
GPT-Image-2 Prompts vs DALL·E 3 and SDXL Guide
Learn GPT-Image-2 multi-modal prompts with the six-block framework, 16-image references and 99% text accuracy. Detailed comparison with DALL·E 3 and SDXL.
GPT-Image-2 is OpenAI's latest multimodal model, launched April 21, 2026. Unlike earlier tools like DALL·E 3, it combines text understanding and image generation in a single system. This allows for better accuracy in tasks like multilingual text rendering, spatial layouts, and handling complex prompts. Key highlights include:
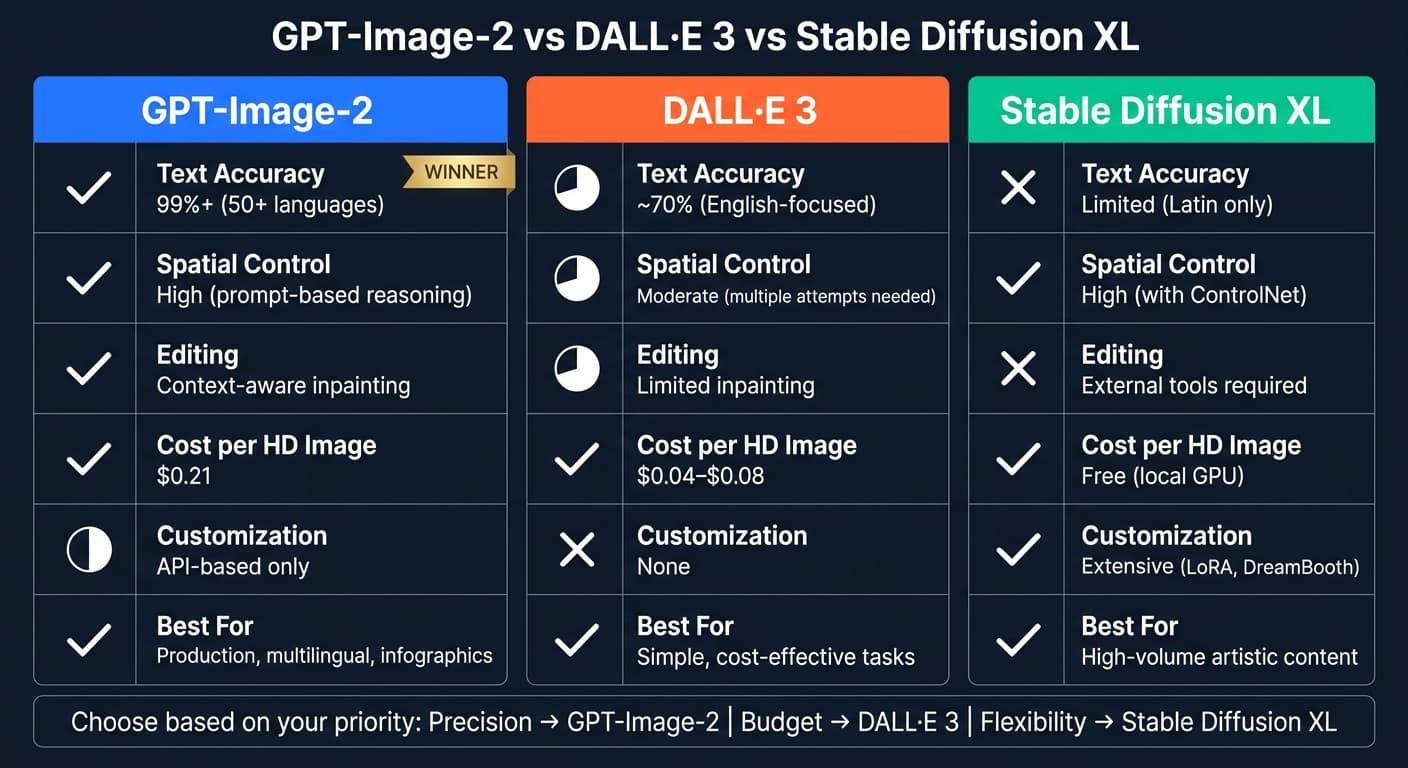
- Text Rendering: 99% accuracy in over 50 languages, far surpassing DALL·E 3 and Stable Diffusion XL.
- Spatial Control: Precise object placement using terms like "top-center" or "bottom-right."
- Editing Tools: Tactical inpainting for specific changes without altering the entire image.
- Prompt Flexibility: Handles up to 32,000 tokens and integrates up to 16 reference images, accessible via the AI Model Marketplace.
While it costs more than DALL·E 3 and Stable Diffusion XL, GPT-Image-2 delivers unmatched precision for production-focused tasks like infographics, multilingual designs, and detailed compositions. However, its slower generation time and higher pricing may not suit all projects.
Quick Comparison:
| Feature | GPT-Image-2 | DALL·E 3 | Stable Diffusion XL |
|---|---|---|---|
| Text Accuracy | 99%+ (multilingual) | ~70% (English-focused) | Limited (Latin only) |
| Spatial Control | High (via prompts) | Moderate | High (with ControlNet) |
| Editing | Context-aware edits | Limited inpainting | External tools required |
| Cost | $0.21 (HD image) | $0.04–$0.08 | Free locally |
| Customization | API-based only | None | Extensive (local fine-tuning) |
For precision-heavy tasks, GPT-Image-2 is the top choice. DALL·E 3 suits simpler, cost-effective needs, while Stable Diffusion XL offers flexibility for tech-savvy users.
GPT Image 2 Is Here - Everything You NEED to Know
1. GPT-Image-2
GPT-Image-2 is a natural-language model designed to think critically - planning its composition and resolving spatial conflicts - before creating an image. As Pixo Blog explains:
"GPT-Image-2 is not a keyword-matching engine. It's a natural-language model with O-series reasoning layered on top." [7]
This unique ability makes its prompt architecture especially noteworthy.
Prompt Structure
The model's reasoning capabilities are complemented by a well-designed prompt structure. The most effective prompts use a six-block framework: Subject, Action, Scene, Composition, Lighting, and Style. Think of the prompt as a creative brief. While the unified LLM API can handle up to 32,000 tokens, keeping prompts between 100–300 words gives the best results. [7]
For multi-image projects, GPT-Image-2 allows up to 16 reference images in a single prompt. Assign each image a clear role using an index - for instance, "Image 1: subject identity, Image 2: color style" - to ensure the model properly integrates elements from each source. [7][9]
Text Rendering
GPT-Image-2 excels in rendering text across multiple languages, including English, Spanish, German, French, Japanese, Simplified and Traditional Chinese, and Korean. [9] To add text, enclose it in double quotes (e.g., "30% OFF"). For non-English terms, spell them out letter-by-letter, like "ZEITGEIST (Z-E-I-T-G-E-I-S-T)", which boosts accuracy to about 99%. [7]
However, if no anti-text directive is included, roughly 60% of images may contain unintended lettering. To prevent this, always end prompts with instructions like "No extra text, no additional words, no watermarks." [7]
Spatial Control
GPT-Image-2 also offers precise spatial control for layouts. Activating Thinking Mode for scenes with more than three elements improves layout accuracy by allowing the model 10–30 seconds to plan before rendering. [7] Using explicit positioning terms such as "top-center", "bottom-right," or "along the left margin" ensures objects and text are placed correctly. Marcus Rivera, AI Model Research Lead at CreateVision AI, observed that the model "resolves conflicting constraints sensibly on the first attempt, instead of arriving as four columns with no title." [9]
Editing Capabilities
To refine its outputs, GPT-Image-2 supports tactical inpainting through its Edits API endpoint (v1/images/edits). Users can select a specific area and provide instructions like "fix a typo" or "swap a product." [7][8] For best results, clearly specify what should remain unchanged, such as "change only the background, keep the subject and lighting the same." Limiting edits to three rounds helps avoid introducing noise or degrading the image quality. [7]
2. DALL·E 3

DALL·E 3 uses GPT-4 to process prompts, expanding and rewriting them before generating images. As Enter Pro explains:
"DALL·E 3 was a standalone diffusion model. OpenAI plugged it into ChatGPT as an external tool - GPT-4 would write an expanded prompt, then DALL·E 3 would render it separately." [4]
This two-step process can result in "intent drift", where the final image might not align perfectly with the original request. The expanded prompt sometimes misses the finer details of the user's intent, affecting both control and accuracy.
Prompt Structure
With GPT-4 automatically expanding prompts, DALL·E 3 can work with shorter, conversational inputs. However, this comes at the cost of creative control. For instance, it doesn’t support multi-image composition, a feature that GPT-Image-2 does offer [10].
Text Rendering
One of DALL·E 3's notable challenges is its text rendering, achieving only about 70% accuracy. It often struggles with longer text or non-Latin scripts. The Lensgo Team highlighted this issue:
"DALL·E 3's biggest weakness was legible text. Ask for a poster with the words 'Summer Sale 50% Off' and DALL·E 3 would return something like 'Sumnner Sal 50% Of.'" [10]
This makes it less reliable for projects requiring precise text, such as posters, product labels, or multilingual designs.
Spatial Control
DALL·E 3 relies on descriptive language in prompts to manage spatial placement. While it performs moderately well, achieving precise object positioning often requires several regeneration attempts, which can be both time-consuming and costly [5]. This contrasts with GPT-Image-2's more accurate layout capabilities.
Editing Capabilities
Editing in DALL·E 3 is limited by its inpainting approach. When regenerating selected areas, adjacent parts of the image are often altered unintentionally. For example:
"When you upload a photo and say 'change the hat to red velvet,' DALL·E 3 tends to regenerate the whole image and the face comes back different." [10]
It lacks features like subject-lock, input_fidelity adjustments, and native support for transparent backgrounds, making manual corrections necessary. While its pricing - $0.04 per standard 1024×1024 image and $0.08 for high resolution - is lower than GPT-Image-2, these limitations make it less ideal for iterative, production-focused tasks [4].
As of April 2026, DALL·E 3 was removed from the ChatGPT interface and replaced by GPT-Image-2. Its legacy API endpoint is also set to be discontinued later in 2026 [2].
3. Stable Diffusion XL
SDXL stands out as a user-driven alternative to API-based tools like GPT-Image-2 and DALL·E 3. It’s an open-source foundation model that can be operated locally on your GPU or through cloud services, offering more control compared to simply calling a managed API with a prompt [11].
Prompt Structure
Unlike models with built-in reasoning layers, SDXL relies entirely on explicit tokens and weight adjustments for generating results. This means users need to be precise with prompts. To achieve a specific style or character, SDXL can be fine-tuned using tools like LoRA or DreamBooth [12].
Text Rendering
When it comes to text rendering, SDXL has its limitations. While it can handle short Latin-script text, it struggles with longer strings, non-Latin scripts, and accurate typography. In comparison, GPT-Image-2 excels in multilingual text rendering with near-perfect precision. For SDXL to match that level, external fine-tuning is essential [11].
Spatial Control
SDXL offers strong spatial control capabilities, especially with ControlNet, which allows users to input depth maps, pose skeletons, and edge detection data to precisely structure compositions [11]. Without ControlNet, however, SDXL can struggle with more intricate layouts.
"Ask them to render a magazine cover with five headlines, or a four-panel infographic with labeled arrows, and they fall apart. Text goes garbled. Labels drop. Layout collapses." - BestPhoto Team [3]
Editing Capabilities
Editing with SDXL depends entirely on external tools like inpainting, outpainting, LoRA swaps, and ControlNet overlays [12]. These tools can deliver powerful results but come with a steep learning curve. Users must manage Python environments, GPU drivers, and model weights, which can be daunting. However, for teams prioritizing privacy-sensitive or brand-specific outputs, SDXL’s local processing is a significant advantage. For others, the technical overhead might outweigh the benefits [11].
| Feature | Stable Diffusion XL | GPT-Image-2 |
|---|---|---|
| Spatial Control | High (ControlNet, depth maps) [11] | Moderate (prompt-based) [11] |
| Customization | High (LoRA, DreamBooth) [11] | Low (API-only, no fine-tuning) [11] |
| Text Rendering | Average (Latin-focused) [3] | 99%+ accuracy, multilingual [3] |
| Editing Method | Inpainting, masks, ControlNet [12] | Natural language instructions [12] , similar to the Flux 2 API |
| Privacy | High (local processing) [11] | Moderate (OpenAI servers) [11] |
| Cost | Free locally (GPU required) [11] | ~$0.04–$0.35 per image [11] |
Pros and Cons
Each AI model brings its own mix of strengths and weaknesses, making them suited for different tasks.
| Model | Strengths | Weaknesses |
|---|---|---|
| GPT-Image-2 | Excels at text rendering in over 50 languages; uses reasoning for layout planning; supports context-aware editing with up to 16 reference images [9] | Slower generation times (30–60 seconds standard, up to 149 seconds in Thinking mode); higher cost (~$0.21 per HD image); struggles with replicating precise trademark logos [1] |
| DALL·E 3 | User-friendly; follows prompts well for simple scenes; lower cost ($0.04–$0.08 per image) [4] | Inconsistent text rendering for longer strings; prone to deviating from prompts; lacks consistency across multiple images [4] |
| Stable Diffusion XL | Free for local use; highly customizable with tools like LoRA and ControlNet; ideal for producing large volumes of artistic content [12] | Poor text rendering unless fine-tuned; struggles with complex layouts; requires a technically demanding setup (Python, GPU drivers, model weights) [12] |
This table underscores the trade-offs between cost, accuracy, and flexibility among the models.
When comparing costs, GPT-Image-2 is about five times more expensive than DALL·E 3 and over four times pricier than Stable Diffusion XL when using cloud services. However, this higher price tag delivers advanced reasoning capabilities, near-perfect multilingual text accuracy, and top-tier performance using an AI Canvas for editing.
"GPT-Image-2 is the first widely-available model that reliably handles those dense, information-rich compositions. It's also the first to use a reasoning step." - BestPhoto Team [3]
For teams working on infographics or multilingual projects, GPT-Image-2’s precision justifies the extra cost and slower processing time. On the other hand, Stable Diffusion XL is a practical choice for creative projects focused on artistic style, thanks to its local processing and zero cost per image. Meanwhile, DALL·E 3 offers a balanced option - affordable and quick, though less reliable for tasks requiring precision. For those needing a balance of cost and quality, the GPT-4o Image API provides a high-performance alternative for multimodal generation.
Conclusion
Selecting the right model depends entirely on the specific needs of your project. GPT-Image-2 stands out for production workflows that demand precision. Whether you're designing product labels, UI mockups, multilingual posters, or campaigns requiring consistent characters across frames, this model delivers exceptional multilingual text accuracy and cohesive reasoning. It's a strong contender for projects where precision is non-negotiable.
On the other hand, DALL·E 3 excels for creating artistic, one-off illustrations where text accuracy isn't a priority. Meanwhile, Stable Diffusion XL is ideal for teams producing high-volume, stylized outputs and equipped with the technical expertise to maximize its features. Its advanced capabilities justify the higher investment for complex, demanding projects.
When deciding, don’t overlook practical deployment factors. Managing multiple API keys and billing accounts can complicate production workflows. Tools like APIMart simplify this by offering access to over 500 AI models - including GPT-Image-2 - through a single, unified API. This streamlines administrative tasks, allowing you to focus on delivering results.
"The upgrade [to GPT-Image-2] is comparable to the jump from GPT-3 to GPT-5." - Sam Altman, CEO, OpenAI [6]
Incorporating GPT-Image-2 into critical workflows can significantly enhance both output quality and consistency.
FAQs
How do I write a strong GPT-Image-2 prompt?
Creating a strong GPT-Image-2 prompt comes down to clarity and structure. Think of it as crafting a detailed creative brief for the model. Start by specifying the visual style you want - whether it's "cinematic", "watercolor", or something else entirely. This sets the tone for the output.
Next, provide precise details about the lighting, environment, and layout. For example, instead of saying "a room", describe it as "a cozy living room with warm, natural sunlight streaming through large bay windows." The more specific you are, the better the model can interpret your vision.
If you're including text, such as labels or UI elements, use exact wording in quotes to avoid misinterpretation. For instance, write "Press Start" rather than just mentioning "a button label."
Lastly, steer clear of vague phrases or cramming too many unrelated keywords into the prompt. Instead, focus on clear, descriptive language to guide the model effectively and produce high-quality results.
How do I prevent unwanted text in images?
To minimize unwanted text in images created by GPT-Image-2, it's important to use clear and precise prompts. Be specific and detailed in your instructions, steering clear of vague or overly simple language. Well-structured prompts make a big difference, reducing visual artifacts and ensuring any text within the image is legible. By sticking to prompt engineering best practices, you can greatly enhance the quality of your results.
When should I use Thinking Mode for layout?
When you activate Thinking Mode for layout, the model takes time to plan the composition, hierarchy, and constraints before generating an image. This approach allows the model to carefully reason through the design and layout, ensuring the final rendering is more structured and well-organized.
Related Blog Posts
Choose the model you want in the model marketplace
Try chat, image and video models in the APIMart model marketplace, and experience model capabilities quickly with one unified API.