent-encumbered |
Advancements in adaptive context selection are also playing a key role in reducing bitrates further [2].
"The practical 2026 task for almost every operator is to run a same-VMAF AV1-versus-AV2 evaluation against their own catalogue, build a hardware decode roadmap by device family, and design a fallback ladder." - Nikolay Sapunov, CEO, Fora Soft [21]
AI-Driven End-to-End Pipeline Optimization
Beyond codec improvements, AI is reshaping the entire compression pipeline. The buzz isn't just about new codecs - it's about integrating AI into every step of the process. As Nikolay Sapunov puts it:
"When people say 'AI inside the encoder' in 2026, they almost never mean a neural codec that replaces H.264 or AV1 - they mean a small, fast model bolted onto a classical encoder to make one specific decision faster or smarter." - Nikolay Sapunov, CEO, Fora Soft [3]
A great example of this is EncodeIQ, which introduced the Kelvin v1.0 neural pre-encoder in May 2026. Using a SigLIP-2 feature extractor, Kelvin v1.0 adjusts pixels before encoding with the standard x264 encoder. The result? A 27.76% reduction in BD-rate for 1080p content, all while maintaining compatibility with existing decoders. This approach has been especially impactful, given that H.264 still accounted for 79% of production usage among video developers as of 2025 [8].
On the experimental side, Generative Video Compression (GVC), pioneered by TeleAI, takes a bold approach. Instead of compressing and transmitting pixels, GVC sends a compact description of the video. An "AI painter" at the receiving end reconstructs the visuals. TeleAI showcased this at the World Artificial Intelligence Conference (WAIC) in 2025, demonstrating an ultra-low compression rate of just 0.02% for maritime satellite communications [6].
"The core principle of GVC is trading computation for compression rate... traditional compression is akin to photographing a painting and sending the image; GVC, in contrast, describes the painting's composition and style, then relies on an 'AI painter' at the receiver to recreate it." - Xiangyu Chen et al., TeleAI [6]
How Platforms Like APIMart Support the Future of Compression
With these advanced codecs and techniques, managing model weights becomes a significant challenge. Neural codecs rely on trained model weights, and ensuring these work seamlessly across diverse hardware architectures can be daunting.
Platforms like APIMart simplify this process by offering unified access to a vast library of AI models. This solution is ideal for teams exploring neural pre-encoders or video generation models without needing to invest heavily in infrastructure. As one industry expert noted, using a managed API often provides a quicker path to achieving AV1 bandwidth savings without the need to set up an FFmpeg cluster [7]. APIMart currently hosts over 500 AI models for video generation, image processing, and multimodal workflows, offering a straightforward way to integrate next-gen compression technologies into production pipelines.
First AI Codec Running in FFmpeg & VLC – Deep Render’s Breakthrough
FAQs
Do I need new decoders to use AI compression?
Most AI-driven compression methods are designed to work seamlessly with existing decoders. These techniques enhance traditional encoders like H.264, HEVC, AV1, and VVC, generating standard bitstreams that remain compatible with current playback systems. Only experimental neural codecs, which overhaul the entire compression pipeline, require specialized decoders - and these aren’t commonly used yet. Platforms like APIMart provide access to advanced AI models that simplify media workflows without needing any changes to decoders.
When should I use AI-enhanced vs AI-native compression?
AI-enhanced compression is all about improving current workflows without overhauling your existing setup. These tools refine standard encoding processes - like partitioning and scene detection - while keeping everything compatible with your current decoders and hardware. This means you get better performance immediately, with no need for costly upgrades or changes to your pipeline.
On the other hand, AI-native compression is designed for more experimental or specialized applications. These systems completely replace traditional pipelines, offering a fully AI-driven approach. However, they require non-standard decoders, making them impractical for broad commercial use at this stage. For professionals looking to integrate advanced AI models into their workflows, platforms like APIMart make the process smoother and more accessible.
How do I validate quality at scale with AI compression?
To ensure AI compression quality at scale, it's essential to integrate automated quality checks into your transcoding pipeline. A reliable tool for this is VMAF (Video Multi-Method Assessment Fusion), which provides evaluations that align more closely with human perception compared to older metrics like PSNR or SSIM.
Additionally, validating your source files is crucial to catch issues such as corrupt data or unsupported codecs before processing begins. For more advanced workflows, you can analyze compression-induced embedding shifts and compare them against acceptable variations to maintain consistent quality. Tools like APIMart make it easier to incorporate these models into your media workflows seamlessly.
Related Blog Posts
Choose the model you want in the model marketplace
Try chat, image and video models in the APIMart model marketplace, and experience model capabilities quickly with one unified API.